Comprensione degli algoritmi di Machine Learning una panoramica approfondita
Panoramica approfondita degli algoritmi di Machine Learning

Machine Learning. Un blocco di parole impressionante, vero? Dal momento che l’IA e i suoi strumenti, come ChatGPT e Bard, stanno avendo un grande successo in questo momento, è tempo di approfondire e imparare i fondamenti.
Questi concetti fondamentali potrebbero non illuminarti subito, ma se sei interessato ai concetti, avrai ulteriori link per approfondire ancora di più.
La forza dell’apprendimento automatico deriva dai suoi algoritmi complessi, che sono alla base di ogni progetto di apprendimento automatico. A volte questi algoritmi traggono ispirazione dalla cognizione umana, come il riconoscimento vocale o il riconoscimento facciale.
- Chatbot AI costruiscono software in pochi minuti per meno di 1 dollaro
- 4 Modi per Codificare le Caratteristiche Categoriche ad Alta Cardinalità – con Implementazione in Python
- Machine Learning ispirato agli Indigos come una ricerca poetica per l’illuminazione
In questo articolo, passeremo prima attraverso una spiegazione delle classi di apprendimento automatico, come l’apprendimento supervisionato, non supervisionato e per rinforzo.
Poi, affronteremo le attività gestite dall’apprendimento automatico, ovvero la classificazione, la regressione e il clustering.
Dopo di che, scopriremo in modo approfondito gli alberi decisionali, le macchine a vettori di supporto e i vicini più vicini, e la regressione lineare, visualmente e con definizioni.
Ma naturalmente, come puoi scegliere il miglior algoritmo che sia in linea con le tue esigenze? Certo, capire concetti come “comprensione dei dati” o “definizione del tuo problema” ti guiderà nel superare possibili sfide e ostacoli nel tuo progetto.
Iniziamo il viaggio dell’apprendimento automatico!
Categorie di apprendimento automatico
Quando esploriamo l’apprendimento automatico, possiamo vedere che ci sono tre categorie principali che ne plasmano il framework.
- Apprendimento supervisionato
- Apprendimento non supervisionato
- Apprendimento per rinforzo.
Nell’apprendimento supervisionato, l’etichetta che si desidera prevedere è nel dataset.
In questo scenario, l’algoritmo agisce come un attento apprendista, associando le caratteristiche alle uscite corrispondenti. Dopo che la fase di apprendimento è terminata, può proiettare l’output per i nuovi dati e i dati di test. Considera scenari come l’etichettatura di email di spam o la previsione dei prezzi delle case.
Immagina di studiare senza un mentore accanto; deve essere spaventoso. I metodi di apprendimento non supervisionato in particolare fanno questo, fanno previsioni senza etichette.
Vanno coraggiosamente nell’ignoto, scoprendo modelli nascosti e strutture in dati non etichettati, simili agli esploratori che scoprono manufatti perduti.
Comprendere la struttura genetica in biologia e la segmentazione dei clienti nel marketing sono esempi di apprendimento non supervisionato.
Infine, arriviamo all’apprendimento per rinforzo, dove l’algoritmo impara facendo errori, proprio come un cucciolo. Immagina di insegnare a un animale domestico: si scoraggia il comportamento scorretto, mentre si premia il buon comportamento.
Similmente a questo, l’algoritmo compie azioni, sperimenta ricompense o penalità e alla fine capisce come ottimizzare. Questa strategia viene spesso utilizzata in settori come la robotica e i videogiochi.
Tipi di apprendimento automatico
Qui divideremo gli algoritmi di apprendimento automatico in tre sottosezioni. Queste sottosezioni sono Classificazione, Regressione e Clustering.
Classificazione
Come suggerisce il nome, la classificazione si concentra sul processo di raggruppamento o categorizzazione degli elementi. Immagina di essere un botanico incaricato di classificare le piante in categorie benigna o pericolose in base a una serie di caratteristiche. È simile a ordinare le caramelle in barattoli diversi in base ai loro colori.
Regressione
La regressione è il passo successivo; pensaci come un tentativo di prevedere variabili numeriche.
L’obiettivo in questa situazione è prevedere una certa variabile, come il costo di una proprietà considerando le sue caratteristiche (numero di stanze, posizione, ecc.).
