Una modesta introduzione all’elaborazione analitica in streaming
Introduzione all'elaborazione analitica in streaming
Fondamenta architettoniche per la creazione di sistemi distribuiti affidabili.

Fondamenti del processing dei flussi
I fondamenti sono la base inossidabile e infrangibile su cui vengono posizionati gli edifici. Quando si tratta di costruire un’architettura dati di successo, i dati sono l’elemento centrale del sistema e il componente principale di quella base.
Dato il modo comune in cui i dati fluiscono ora nelle nostre piattaforme dati attraverso piattaforme di processing dei flussi come Apache Kafka e Apache Pulsar, è fondamentale assicurarci (come ingegneri del software) di fornire capacità igieniche e guide prive di attrito per ridurre lo spazio dei problemi legati alla qualità dei dati “dopo” che i dati sono entrati in queste reti di dati a flusso rapido. Ciò significa stabilire contratti a livello di API riguardanti lo schema dei dati (tipi e struttura), la disponibilità a livello di campo (nullable, ecc) e la validità del tipo di campo (intervalli previsti, ecc) diventano le basi fondamentali della nostra base dati, soprattutto data la natura decentralizzata e distribuita dei moderni sistemi dati di oggi.
Tuttavia, per arrivare al punto in cui possiamo anche iniziare a stabilire una fiducia cieca – o reti dati ad alta fiducia – dobbiamo prima stabilire modelli di progettazione intelligenti a livello di sistema.
Costruire sistemi di dati in streaming affidabili
Come ingegneri del software e dei dati, costruire sistemi di dati affidabili è letteralmente il nostro lavoro, e ciò significa che il tempo di inattività dei dati dovrebbe essere misurato come qualsiasi altro componente del business. Probabilmente hai già sentito parlare dei termini SLA, SLO e SLI in un momento o nell’altro. In poche parole, queste sigle sono associate ai contratti, alle promesse e alle misurazioni effettive con cui valutiamo i nostri sistemi end-to-end. Come responsabili del servizio, saremo chiamati a rispondere dei nostri successi e fallimenti, ma uno sforzo preliminare può fare molta strada, e i metadati acquisiti per garantire che le cose funzionino senza intoppi dal punto di vista operativo possono anche fornire preziose informazioni sulla qualità e sulla fiducia dei nostri dati in transito, riducendo anche il livello di sforzo per la risoluzione dei problemi relativi ai dati a riposo.
- Gorilla – Migliorare la capacità dei grandi modelli di linguaggio nell’utilizzo delle chiamate API
- Lo Zero Redundancy Optimizer (ZeRO) Una breve introduzione con Python
- Top 6 Strumenti per Migliorare la Tua Produttività su Snowflake
Adottare la mentalità del proprietario
Ad esempio, gli Accordi di Livello di Servizio (SLA) tra il tuo team o organizzazione e i tuoi clienti (interni ed esterni) vengono utilizzati per creare un contratto vincolante con riguardo al servizio che stai offrendo. Per i team di dati, ciò significa identificare e acquisire metriche (KPM – metriche di performance chiave) basate sui tuoi Obiettivi di Livello di Servizio (SLO). Gli SLO sono le promesse che intendi mantenere in base ai tuoi SLA, che possono essere qualsiasi cosa, dalla promessa di un uptime del servizio quasi perfetto (99,999%) (API o JDBC), fino a qualcosa di semplice come la promessa di una conservazione dei dati per 90 giorni per un determinato set di dati. Infine, i tuoi Indicatori di Livello di Servizio (SLI) sono la prova che stai operando in conformità con i contratti di livello di servizio e vengono presentati tipicamente sotto forma di analisi operative (dashboard) o report.
Sapere dove vogliamo andare può aiutare a stabilire il piano per arrivarci. Questo viaggio inizia dall’inserimento (o punto di ingresso) e con i dati. In particolare, con la struttura formale e l’identità di ogni punto dati. Considerando l’osservazione che “sempre più dati stanno facendo il loro ingresso nella piattaforma dati tramite piattaforme di processing dei flussi come Apache Kafka” è utile avere garanzie di compilazione a tempo, compatibilità all’indietro e serializzazione binaria veloce dei dati che vengono emessi in questi flussi di dati. La responsabilità dei dati può essere una sfida di per sé. Vediamo perché.
Gestione della responsabilità dei dati in streaming
I sistemi di streaming operano 24 ore al giorno, 7 giorni alla settimana e 365 giorni all’anno. Ciò può complicare le cose se non viene applicato lo sforzo iniziale corretto al problema, e uno dei problemi che tende a manifestarsi di tanto in tanto è quello dei dati corrotti, anche noti come problemi di dati in transito.
Gestione dei problemi dei dati in transito
Ci sono due modi comuni per ridurre i problemi di dati in volo. In primo luogo, è possibile introdurre gatekeeper all’estremità della rete dati che negoziano e convalidano i dati utilizzando tradizionali interfacce di programmazione delle applicazioni (API), oppure, come seconda opzione, è possibile creare e compilare librerie di supporto o kit di sviluppo software (SDK) per applicare i protocolli dati e consentire agli scrittori distribuiti (produttori di dati) di accedere all’infrastruttura di dati in streaming. È anche possibile utilizzare entrambe le strategie contemporaneamente.
