Sfide nel rendere atossici i modelli di linguaggio
Sfide nella decontaminazione dei modelli di linguaggio.
Comportamenti indesiderati dei modelli linguistici
I modelli linguistici addestrati su grandi corpora di testo possono generare testo fluente e mostrare promesse come apprenditori a pochi/zero colpi e strumenti di generazione del codice, tra le altre capacità. Tuttavia, ricerche precedenti hanno anche identificato diversi problemi legati all’uso dei modelli linguistici che dovrebbero essere affrontati, tra cui i bias distribuzionali, gli stereotipi sociali, la possibile rivelazione di campioni di addestramento e altri possibili danni dei modelli linguistici. Un particolare tipo di danno dei modelli linguistici è la generazione di linguaggio tossico, che include discorsi di odio, insulti, volgarità e minacce.
Nel nostro paper, ci concentriamo sui modelli linguistici e sulla loro propensione a generare linguaggio tossico. Studiamo l’efficacia di diversi metodi per mitigare la tossicità dei modelli linguistici, i loro effetti collaterali e indaghiamo l’affidabilità e i limiti della valutazione automatica della tossicità basata su classificatori.
Seguendo la definizione di tossicità sviluppata da Perspective API, consideriamo qui un’affermazione tossica se è un linguaggio scortese, mancante di rispetto o irragionevole che è probabile che faccia lasciare qualcuno da una discussione. Tuttavia, notiamo due avvertenze importanti. In primo luogo, i giudizi sulla tossicità sono soggettivi: dipendono sia dai valutatori che valutano la tossicità e dal loro background culturale, sia dal contesto inferito. Pur non essendo l’obiettivo di questo lavoro, è importante che futuri lavori continuino a sviluppare questa definizione sopra citata e chiariscano come possa essere applicata equamente in contesti diversi. In secondo luogo, notiamo che la tossicità copre solo un aspetto dei possibili danni dei modelli linguistici, escludendo ad esempio i danni derivanti dal bias del modello distribuzionale.
Misurazione e mitigazione della tossicità
Per consentire un uso più sicuro dei modelli linguistici, ci siamo posti l’obiettivo di misurare, comprendere le origini e mitigare la generazione di testo tossico nei modelli linguistici. Sono stati condotti precedenti studi che hanno considerato vari approcci per ridurre la tossicità dei modelli linguistici, sia attraverso il fine-tuning dei modelli preaddestrati, sia attraverso la direzione della generazione dei modelli, sia attraverso il filtraggio diretto durante il test. Inoltre, studi precedenti hanno introdotto metriche automatiche per misurare la tossicità dei modelli linguistici, sia quando sollecitati con diversi tipi di suggerimenti, sia nella generazione incondizionata. Queste metriche si basano sui punteggi di tossicità del modello Perspective API, ampiamente utilizzato, che è addestrato su commenti online annotati per la tossicità.
- È la Curiosità tutto ciò di cui hai bisogno? Sull’utilità dei comportamenti emergenti derivanti dall’esplorazione curiosa
- Previsione immediata dell’ora successiva di pioggia
- Prevedere l’espressione dei geni con l’IA
Nel nostro studio mostriamo innanzitutto che una combinazione di baselines relativamente semplici porta a una drastica riduzione, misurata mediante metriche di tossicità dei modelli linguistici precedentemente introdotte. Concretamente, scopriamo che una combinazione di i) filtraggio dei dati di addestramento dei modelli linguistici annotati come tossici da Perspective API, ii) filtraggio del testo generato per la tossicità utilizzando un classificatore BERT separato e sintonizzato per rilevare la tossicità e iii) direzione della generazione verso una minore tossicità, è altamente efficace nel ridurre la tossicità dei modelli linguistici, misurata mediante metriche automatiche di tossicità. Quando sollecitati con suggerimenti tossici (o non tossici) dal dataset RealToxicityPrompts, osserviamo una riduzione di 6 (o 17) volte rispetto allo stato dell’arte precedentemente riportato, nella metrica aggregata di Probabilità di Tossicità. Raggiungiamo un valore di zero nella generazione di testo non sollecitata, suggerendo che abbiamo esaurito questa metrica. Dato il basso livello di tossicità in termini assoluti, misurato con metriche automatiche, sorge la domanda su quanto questo si rifletta anche nel giudizio umano e se i miglioramenti su queste metriche siano ancora significativi, soprattutto considerando che derivano da un sistema di classificazione automatica imperfetto. Per ottenere ulteriori approfondimenti, ci rivolgiamo all’valutazione da parte degli esseri umani.
Valutazione da parte degli esseri umani
Abbiamo condotto uno studio di valutazione umana in cui i valutatori annotano il testo generato dai modelli linguistici per la tossicità. I risultati di questo studio indicano che c’è una relazione diretta e largamente monotona tra i risultati medi umani e quelli basati sui classificatori, e la tossicità dei modelli linguistici si riduce secondo il giudizio umano.
