L’evoluzione dei dati tabulari dall’analisi all’IA
Evoluzione dati tabulari da analisi a IA
Scopri come lo spazio dei dati tabulari sta essendo trasformato dalle competizioni di Kaggle, dalla comunità open-source e dall’IA generativa.

Introduzione
I dati tabulari si riferiscono a dati organizzati in righe e colonne. Comprendono tutto, dai file CSV e fogli di calcolo ai database relazionali. I dati tabulari esistono da decenni e sono uno dei tipi di dati più comuni utilizzati nell’analisi dei dati e nell’apprendimento automatico.
Tradizionalmente, i dati tabulari sono stati utilizzati semplicemente per organizzare e riportare informazioni. Tuttavia, nell’ultimo decennio, il loro utilizzo è evoluto significativamente a causa di diversi fattori chiave:
- Competizioni di Kaggle: Kaggle è emerso nel 2010 [1] e ha reso popolari le competizioni di scienza dei dati e apprendimento automatico utilizzando set di dati tabulari del mondo reale. Ciò ha esposto molti scienziati dei dati e ingegneri di apprendimento automatico al potere di analizzare e costruire modelli sui dati tabulari.
- Contributi open-source: Grazie a importanti librerie open-source come Pandas, DuckDB, SDV e Scikit-learn, la manipolazione, la preelaborazione e la costruzione di modelli predittivi sui dati tabulari sono ora incredibilmente facili. Inoltre, i set di dati open-source forniscono ai principianti un facile accesso per esercitarsi su set di dati del mondo reale.
- IA generativa: I recenti progressi nell’IA generativa, in particolare i grandi modelli di linguaggio, consentono ora la generazione di dati tabulari realistici e rendono facile per praticamente chiunque condurre analisi dei dati e costruire applicazioni di apprendimento automatico.
Nel saggio, discuteremo ognuno di questi fattori in maggiore dettaglio e guarderemo esempi di come aziende e ricercatori stanno utilizzando i dati tabulari in modi innovativi oggi. La principale conclusione sarà l’importanza di analizzare e preparare i dati tabulari nel modo giusto per raccogliere i benefici dell’apprendimento automatico e dell’IA.
Questo saggio fa parte del Rapporto AI di Kaggle 2023, una competizione in cui i partecipanti scrivono un saggio su uno dei sette argomenti. La domanda chiede loro di descrivere cosa ha imparato la comunità negli ultimi due anni di lavoro e sperimentazione.
- Questo articolo sull’IA suggerisce che i modelli di apprendimento delle macchine quantistiche potrebbero essere meglio difesi dagli attacchi avversari generati dai computer classici
- Post principali dal 7 al 13 agosto Dimenticate ChatGPT, Questo nuovo assistente di intelligenza artificiale è di gran lunga superiore e cambierà per sempre il modo in cui lavorate
- Come utilizzare HeyGen per creare avatar generati da intelligenza artificiale realistici
Competizioni Dati Tabulari di Kaggle
La competizione Kaggle ha avuto un profondo impatto nel campo della scienza dei dati e dell’ingegneria dell’apprendimento automatico. Inoltre, le competizioni tabulari hanno introdotto nuove tecniche, strumenti e varie attività tabulari.
Oltre all’apprendimento e allo sviluppo delle conoscenze, vincere le competizioni spesso comporta premi in denaro, fornendo ulteriore motivazione per la partecipazione. Ad esempio:
- In media, le competizioni Kaggle offrono premi in denaro di circa $21.246 e hanno circa 1.498 squadre partecipanti.
- I premi in denaro più alti sono arrivati fino a $125.000, dando ai vincitori un incentivo significativo per fare un ulteriore sforzo e spingere i limiti di ciò che è possibile con i dati tabulari.