Gatekeeper dei dati
Il vantaggio di aggiungere API gateway all’estremità (in avanti) della rete dati è che è possibile applicare l’autenticazione (questo sistema può accedere a questa API?), l’autorizzazione (questo sistema può pubblicare dati in uno specifico flusso di dati?) e la convalida (questi dati sono accettabili o validi?) al punto di produzione dei dati. Il diagramma in Figura 1–1 qui sotto mostra il flusso del gateway dei dati.
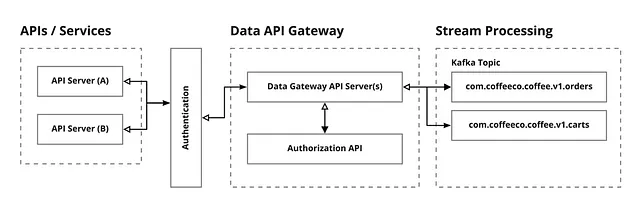
Il servizio gateway dei dati agisce come il guardiano digitale (portiere) della rete dati protetta (interna). Ha il compito principale di controllare, limitare e persino impedire l’accesso non autenticato all’estremità (vedi API/Servizi nella figura 1–1 sopra), autorizzando i servizi a monte (o gli utenti) che sono autorizzati a pubblicare dati (gestito comunemente tramite ACL dei servizi) insieme a un’identità fornita (pensate all’identità e all’accesso IAM del servizio, all’identità e all’accesso JWT del web e al nostro vecchio amico OAUTH).
La responsabilità principale del servizio gateway è convalidare i dati in ingresso prima di pubblicare dati potenzialmente corrotti o generalmente non validi. Se il gateway fa correttamente il suo lavoro, solo i dati “buoni” raggiungeranno la rete dati che è il canale dei dati operativi ed eventi per essere elaborati tramite l’elaborazione in streaming, in altre parole:
“Ciò significa che il sistema a monte che produce i dati può fallire rapidamente durante la produzione dei dati. Ciò impedisce l’ingresso di dati corrotti nei flussi di dati in streaming o stazionari all’estremità della rete dati ed è un modo per stabilire una conversazione con i produttori riguardo a cosa e come sono andate storte le cose in modo più automatico tramite codici di errore e messaggi utili.”
Utilizzo dei messaggi di errore per fornire soluzioni self-service
La differenza tra un’esperienza positiva e una negativa dipende da quanto sforzo è necessario per passare da una situazione negativa a una positiva. Probabilmente tutti abbiamo lavorato con servizi che non funzionano senza un motivo apparente (eccezione di puntatore nullo che genera un errore 500 casuale).
Per instaurare una fiducia di base, anche un piccolo gesto può fare molto. Ad esempio, ricevere un HTTP 400 da un endpoint di API con il seguente corpo del messaggio (mostrato di seguito)
{ "error": { "code": 400, "message": "I dati dell'evento non contengono l'ID utente e il timestamp non è valido (previsto un formato stringa con formattazione ISO8601). Consultare i documenti all'indirizzo http://coffeeco.com/docs/apis/customer/order#required-fields per modificare i dati." }}fornisce un motivo per il 400 e dà agli ingegneri che inviano dati a noi (come proprietari del servizio) la possibilità di risolvere un problema senza dover organizzare una riunione, far suonare il pager o contattare tutti su Slack. Quando possibile, ricordate che tutti siamo umani e amiamo i sistemi a ciclo chiuso!
Pro e contro delle API per i dati
Questo approccio API ha i suoi pro e contro.
I pro sono che la maggior parte dei linguaggi di programmazione funziona nativamente con i protocolli di trasporto HTTP (o HTTP/2), oppure con l’aggiunta di una piccola libreria, e il formato di scambio dati JSON è pressoché universale al giorno d’oggi.
D’altra parte (contro), si potrebbe sostenere che per ogni nuovo dominio dei dati, è necessario scrivere e gestire un altro servizio e, senza una forma di automazione delle API o l’adesione a una specifica aperta come OpenAPI, ogni nuova rotta (endpoint) dell’API richiede più tempo del necessario.
In molti casi, la mancanza di aggiornamenti tempestivi alle API di ingestione dei dati, o problemi di scalabilità e/o periodi di inattività delle API, fallimenti casuali o semplicemente mancanza di comunicazione, forniscono la giustificazione necessaria per aggirare la “stupida” API e cercare invece di pubblicare direttamente i dati degli eventi su Kafka. Sebbene le API possano sembrare un ostacolo, c’è un forte argomento a favore di un gatekeeper comune, specialmente dopo che problemi di qualità dei dati come eventi corrotti o eventi mescolati accidentalmente iniziano a destabilizzare il sogno dello streaming.
Per risolvere questo problema (e ridurlo quasi del tutto), una buona documentazione, la gestione dei cambiamenti (CI/CD) e l’igiene generale dello sviluppo del software, inclusi test unitari e di integrazione effettivi, consentono cicli rapidi di sviluppo delle funzionalità e delle iterazioni che non riducono la fiducia.
