Approfondimento sul modalità Copy-on-Write di pandas – Parte II
Approfondimento Copy-on-Write di pandas - Parte II
Spiegazione di come la Copia su Scrittura ottimizza le prestazioni

Introduzione
Il primo post ha spiegato come funziona il meccanismo della Copia su Scrittura. Mette in evidenza alcune aree in cui vengono introdotte copie nel flusso di lavoro. Questo post si concentrerà sulle ottimizzazioni che garantiscono che ciò non rallenti il flusso di lavoro medio.
Utilizziamo una tecnica che gli interni di pandas utilizzano per evitare di copiare l’intero DataFrame quando non è necessario e, di conseguenza, aumentare le prestazioni.
Faccio parte del team principale di pandas e sono stato fortemente coinvolto nell’implementazione e nel miglioramento della Copia su Scrittura finora. Sono un ingegnere open source per Coiled, dove lavoro su Dask, incluso il miglioramento dell’integrazione con pandas e garantendo che Dask sia conforme alla Copia su Scrittura.
Rimozione delle copie difensive
Iniziamo con il miglioramento più impattante. Molti metodi di pandas eseguono copie difensive per evitare effetti collaterali e proteggere dalle modifiche inplace in seguito.
- Tabnine presenta Tabnine Chat un’applicazione di chat di livello aziendale, incentrata sul codice, in fase beta che consente agli sviluppatori di interagire con i modelli di intelligenza artificiale di Tabnine utilizzando il linguaggio naturale.
- Come utilizzare l’API PaLM 2 di Google con Python
- Cosa imparare in Data Science (2023)
df = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})df2 = df.reset_index()df2.iloc[0, 0] = 100Non c’è bisogno di copiare i dati in reset_index, ma restituire una vista introdurrebbe effetti collaterali quando si modifica il risultato, ad esempio df verrebbe aggiornato. Pertanto, viene eseguita una copia difensiva in reset_index.
Tutte queste copie difensive non sono più presenti quando la Copia su Scrittura è abilitata. Questo influisce su molti metodi. Un elenco completo può essere trovato qui.
Inoltre, la selezione di un sottoinsieme di colonne di un DataFrame restituirà sempre una vista anziché una copia come prima.
Vediamo cosa significa in termini di prestazioni quando combiniamo alcuni di questi metodi:
import pandas as pdimport numpy as npN = 2_000_000int_df = pd.DataFrame( np.random.randint(1, 100, (N, 10)), columns=[f"col_{i}" for i in range(10)],)float_df = pd.DataFrame( np.random.random((N, 10)), columns=[f"col_{i}" for i in range(10, 20)],)str_df = pd.DataFrame( "a", index=range(N), columns=[f"col_{i}" for i in range(20, 30)],)df = pd.concat([int_df, float_df, str_df], axis=1)Questo crea un DataFrame con 30 colonne, 3 diversi tipi di dati e 2 milioni di righe. Eseguiamo la seguente catena di metodi su questo DataFrame:
%%timeit( df.rename(columns={"col_1": "new_index"}) .assign(sum_val=df["col_1"] + df["col_2"]) .drop(columns=["col_10", "col_20"]) .astype({"col_5": "int32"}) .reset_index() .set_index("new_index"))Tutti questi metodi eseguono una copia difensiva senza la Copia su Scrittura abilitata.
Prestazioni senza la Copia su Scrittura:
2,45 s ± 293 ms per loop (media ± deviazione standard di 7 run, 1 loop ciascuno)Prestazioni con la Copia su Scrittura abilitata:
13,7 ms ± 286 µs per loop (media ± deviazione standard di 7 run, 100 loop ciascuno)Un miglioramento di circa un fattore di 200. Ho scelto questo esempio appositamente per illustrare i potenziali vantaggi della Copia su Scrittura. Non tutti i metodi diventeranno così molto più veloci.
Ottimizzazione delle copie innescate da modifiche inplace
La sezione precedente ha illustrato molti metodi in cui una copia difensiva non è più necessaria. La Copia su Scrittura garantisce che non si possano modificare contemporaneamente due oggetti. Ciò significa che dobbiamo introdurre una copia quando gli stessi dati sono referenziati da due DataFrame. Vediamo le tecniche per rendere queste copie il più efficienti possibile.
L’articolo precedente ha mostrato che il seguente codice potrebbe generare una copia:
df.iloc[0, 0] = 100La copia viene generata se i dati che supportano df sono referenziati da un altro DataFrame. Assumiamo che il nostro DataFrame abbia n colonne di interi, ad esempio è supportato da un unico blocco.
