Rilevazione di anomalie temporali nel mondo reale tramite apprendimento automatico supervisionato e teoria degli insiemi
Detection of real-world temporal anomalies through supervised machine learning and set theory
Sentiero Burke Gilman di Seattle
Esplora i dati aperti della città di Seattle
Indice:
I. Problema dichiarato
- Un eccellente risorsa per imparare le fondamenta di tutto ciò che sta sotto ChatGPT
- Navigare i formati dei dati con Pandas per principianti
- Come ottimizzare le istruzioni del codice LLM senza dati GPT4? Incontra OctoPack un insieme di modelli di intelligenza artificiale per l’ottimizzazione delle istruzioni dei grandi modelli di linguaggio del codice.
II. Trasformazione delle serie temporali in un problema supervisionato
III. Modellazione e analisi supervisionata
I. Problema dichiarato
I dati possono essere scaricati da qui: Sentiero Burke Gilman di Seattle | Kaggle
La sostanza di questo problema è che dobbiamo rilevare anomalie con 3 ore di anticipo. Un’anomalia è definita come >500 persone totali sul sentiero tra 3 ore. Per risolvere questo problema, ci sono stati forniti dati per ogni ora del traffico sul sentiero – pedoni e biciclette.
II. Trasformazione delle serie temporali in un problema supervisionato
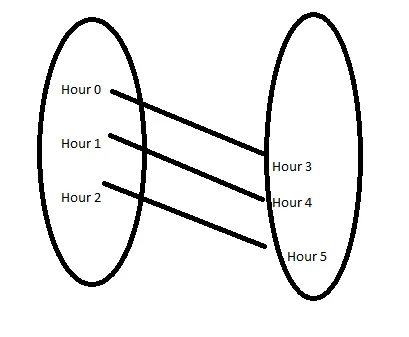
Quindi quello che possiamo fare è fare due copie dei dati e poi possiamo unire i dati in modo che l’ora 0 corrisponda all’ora 3 sulla stessa riga.
Come si fa?
Prima, importiamo i dati:
import pandas as pddf = pd.read_csv(r’/content/burke-gilman-trail-north-of-ne-70th-st-bike-and-ped-counter.csv’)Successivamente:
# cambia df in dataframe
df = pd.DataFrame(df)
df = df.fillna(0)Una volta fatto questo, facciamo una copia dei nostri dati che inizia dalla riga 3:
# crea df2 che inizia dalla 4a riga
df2 = df[df.index >= 3]
df2.head()Ora, aggiungeremo una colonna di indice a entrambi i dataframes che inizia da 1:
# aggiungi una colonna numerica sia a df1 che a df2. la prima riga dovrebbe essere 1, la seconda riga è 2 e così via. Entrambe le colonne dei dataframes dovrebbero iniziare da 1
df['index'] = list(range(1, len(df) + 1))
df2['index'] = list(range(1, len(df2) + 1))Il motivo per cui facciamo questo è per poter unire sulla colonna di indice. L’indice 1 si unirà all’indice 1 di df2, ma su quella riga, vedremo l’ora 0 sul lato sinistro e l’ora 3 sul lato destro…