Idealemente, i dati stessi (schema/formato) potrebbero dettare le regole del proprio contratto a livello di dati abilitando la validazione a livello di campo (predicati), producendo messaggi di errore utili e agendo nel proprio interesse. Ehi, con un po’ di metadata a livello di percorso o dati e un po’ di pensiero creativo, l’API potrebbe generare automaticamente percorsi e comportamenti auto-definiti.
Infine, le API gateway possono essere viste come fonte di problemi centralizzati poiché ogni fallimento di un sistema upstream nell’emettere dati validi (ad es. bloccati dal gatekeeper) fa sì che informazioni preziose (dati degli eventi, metriche) vengano perse. Il problema della colpa tende anche a andare in entrambe le direzioni, poiché un cattivo deployment del gatekeeper può accecare un sistema upstream che non è configurato per gestire i ritentativi in caso di downtime del gateway (anche solo per pochi secondi).
Mettendo da parte tutti i pro e i contro, l’utilizzo di una API gateway per fermare la propagazione di dati corrotti prima che entrino nella piattaforma dei dati significa che quando si verifica un problema (perché succede sempre), l’area del problema si riduce a un determinato servizio. Questo è sicuramente meglio che fare il debug di una rete distribuita di pipeline di dati, servizi e una miriade di destinazioni finali dei dati e sistemi upstream per scoprire che i dati errati vengono pubblicati direttamente da “qualcuno” nell’azienda.
Se eliminassimo l’intermediario (servizio gateway), le capacità di governare la trasmissione dei dati “previsti” ricadrebbero sulle “librerie” sotto forma di SDK specializzati.
Software Development Kits (SDK)
Le SDK sono librerie (o micro-framework) che vengono importate in una codebase per semplificare un’azione, un’attività o un’operazione altrimenti complessa. Sono anche conosciuti con un altro nome, client. Prendiamo ad esempio l’esempio precedente sull’utilizzo di buoni messaggi di errore e codici di errore. Questo processo è necessario per informare un client che la sua azione precedente è stata invalida, tuttavia può essere vantaggioso aggiungere adeguate protezioni direttamente in una SDK per ridurre l’area di potenziali problemi. Ad esempio, supponiamo di avere un’API configurata per tracciare il comportamento dei clienti relativi al caffè tramite il tracciamento degli eventi.
Riduzione degli errori utente con le protezioni SDK
Una SDK client può teoricamente includere tutti gli strumenti necessari per gestire le interazioni con il server API, inclusa l’autenticazione, l’autorizzazione e, per quanto riguarda la validazione, se la SDK fa il suo lavoro, i problemi di validazione verranno eliminati. Il seguente frammento di codice mostra un esempio di SDK che potrebbe essere utilizzato per tracciare in modo affidabile gli eventi dei clienti.
import com.coffeeco.data.sdks.client._import com.coffeeco.data.sdks.client.protocol._Customer.fromToken(token) .track( eventType=Events.Customer.Order, status=Status.Order.Initalized, data=Order.toByteArray )Con un po’ di lavoro aggiuntivo (aka la SDK client), il problema di validazione dei dati o corruzione degli eventi può quasi scomparire del tutto. I problemi aggiuntivi possono essere gestiti all’interno della SDK stessa, ad esempio come riprovare l’invio di una richiesta nel caso in cui il server sia offline. Invece di far riprovare immediatamente tutte le richieste, o in un ciclo che inonda indefinitamente un bilanciatore di carico del gateway, la SDK può adottare azioni più intelligenti come l’utilizzo del backoff esponenziale. Consulta “Il problema del branco tonante” per approfondire ciò che va storto quando le cose vanno male!
Il problema del branco tonante Supponiamo di avere un singolo server API gateway. Hai scritto un’API fantastica e molti team in azienda inviano dati degli eventi a questa API. Tutto va bene finché un giorno un nuovo team interno inizia a inviare dati non validi al server (e anziché rispettare i tuoi codici di stato HTTP, trattano tutti i codici HTTP diversi da 200 come motivo per riprovare. Ma aspetta, hanno dimenticato di aggiungere qualsiasi tipo di euristica di ripetizione come il backoff esponenziale, quindi tutte le richieste riprovano all’infinito – attraverso una coda di ripetizione sempre crescente). Tieni presente che prima che questo nuovo team si unisse, non c’era mai una ragione per eseguire più di un’istanza del server API e non c’era mai bisogno di utilizzare alcun tipo di limitatore di velocità a livello di servizio, perché tutto funzionava senza problemi entro gli SLA concordati.

