Un eccellente risorsa per imparare le fondamenta di tutto ciò che sta sotto ChatGPT
Una risorsa eccellente per imparare le fondamenta di ChatGPT e tutto ciò che c'è sotto

OpenAI, ChatGPT, la serie GPT e i Large Language Models (LLM) in generale – se sei remotamente associato alla professione di intelligenza artificiale o a un tecnologo, è molto probabile che sentirai queste parole in quasi tutte le tue conversazioni di lavoro di questi giorni.
E l’hype è reale. Non possiamo più chiamarlo una bolla. Dopotutto, questa volta l’hype mantiene le sue promesse.
Chi l’avrebbe mai detto che le macchine potessero capire e rispondere con un’intelligenza simile a quella umana e fare quasi tutti quei compiti precedentemente considerati prerogativa umana, comprese applicazioni creative di musica, scrittura di poesie e persino programmazione di applicazioni?
- Navigare i formati dei dati con Pandas per principianti
- Come ottimizzare le istruzioni del codice LLM senza dati GPT4? Incontra OctoPack un insieme di modelli di intelligenza artificiale per l’ottimizzazione delle istruzioni dei grandi modelli di linguaggio del codice.
- Errore di Snapchat scatena il panico la mia IA pubblica storie e immagini misteriose
La pervasiva proliferazione di LLM nelle nostre vite ci ha resi tutti curiosi di ciò che si nasconde dietro questa potente tecnologia.
Quindi, se ti stai trattenendo a causa dei dettagli che sembrano spaventosi degli algoritmi e delle complessità del campo dell’intelligenza artificiale, ti consiglio vivamente questa risorsa per imparare tutto su “Cosa fa ChatGPT… e perché funziona?”
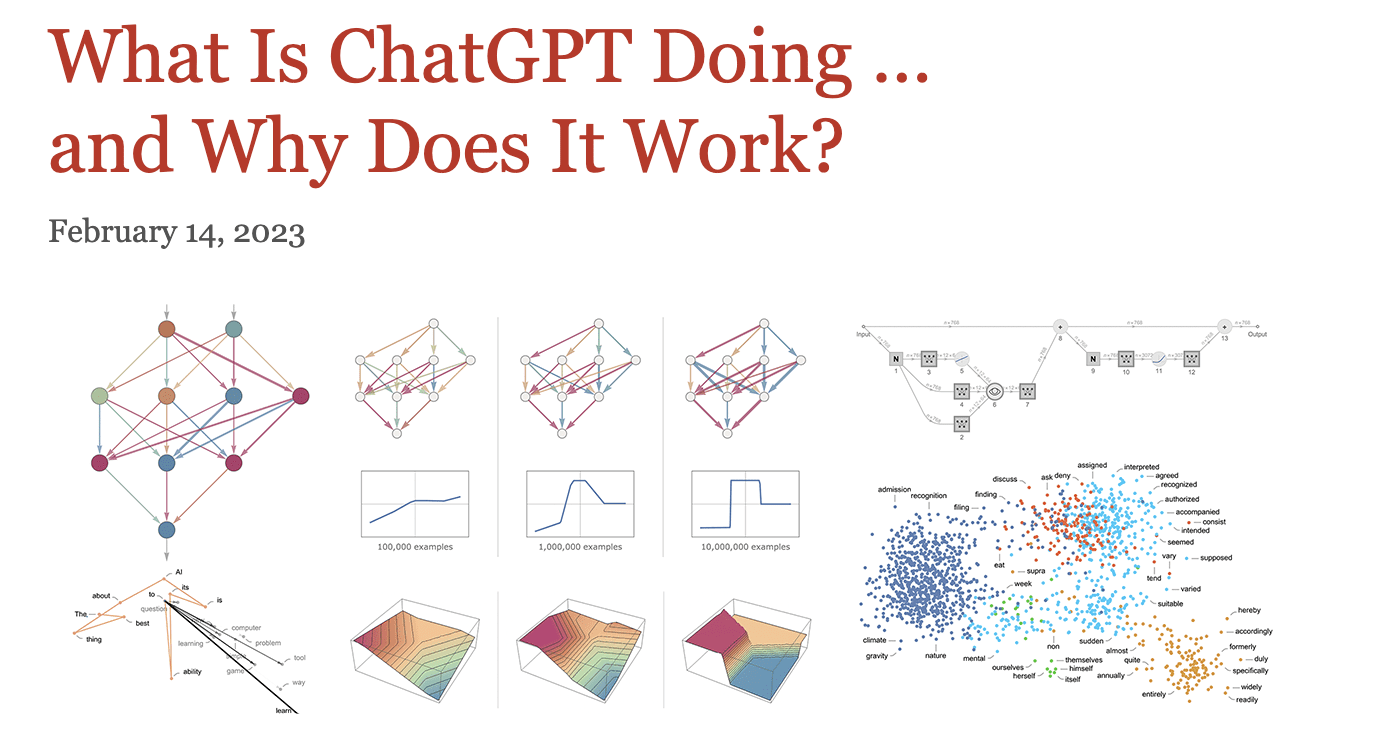
Sì, questo è il titolo dell’articolo di Wolfram.
Perché sto raccomandando questo? Perché è fondamentale comprendere gli elementi essenziali del machine learning e come le reti neurali profonde sono correlate ai cervelli umani prima di approfondire gli argomenti sui Transformers, LLM o persino l’AI generativa.
Sembra quasi un mini-libro che è letteratura di per sé, ma prenditi il tuo tempo con la lunghezza di questa risorsa.
In questo articolo, condividerò come iniziare a leggerlo per rendere i concetti più facili da comprendere.