Nota: Utilizzeremo il dataset Meta Kaggle per la nostra analisi ed esempi di codice. Il dataset è sotto licenza Apache 2.0 ed è aggiornato quotidianamente.
import pandas as pdcomptags = pd.read_csv("/kaggle/input/meta-kaggle/CompetitionTags.csv")tags = pd.read_csv("/kaggle/input/meta-kaggle/Tags.csv")comps = pd.read_csv("/kaggle/input/meta-kaggle/Competitions.csv")tabular_competition_ids = comptags.query("TagId == 14101")['CompetitionId']tabular_competitions = comps.set_index('Id').loc[tabular_competition_ids]tabular_competitions.describe()[["RewardQuantity","TotalTeams"]]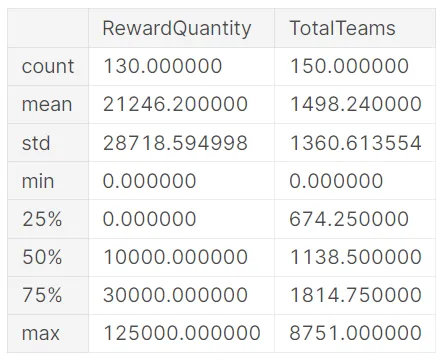
Nell’ultimo decennio, Kaggle ha ospitato numerose competizioni incentrate sui dati tabulari, con diverse competizioni dal 2015 che offrono premi in denaro fino a $100.000 per la squadra vincitrice.
import plotly.express as pxtabular_competitions["EnabledDate"] = pd.to_datetime( tabular_competitions["EnabledDate"], format="%m/%d/%Y %H:%M:%S")tabular_competitions["EnabledDate"] = tabular_competitions["EnabledDate"].dt.yeartabular_competitions.sort_values(by="EnabledDate", inplace=True)fig = px.bar( tabular_competitions, x="EnabledDate", y="RewardQuantity", title="Distribuzione dei premi delle competizioni tabulari nel corso degli anni", labels={"RewardQuantity": "Premio in denaro($)", "EnabledDate": "Anno"},)fig.show()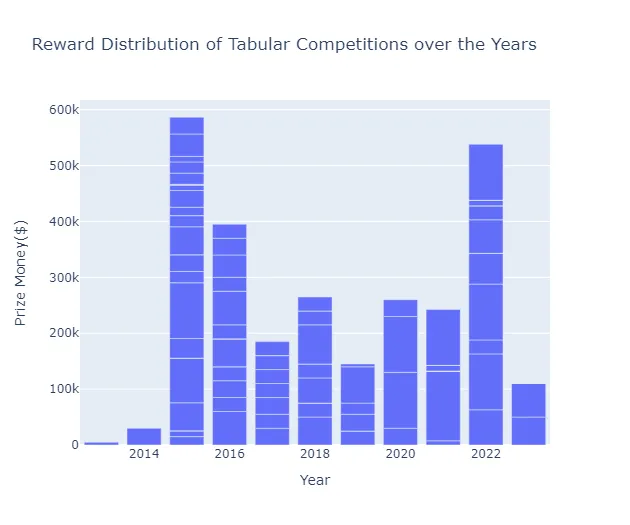
Il numero di competizioni di dati tabulari è cresciuto significativamente in questo periodo, con un’attività particolarmente intensa nel 2015 e nel 2022.
fig = px.histogram( tabular_competitions, x="EnabledDate", nbins=20, title="Numero di competizioni tabulari nel corso degli anni", labels={"EnabledDate": "Anno"},)fig.show()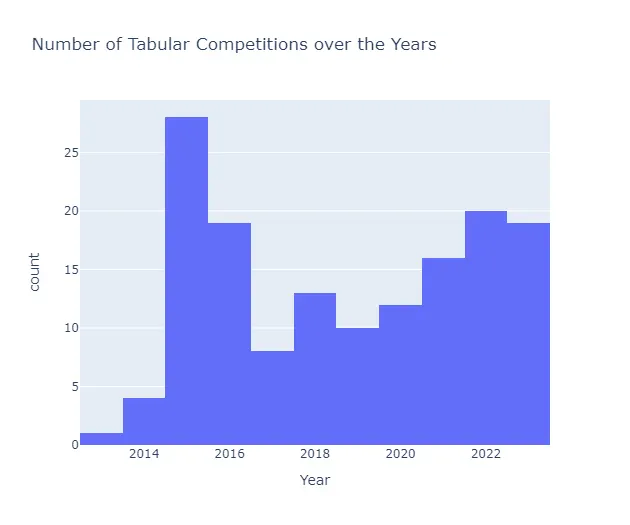
Tabular Playground Series
A causa dell’elevata domanda di problemi di dati tabulari, il personale di Kaggle ha avviato un esperimento nel 2021 [2] lanciando un concorso mensile chiamato Tabular Playground Series. Queste competizioni avevano lo scopo di fornire una piattaforma coerente per i concorrenti per affinare le loro competenze sui dati tabulari.