Bene, questo era prima di oggi. Ora il tuo servizio è offline. I dati si stanno backuppando, i servizi in upstream stanno riempiendo le loro code, e le persone sono arrabbiate perché i loro servizi stanno iniziando ad avere problemi a causa del tuo punto singolo di fallimento… Tutti questi problemi derivano da una forma di fame di risorse chiamata “Problema dell’Armento Tonante”. Questo problema si verifica quando molti processi sono in attesa di un evento, come la disponibilità delle risorse di sistema, o in questo esempio, il ripristino del server API. Ora c’è una corsa in cui tutti i processi competono per cercare di ottenere risorse, e in molti casi il carico sul singolo processo (server api) è sufficiente per riportare il servizio offline. Sfortunatamente, iniziando così il ciclo di fame di risorse di nuovo. Questo è ovviamente a meno che tu non riesca a calmare l’armento o a distribuire il carico su un numero maggiore di processi di lavoro, il che riduce il carico sulla rete al punto in cui le risorse hanno spazio per respirare di nuovo. Mentre l’esempio iniziale sopra è più simile a un attacco di negazione del servizio distribuito non intenzionale (DDoS), questi tipi di problemi possono essere risolti a livello del client (con exponential backoff o autoregolazione) e al bordo dell’API tramite bilanciamento del carico e limitazione del tasso.
In definitiva, senza il giusto set di occhi e orecchie, abilitati da metriche operative, monitor e allarmi a livello di sistema (SLA/SLI/SLO), i dati possono scomparire, e questo può essere un problema difficile da risolvere.
Indipendentemente dal fatto che tu decida di aggiungere un’API gateway dati al bordo della tua rete dati, di utilizzare un SDK personalizzato per la coerenza e la responsabilità a monte, o di adottare un approccio alternativo per gestire l’inserimento dei dati nella tua piattaforma dati, è comunque utile sapere quali sono le tue opzioni. Indipendentemente dal percorso in cui i dati vengono emessi nei tuoi flussi di dati, questa introduzione ai dati in streaming non sarebbe completa senza una discussione adeguata sui formati dei dati, sui protocolli e sull’argomento dei dati serializzabili binari. Chissà che non scopriamo un approccio migliore per gestire il nostro problema di responsabilità dei dati!
Selezionare il Protocollo Dati Corretto per il Lavoro
Quando si pensa ai dati strutturati, la prima cosa che viene in mente potrebbe essere il formato JSON. I dati JSON hanno struttura, sono un protocollo dati standard basato sul web e, se nient’altro, sono estremamente facili da utilizzare. Questi sono tutti vantaggi per iniziare rapidamente, ma nel tempo, e senza le adeguate protezioni, potresti incontrare problemi nel standardizzare JSON per i tuoi sistemi di streaming.
Il Rapporto Amore / Odio con JSON
Il primo problema è che i dati JSON sono mutabili. Ciò significa che come struttura dati è flessibile e quindi fragile. I dati devono essere consistenti per essere responsabili, e nel caso del trasferimento di dati attraverso una rete (on-the-wire), il formato serializzato (rappresentazione binaria) dovrebbe essere altamente compatto. Con i dati JSON, è necessario inviare le chiavi (per tutti i campi) per ogni oggetto rappresentato nel payload. Inevitabilmente, questo significa che di solito invierai una grande quantità di peso aggiuntivo per ogni record aggiuntivo (dopo il primo) in una serie di oggetti.
Fortunatamente, questo non è un nuovo problema, e proprio per questo esistono best practice per questo tipo di cose, e più scuole di pensiero su quale sia la migliore strategia per serializzare ottimamente i dati. Questo non significa che JSON non abbia i suoi meriti. Semplicemente, quando si tratta di stabilire una solida base di dati, maggiore è la struttura e maggiore è il livello di compattezza, meglio è, purché non bruci molte CPU.
Dati Strutturati Serializzabili
Quando si tratta di codificare ed effettuare il trasferimento di dati binari, due framework di serializzazione tendono sempre a emergere: Apache Avro e Google Protocol Buffers (protobuf). Entrambe le librerie forniscono tecniche efficienti in termini di CPU per serializzare strutture di dati basate su righe, e oltre a entrambe le tecnologie forniscono anche i loro framework e capacità di chiamata di procedura remota (RPC). Analizziamo avro, poi protobuf, e concludiamo analizzando le chiamate di procedura remota.
Formato di messaggio Avro
Con Avro, si definiscono schemi dichiarativi per i dati strutturati utilizzando il concetto di record. Questi record sono semplicemente file di definizione di dati formattati JSON (schemi) archiviati con il tipo di file avsc. L’esempio seguente mostra uno schema di Coffee nel formato del descrittore Avro.
{ "namespace": "com.coffeeco.data", "type": "record", "name": "Coffee", "fields": [ {"name": "id", "type": "string"}, {"name": "name", "type": "string"}, {"name": "boldness", "type": "int", "doc": "da leggero a audace. 1 a 10"}, {"name": "available", "type": "boolean"} ]}Lavorare con dati Avro può seguire due percorsi che si separano a seconda di come si desidera lavorare durante l’esecuzione. È possibile adottare l’approccio del tempo di compilazione o risolvere le cose su richiesta durante l’esecuzione. Ciò consente una flessibilità che può migliorare una sessione interattiva di scoperta dei dati. Ad esempio, Avro è stato originariamente creato come un protocollo di serializzazione efficiente per memorizzare grandi collezioni di dati, come file partizionati, a lungo termine all’interno del file system Hadoop. Poiché i dati venivano tipicamente letti da una posizione e scritti in un’altra all’interno di HDFS, Avro poteva archiviare lo schema (utilizzato durante la scrittura) una volta per file.