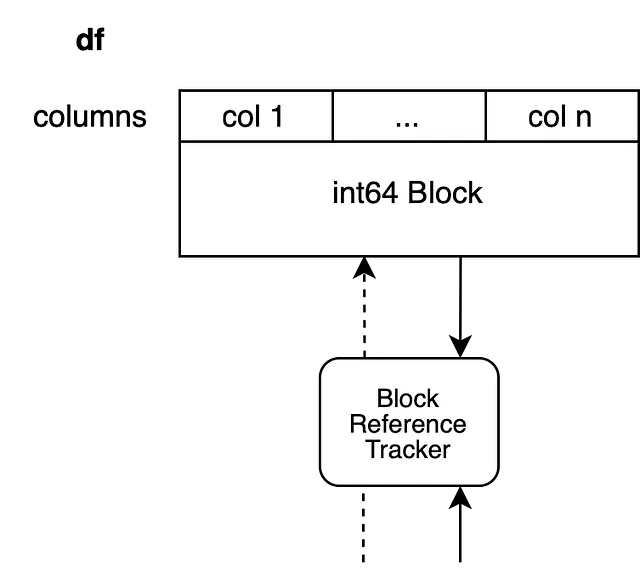
Il nostro oggetto di tracciamento dei riferimenti sta anche referenziando un altro blocco, quindi non possiamo modificare il DataFrame sul posto senza modificare un altro oggetto. Un approccio ingenuo sarebbe copiare l’intero blocco e terminare.
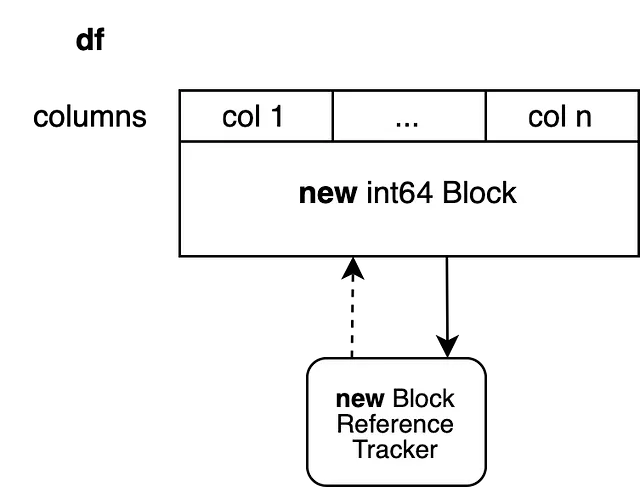
In questo modo viene impostato un nuovo oggetto di tracciamento dei riferimenti e viene creato un nuovo blocco supportato da un nuovo array NumPy. Questo blocco non ha più referenze, quindi un’altra operazione potrebbe modificarlo di nuovo sul posto. Questo approccio copia n-1 colonne che non è necessario copiare. Utilizziamo una tecnica che chiamiamo “Block splitting” per evitarlo.
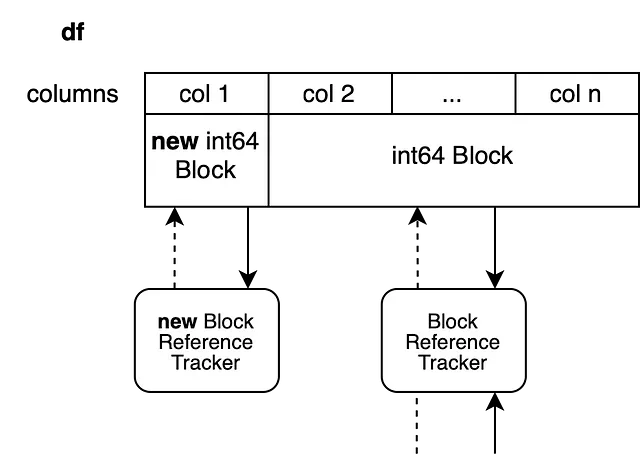
Internamente, viene copiata solo la prima colonna. Tutte le altre colonne sono prese come visualizzazioni dell’array precedente. Il nuovo blocco non condivide referenze con altre colonne. Il vecchio blocco condivide ancora referenze con altri oggetti poiché è solo una visualizzazione dei valori precedenti.