Comprendere il ‘Modello’ è Cruciale
Il suo punto forte è focalizzato sulla parte del ‘modello’ dei “Large Language Models”, illustrata da un esempio del tempo che impiega una pallina a raggiungere il suolo da ciascun piano.
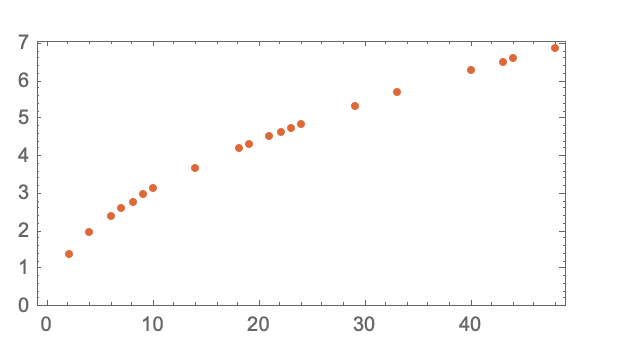
Ci sono due modi per ottenere questo – ripetere questo esercizio da ogni piano oppure costruire un modello che possa calcolarlo.
In questo esempio, esiste una formulazione matematica sottostante che rende più facile il calcolo, ma come si potrebbe stimare un tale fenomeno utilizzando un ‘modello’?
La scommessa migliore sarebbe adattare una linea retta per stimare la variabile di interesse, in questo caso il tempo.
Una lettura più approfondita di questa sezione spiegherebbe che non esiste mai un “modello senza modello”, il che ti porta senza soluzione di continuità ai vari concetti di deep learning.
Il Cuore del Deep Learning
Imparerai che un modello è una funzione complessa che prende certe variabili in ingresso e produce un’uscita, ad esempio un numero nei compiti di riconoscimento dei numeri.
L’articolo passa dal riconoscimento dei numeri al classificatore tipico gatto vs. cane per spiegare chiaramente quali caratteristiche vengono selezionate da ogni livello, a partire dalla silhouette del gatto. In particolare, i primi livelli di una rete neurale individuano alcuni aspetti delle immagini, come i contorni degli oggetti.

Terminologia Chiave
Oltre a spiegare il ruolo di più livelli, vengono anche spiegate diverse sfaccettature degli algoritmi di deep learning, come:
Architettura delle Reti Neurali
È una combinazione di arte e scienza, dice il post – “Ma per lo più le cose sono state scoperte per tentativi ed errori, aggiungendo idee e trucchi che hanno costruito progressivamente una significativa tradizione su come lavorare con le reti neurali”.
Epoche
Le epoche sono un modo efficace per far ricordare al modello un esempio particolare.
Dato che ripetere lo stesso esempio più volte non è sufficiente, è importante mostrare diverse varianti degli esempi alla rete neurale.
Pesi (Parametri)
Avrai sentito dire che uno dei LLM ha ben 175 miliardi di parametri. Bene, questo mostra come la struttura del modello varia in base a come vengono regolati i suoi “pulsanti”.
In sostanza, i parametri sono i “pulsanti che puoi girare” per adattare i dati. Il post mette in evidenza che il vero processo di apprendimento delle reti neurali consiste nel trovare i pesi giusti: “Alla fine, si tratta di determinare quali pesi cattureranno al meglio gli esempi di addestramento forniti”.
Generalizzazione
Le reti neurali imparano a “interpolare tra gli esempi mostrati in modo ragionevole”.
Questa generalizzazione aiuta a prevedere record non visti imparando da più esempi di input-output.
Funzione di Perdita
Ma come possiamo sapere cosa è ragionevole? Questo è definito da quanto i valori di output si discostano dai valori attesi, che sono racchiusi nella funzione di perdita.
Ci fornisce una “distanza tra i valori che abbiamo ottenuto e i valori veri”. Per ridurre questa distanza, i pesi vengono regolati iterativamente, ma deve esserci un modo per ridurre sistematicamente i pesi in una direzione che prenda il percorso più breve.
Discesa del Gradiente
Trovare il percorso più ripido per scendere in un paesaggio di pesi è chiamato discesa del gradiente.
Si tratta di trovare i pesi corretti che rappresentano al meglio la verità fondamentale navigando nel paesaggio di pesi.
Backpropagation
Continua a leggere il concetto di backpropagation, che prende la funzione di perdita e lavora all’indietro per trovare progressivamente i pesi per minimizzare la perdita associata.
Iperparametri
Oltre ai pesi (chiamati anche parametri), ci sono iperparametri che includono diverse scelte della funzione di perdita, minimizzazione della perdita o persino la scelta di quanto grandi dovrebbero essere un “batch” di esempi.
Reti Neurali per Problemi Complessi
L’uso di reti neurali per problemi complessi è ampiamente discusso. Tuttavia, la logica alla base di tale assunzione era poco chiara fino a questo post, che spiega come molteplici variabili di peso in uno spazio ad alta dimensione consentano varie direzioni che possono portare al minimo.
Confronta ora questo con meno variabili, che implica la possibilità di rimanere bloccati in un minimo locale senza una direzione per uscirne.
Conclusioni
Con questa lettura, abbiamo coperto molta strada, dalla comprensione del modello e di come funzionano i cervelli umani, fino ad arrivare alle reti neurali, al loro design e alle terminologie associate.
Rimani sintonizzato per un post successivo su come costruire su questa conoscenza per comprendere come funziona chatgpt. Vidhi Chugh è una stratega di intelligenza artificiale e una leader nella trasformazione digitale che lavora all’incrocio tra prodotto, scienze e ingegneria per costruire sistemi di apprendimento automatico scalabili. È una leader dell’innovazione premiata, un’autrice e una relatrice internazionale. È in missione per democratizzare l’apprendimento automatico e rompere il gergo affinché tutti possano far parte di questa trasformazione.