Formato binario Avro
Quando si scrive una collezione di record Avro su disco, il processo codifica lo schema dei dati Avro direttamente nel file stesso (una volta). Si verifica un processo simile quando si tratta di codifica dei file Parquet, in cui lo schema viene compresso e scritto come piè di pagina di un file binario. Abbiamo visto questo processo di persona, alla fine del capitolo 4, quando abbiamo seguito il processo di aggiunta della documentazione a livello di StructField al nostro StructType. Questo schema è stato utilizzato per codificare il nostro DataFrame e, quando abbiamo scritto su disco, ha preservato la nostra documentazione in linea per la successiva lettura.
Abilitare la compatibilità all’indietro e prevenire la corruzione dei dati
Nel caso della lettura di più file come una singola collezione, possono sorgere problemi nel caso di modifiche dello schema tra i record. Avro codifica i record binari come matrici di byte e applica uno schema ai dati al momento della deserializzazione (conversione di un array di byte in un oggetto).
Ciò significa che si devono prendere precauzioni aggiuntive per preservare la compatibilità all’indietro, altrimenti ci si potrebbe imbattere in problemi con eccezioni ArrayIndexOutOfBounds.
Questo può accadere se lo schema cambia in modo sottile. Ad esempio, supponiamo che sia necessario cambiare un valore intero in un valore long per un campo specifico dello schema. Non farlo. Questo romperà la compatibilità all’indietro a causa dell’aumento della dimensione dei byte da int a long. Questo è dovuto all’uso della definizione dello schema per definire la posizione di inizio e fine nell’array di byte per ciascun campo di un record. Per mantenere la compatibilità all’indietro, sarà necessario deprecare l’uso del campo intero in futuro (preservandolo nella definizione Avro) e aggiungere (appendere) un nuovo campo allo schema da utilizzare in futuro.
Best practice per lo streaming di dati Avro
Passando da file Avro statici, con i loro utili schemi incorporati, a uno stream illimitato di dati binari ben strutturati, la principale differenza è che è necessario fornire il proprio schema. Ciò significa che è necessario supportare la compatibilità all’indietro (nel caso in cui sia necessario tornare indietro e rieseguire l’elaborazione dei dati prima e dopo una modifica dello schema), così come la compatibilità in avanti, nel caso in cui ci siano già lettori esistenti che consumano uno stream.
La sfida qui è supportare entrambe le forme di compatibilità dato che Avro non ha la capacità di ignorare campi sconosciuti, il che è un requisito per supportare la compatibilità in avanti. Per supportare queste sfide con Avro, il team di Confluence ha reso open source il loro registro degli schemi (per l’uso con Kafka) che consente la versioning degli schemi a livello di topic Kafka (stream di dati).
Quando si supporta Avro senza un registro degli schemi, è necessario assicurarsi di aver aggiornato tutti i lettori attivi (applicazioni Spark o altro) per utilizzare la nuova versione dello schema prima di aggiornare la versione della libreria degli schemi sui writer. Altrimenti, al momento di cambiare, ci si potrebbe ritrovare all’inizio di un incidente.
Formato di messaggio Protobuf
Con Protobuf, si definiscono le definizioni dei dati strutturati utilizzando il concetto di messaggi. I messaggi sono scritti in un formato che ricorda la definizione di una struttura in C. Questi file di messaggio sono scritti in file con estensione proto. I Protocol Buffers hanno il vantaggio di utilizzare le importazioni. Ciò significa che è possibile definire tipi di messaggio comuni e enumerazioni che possono essere utilizzati all’interno di un grande progetto o addirittura importati in progetti esterni per consentire il riutilizzo su larga scala. Un semplice esempio di creazione del record di Coffee (tipo di messaggio) utilizzando protobuf.
syntax = "proto3";
option java_package="com.coffeeco.protocol";
option java_outer_classname="Common";
message Coffee {
string id = 1;
string name = 2;
uint32 boldness = 3;
bool available = 4;
}Con protobuf si definiscono i messaggi una volta e poi si compila per il linguaggio di programmazione scelto. Ad esempio, possiamo generare il codice per Scala utilizzando il file coffee.proto con il compilatore autonomo del progetto ScalaPB (creato e mantenuto da Nadav Samet), o sfruttare la brillantezza di Buf, che ha creato un insieme prezioso di strumenti e utilità intorno a protobuf e grpc.
Generazione di codice
La compilazione di protobuf consente una semplice generazione di codice. L’esempio seguente è tratto dalla directory /ch-09/data/protobuf. Le istruzioni nel file README del capitolo spiegano come installare ScalaPB e includono i passaggi per impostare le variabili d’ambiente corrette per eseguire il comando.
