Svelare la Legge dei Grandi Numeri
'Unveiling the Law of Large Numbers'.

La LLN è interessante tanto per quello che non dice quanto per quello che dice
Il 24 agosto 1966, uno talentuoso drammaturgo di nome Tom Stoppard mise in scena una commedia a Edimburgo, in Scozia. La commedia aveva un titolo curioso, “Rosencrantz and Guildenstern Are Dead”. I suoi personaggi principali, Rosencrantz e Guildenstern, sono amici d’infanzia di Amleto (famoso nelle opere di Shakespeare). La commedia si apre con Guildenstern che lancia ripetutamente monete che continuano a uscire Testa. Ogni risultato fa diventare più leggera la borsa di denaro di Guildenstern e più pesante quella di Rosencrantz. Mentre il rullo di Teste continua con una spietata persistenza, Guildenstern è preoccupato. Si chiede se sta segretamente desiderando che ogni moneta esca Testa come una punizione autoinflitta per qualche peccato dimenticato. O se il tempo si è fermato dopo il primo lancio e lui e Rosencrantz stanno vivendo lo stesso risultato ripetutamente.
Stoppard fa un lavoro brillante nel mostrare come le leggi della probabilità siano intrecciate nella nostra visione del mondo, nella nostra percezione delle aspettative, nel tessuto stesso del pensiero umano. Quando anche il 92° lancio esce Testa, Guildenstern si chiede se lui e Rosencrantz sono sotto il controllo di una realtà innaturale in cui le leggi della probabilità non operano più.
Le paure di Guildenstern sono ovviamente infondate. Ammettiamo che la probabilità di ottenere 92 Teste consecutive sia inimmaginabilmente piccola. In realtà, è una virgola seguita da 28 zeri seguiti da 2. Guildenstern ha più probabilità di essere colpito in testa da un meteorite.
Guildenstern deve solo tornare il giorno successivo per lanciare un’altra sequenza di 92 lanci di monete e il risultato sarà quasi certamente molto diverso. Se seguisse questa routine ogni giorno, scoprirebbe che nella maggior parte dei giorni il numero di Teste corrisponderà più o meno al numero di Croci. Guildenstern sta vivendo un comportamento affascinante dell’universo conosciuto come la Legge dei Grandi Numeri.
- Svelando la Legge dei Grandi Numeri
- Top 15 Software per Big Data da conoscere nel 2023
- Come eseguire la codifica delle etichette in Python?
La Legge dei Grandi Numeri spiegata in linguaggio semplice
La LLN, come viene chiamata, viene in due varianti: debole e forte. La LLN debole può essere più intuitiva e più facile da comprendere. Ma è anche facile da interpretare erroneamente. In questo articolo parlerò della versione debole e lascerò la discussione sulla versione forte per un articolo successivo.
La Legge dei Grandi Numeri debole si occupa della relazione tra la media campionaria e la media della popolazione. Spiegherò cosa dice in parole semplici:
Supponiamo di estrarre un campione casuale di una certa dimensione, diciamo 100, dalla popolazione. A proposito, prendi nota mentale del termine dimensione del campione. La dimensione del campione è il direttore del circo, il grande capo di questa legge. Ora calcola la media di questo campione e mettila da parte. Successivamente, ripeti questo processo molte volte. Otterrai un insieme di medie imperfette. Le medie sono imperfette perché ci sarà sempre un “gap”, un delta, una deviazione tra esse e la vera media della popolazione. Supponiamo che tu tolleri una certa deviazione. Se selezioni una media campionaria a caso da questo insieme di medie, ci sarà una possibilità che la differenza assoluta tra la media campionaria e la media della popolazione superi la tua tolleranza.
La Legge dei Grandi Numeri deboli afferma che la probabilità che questa deviazione superi il tuo livello di tolleranza selezionato si ridurrà a zero man mano che la dimensione del campione cresce fino all’infinito o fino alla dimensione della popolazione.