È simile a capire le grandi quantità di un frutto usando le sue dimensioni perché non ci sono categorie chiaramente definite, ma piuttosto un intervallo continuo.
Clustering
Ora arriviamo al Clustering, che è paragonabile all’organizzazione di abiti disordinati. Anche se non hai categorie predefinite (o etichette), metti comunque insieme oggetti correlati.
Immagina un algoritmo che, senza conoscenze pregresse sugli argomenti coinvolti, classifichi le notizie in base a quei temi. Il clustering è ovvio lì!
Analizziamo alcuni algoritmi popolari che svolgono questi compiti perché c’è ancora molto da esplorare!
Algoritmi di Apprendimento Automatico Popolari
Qui andremo più in profondità sugli algoritmi di apprendimento automatico popolari, come gli Alberi Decisionali, le Macchine a Vettori di Supporto, i Vicini più Prossimi e la Regressione Lineare.
A. Albero Decisionale
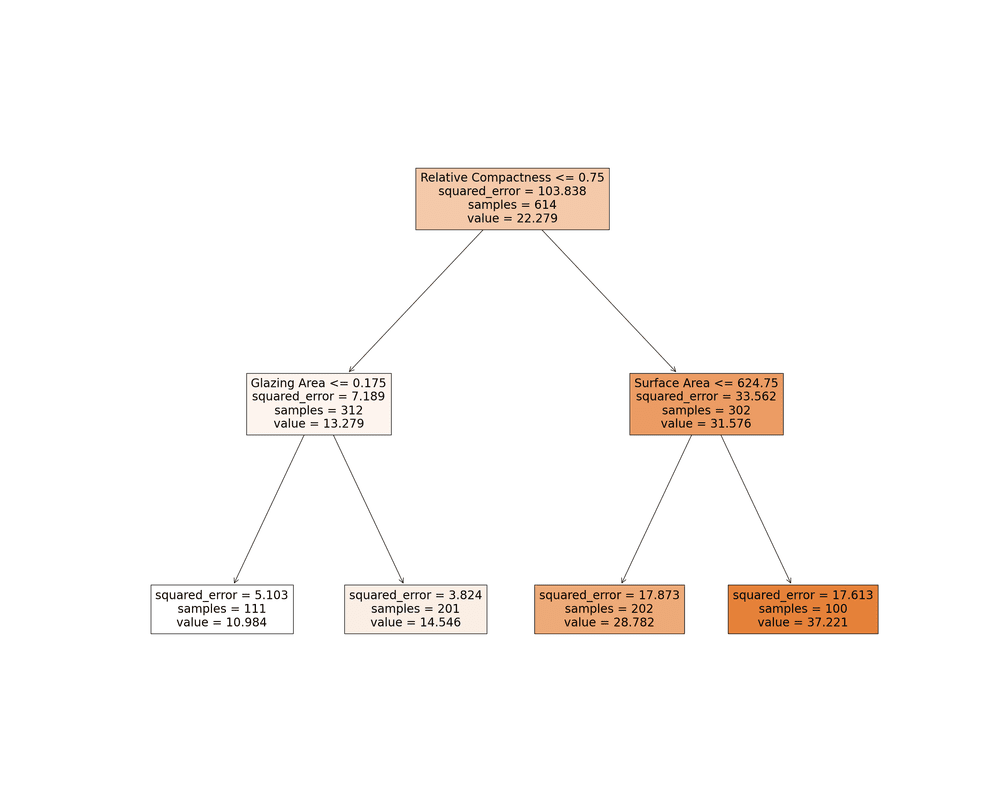
Pensa a pianificare un evento all’aperto e dover decidere se procedere o annullarlo in base alle condizioni meteorologiche. Un Albero Decisionale può essere utilizzato per rappresentare questo processo decisionale.
Un metodo basato su Albero Decisionale nel campo dell’apprendimento automatico (ML) pone una serie di domande binarie sui dati (ad esempio, “Sta piovendo?”) fino a giungere a una decisione (continuare la raccolta o interromperla). Questo metodo è molto utile quando abbiamo bisogno di capire il ragionamento alla base di una previsione.
Se desideri saperne di più sugli alberi decisionali, puoi leggere l’articolo sull’Albero Decisionale e l’Algoritmo Random Forest (fondamentalmente un albero decisionale potenziato).