$SCALAPBC/bin/scalapbc -v3.11.1 \ --scala_out=/Users/`whoami`/Desktop/coffee_protos \ --proto_path=$SPARK_MDE_HOME/ch-09/data/protobuf/ \ coffee.protoQuesto processo risparmia tempo nel lungo periodo, liberandoti dalla necessità di scrivere codice aggiuntivo per serializzare e deserializzare i tuoi oggetti dati (attraverso confini di linguaggio o all’interno di diverse basi di codice).
Formato binario di Protobuf
La serializzazione (formato binario) è codificata utilizzando il concetto di separatori di livello di campo binario. Questi separatori vengono utilizzati come marcatori che identificano i tipi di dati incapsulati all’interno di un messaggio protobuf serializzato. Nell’esempio coffee.proto, probabilmente hai notato che c’era un marcatore indicizzato accanto a ciascun tipo di campo (string id = 1;), questo viene utilizzato per aiutare l’encoding/decoding dei messaggi sul/dal filo. Ciò significa che c’è un piccolo sovraccarico aggiuntivo rispetto al formato binario di Avro, ma se leggi le specifiche di encoding, vedrai che altre efficienze compensano ampiamente eventuali byte aggiuntivi (come il bit packing, la gestione efficiente dei tipi di dati numerici e l’encoding speciale dei primi 15 indici per ogni messaggio). Per quanto riguarda l’utilizzo di protobuf come protocollo binario di scelta per lo streaming dei dati, i vantaggi superano di gran lunga gli svantaggi nel grande schema delle cose. Uno dei modi in cui questo si ripaga ampiamente è il supporto sia per la compatibilità all’indietro che per quella in avanti.
Abilitazione della compatibilità all’indietro e prevenzione della corruzione dei dati
Esistono regole simili da tenere a mente quando si modifica lo schema protobuf come abbiamo discusso con Avro. Come regola generale, puoi cambiare il nome di un campo, ma non cambiare il tipo o la posizione (indice) a meno che tu non voglia rompere la compatibilità all’indietro. Queste regole possono essere trascurate quando si tratta di supportare qualsiasi tipo di dati a lungo termine e possono essere particolarmente difficili quando i team diventano più competenti nell’uso di protobuf. C’è questa necessità di riorganizzare e ottimizzare che può tornare a morderti se non sei attento. (Vedi il consiglio di seguito chiamato Mantenere la qualità dei dati nel tempo per ulteriori informazioni).
Best Practice per lo streaming di dati Protobuf
Dato che protobuf supporta sia la compatibilità all’indietro che quella in avanti, ciò significa che puoi distribuire nuovi scrittori senza preoccuparti di aggiornare prima i tuoi lettori, e lo stesso vale per i tuoi lettori, puoi aggiornarli con versioni più recenti delle tue definizioni protobuf senza preoccuparti di una distribuzione complessa di tutti i tuoi scrittori. Protobuf supporta la compatibilità in avanti utilizzando il concetto di campi sconosciuti. Questo è un concetto aggiuntivo che non esiste nella specifica di Avro ed è utilizzato per tenere traccia degli indici e dei byte associati che non è stato possibile analizzare a causa della divergenza tra la versione locale di protobuf e la versione che si sta leggendo attualmente. La cosa vantaggiosa qui è che puoi anche scegliere, in qualsiasi momento, di aderire a nuovi cambiamenti nelle definizioni di protobuf.
Ad esempio, supponiamo di avere due applicazioni di streaming (a) e (b). L’applicazione (a) sta elaborando dati in streaming da un topic Kafka a monte (x), arricchendo ogni record con informazioni aggiuntive e quindi scrivendolo su un nuovo topic Kafka (y). Ora, l’applicazione (b) legge da (y) e fa la sua cosa. Supponiamo che ci sia una versione più recente della definizione di protobuf e l’applicazione (a) non è ancora stata aggiornata alla versione più recente, mentre il topic Kafka a monte (x) e l’applicazione (b) sono già stati aggiornati e si aspettano di utilizzare alcuni nuovi campi disponibili dall’aggiornamento. La cosa incredibile è che è ancora possibile passare i campi sconosciuti attraverso l’applicazione (a) e l’applicazione (b) senza nemmeno sapere che esistono.
Vedi “Consigli per mantenere una buona qualità dei dati nel tempo” per un’ulteriore analisi approfondita.
Suggerimento: Mantenere la Qualità dei Dati nel Tempo
Quando si lavora con avro o protobuf, è necessario trattare gli schemi allo stesso modo del codice che si desidera pubblicare in produzione. Ciò significa creare un progetto che può essere inserito nel repository GitHub della tua azienda (o qualsiasi altro sistema di controllo versione che stai utilizzando), e significa anche scrivere test unitari per gli schemi. Non solo ciò fornisce esempi viventi su come utilizzare ogni tipo di messaggio, ma la ragione più importante per testare i formati dei dati è garantire che le modifiche allo schema non interrompano la compatibilità all’indietro. La ciliegina sulla torta è che per testare gli schemi avrai bisogno di compilare prima i file (.avsc o .proto) e utilizzare la generazione di codice delle rispettive librerie. Questo rende più facile creare codice di libreria rilasciabile e puoi anche utilizzare la versione del rilascio (versione 1.0.0) per catalogare ogni modifica agli schemi.