Non importa quanto sia piccolo il tuo livello di tolleranza selezionato, man mano che estrai insiemi di campioni di dimensioni sempre più grandi, diventerà sempre più improbabile che la media di un campione scelto a caso dall’insieme superi questa tolleranza.
Un’illustrazione del mondo reale di come funziona la LLN debole
Per capire come funziona la LLN debole la metteremo in pratica con un esempio. E per questo, permettimi, se vuoi, di portarti nella fredda e cupa distesa dell’Oceano Atlantico Nordorientale.
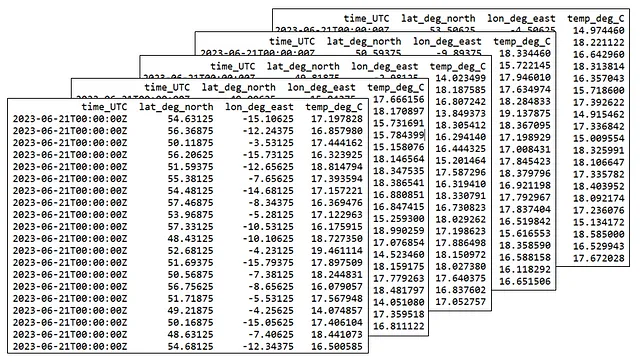
Ogni giorno, il Governo dell’Irlanda pubblica un dataset delle misurazioni della temperatura dell’acqua prelevate dalla superficie del Nord Est del Nord Atlantico. Questo dataset contiene centinaia di migliaia di misurazioni della temperatura dell’acqua superficiale indicizzate per latitudine e longitudine. Ad esempio, i dati per il 21 giugno 2023 sono i seguenti:
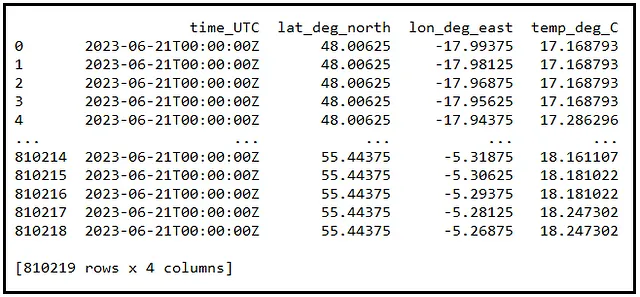
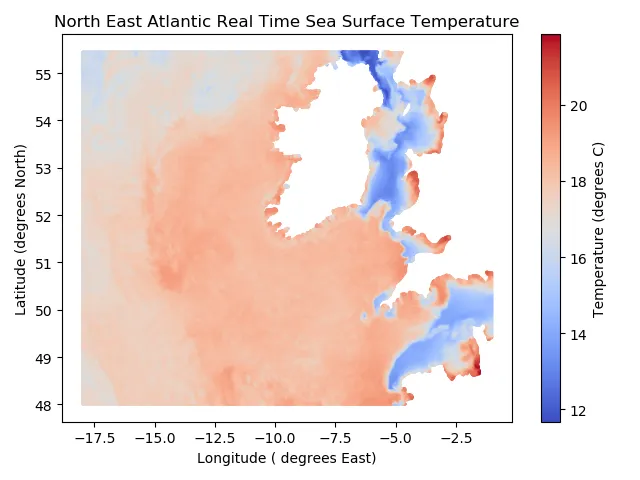
È difficile immaginare come siano fatti ottocentomila valori di temperatura della superficie. Quindi creiamo un grafico a dispersione per visualizzare questi dati. Ho mostrato questo grafico di seguito. Le aree bianche vuote nel grafico rappresentano l’Irlanda e il Regno Unito.
Come studente di statistica, non avrai mai accesso alla “popolazione”. Quindi avrai ragione a criticarmi severamente se dichiaro questa popolazione di 800.000 misurazioni di temperatura come “popolazione”. Ma sopportami per un attimo. Presto vedrai perché, nella nostra ricerca per capire il LLN, ci aiuta considerare questi dati come la “popolazione”.