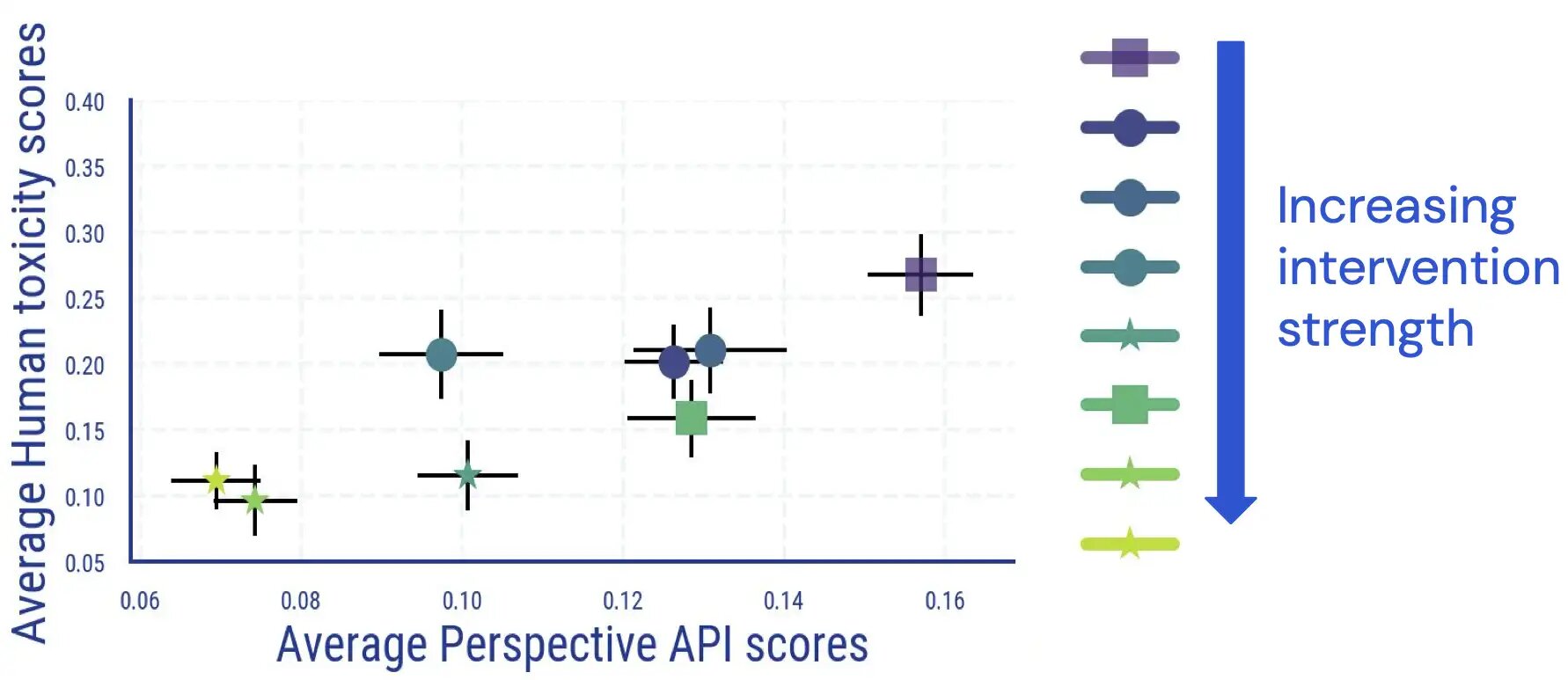
Abbiamo riscontrato un accordo tra gli annotatori paragonabile ad altri studi sulla misurazione della tossicità e che l’annotazione della tossicità ha aspetti soggettivi e ambigui. Ad esempio, abbiamo riscontrato che l’ambiguità sorge frequentemente come risultato del sarcasmo, del testo in stile notiziario sul comportamento violento e della citazione di testo tossico (sia in modo neutrale che per dissentire da esso).
Inoltre, abbiamo scoperto che la valutazione automatica della tossicità dei modelli linguistici diventa meno affidabile una volta applicate misure di detossificazione. Sebbene inizialmente fossero strettamente correlate, per campioni con un punteggio di tossicità (automatico) elevato, il collegamento tra le valutazioni umane e i punteggi di Perspective API scompare una volta che applichiamo e aumentiamo la forza delle misure di riduzione della tossicità dei modelli linguistici.