B. Macchine a Vettori di Supporto (SVM)
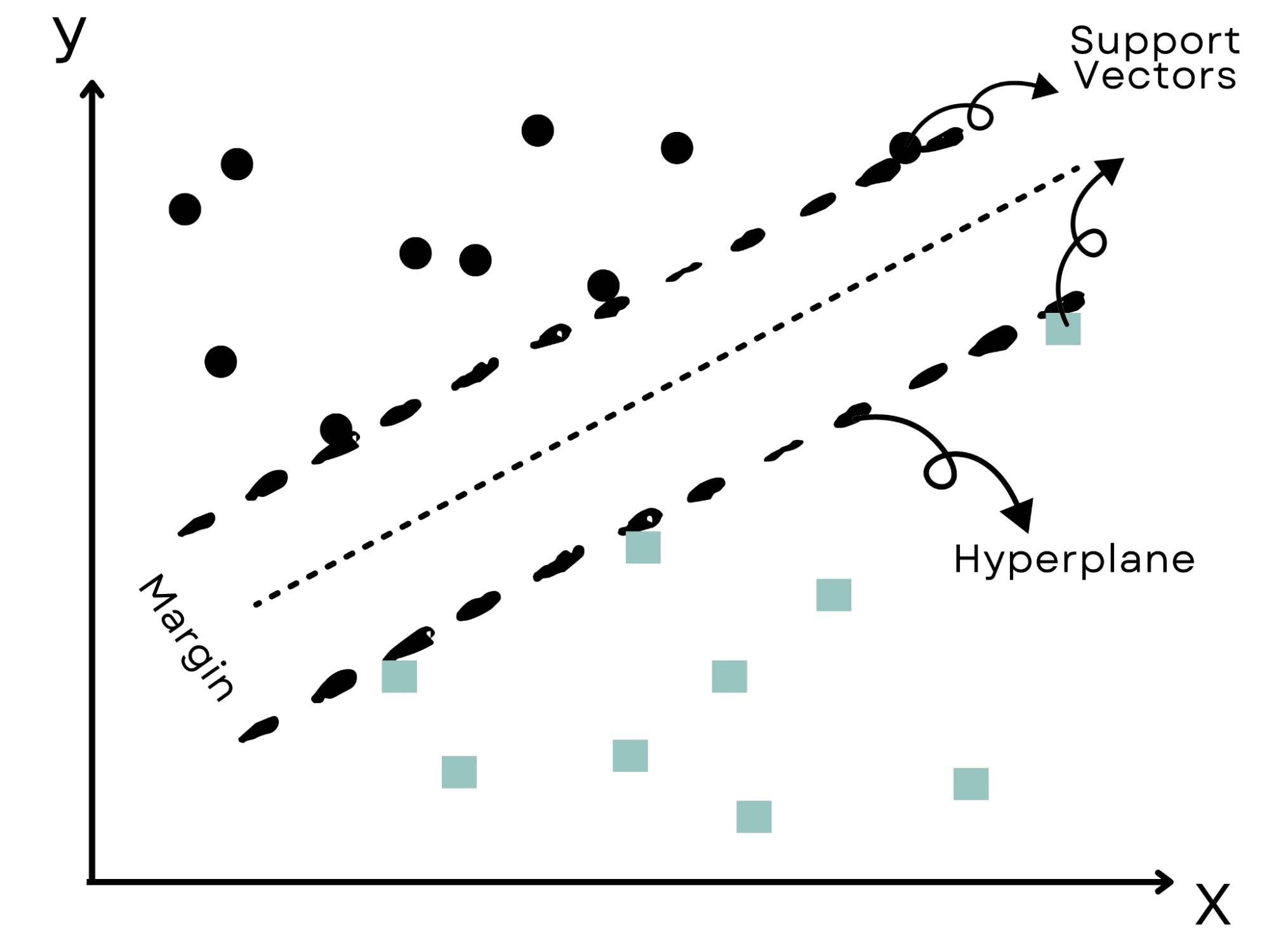
Immagina uno scenario simile al Far West in cui l’obiettivo è dividere due gruppi rivali.
Per evitare conflitti, sceglieremmo il confine più pratico possibile; è esattamente ciò che fanno le Macchine a Vettori di Supporto (SVM).
Identificano il ‘iperpiano’ o confine più efficace che divide i dati in cluster mantenendo la distanza massima dai punti dati più vicini.
Qui puoi trovare maggiori informazioni sulle SVM.