Quindi supponiamo che questi dati siano – ahem… toss – la popolazione. La temperatura media dell’acqua superficiale nelle 810.219 posizioni di questa popolazione di valori è di 17,25840 gradi Celsius. 17,25840 è semplicemente la media delle 810.000 misurazioni di temperatura. Designiamo questo valore come media della popolazione, μ. Ricorda questo valore. Avrai bisogno di consultarlo spesso.
Ora supponi che questa popolazione di 810.219 valori non sia accessibile a te. Invece, hai accesso solo a un piccolo campione casuale di 20 posizioni estratte da questa popolazione. Ecco un tale campione casuale:
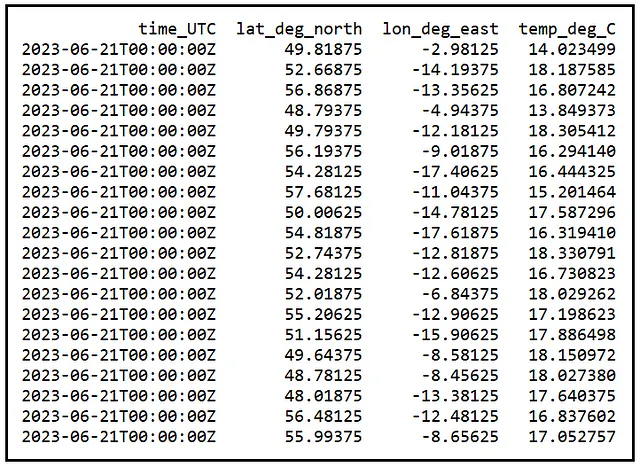
La temperatura media del campione è di 16,9452414 gradi Celsius. Questa è la nostra media del campione X_bar che viene calcolata nel seguente modo:
X_bar = (X1 + X2 + X3 + … + X20) / 20
Puoi facilmente estrarre un secondo, un terzo, infatti qualsiasi numero di tali campioni casuali di dimensione 20 dalla stessa popolazione. Ecco alcuni campioni casuali a titolo illustrativo:
Una breve parentesi su cosa sia realmente un campione casuale
Prima di andare avanti, fermiamoci un attimo per ottenere un certo grado di prospettiva sul concetto di campione casuale. Sarà più facile capire come funziona il debole LLN. E per acquisire questa prospettiva, devo presentarti la slot machine del casinò:

La slot machine mostrata sopra contiene tre slot. Ogni volta che abbassi il braccio della macchina, la macchina riempie ogni slot con un’immagine selezionata casualmente dalla popolazione di immagini mantenuta internamente, come ad esempio un elenco di immagini di frutta. Ora immagina una slot machine con 20 slot chiamati X1 attraverso X20. Supponi che la macchina sia progettata per selezionare valori da una popolazione di 810.219 misurazioni di temperatura. Quando tiri giù il braccio, ciascuno dei 20 slot – X1 attraverso X20 – si riempie con un valore selezionato casualmente dalla popolazione di 810.219 valori. Pertanto, X1 attraverso X20 sono variabili casuali che possono contenere qualsiasi valore della popolazione. Presi insieme, formano un campione casuale. In altre parole, ogni elemento di un campione casuale è esso stesso una variabile casuale.
X1 attraverso X20 hanno alcune proprietà interessanti:
- Il valore che X1 acquisisce è indipendente dai valori che X2 fino a X20 acquisiscono. Lo stesso vale per X2, X3, …, X20. Pertanto X1 fino a X20 sono variabili casuali indipendenti.
- Poiché X1, X2,…, X20 possono assumere ciascuno qualsiasi valore della popolazione, la media di ciascuno di essi è la media della popolazione, μ. Usando la notazione E() per l’aspettazione, scriviamo questo risultato come segue: E(X1) = E(X2) = … = E(X20) = μ.