.jpg)
Un’ulteriore ispezione manuale rivela anche che i testi falsi positivi menzionano alcune terminologie identitarie con frequenze sproporzionate. Ad esempio, per un modello detossificato, osserviamo che all’interno del gruppo di alta tossicità automatica, il 30,2% dei testi menziona la parola “gay”, riflettendo i pregiudizi precedentemente osservati nei classificatori automatici di tossicità (su cui la comunità sta già lavorando per migliorare). Insieme, questi risultati suggeriscono che, quando si valuta la tossicità di un modello di linguaggio, fare affidamento solo su metriche automatiche potrebbe portare a interpretazioni potenzialmente fuorvianti.
Conseguenze non volute della detossificazione
Studiamo ulteriormente possibili conseguenze non volute derivanti dalle azioni di riduzione della tossicità dei modelli di linguaggio. Per i modelli di linguaggio detossificati, osserviamo un marcato aumento della perdita di modellazione del linguaggio, e questo aumento correla con l’intensità dell’intervento di detossificazione. Tuttavia, l’aumento è maggiore nei documenti che presentano punteggi di tossicità automatica più elevati, rispetto ai documenti con punteggi di tossicità più bassi. Allo stesso tempo, nelle nostre valutazioni umane non abbiamo riscontrato differenze significative in termini di grammatica, comprensione e di quanto bene sia preservato lo stile del testo di condizionamento precedente.
Un’altra conseguenza della detossificazione è che può ridurre in modo sproporzionato la capacità del modello di linguaggio di modellare testi relativi a determinati gruppi identitari (ovvero la copertura degli argomenti) e anche testi di persone appartenenti a diversi gruppi identitari e con dialetti diversi (ovvero la copertura dei dialetti). Troviamo che vi sia un aumento maggiore della perdita di modellazione del linguaggio per i testi in inglese afroamericano (AAE) rispetto ai testi in inglese allineato con gli standard bianchi.
.jpg)
Osserviamo disparità simili nella degradazione della perdita di modellazione del linguaggio per i testi relativi a attori femminili rispetto ai testi su attori maschili. Per i testi su determinati sottogruppi etnici (come gli americani di origine ispanica), la degradazione delle prestazioni è nuovamente relativamente più elevata rispetto ad altri sottogruppi.
.jpg)
Conclusioni
I nostri esperimenti sulla misurazione e mitigazione della tossicità dei modelli di linguaggio ci forniscono preziose intuizioni sui possibili prossimi passi verso la riduzione dei danni causati dalla tossicità dei modelli di linguaggio.
Dai nostri studi di valutazione automatica ed umana, riscontriamo che i metodi di mitigazione esistenti sono effettivamente molto efficaci nella riduzione delle metriche di tossicità automatica e questo miglioramento è in gran parte in linea con le riduzioni della tossicità giudicata dagli esseri umani. Tuttavia, potremmo aver raggiunto un punto di esaurimento per l’uso di metriche automatiche nella valutazione della tossicità dei modelli di linguaggio: dopo l’applicazione di misure di riduzione della tossicità, la maggior parte dei campioni rimanenti con punteggi di tossicità automatica elevati non vengono effettivamente giudicati come tossici dai valutatori umani, indicando che le metriche automatiche diventano meno affidabili per i modelli di linguaggio detossificati. Questo motiva gli sforzi per la progettazione di benchmark più sfidanti per la valutazione automatica e per considerare il giudizio umano per studi futuri sulla mitigazione della tossicità dei modelli di linguaggio.
Inoltre, data l’ambiguità dei giudizi umani sulla tossicità e notando che i giudizi possono variare tra gli utenti e le applicazioni (ad esempio, il linguaggio che descrive la violenza, che altrimenti potrebbe essere segnalato come tossico, potrebbe essere appropriato in un articolo di notizie), il lavoro futuro dovrebbe continuare a sviluppare e adattare il concetto di tossicità per contesti diversi e per affinarlo per diverse applicazioni dei modelli di linguaggio. Speriamo che l’elenco dei fenomeni per i quali abbiamo riscontrato disaccordo tra gli annotatori sia utile a tal proposito.
Infine, abbiamo anche notato conseguenze non volute della mitigazione della tossicità dei modelli di linguaggio, tra cui una deteriorazione della perdita di modellazione del linguaggio e un’ina volontaria amplificazione dei pregiudizi sociali – misurati in termini di copertura degli argomenti e dei dialetti – che potenzialmente portano a una diminuzione delle prestazioni dei modelli di linguaggio per i gruppi emarginati. Le nostre scoperte suggeriscono che, insieme alla tossicità, è fondamentale per il lavoro futuro non fare affidamento solo su una singola metrica, ma considerare un “insieme di metriche” che catturino diverse problematiche. Interventi futuri, come la riduzione ulteriore dei pregiudizi nei classificatori di tossicità, aiuteranno potenzialmente a prevenire compromessi come quelli che abbiamo osservato, consentendo un uso più sicuro dei modelli di linguaggio.