Le competizioni della Tabular Playground Series erano basate su set di dati sintetici che replicavano la struttura di dati pubblici o dati di competizioni Kaggle precedenti. I set di dati sintetici sono stati creati utilizzando una rete generativa di deep learning chiamata CTGAN.[3]
- Esposizione: Molti professionisti del machine learning hanno avuto la loro prima esperienza nel lavorare con dati tabulari attraverso la Tabular Playground Series. Questo li ha aiutati a familiarizzare con concetti come il caricamento dei dati, l’ingegneria delle caratteristiche e l’ottimizzazione dei modelli.
- Tecniche: Le competizioni Kaggle hanno presentato tecniche come l’ingegneria delle caratteristiche, l’aumento dei dati e la modellazione ensemble che sono particolarmente utili per i dati tabulari. I concorrenti hanno utilizzato queste tecniche per ottenere punteggi più alti, dando l’esempio agli altri.
- Comunità: Le discussioni all’interno delle competizioni Kaggle hanno fornito un terreno fertile per la condivisione di tecniche e idee su come gestire al meglio i dati tabulari. Questo ha contribuito a formare una comunità di pratica intorno ai dati tabulari.
- Democratizzazione: Le competizioni Kaggle hanno reso il machine learning sui dati tabulari accessibile a un pubblico più ampio, non solo agli esperti di dati. I partecipanti hanno accesso gratuito sia alla CPU che alla GPU, nonché a grandi set di dati, e chiunque è il benvenuto a partecipare alla competizione.
La Tabular Playground Series è ancora in corso, attualmente nella Stagione 3 con l’Episodio 18. Questo dimostra che i premi in denaro non sono l’unico motivo per i partecipanti, poiché queste competizioni non offrono premi monetari o sistemi di punteggio. Piuttosto, la serie si rivolge agli appassionati di dati che vogliono perfezionare le proprie competenze praticando vari tipi di dati tabulari.
Soluzioni delle competizioni
L’esame delle soluzioni vincenti ha rivelato che non sono necessari strumenti sofisticati o modelli di deep learning per ottenere posizioni elevate. Anche modelli più semplici come la regressione lineare, con un’attenta ingegneria delle caratteristiche, possono vincere premi. La chiave è trovare tecniche semplici ma efficaci per risolvere il problema assegnato.
Ad esempio, il vincitore [4] della competizione GoDaddy – Microbusiness Density Forecasting [5] ha utilizzato la regressione lineare. Questo non sorprende poiché le soluzioni vincenti si basano spesso su modelli semplici ma coinvolgono una selezione estensiva delle caratteristiche, la cross-validazione, l’aumento dei dati e le tecniche di ensemble.
Contributi open-source sui dati tabulari
I contributi open-source relativi ai dati tabulari sono stati preziosi per il progresso del campo e per consentire applicazioni reali. I contributi rientrano principalmente in due categorie:
- Set di dati open-source
- Strumenti open-source
Set di dati open-source
Kaggle deve il suo successo ai generosi contributi dei collaboratori open-source che condividono dataset tabulari reali per problemi di machine learning. Questi dataset, che coprono vari domini e casi d’uso, forniscono dati di formazione e benchmarking preziosi per la comunità di machine learning. Numerose aziende e organizzazioni hanno contribuito apertamente con i loro dati tabulari proprietari per far avanzare il campo. Il notevole numero e la diversità dei dataset disponibili su Kaggle sono stati un fattore essenziale per l’innovazione nel lavorare con dati tabulari.
Il dataset Kaggle [6] è il punto di riferimento per principianti ed esperti che cercano dataset specifici. La vasta collezione di dataset tabulari sta aiutando centinaia di membri della comunità ogni giorno a praticare nuove tecniche e gestire nuovi tipi di dati.
Strumenti Open-Source
Diversi importanti strumenti open-source per analizzare, manipolare e modellare dati tabulari sono stati resi possibili dai contributi delle comunità di sviluppatori. Strumenti come Pandas, Numpy, scikit-learn, TensorFlow, XGBoost e molti altri sono stati elementi cruciali per lavorare con dati tabulari su larga scala. Queste librerie forniscono un set completo di funzionalità che hanno reso l’apprendimento automatico su dati tabulari accessibile a un vasto pubblico. I contributi continui della comunità assicurano che gli strumenti continuino a migliorare e rimangano al passo con le nuove esigenze.