- X1 fino a X20 hanno distribuzioni di probabilità identiche.
Pertanto, X1, X2,…,X20 sono variabili casuali indipendenti e identicamente distribuite (i.i.d.).
…e ora torniamo a mostrare come funziona il LLN debole
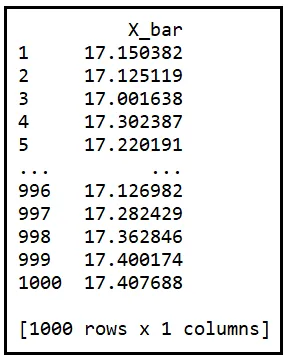
Calcoliamo la media (indicata da X_bar) di questo campione di 20 elementi e mettiamola da parte. Ora abbassiamo di nuovo il braccio della macchina e ne uscirà un altro campione casuale di 20 elementi. Calcoliamo la sua media e mettiamola da parte anche questa volta. Se ripetiamo questo processo mille volte, avremo calcolato mille medie campionarie.
Ecco una tabella di 1000 medie campionarie calcolate in questo modo. Le designiamo come X_bar_1 fino a X_bar_1000:

Ora considera attentamente la seguente affermazione:
Dato che la media campionaria è calcolata da un campione casuale, la media campionaria è essa stessa una variabile casuale.
A questo punto, se annuisci saggiamente e ti strofini il mento, stai facendo esattamente la cosa giusta. La realizzazione che la media campionaria è una variabile casuale è una delle realizzazioni più penetranti che si possono avere in statistica.
Notare anche come ogni media campionaria nella tabella sopra sia ad una certa distanza dalla media della popolazione, μ. Grafichiamo un istogramma di queste medie campionarie per vedere come sono distribuite intorno a μ:
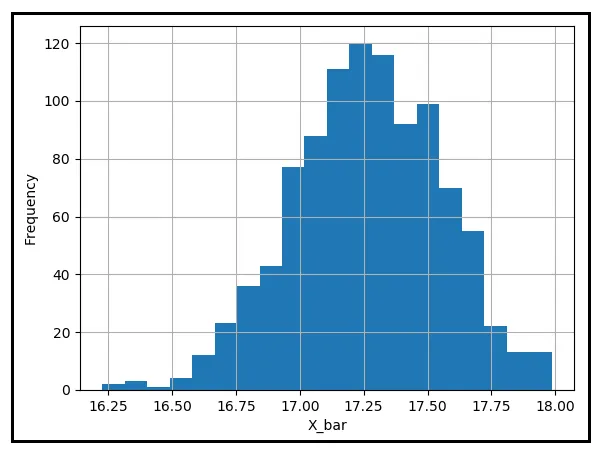
Molte delle medie campionarie sembrano essere vicine alla media della popolazione di 17,25840 gradi Celsius. Tuttavia, ce ne sono alcune che sono considerevolmente distanti da μ. Supponi che la tua tolleranza per questa distanza sia di 0,25 gradi Celsius. Se immergessi la tua mano in questo secchio di 1000 medie campionarie, prendi qualsiasi media che si trovi entro la tua portata e tirala fuori. Qual sarà la probabilità che la differenza assoluta tra questa media e μ sia uguale o maggiore di 0,25 gradi C? Per stimare questa probabilità, devi contare il numero di medie campionarie che sono almeno a 0,25 gradi di distanza da μ e dividere questo numero per 1000.
Nella tabella sopra, questo conteggio risulta essere 422 e quindi la probabilità P(|X_bar — μ | ≥ 0,25) risulta essere 422/1000 = 0,422
Mettiamo da parte questa probabilità per un momento.
Ora ripeti tutti i passaggi precedenti, ma questa volta usa una dimensione del campione di 100 invece di 20. Quindi ecco cosa farai: estrai 1000 campioni casuali ciascuno di dimensione 100, prendi la media di ciascun campione, conserva tutte quelle medie, conta quelle che sono almeno a 0,25 gradi C di distanza da μ e dividi questo conteggio per 1000. Se ti è sembrato il lavoro di Ercole, non ti sbagliavi. Quindi prenditi un momento per riprendere fiato. E una volta che sei al passo con tutto, nota sotto cosa hai ottenuto come frutto dei tuoi sforzi.
