Progressi nella comprensione dei documenti
Progressi documentali
Pubblicato da Sandeep Tata, Ingegnere Software, Google Research, Team Athena
Negli ultimi anni abbiamo assistito a un rapido progresso nei sistemi in grado di elaborare automaticamente documenti aziendali complessi e trasformarli in oggetti strutturati. Un sistema in grado di estrarre automaticamente dati dai documenti, ad esempio ricevute, preventivi assicurativi e rendiconti finanziari, ha il potenziale per migliorare drasticamente l’efficienza dei flussi di lavoro aziendali evitando il lavoro manuale soggetto a errori. Modelli recenti, basati sull’architettura Transformer, hanno mostrato guadagni impressionanti in termini di precisione. Modelli più grandi, come PaLM 2, vengono utilizzati anche per ottimizzare ulteriormente questi flussi di lavoro aziendali. Tuttavia, i set di dati utilizzati nella letteratura accademica non riescono a cogliere le sfide riscontrate nei casi d’uso del mondo reale. Di conseguenza, i benchmark accademici riportano una forte precisione del modello, ma questi stessi modelli hanno prestazioni scadenti quando vengono utilizzati per applicazioni complesse del mondo reale.
In “VRDU: A Benchmark for Visually-rich Document Understanding”, presentato a KDD 2023, annunciamo il rilascio del nuovo set di dati Visually Rich Document Understanding (VRDU) che mira a colmare questa lacuna e aiutare i ricercatori a monitorare meglio i progressi nelle attività di comprensione dei documenti. Elenchiamo cinque requisiti per un buon benchmark di comprensione dei documenti, basati sui tipi di documenti del mondo reale per i quali i modelli di comprensione dei documenti vengono frequentemente utilizzati. Successivamente, descriviamo come la maggior parte dei set di dati attualmente utilizzati dalla comunità di ricerca non soddisfa uno o più di questi requisiti, mentre VRDU li soddisfa tutti. Siamo entusiasti di annunciare il rilascio pubblico del set di dati VRDU e del codice di valutazione con licenza Creative Commons.
Requisiti del benchmark
Innanzitutto, abbiamo confrontato l’accuratezza dei modelli di ultima generazione (ad esempio, con FormNet e LayoutLMv2) nei casi d’uso del mondo reale con i benchmark accademici (ad esempio, FUNSD, CORD, SROIE). Abbiamo osservato che i modelli di ultima generazione non corrispondevano ai risultati dei benchmark accademici e fornivano un’accuratezza molto più bassa nel mondo reale. Successivamente, abbiamo confrontato i set di dati tipici per i quali i modelli di comprensione dei documenti vengono frequentemente utilizzati con i benchmark accademici e abbiamo identificato cinque requisiti del set di dati che consentono di catturare meglio la complessità delle applicazioni del mondo reale:
- Furto digitale” riconquista la Pietra di Rosetta
- Rinventare l’Utopia Comunità autogenerate per l’era digitale
- Big Tech e l’IA generativa Big Tech controllerà l’IA generativa?
- Schema ricco: Nella pratica, si osserva una grande varietà di schemi ricchi per l’estrazione strutturata. Le entità hanno diversi tipi di dati (numerici, stringhe, date, ecc.) che possono essere richiesti, facoltativi o ripetuti in un singolo documento o possono persino essere nidificati. I compiti di estrazione su schemi piatti semplici come (intestazione, domanda, risposta) non riflettono i problemi tipici riscontrati nella pratica.
- Documenti con layout complesso: I documenti dovrebbero avere elementi di layout complessi. Le sfide in contesti pratici derivano dal fatto che i documenti possono contenere tabelle, coppie chiave-valore, passare da un layout a una o due colonne, avere dimensioni del carattere variabili per diverse sezioni, includere immagini con didascalie e persino note a piè di pagina. Contrariamente ai set di dati in cui la maggior parte dei documenti è organizzata in frasi, paragrafi e capitoli con intestazioni di sezione, tipicamente oggetto della letteratura classica di elaborazione del linguaggio naturale su input lunghi.
- Template diversificati: Un benchmark dovrebbe includere layout o template strutturali diversi. Per un modello ad alta capacità, è banale estrarre da un template particolare memorizzando la struttura. Tuttavia, nella pratica, è necessario essere in grado di generalizzare a nuovi template/layout, una capacità che lo split di train-test in un benchmark dovrebbe misurare.
- OCR di alta qualità: I documenti dovrebbero avere risultati di riconoscimento ottico dei caratteri (OCR) di alta qualità. Il nostro obiettivo con questo benchmark è concentrarci sul compito VRDU stesso ed escludere la variabilità determinata dalla scelta del motore OCR.