Un metodo semplice per abilitare questo processo è serializzare e archiviare una copia binaria di ciascun messaggio, attraverso tutte le modifiche dello schema, come parte del ciclo di vita del progetto. Ho riscontrato successo aggiungendo direttamente questo passaggio nei test unitari stessi, utilizzando il set di test per creare, leggere e scrivere questi record direttamente nella directory delle risorse di test del progetto. In questo modo ogni versione binaria, attraverso tutte le modifiche dello schema, è disponibile all’interno del codice stesso.
Con un piccolo sforzo iniziale extra, puoi risparmiarti molta fatica nel grande schema delle cose e dormire tranquillo sapendo che i tuoi dati sono al sicuro (almeno sul lato di produzione e consumo della tabella)
Utilizzo degli Strumenti Buf e Protobuf in Spark
Dal momento della scrittura di questo capitolo nel 2021, Buf Build (https://buf.build/) si è trasformato nell’azienda che si occupa di tutto ciò che riguarda protobuf. I loro strumenti sono semplici da usare, gratuiti e open-source, e sono apparsi proprio nel momento giusto per supportare alcune iniziative nella comunità di Spark. Il progetto Apache Spark ha introdotto il supporto nativo completo per Protocol Buffers in Spark 3.4 per supportare spark-connect, e sta utilizzando Buf per compilare i servizi e i messaggi GRPC. Spark Connect è infatti un connettore nativo GRPC per l’incorporamento di applicazioni Spark al di fuori del JVM.
Le tradizionali applicazioni Apache Spark devono essere eseguite come applicazione driver da qualche parte, e in passato ciò significava utilizzare pyspark o spark nativo, che in entrambi i casi vengono ancora eseguiti su un processo JVM.
Alla fine della giornata, Buf Build garantisce tranquillità nel processo di compilazione. Per generare il codice, è sufficiente eseguire un semplice comando: buf generate. Per il linting e la formattazione coerente, buf lint && buf format -w. La ciliegina sulla torta, però, è la rilevazione dei cambiamenti che potrebbero causare problemi. buf breaking --against .git#branch=origin/main è tutto ciò che serve per garantire che le nuove modifiche alle definizioni dei messaggi non influiscano negativamente su ciò che è attualmente in esecuzione in produzione. *In futuro, scriverò un articolo sull’utilizzo di buf per l’analisi aziendale, ma per ora è il momento di concludere questo capitolo.
Quindi, dove eravamo rimasti. Ora sai che ci sono vantaggi nell’utilizzare avro o protobuf per la tua strategia di responsabilità dei dati a lungo termine. Utilizzando questi formati di dati strutturati, agnostici al linguaggio e basati su righe, riduci il problema del blocco del linguaggio a lungo termine, lasciando aperte le porte a qualsiasi linguaggio di programmazione in futuro. Perché onestamente, può essere un compito ingrato supportare librerie e code legacy. Inoltre, i formati serializzati aiutano a ridurre i costi e la congestione della larghezza di banda di rete associati all’invio e alla ricezione di grandi quantità di dati. Ciò contribuisce anche a ridurre i costi di overhead di archiviazione per la conservazione a lungo termine dei dati.
Infine, vediamo come questi protocolli di dati strutturati consentono efficienze aggiuntive nell’invio e nella ricezione di dati tramite chiamate di procedura remote.
Chiamate di Procedura Remote
I framework RPC, in poche parole, consentono alle applicazioni client di chiamare in modo trasparente metodi (procedure) remoti (lato server) tramite chiamate di funzioni locali passando avanti e indietro messaggi serializzati. Le implementazioni lato client e lato server utilizzano la stessa definizione di interfaccia pubblica per definire i metodi e i servizi RPC funzionali disponibili. Il linguaggio di definizione dell’interfaccia (IDL) definisce il protocollo e le definizioni dei messaggi e funge da contratto tra il client e il lato server. Vediamo questo in azione analizzando il popolare framework RPC open-source gRPC.
gRPC
Prima concepito e creato da Google, gRPC che sta per “generic” remote procedure call, è un robusto framework open-source utilizzato per servizi ad alte prestazioni che vanno dal coordinamento del database distribuito, come si vede con CockroachDB, all’analisi in tempo reale, come si vede con Microsoft Azure Video Analytics.
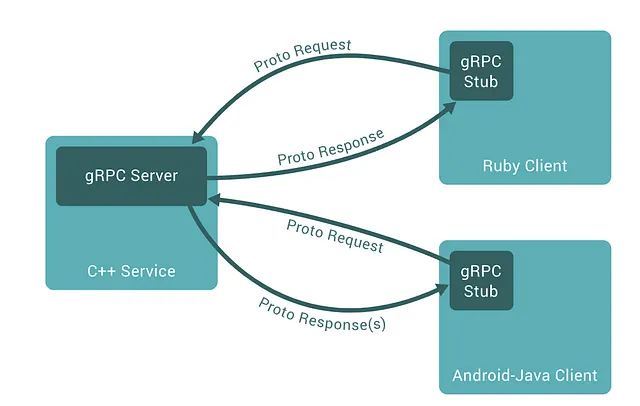
Il diagramma mostrato nella Figura 9-3 mostra un esempio di gRPC in azione. Il codice lato server è scritto in C++ per la velocità, mentre i client scritti in ruby e java possono interagire con il servizio utilizzando messaggi protobuf come mezzo di comunicazione.