La tabella qui sotto contiene le medie dei 1000 campioni casuali, ciascuno di dimensione 100:
Di queste mille medie, cinquantasei medie si discostano di almeno 0,25 gradi C da μ. Ciò ti dà la probabilità di incontrare una tale media come 56/1000 = 0,056. Questa probabilità è decisamente più piccola rispetto al 0,422 calcolato in precedenza quando la dimensione del campione era solo 20.
Se ripeti questa sequenza di passaggi più volte, ogni volta con una dimensione del campione diversa che aumenta incrementalmente, otterrai una tabella piena di probabilità. Ho fatto questo esercizio per te aumentando la dimensione del campione da 10 a 490 in incrementi di 10. Ecco il risultato:
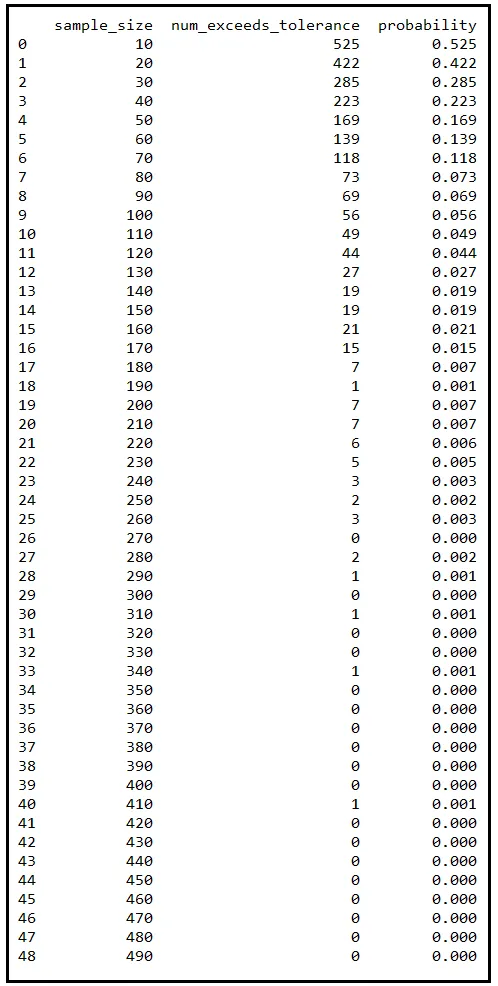
Ogni riga di questa tabella corrisponde a 1000 campioni diversi che ho estratto casualmente dalla popolazione di 810219 misurazioni di temperatura. La colonna sample_size indica la dimensione di ciascuno di questi 1000 campioni. Una volta estratto, ho preso la media di ciascun campione e ho contato quelli che si discostavano di almeno 0,25 gradi C da μ. La colonna num_exceeds_tolerance indica questo conteggio. La colonna probability è num_exceeds_tolerance / sample_size.
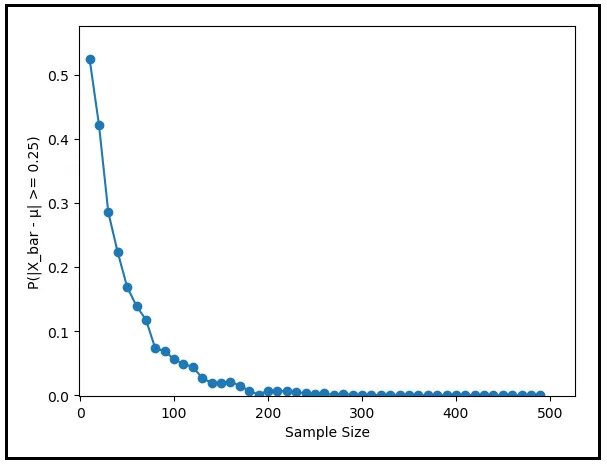
Nota come questo conteggio diminuisce rapidamente all’aumentare della dimensione del campione. E lo stesso vale per la probabilità corrispondente P(|X_bar — μ | ≥ 0.25). Quando la dimensione del campione raggiunge 320, la probabilità si è ridotta a zero. Ogni tanto può salire a 0,001, ma questo è perché ho estratto un numero finito di campioni. Se ogni volta estraggo 10000 campioni invece di 1000, non solo le occasionali fluttuazioni diminuiranno, ma anche l’attenuazione delle probabilità sarà più regolare.