- Annotationi a livello di token: I documenti dovrebbero contenere annotazioni di ground truth che possono essere mappate al testo di input corrispondente, in modo che ogni token possa essere annotato come parte dell’entità corrispondente. Questo è in contrasto con la semplice fornitura del testo del valore da estrarre per l’entità. Questo è fondamentale per generare dati di addestramento puliti in cui non dobbiamo preoccuparci di corrispondenze incidentali al valore dato. Ad esempio, in alcune ricevute, il campo ‘totale prima delle tasse’ può avere lo stesso valore del campo ‘totale’ se l’importo delle tasse è zero. L’annotazione a livello di token ci impedisce di generare dati di addestramento in cui entrambe le istanze del valore corrispondente sono contrassegnate come ground truth per il campo ‘totale’, generando così esempi rumorosi.
 |
Dataset e compiti VRDU
Il dataset VRDU è una combinazione di due dataset disponibili pubblicamente, Formulari di registrazione e Formulari di acquisto di annunci. Questi dataset forniscono esempi rappresentativi di casi d’uso reali e soddisfano i cinque requisiti di riferimento descritti in precedenza.
Il dataset dei Formulari di acquisto di annunci consiste in 641 documenti con dettagli di annunci politici. Ogni documento è una fattura o una ricevuta firmata da una stazione televisiva e un gruppo di campagna. I documenti utilizzano tabelle, colonne multiple e coppie chiave-valore per registrare le informazioni sull’annuncio, come il nome del prodotto, le date di trasmissione, il prezzo totale e la data e l’ora di pubblicazione.
Il dataset dei Formulari di registrazione consiste in 1915 documenti con informazioni su agenti stranieri che si registrano presso il governo degli Stati Uniti. Ogni documento registra informazioni essenziali sugli agenti stranieri coinvolti in attività che richiedono una divulgazione pubblica. I contenuti includono il nome del registrante, l’indirizzo degli uffici correlati, lo scopo delle attività e altri dettagli.
Abbiamo raccolto un campione casuale di documenti dai siti pubblici della Federal Communications Commission (FCC) e del Foreign Agents Registration Act (FARA) e abbiamo convertito le immagini in testo utilizzando l’OCR di Google Cloud. Abbiamo scartato un piccolo numero di documenti che avevano diverse pagine e il processo non è stato completato in meno di due minuti. Ciò ci ha anche permesso di evitare di inviare documenti molto lunghi per l’annotazione manuale, un compito che può richiedere oltre un’ora per un singolo documento. Successivamente, abbiamo definito lo schema e le istruzioni di etichettatura corrispondenti per un team di annotatori esperti in compiti di etichettatura documentale.
Gli annotatori hanno ricevuto anche alcuni documenti di esempio etichettati che abbiamo etichettato noi stessi. Il compito richiedeva agli annotatori di esaminare ogni documento, disegnare un riquadro intorno ad ogni occorrenza di un’entità dello schema per ogni documento e associare quel riquadro all’entità di destinazione. Dopo il primo round di etichettatura, un gruppo di esperti è stato incaricato di rivedere i risultati. I risultati corretti sono inclusi nel dataset VRDU pubblicato. Per ulteriori dettagli sul protocollo di etichettatura e lo schema per ciascun dataset, consultare l’articolo.
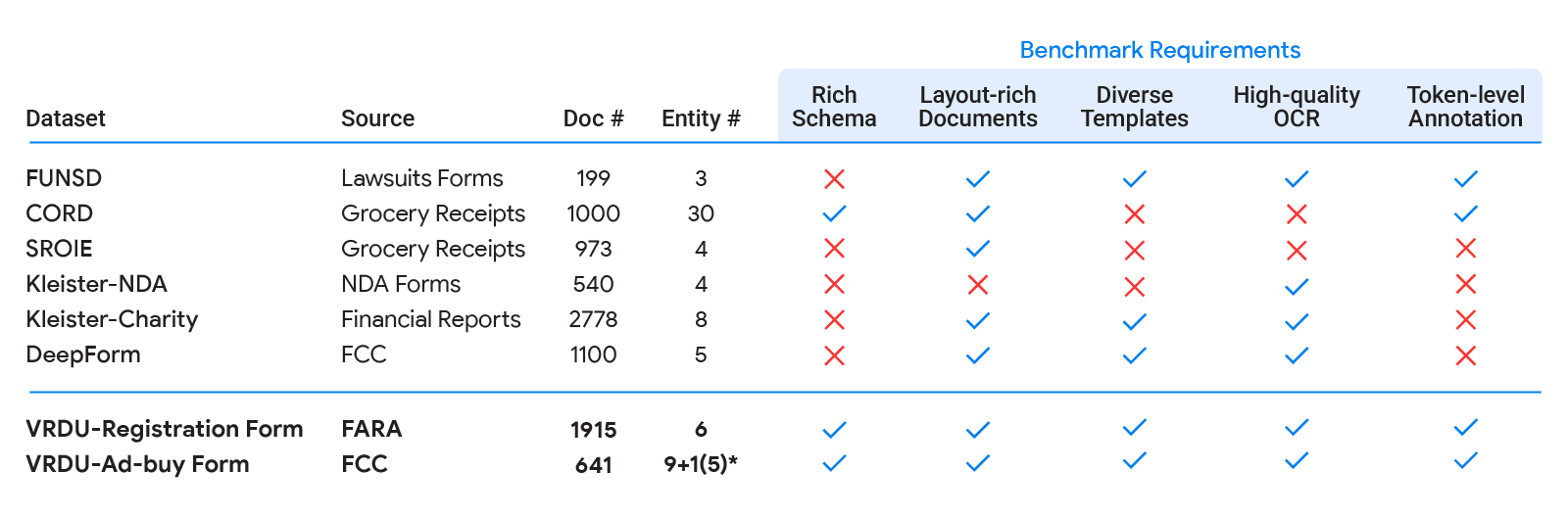 |
| I benchmark accademici esistenti (FUNSD, CORD, SROIE, Kleister-NDA, Kleister-Charity, DeepForm) non soddisfano uno o più dei cinque requisiti che abbiamo identificato per un buon benchmark di comprensione dei documenti. VRDU soddisfa tutti loro. Consultare il nostro articolo per maggiori dettagli su ciascuno di questi dataset e una discussione su come non riescono a soddisfare uno o più dei requisiti. |