Inoltre, ora ci sono strumenti efficienti disponibili come DuckDB e PySpark, che offrono un modo facile da usare ma potente per analizzare e elaborare grandi dataset tabulari.
%pip install duckdb -qCon DuckDB, è possibile importare facilmente un file CSV ed eseguire query SQL in pochi secondi.
import duckdbduckdb.sql('SELECT * FROM "/kaggle/input/meta-kaggle/Competitions.csv" LIMIT 5')
┌───────┬────────────────┬──────────────────────┬───┬──────────────────────┬──────────┬───────────────────┐│ Id │ Slug │ Title │ … │ EnableSubmissionMo… │ HostName │ CompetitionTypeId ││ int64 │ varchar │ varchar │ │ boolean │ varchar │ int64 │├───────┼────────────────┼──────────────────────┼───┼──────────────────────┼──────────┼───────────────────┤│ 2408 │ Eurovision2010 │ Forecast Eurovisio… │ … │ false │ NULL │ 1 ││ 2435 │ hivprogression │ Predict HIV Progre… │ … │ false │ NULL │ 1 ││ 2438 │ worldcup2010 │ World Cup 2010 - T… │ … │ false │ NULL │ 1 ││ 2439 │ informs2010 │ INFORMS Data Minin… │ … │ false │ NULL │ 1 ││ 2442 │ worldcupconf │ World Cup 2010 - C… │ … │ false │ NULL │ 1 │├───────┴────────────────┴──────────────────────┴───┴──────────────────────┴──────────┴───────────────────┤│ 5 righe 42 colonne (6 mostrate) │└─────────────────────────────────────────────────────────────────────────────────────────────────────────┘Esegui azioni rapide e multiple su dati tabulari utilizzando l’API relazionale di Python. La sua sintassi è simile a quella di pandas, rendendola facile da usare.
rel = duckdb.read_csv('/kaggle/input/meta-kaggle/Competitions.csv')rel.filter("RewardQuantity > 100000").project( "EnabledDate,RewardQuantity").order("RewardQuantity").limit(5)
┌─────────────────────┬────────────────┐│ EnabledDate │ RewardQuantity ││ varchar │ double │├─────────────────────┼────────────────┤│ 07/25/2019 21:10:14 │ 120000.0 ││ 11/02/2021 16:00:27 │ 125000.0 ││ 11/14/2016 08:02:32 │ 150000.0 ││ 11/22/2021 18:53:57 │ 150000.0 ││ 05/11/2022 18:46:43 │ 150000.0 │└─────────────────────┴────────────────┘Intelligenza Artificiale Generativa per i Dati Tabulari
L’Intelligenza Artificiale Generativa è un sottofondo dell’intelligenza artificiale alimentato da reti neurali come Autoencoder Variazionale e Reti Antagonistiche Generative (GAN) che possono generare immagini fotorealistiche, comporre pezzi musicali originali, scrivere articoli di notizie e storie e persino progettare oggetti. È addestrato su grandi set di dati, consentendo ai modelli di Intelligenza Artificiale Generativa di scoprire i modelli sottostanti, le strutture e le distribuzioni statistiche presenti nei dati.
I modelli di Intelligenza Artificiale Generativa hanno significativamente progresso nel campo del lavoro con dati tabulari. Capabilità come l’aumento dei dati, la rilevazione delle anomalie e la generazione di dati sintetici hanno aiutato a affrontare problemi come la scarsità dei dati, la privacy e i pregiudizi.
Tuttavia, recenti avanzamenti come ChatGPT e altri grandi modelli di linguaggio (LLM) vengono ora utilizzati anche come assistenti per compiti di dati tabulari. Alcuni dei modi in cui l’Intelligenza Artificiale Generativa sta trasformando i nostri flussi di lavoro includono:
- Assistenza al codice: I LLM come ChatGPT possono aiutare con compiti di codifica come l’ingegneria delle caratteristiche, la preelaborazione, la modellazione e la valutazione delle pipeline di apprendimento automatico per dati tabulari. Possono suggerire frammenti di codice, funzioni e interi script.