Il grafico seguente rappresenta P(|X_bar — μ | ≥ 0.25) in funzione della dimensione del campione. Mette in evidenza come la probabilità diminuisca a zero all’aumentare della dimensione del campione.
Al posto di 0.25 gradi C, cosa succede se scegli un’altra tolleranza, sia più bassa che più alta? La probabilità diminuisce indipendentemente dal livello di tolleranza scelto? La seguente serie di grafici illustra la risposta a questa domanda.
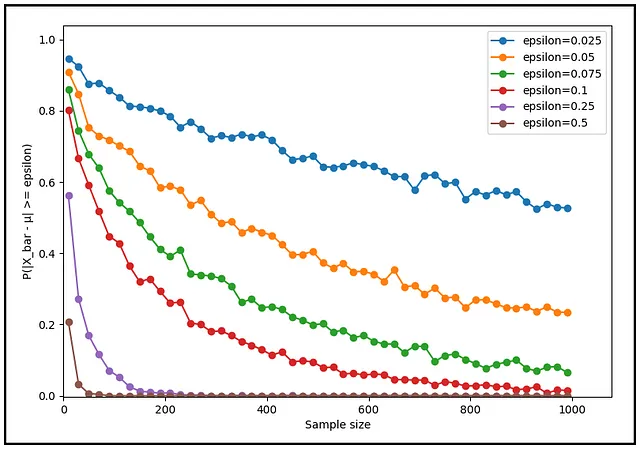
Indipendentemente da quanto piccola, quanto minima sia la tua scelta di tolleranza (ε), la probabilità P(|X_bar — μ | ≥ ε) convergerà sempre a zero all’aumentare della dimensione del campione. Questa è la debole legge dei grandi numeri in azione.
La legge debole dei grandi numeri, enunciata formalmente
Il comportamento della legge debole dei grandi numeri può essere enunciato formalmente come segue:
Sia X1, X2, …, Xn delle variabili casuali i.i.d. che formano insieme un campione casuale di dimensione n. Sia X_bar_n la media di questo campione. Supponiamo inoltre che E(X1) = E(X2) = … = E(Xn) = μ. Allora per ogni numero reale non negativo ε, la probabilità che X_bar_n sia almeno ε lontano da μ tende a zero all’aumentare della dimensione del campione. L’esquisita equazione seguente cattura questo comportamento:
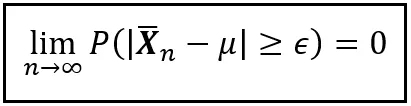
Nel corso dei 310 anni di storia di questa legge, i matematici sono stati in grado di rilassare progressivamente il requisito che X1 attraverso Xn siano indipendenti e identicamente distribuite, pur preservando lo spirito della legge.
Il principio della “convergenza in probabilità”, la notazione “plim” e l’arte di dire cose veramente importanti con poche parole
Lo stile particolare di convergenza a un certo valore utilizzando la probabilità come mezzo di trasporto è chiamato convergenza in probabilità. In generale, viene enunciato come segue:
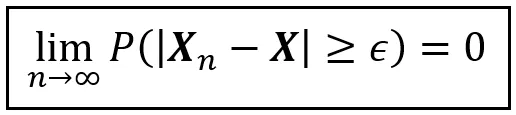
Nell’equazione sopra, X_n e X sono variabili casuali. ε è un numero reale non negativo. L’equazione afferma che al tendere di n all’infinito, X_n converge in probabilità a X.