Abbiamo creato quattro diversi set di addestramento del modello con rispettivamente 10, 50, 100 e 200 campioni. Successivamente, abbiamo valutato i dataset VRDU utilizzando tre compiti (descritti di seguito): (1) Apprendimento di un singolo modello, (2) Apprendimento di modelli misti e (3) Apprendimento di modelli inaspettati. Per ciascuno di questi compiti, abbiamo incluso 300 documenti nel set di test. Valutiamo i modelli utilizzando lo score F1 sul set di test.
- Apprendimento di un singolo modello (STL): Questo è lo scenario più semplice in cui i set di addestramento, test e convalida contengono solo un singolo modello. Questo semplice compito è progettato per valutare la capacità di un modello di gestire un modello fisso. Naturalmente, ci aspettiamo score F1 molto elevati (0,90+) per questo compito.
- Apprendimento di modelli misti (MTL): Questo compito è simile al compito che la maggior parte degli articoli correlati utilizza: i set di addestramento, test e convalida contengono tutti documenti appartenenti allo stesso insieme di modelli. Campioniamo casualmente documenti dai dataset e costruiamo le divisioni per assicurarci che la distribuzione di ogni modello non cambi durante il campionamento.
- Apprendimento di modelli inaspettati (UTL): Questa è l’impostazione più sfidante, in cui valutiamo se il modello può generalizzare a modelli non visti in precedenza. Ad esempio, nel dataset dei Formulari di registrazione, addestriamo il modello con due dei tre modelli e testiamo il modello con l’altro rimanente. I documenti nei set di addestramento, test e convalida sono tratti da insiemi di modelli disgiunti. A nostra conoscenza, i benchmark e i dataset precedenti non forniscono esplicitamente un compito del genere progettato per valutare la capacità del modello di generalizzare a modelli non visti durante l’addestramento.
L’obiettivo è quello di essere in grado di valutare i modelli in base alla loro efficienza dei dati. Nel nostro articolo, abbiamo confrontato due modelli recenti utilizzando i compiti STL, MTL e UTL e abbiamo fatto tre osservazioni. Primo, a differenza di altri benchmark, VRDU è impegnativo e mostra che i modelli hanno molto spazio per miglioramenti. Secondo, mostriamo che le prestazioni a pochi esempi, anche per modelli all’avanguardia, sono sorprendentemente basse, con i migliori modelli che producono uno score F1 inferiore a 0,60. Terzo, mostriamo che i modelli faticano a gestire campi strutturati ripetuti e ottengono risultati particolarmente scadenti su di essi.
Conclusioni
Rilasciamo il nuovo dataset Visually Rich Document Understanding (VRDU) che aiuta i ricercatori a monitorare meglio i progressi nei compiti di comprensione dei documenti. Descriviamo perché VRDU riflette meglio le sfide pratiche in questo campo. Presentiamo anche esperimenti che dimostrano che i compiti VRDU sono impegnativi e che i modelli recenti hanno un ampio margine di miglioramento rispetto ai dataset tipicamente utilizzati nella letteratura, con punteggi F1 superiori a 0,90 che sono tipici. Speriamo che il rilascio del dataset VRDU e del codice di valutazione aiuti i team di ricerca a avanzare lo stato dell’arte nella comprensione dei documenti.
Ringraziamenti
Molte grazie a Zilong Wang, Yichao Zhou, Wei Wei e Chen-Yu Lee, che hanno co-autorato l’articolo insieme a Sandeep Tata. Grazie a Marc Najork, Riham Mansour e numerosi partner di Google Research e del team Cloud AI per i preziosi contributi. Grazie a John Guilyard per la creazione delle animazioni in questo post.