- Comprensione dei dati: L’Intelligenza Artificiale Generativa può fornire informazioni sulle distribuzioni dei dati, le correlazioni, i valori mancanti, le anomalie, le variabili target e altro ancora.
- Analisi approfondita: Esegue test statistici, crea visualizzazioni e deriva altre metriche di riepilogo che forniscono agli operatori un’analisi approfondita dei dataset tabulari per informare le decisioni di modellazione.
- Web scraping: Gli strumenti di Intelligenza Artificiale Generativa possono aiutarti a estrarre nuovi dati tabulari da siti web/applicazioni, assistendo con compiti di acquisizione dati.
Anche se persistono problemi come la sicurezza, i pregiudizi e la capacità limitata, i grandi modelli di linguaggio stanno iniziando a trasformare il modo in cui gli scienziati dei dati e gli ingegneri di apprendimento automatico lavorano con dati tabulari su base quotidiana. Stanno diventando sempre più assistenti che gestiscono vari compiti analitici e di codifica, liberando gli operatori per concentrarsi su lavori di livello superiore.
ChatGPT per i Dati Tabulari
ChatGPT [7] è rapidamente diventato un assistente prezioso per quasi ogni fase di lavoro con dati tabulari, dall’aiuto nella pulizia dei dati e nell’ingegneria delle caratteristiche alla generazione di codice modello complesso, all’interpretazione delle metriche, alla produzione di report di analisi dei dati e persino all’aiuto nella generazione di dati sintetici per compiti come l’aumento dei dati e la rilevazione delle anomalie.
Con ChatGPT, è possibile costruire e addestrare facilmente un modello di apprendimento automatico semplicemente digitando un prompt dettagliato. Inoltre, è possibile utilizzare più plugin per automatizzare compiti complessi come l’esecuzione del codice e l’accesso a Internet.
Consultare “Guida all’utilizzo di ChatGPT per progetti di Data Science”[8] per imparare come utilizzare ChatGPT in un progetto di data science reale da capo a fondo.
Strumenti di Intelligenza Artificiale Generativa per i Dati Tabulari
Gli strumenti di Intelligenza Artificiale Generativa, come PandasAI [9], hanno reso estremamente facile l’analisi dei dati, la pulizia dei dataset e la visualizzazione dei dati per chiunque. Questi strumenti utilizzano grandi modelli di linguaggio come gpt-3.5-turbo [10] per generare risultati illuminanti. Inoltre, è possibile anche connettersi a modelli open-source ospitati su Hugging Face per eseguire analisi di intelligenza artificiale.
%pip install pandasai -q
from kaggle_secrets import UserSecretsClientfrom pandasai import PandasAIfrom pandasai.llm.openai import OpenAIuser_secrets = UserSecretsClient()secret_value_0 = user_secrets.get_secret("OPENAI_API_KEY")llm = OpenAI(api_token=secret_value_0)pandas_ai = PandasAI(llm)Per vedere le prime cinque competizioni con la quantità di premi più alta, abbiamo chiesto a ChatGPT di mostrarle digitando un prompt.
pandas_ai.run(tabular_competitions, prompt='Puoi fornire un elenco delle prime cinque competizioni con la quantità di premi più alta? Mostra solo il nome della competizione, la data e il premio corrispondente.')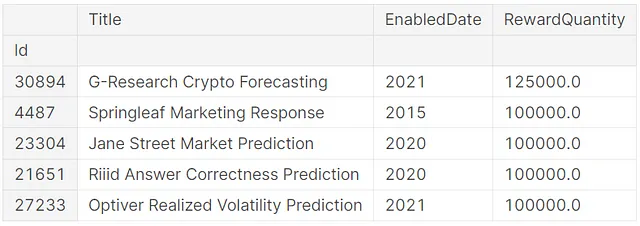
Puoi persino chiedergli di eseguire compiti complessi o generare visualizzazioni.
