Demistificazione della Regressione Logistica Una Guida Semplice
Demistificazione della Regressione Logistica
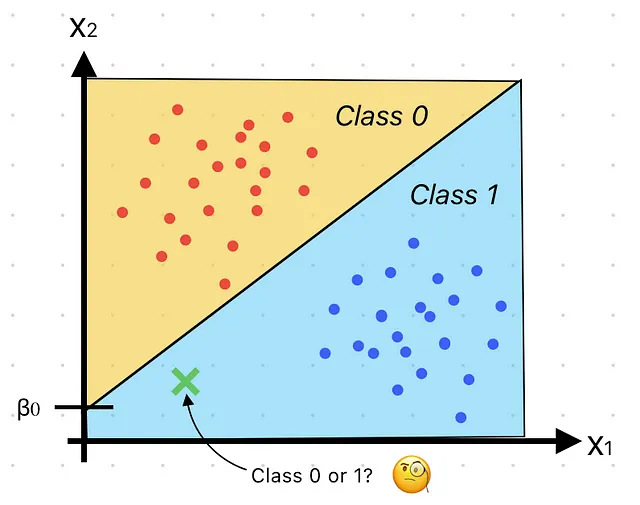
Introduzione
Nel mondo della scienza dei dati e dell’apprendimento automatico, la regressione logistica è un algoritmo potente e ampiamente utilizzato. Nonostante il nome, non ha nulla a che fare con la gestione della logistica o il movimento di merci. Invece, è uno strumento fondamentale per le attività di classificazione, che ci aiuta a prevedere se qualcosa appartiene a una delle due categorie, come sì/no, vero/falso o spam/non spam. In questo blog, analizzeremo il concetto di regressione logistica e lo spiegheremo nel modo più semplice possibile.
Cos’è la regressione logistica?
La regressione logistica è un tipo di algoritmo di apprendimento supervisionato. Il termine “regressione” potrebbe essere fuorviante, poiché non viene utilizzata per prevedere valori continui come nella regressione lineare. Invece, si occupa di problemi di classificazione binaria. In altre parole, risponde a domande che possono essere risposte con un semplice “sì” o “no”.
Immagina di essere un ufficiale delle ammissioni universitarie e di voler prevedere se uno studente verrà ammesso in base ai suoi punteggi ai test. La regressione logistica può aiutarti a fare questa previsione!
- Cos’è la qualità dei dati?
- Perché di più è meglio (nell’Intelligenza Artificiale)
- Un’immersione approfondita nel codice del modello Visual Transformer (ViT)
La funzione sigmoide
Alla base della regressione logistica si trova la funzione sigmoide. Può sembrare complessa, ma è solo una funzione matematica che “schiaccia” qualsiasi input in un valore compreso tra 0 e 1.
La formula per la funzione sigmoide è:
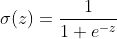
Dove:
- z è l’input per la funzione.
Visualizziamola:
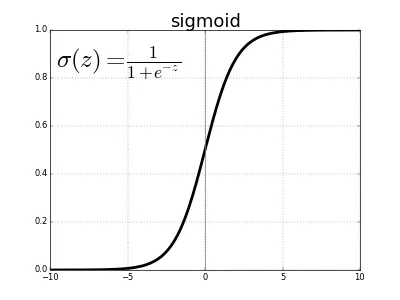
Come puoi vedere, la funzione sigmoide mappa i valori di z grandi e positivi vicino a 1 e i valori grandi e negativi vicino a 0. Quando z = 0, sigmoid(z) è esattamente 0,5.
Effettuare previsioni
Ora che comprendiamo la funzione sigmoide, come ci aiuta a fare previsioni?
Nella regressione logistica, assegniamo un punteggio a ciascun punto dati, che è il risultato di una combinazione lineare delle caratteristiche di input. Quindi, passiamo questo punteggio attraverso la funzione sigmoide per ottenere un valore di probabilità compreso tra 0 e 1.
Matematicamente, il punteggio z viene calcolato come:
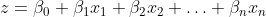
Dove:
- Betas (beta_0, beta_1, beta_2, … , beta_n) sono coefficienti (pesi) che l’algoritmo apprende dai dati di addestramento.
- beta_0 è comunemente noto come peso di bias.
- X (x_1, x_2, … , x_n) sono le caratteristiche di input di un punto dati.
Una volta ottenuta la probabilità sigmoid(z), possiamo interpretarla come la probabilità che il punto dati appartenga alla classe positiva (ad esempio, l’ammissione).
Impostare una soglia
Dato che la regressione logistica ci fornisce probabilità, dobbiamo prendere una decisione basata su quelle probabilità. Lo facciamo impostando una soglia, di solito a 0,5. Se sigmoid(z) è maggiore o uguale a 0,5, prevediamo la classe positiva; altrimenti, prevediamo la classe negativa.
Conclusione
In sintesi, la regressione logistica è un algoritmo semplice ma efficace per problemi di classificazione binaria. Utilizza la funzione sigmoide per mappare i punteggi alle probabilità, facilitando l’interpretazione dei risultati.
Ricorda, la regressione logistica è solo una parte del vasto ed emozionante campo del machine learning, ma è un mattoncino fondamentale nel tuo percorso di data science. Buona classificazione!
TLDR: Cose da ricordare per il blog sulla regressione logistica:
1. Regressione logistica per la classificazione binaria: la regressione logistica è un potente algoritmo utilizzato per compiti di classificazione binaria. Aiuta a prevedere se qualcosa appartiene a una delle due categorie, rendendolo ideale per scenari di sì/no, vero/falso o spam/non spam.
2. Funzione sigmoide: Al centro della regressione logistica si trova la funzione sigmoide, che mappa i valori di input in probabilità comprese tra 0 e 1. Questa funzione è fondamentale per convertire la combinazione lineare delle caratteristiche di input in un punteggio di probabilità.
3. Interpretazione delle probabilità: A differenza di altri metodi di regressione, la regressione logistica produce probabilità invece di valori continui. Queste probabilità rappresentano la probabilità che un punto dati appartenga alla classe positiva, consentendo una comprensione chiara delle previsioni del modello.
4. Impostazione della soglia: Per effettuare previsioni effettive, viene impostata una soglia (solitamente 0,5). Se la probabilità prevista è maggiore o uguale alla soglia, viene prevista la classe positiva; altrimenti, viene prevista la classe negativa. L’aggiustamento della soglia può influire sul compromesso tra precisione e richiamo del modello.
5. Blocco di costruzione fondamentale: La regressione logistica è un concetto fondamentale nel mondo del machine learning e serve come base per algoritmi più complessi. La comprensione della regressione logistica getta le basi per affrontare problemi di classificazione più avanzati ed esplorare un’ampia gamma di applicazioni di data science.
Comprendendo queste cose da ricordare, puoi apprezzare la semplicità e l’importanza della regressione logistica nella risoluzione di compiti di classificazione binaria e intraprendere il tuo viaggio per esplorare ulteriormente il fascinante campo del machine learning.
Grazie per la lettura e spero che questo post ti sia utile. Eventuali commenti o feedback sono molto apprezzati.
Il mio nome è WeiQin Chuah (chiamato Wei dalla maggior parte dei miei colleghi) e sono un ricercatore presso l’Università RMIT di Melbourne, Australia. La mia ricerca si concentra nello sviluppo di modelli robusti di deep learning per risolvere problemi di computer vision. Puoi trovare ulteriori informazioni su di me sulla mia pagina LinkedIn.