In tutta l’immensa vastità delle statistiche, ti imbatterai in una notazione silenziosamente modesta chiamata plim. Si pronuncia ‘p lim’, o ‘plim’ (come la parola “prugna” ma con una “i”), o limite di probabilità. plim è il modo abbreviato di dire che una misura come la media converge in probabilità a un valore specifico. Utilizzando plim, la legge debole dei grandi numeri può essere enunciata in modo conciso come segue:
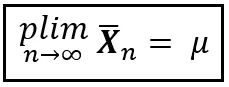
O semplicemente come:
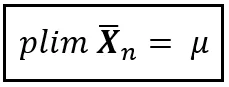
La brevità della notazione non è affatto sorprendente. I matematici sono attratti dalla brevità come le api dal nettare. Quando si tratta di trasmettere verità profonde, la matematica potrebbe benissimo essere il campo più efficiente in termini di inchiostro. E all’interno di questo campo ossessionato dall’efficienza, plim occupa una posizione di rilievo. Ti sarà difficile trovare un concetto altrettanto profondo come plim espresso con una quantità di inchiostro o di elettroni inferiore.
Ma non lottare più. Se la bellezza laconica di plim ti ha lasciato desiderare di più, ecco un’altra notazione, forse ancora più efficiente, che trasmette lo stesso significato di plim:
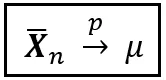
Smentire alcuni miti sul debole LLN
All’inizio di questo articolo, ho menzionato che il debole Legge dei Grandi Numeri è degno di nota per ciò che non dice tanto quanto per ciò che dice. Permettetemi di spiegare cosa intendo. Il debole LLN viene spesso frainteso nel senso che, all’aumentare della dimensione del campione, la sua media si avvicina alla media della popolazione o a varie generalizzazioni di quell’idea. Come abbiamo visto, tali idee sul debole LLN non hanno alcun attaccamento alla realtà.
In effetti, sfatiamo subito un paio di miti riguardanti il debole LLN.
MITO #1: All’aumentare della dimensione del campione, la media del campione tende alla media della popolazione.
Questa è molto probabilmente la più frequente interpretazione errata del debole LLN. Tuttavia, il debole LLN non fa tale affermazione. Per capire perché, considerate la seguente situazione: siete riusciti a ottenere un campione davvero grande. Mentre ammirate con gioia il vostro successo, dovreste anche porvi le seguenti domande: solo perché il vostro campione è grande, deve essere anche ben bilanciato? Cosa impedisce alla natura di colpirvi con un campione gigante che contiene una quantità altrettanto gigante di bias? La risposta è assolutamente nulla! In effetti, non è quello che è successo a Guildenstern con la sua sequenza di 92 teste? Era, dopotutto, un campione completamente casuale! Se capita di avere un grande bias, allora nonostante la grande dimensione del campione, il bias spazzerà via la media del campione fino a un punto lontano dal vero valore della popolazione. Al contrario, un piccolo campione può rivelarsi squisitamente ben bilanciato. Il punto è che, all’aumentare della dimensione del campione, la media del campione non è garantita di avanzare obbedientemente verso la media della popolazione. La natura non fornisce tali garanzie inutili.
MITO #2: All’aumentare della dimensione del campione, praticamente tutto sul campione — la sua mediana, la sua varianza, la sua deviazione standard — converge ai valori della popolazione corrispondenti.
Questa frase è due miti racchiusi in un unico pacchetto facile da trasportare. In primo luogo, il debole LLN postula una convergenza in probabilità, non in valore. In secondo luogo, il debole LLN si applica alla convergenza in probabilità solo della media del campione, non di altre statistiche. Il debole LLN non affronta la convergenza di altre misure come la mediana, la varianza o la deviazione standard.