Utilizzando i protocol buffers per le definizioni dei messaggi, la serializzazione, nonché la dichiarazione e la definizione dei servizi, gRPC può semplificare la modalità di acquisizione dei dati e la creazione dei servizi. Ad esempio, diciamo che vogliamo continuare l’esercizio di creazione di un’API di tracciamento per gli ordini di caffè dei clienti. Il contratto API potrebbe essere definito in un semplice file di servizi e da lì è possibile creare l’implementazione lato server e qualsiasi numero di implementazioni lato client utilizzando la stessa definizione di servizio e tipi di messaggio.
Definizione di un servizio gRPC
Puoi definire un’interfaccia di servizio, gli oggetti di richiesta e risposta, così come i tipi di messaggio che devono essere passati tra il client e il server facilmente come 1-2-3.
syntax = "proto3";service CustomerService { rpc TrackOrder (Order) returns (Response) {} rpc TrackOrderStatus (OrderStatusTracker) returns (Response) {}}message Order { uint64 timestamp = 1; string orderId = 2; string userId = 3; Status status = 4;}enum Status { unknown_status = 0; initalized = 1; started = 2; progress = 3; completed = 4; failed = 5; canceled = 6;}message OrderStatusTracker { uint64 timestamp = 1; Status status = 2; string orderId = 3;}message Response { uint32 statusCode = 1; string message = 2;}Con l’aggiunta di gRPC, può essere molto più facile implementare e mantenere il codice lato server e lato client utilizzato all’interno dell’infrastruttura dei dati. Dato che protobuf supporta la compatibilità all’indietro e in avanti, ciò significa che i client gRPC più vecchi possono comunque inviare messaggi validi ai servizi gRPC più recenti senza incontrare problemi e punti critici comuni (discussi in precedenza sotto “Problemi di dati in volo”).
gRPC parla HTTP/2
Come bonus, per quanto riguarda gli stack di servizi moderni, gRPC è in grado di utilizzare HTTP/2 per il suo livello di trasporto. Ciò significa anche che è possibile sfruttare le moderne reti di dati (come Envoy) per il supporto del proxy, il routing e l’autenticazione a livello di servizio, riducendo allo stesso tempo i problemi di congestione dei pacchetti TCP riscontrati con l’HTTP standard su TCP.
La mitigazione dei problemi di dati in volo e il raggiungimento del successo in termini di responsabilità dei dati iniziano con i dati e si estendono da quel punto centrale. Mettere in atto processi per far entrare i dati nella rete dati dovrebbe essere considerato un requisito preliminare da verificare prima di immergersi nel torrente di dati in streaming.
Sommario
Lo scopo di questo post è presentare le parti in movimento, i concetti e le informazioni di base necessarie per armarsi prima di saltare ciecamente da una mentalità più tradizionale (stazionaria) basata su batch a una che comprende i rischi e i vantaggi del lavoro con dati in streaming in tempo reale.
Sfruttare i dati in tempo reale può portare a intuizioni rapide e azioni concrete e aprire le porte all’apprendimento automatico all’avanguardia e all’intelligenza artificiale.
Tuttavia, la gestione distribuita dei dati può anche diventare una crisi dei dati se non vengono presi in considerazione i giusti passi in anticipo. Ricorda che senza una solida base di dati, costruita su dati validi (affidabili), la strada per il tempo reale non sarà un’impresa semplice, ma avrà le sue difficoltà e deviazioni lungo il cammino.
Spero che tu abbia apprezzato la seconda metà del Capitolo 9. Per leggere la prima parte di questa serie, vai su A Gentle Introduction to Analytical Stream Processing.
Un’introduzione delicata all’elaborazione analitica in streaming
Creazione di un modello mentale per gli ingegneri e chiunque altro
towardsdatascience.com
Se vuoi approfondire ulteriormente, ti prego di consultare il mio libro o di supportarmi con un alto cinque.
Modern Data Engineering with Apache Spark: Una guida pratica per la costruzione di streaming mission-critical…
Amazon.com: Modern Data Engineering with Apache Spark: Una guida pratica per la costruzione di streaming mission-critical…
www.amazon.com
Se hai accesso a O’Reilly Media, puoi anche leggere gratuitamente l’intero libro (buono per te, meno buono per me), ma ti prego di trovare il libro gratuitamente da qualche altra parte se hai l’opportunità, o di acquistare un ebook per risparmiare sui costi di spedizione (o sulla necessità di trovare un posto per un libro di oltre 600 pagine).
Modern Data Engineering with Apache Spark: Una guida pratica per la costruzione di streaming mission-critical…
Sfrutta Apache Spark all’interno di un ecosistema di data engineering moderno. Questa guida pratica ti insegnerà come scrivere completamente…
learning.oreilly.com