C. Vicini più Prossimi (KNN)
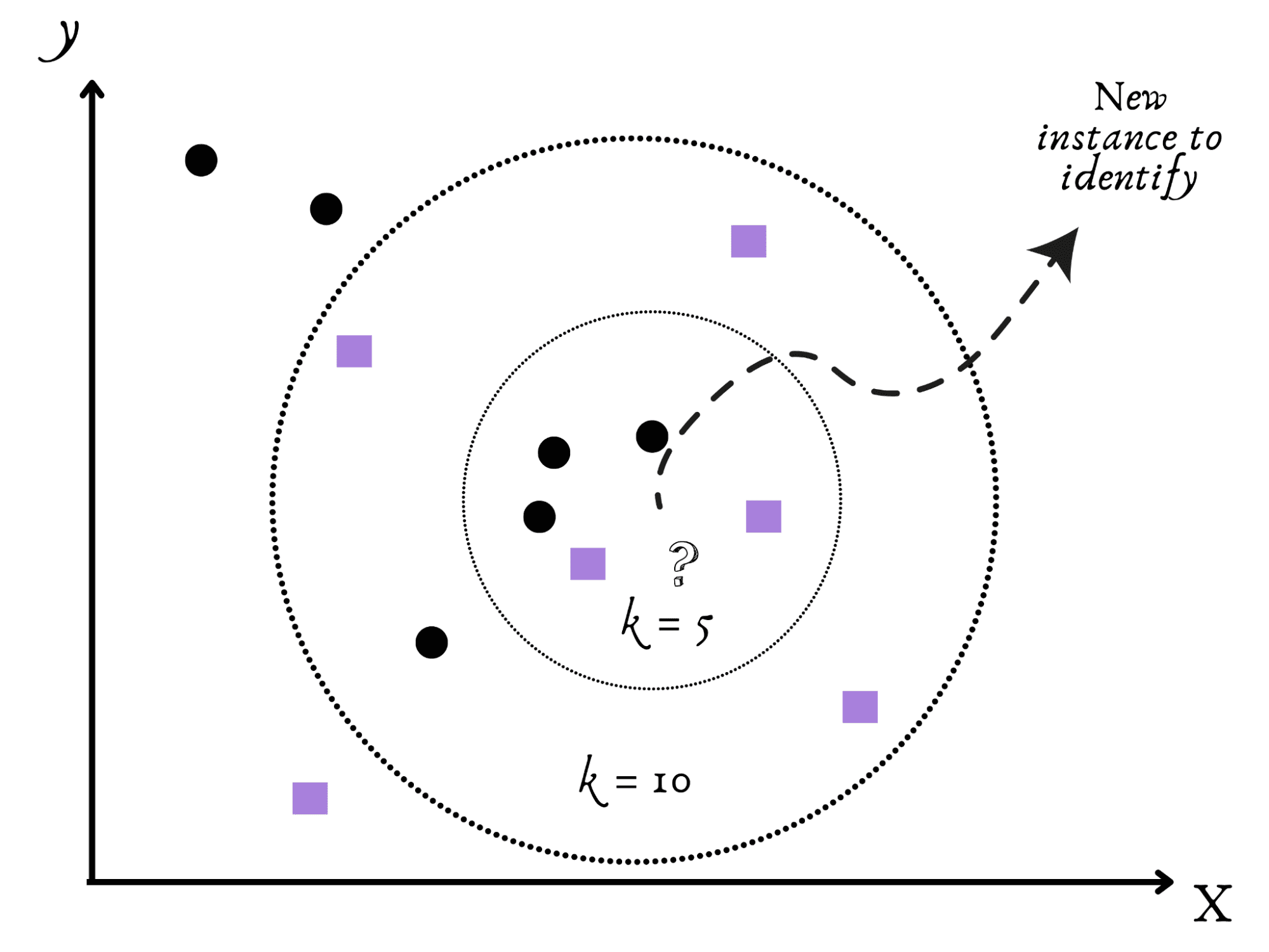
Il K-Nearest Neighbors (KNN), un algoritmo amichevole e sociale, viene dopo.
Immagina di trasferirti in una nuova città e cercare di capire se è tranquilla o movimentata.
Sembra logico che la tua azione naturale sia monitorare i tuoi vicini più prossimi per avere un’idea.