Come sapere se funziona la debole Legge dei Grandi Numeri?
È una cosa affermare il debole LLN e persino dimostrare come funziona utilizzando dati del mondo reale. Ma come puoi essere sicuro che funzioni sempre? Ci sono circostanze in cui può rovinare tutto — situazioni in cui la media del campione semplicemente non converge in probabilità al valore della popolazione? Per saperlo, devi dimostrare il debole LLN e, nel farlo, definire precisamente le condizioni in cui si applicherà.
Casualmente, il debole LLN ha una deliziosa e allettante dimostrazione che utilizza come uno dei suoi ingredienti l’incessantemente allettante Ineguaglianza di Chebyshev. Se questo stimola la tua curiosità, rimani sintonizzato per il mio prossimo articolo sulla dimostrazione della debole Legge dei Grandi Numeri.
Rivisitando Guildenstern
Sarebbe scortese concludere questo argomento senza placare le preoccupazioni del nostro amico Guildenstern. Cerchiamo di apprezzare quanto incredibilmente improbabile sia stato il risultato che ha sperimentato. Simuleremo l’atto di lanciare 92 monete imparziali utilizzando un generatore pseudo-casuale. Le teste saranno codificate come 1 e le croci come 0. Registriamo il valore medio dei 92 risultati. Il valore medio è la frazione di volte in cui la moneta è uscita testa. Ripeteremo questo esperimento diecimila volte per ottenere diecimila medie di 92 lanci di moneta e rappresenteremo la loro distribuzione di frequenza. Dopo aver completato questo esercizio, otterremo il seguente tipo di istogramma:
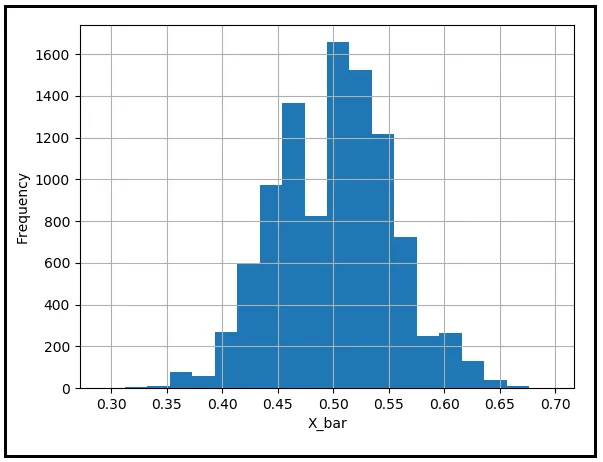
Vediamo che la maggior parte delle medie del campione è raggruppata intorno alla media della popolazione di 0.5. Il risultato di Guildenstern — ottenere 92 teste di fila — è un risultato eccezionalmente improbabile. Pertanto, la frequenza di questo risultato è anche estremamente bassa. Ma contrariamente alle paure di Guildenstern, non c’è nulla di innaturale nel risultato e le leggi della probabilità continuano a operare con il loro solito entusiasmo. Il risultato di Guildenstern si nasconde semplicemente nelle regioni remote della coda sinistra del grafico, aspettando con infinita pazienza di colpire qualche sfortunato lanciatore di monete la cui unica colpa è stata essere incredibilmente sfortunato.
Riferimenti e Diritti d’Autore
Set di dati
Il set di dati sulla temperatura superficiale del mare in tempo reale nell’Atlantico Nord-Est è stato scaricato da DATA.GOV.IE sotto la licenza CC BY 4.0
Immagini
Tutte le immagini in questo articolo sono di proprietà di Sachin Date secondo la licenza CC-BY-NC-SA, a meno che non venga indicata una diversa fonte e diritto d’autore sotto l’immagine stessa.
Grazie per aver letto! Se ti è piaciuto questo articolo, ti invito a seguirmi per ricevere consigli, guide e consigli di programmazione sull’analisi di regressione e di serie temporali.