pandas_ai.run(tabular_competitions, prompt='Per favore elenca tutte le competizioni che contengono la parola "Market".')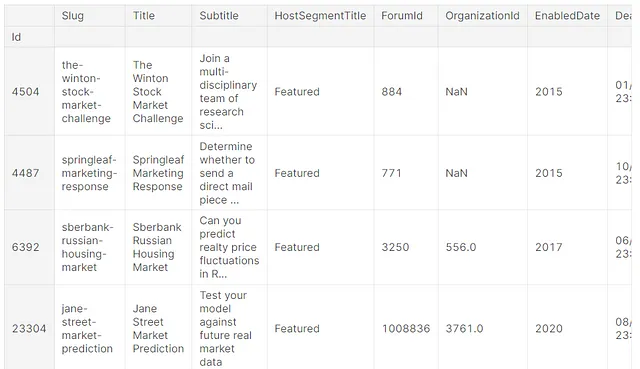
Questo è solo l’inizio, poiché vedremo molti nuovi strumenti di intelligenza artificiale che rendono la vita più facile per gli scienziati dei dati e gli sviluppatori automatizzando compiti e fornendo assistenza.
Conclusioni
Pur essendoci stati progressi significativi nell’utilizzo dei dati tabulari per l’apprendimento automatico e le applicazioni di intelligenza artificiale, abbiamo probabilmente appena iniziato. In futuro, possiamo aspettarci nuovi strumenti potenti guidati da agenti avanzati di intelligenza artificiale [11] che automatizzeranno l’intero flusso di lavoro per compiti di apprendimento automatico su dati tabulari, dall’acquisizione e pulizia dei dati all’ingegneria delle caratteristiche, all’addestramento del modello, alla valutazione e alla distribuzione nelle applicazioni web. Con continui progressi nell’intelligenza artificiale generativa e nell’elaborazione del linguaggio naturale, questi agenti saranno in grado di interpretare indicazioni ad alto livello per completare interi progetti di scienza dei dati tabulari, dai dati alle conoscenze.
Questo saggio evidenzia l’importante impatto delle competizioni Kaggle, delle comunità open-source e dell’intelligenza artificiale generativa nel nostro approccio al lavoro con dati tabulari per compiti come l’analisi dei dati e l’apprendimento automatico. Per approfondire l’argomento, è possibile leggere gli saggi vincitori della competizione Kaggle AI Report 2023[12].
Riferimenti
[1] Contribuenti di Wikipedia, “Kaggle,” Wikipedia, giugno 2023, [Online]. Disponibile: https://it.wikipedia.org/wiki/Kaggle
[2] “Tabular Playground Series — Gen 2021 | Kaggle.” https://www.kaggle.com/competitions/tabular-playground-series-gen-2021
[3] Sdv-Dev, “GitHub — sdv-dev/CTGAN: Conditional GAN per la generazione di dati tabulari sintetici.,” GitHub. https://github.com/sdv-dev/CTGAN
[4] KAGGLEQRDL, “#1 soluzione — generalizzazione con regressione lineare,” 16 marzo 2023. https://www.kaggle.com/competitions/godaddy-microbusiness-density-forecasting/discussion/395131
[5] “GoDaddy — Microbusiness Density Forecasting | Kaggle,” 15 dicembre 2022. https://www.kaggle.com/competitions/godaddy-microbusiness-density-forecasting/overview
[6] “Trova dataset aperti e progetti di apprendimento automatico | Kaggle.” https://www.kaggle.com/datasets
[7] “Introducing ChatGPT,” OpenAI, 30 novembre 2022. https://openai.com/blog/chatgpt
[8] A. A. Awan, “Guida all’utilizzo di ChatGPT per progetti di scienza dei dati,” marzo 2023, [Online]. Disponibile: https://www.datacamp.com/tutorial/chatgpt-data-science-projects
[9] Gventuri, “GitHub — gventuri/pandas-ai: Pandas AI è una libreria Python che integra capacità di intelligenza artificiale generativa in Pandas, rendendo i dataframe conversazionali,” GitHub. https://github.com/gventuri/pandas-ai
[10] “GPT-3.5,” OpenAI. https://platform.openai.com/docs/models/gpt-3-5
[11] R. Cotton, “Introduzione agli agenti di intelligenza artificiale: Iniziare con Auto-GPT, AgentGPT e BabyAGI,” maggio 2023, [Online]. Disponibile: https://www.datacamp.com/tutorial/introduction-to-ai-agents-autogpt-agentgpt-babyagi
[12] “2023 Kaggle AI Report.” Maggio 2023, [Online]. Disponibile: https://www.kaggle.com/competitions/2023-kaggle-ai-report/leaderboard