Similmente a questo, il KNN classifica i nuovi dati in base agli argomenti, come ad esempio il k, dei suoi vicini più prossimi nel set di dati.
Qui puoi saperne di più sul KNN.
D. Regressione Lineare
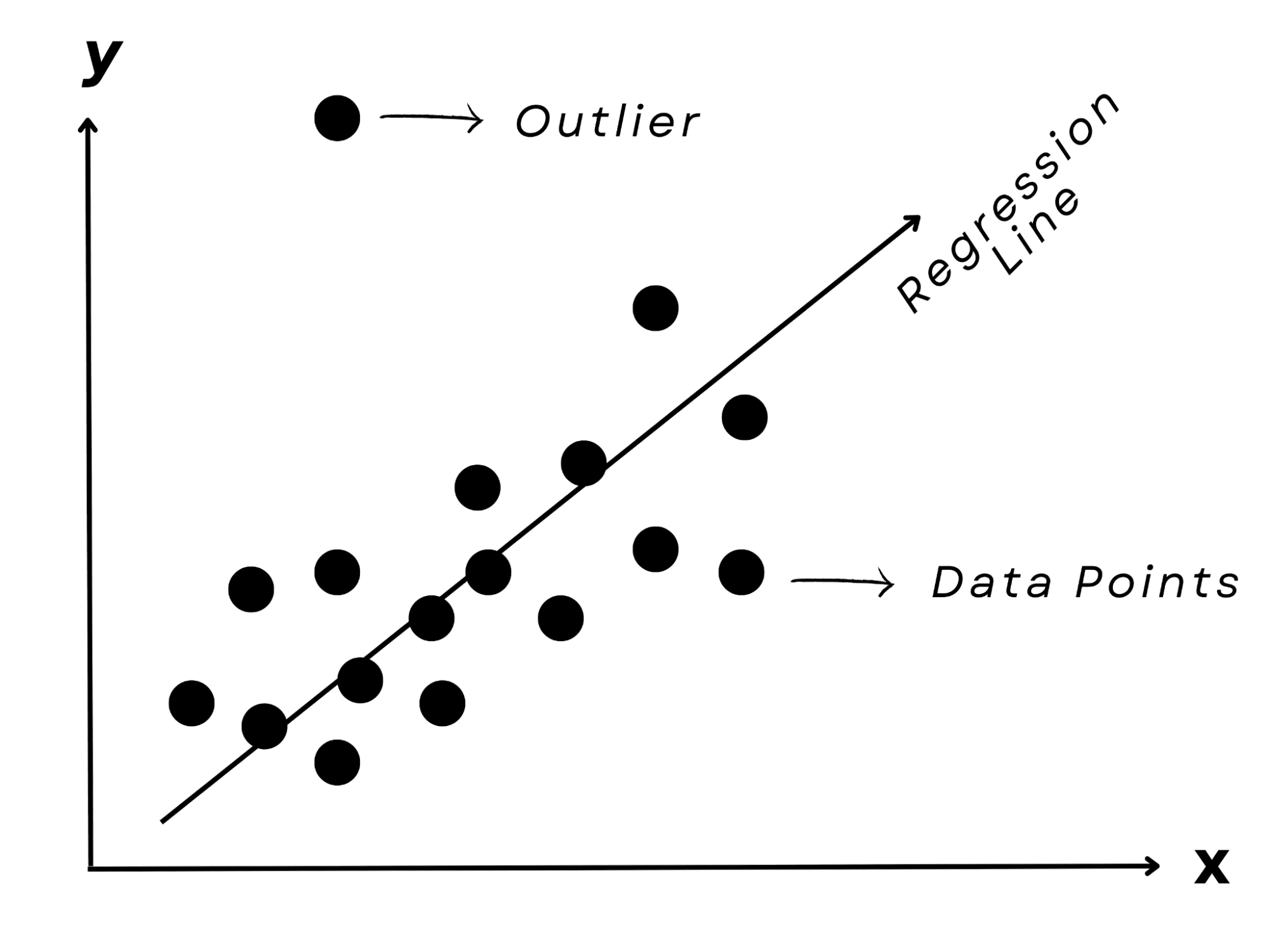
Infine, immagina di cercare di predire il risultato di un esame di un amico in base al numero di ore che ha studiato. Probabilmente noteresti un pattern: più tempo trascorso nello studio di solito si traduce in migliori risultati.