C’è uno svantaggio in questa tecnica. L’array iniziale ha n colonne. Abbiamo creato una visualizzazione delle colonne da 2 a n, ma questo mantiene vivo l’intero array. Abbiamo anche aggiunto un nuovo array con una colonna per la prima colonna. Questo manterrà un po’ più memoria viva del necessario.
Questo sistema si applica direttamente ai DataFrame con diversi dtypes. Tutti i blocchi che non vengono modificati vengono restituiti così come sono e solo i blocchi che vengono modificati sul posto vengono divisi.
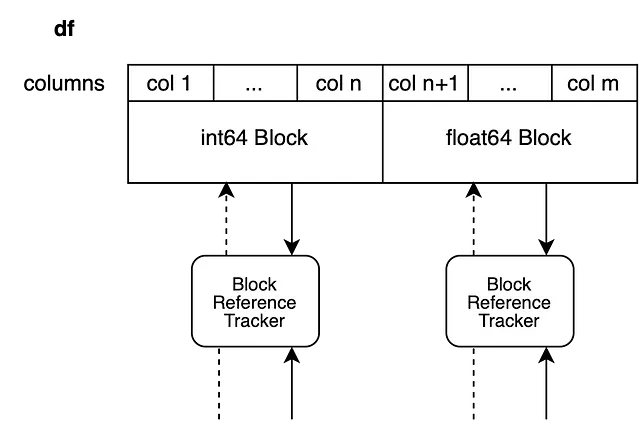
Ora impostiamo un nuovo valore nella colonna n+1 del blocco float per creare una visualizzazione delle colonne da n+2 a m. Il nuovo blocco supporterà solo la colonna n+1.
df.iloc[0, n+1] = 100.5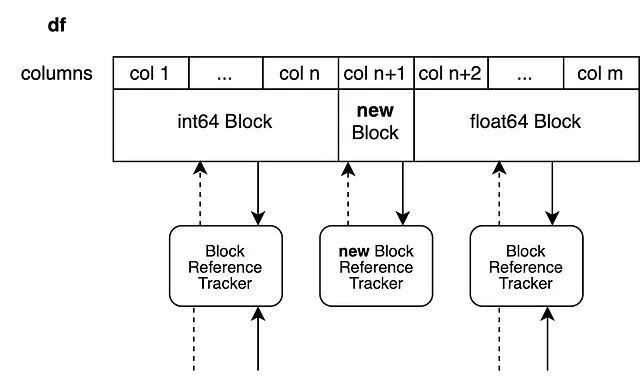
Metodi che possono operare sul posto
Le operazioni di indicizzazione che abbiamo esaminato in genere non creano un nuovo oggetto; modificano l’oggetto esistente sul posto, inclusi i dati di detto oggetto. Un altro gruppo di metodi di pandas non tocca affatto i dati del DataFrame. Un esempio prominente è rename. Rename cambia solo le etichette. Questi metodi possono utilizzare il meccanismo di copia pigra menzionato in precedenza.
C’è un altro terzo gruppo di metodi che possono effettivamente essere eseguiti sul posto, come replace o fillna. Questi attiveranno sempre una copia.
df2 = df.replace(...)Modificare i dati sul posto senza attivare una copia modificherebbe df e df2, violando le regole di CoW. Questo è uno dei motivi per cui consideriamo di mantenere la parola chiave inplace per questi metodi.
df.replace(..., inplace=True)Questo eliminerebbe questo problema. È ancora una proposta aperta e potrebbe prendere una direzione diversa. Detto questo, ciò riguarda solo le colonne effettivamente modificate; tutte le altre colonne vengono comunque restituite come visualizzazioni. Ciò significa che viene copiata solo una colonna se il valore viene trovato solo in una colonna.
Conclusioni
Investighiamo come CoW cambia il comportamento interno di pandas e come ciò si tradurrà in miglioramenti nel tuo codice. Molti metodi diventeranno più veloci con CoW, mentre vedremo un rallentamento in un paio di operazioni relative all’indicizzazione. In precedenza, queste operazioni agivano sempre in modo inplace, il che poteva causare effetti collaterali. Questi effetti collaterali scompaiono con CoW e una modifica su un oggetto DataFrame non avrà mai un impatto su un altro.
Il prossimo post di questa serie spiegherà come puoi aggiornare il tuo codice per essere conforme a CoW. Inoltre, spiegheremo quali pattern evitare in futuro.
Grazie per aver letto. Non esitare a contattarci per condividere le tue opinioni e feedback su Copy-on-Write.