Un modello di regressione lineare, che, come suggerisce il nome, rappresenta la connessione lineare tra l’input (ore di studio) e l’output (voto dell’esame), può catturare questa correlazione.
È un approccio preferito per la previsione di valori numerici, come i costi immobiliari o i valori di mercato delle azioni.
Per saperne di più sulla regressione lineare, puoi leggere questo articolo.
Scegliere il Modello di Apprendimento Automatico Giusto
Scegliere l’algoritmo giusto tra tutte le opzioni a tua disposizione potrebbe sembrare come cercare un ago in un pagliaio molto grande. Ma non preoccuparti! Vediamo di chiarire questo processo con alcune cose importanti da considerare.
A. Comprendi i Tuoi Dati
Considera i tuoi dati come una mappa del tesoro che contiene indizi sul miglior algoritmo.
- Hai etichette sui tuoi dati? (Apprendimento Supervisionato o Non Supervisionato)
- Quante caratteristiche include? (Abbiamo bisogno di riduzione delle dimensioni?)
- È categorico o numerico? (Classificazione o Regressione?)
Le risposte a queste domande potrebbero indirizzarti nella giusta direzione. Al contrario, i dati non etichettati potrebbero favorire algoritmi di apprendimento non supervisionato come il clustering. Ad esempio, i dati etichettati favoriscono l’utilizzo di algoritmi di apprendimento supervisionato come gli alberi decisionali.
B. Definire il tuo problema
Immagina di utilizzare un cacciavite per guidare un chiodo; non molto efficace, vero? La “giusta” “herramienta” o algoritmo può essere scelto definendo chiaramente il tuo problema. Il tuo obiettivo è identificare pattern nascosti (clustering), prevedere una categoria (classificazione) o una metrica (regressione)?
Esistono algoritmi compatibili per ogni tipo di compito.
C. Considerare aspetti pratici
Un algoritmo ideale potrebbe occasionalmente avere una performance peggiore nelle applicazioni reali rispetto alla teoria. La quantità di dati a disposizione, le risorse computazionali disponibili e la necessità dei risultati giocano tutti un ruolo importante.
Ricorda che certi algoritmi, come il KNN, potrebbero avere una performance scadente con grandi dataset, mentre altri, come il Naive Bayes, potrebbero andare bene con dati complessi.
D. Non sottovalutare mai la valutazione
Infine, è cruciale valutare e convalidare le prestazioni del tuo modello. Vuoi assicurarti che l’algoritmo funzioni in modo efficace con i tuoi dati, proprio come provare un vestito prima di acquistarlo.
Questo “fit” può essere misurato utilizzando una varietà di misure, come l’accuratezza per i compiti di classificazione o l’errore quadratico medio per i compiti di regressione.
Conclusione
Non abbiamo percorso una certa distanza?
Come per la categorizzazione di una biblioteca in generi diversi, abbiamo iniziato dividendo il campo dell’apprendimento automatico in Supervised, Unsupervised e Reinforcement Learning. Poi, per capire la diversità dei libri all’interno di questi generi, siamo andati oltre per comprendere i tipi di compiti come classificazione, regressione e clustering, che rientrano in queste categorie.
Abbiamo conosciuto alcuni degli algoritmi di ML, tra cui alberi decisionali, support vector machines, K-nearest neighbors, Naive Bayes e regressione lineare. Ognuno di questi algoritmi ha le proprie specialità e punti di forza.
Abbiamo anche capito che scegliere il giusto algoritmo è come scegliere l’attore ideale per una parte, tenendo conto dei dati, della natura del problema, delle applicazioni reali e della valutazione delle prestazioni.
Ogni progetto di Machine Learning offre un percorso distinto, proprio come ogni libro offre una nuova narrazione.
Ricorda che imparare, sperimentare e migliorare sono più importanti che fare sempre tutto bene dalla prima volta.
Quindi preparati, indossa il tuo cappello da scienziato dei dati e intraprendi la tua avventura di ML! Nate Rosidi è un data scientist e stratega di prodotto. È anche professore a contratto che insegna analisi dei dati ed è fondatore di StrataScratch, una piattaforma che aiuta i data scientist a prepararsi per i colloqui con domande di interviste reali delle migliori aziende. Connettiti con lui su Twitter: StrataScratch o LinkedIn.