Grandi modelli di linguaggio SBERT
Big SBERT Language Models
Scopri come le reti Siamese BERT trasformano accuratamente le frasi in embeddng
Introduzione
Non è un segreto che i transformer abbiano fatto progressi evolutivi nell’NLP. Basandosi sui transformer, molti altri modelli di apprendimento automatico sono evoluti. Uno di essi è BERT, che consiste principalmente in diversi encoder di transformer impilati. Oltre ad essere utilizzato per una serie di problemi diversi come l’analisi del sentiment o la risposta alle domande, BERT è diventato sempre più popolare per la costruzione di embeddings di parole – vettori di numeri che rappresentano i significati semantici delle parole.
Rappresentare le parole sotto forma di embeddings ha dato un enorme vantaggio poiché gli algoritmi di apprendimento automatico non possono lavorare con testi grezzi ma possono operare su vettori di vettori. Ciò consente di confrontare diverse parole in base alla loro similarità utilizzando una metrica standard come la distanza euclidea o coseno.
Il problema è che, nella pratica, spesso è necessario costruire embeddings non per singole parole ma per intere frasi. Tuttavia, la versione di base di BERT costruisce embeddings solo a livello di parola. A causa di ciò, sono state sviluppate successivamente diverse approcci simili a BERT per risolvere questo problema che verranno discussi in questo articolo. Discutendoli progressivamente, raggiungeremo poi il modello all’avanguardia chiamato SBERT.
- I ricercatori di Microsoft svelano PromptTTS 2 rivoluzionando il Text-to-Speech con una maggiore variabilità della voce e una generazione di prompt a basso costo.
- Il modello di intelligenza artificiale accelera la visione artificiale ad alta risoluzione
- I registi Guillermo del Toro e Tim Burton hanno due diverse visioni dell’IA
Per comprendere a fondo come funziona SBERT nel dettaglio, è consigliabile essere già familiari con BERT. Se non lo si è, la parte precedente di questa serie di articoli lo spiega in dettaglio.
Large Language Models: BERT
Comprendere come BERT costruisce embeddings all’avanguardia
towardsdatascience.com
BERT
Prima di tutto, ricordiamo come BERT elabora le informazioni. In input, prende un token [CLS] e due frasi separate da un token speciale [SEP]. A seconda della configurazione del modello, queste informazioni vengono elaborate 12 o 24 volte da blocchi di attenzione multi-head. L’output viene quindi aggregato e passato a un semplice modello di regressione per ottenere l’etichetta finale.
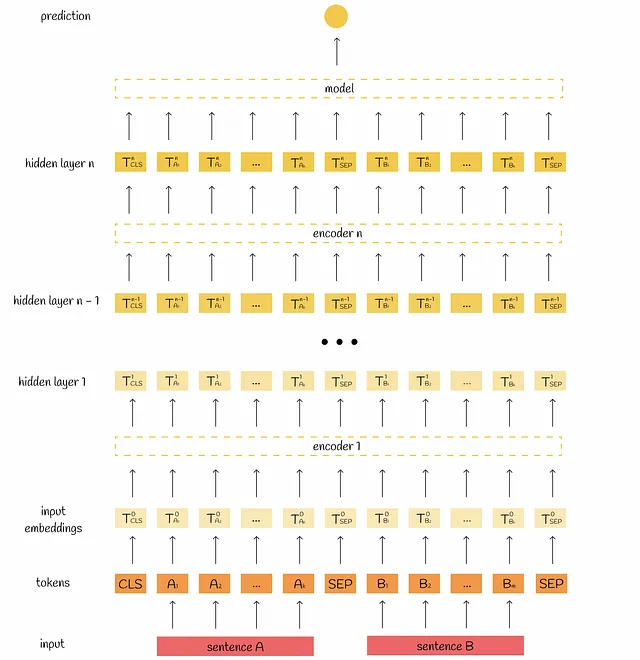
Per ulteriori informazioni sul funzionamento interno di BERT, si può fare riferimento alla parte precedente di questa serie di articoli:
Architettura cross-encoder
È possibile utilizzare BERT per il calcolo della similarità tra una coppia di documenti. Consideriamo l’obiettivo di trovare la coppia di frasi più simile in una grande collezione. Per risolvere questo problema, ogni possibile coppia viene inserita nel modello BERT. Ciò porta a una complessità quadratica durante l’infrazione. Ad esempio, gestire n = 10.000 frasi richiede n * (n – 1) / 2 = 49.995.000 calcoli di inferenza BERT che non è davvero scalabile.
Altri approcci
Analizzando l’inefficienza dell’architettura cross-encoder, sembra logico precalcolare gli embeddings in modo indipendente per ogni frase. Dopodiché, possiamo calcolare direttamente la metrica di distanza scelta su tutte le coppie di documenti, il che è molto più veloce che alimentare un numero quadratico di coppie di frasi a BERT.
Sfortunatamente, questo approccio non è possibile con BERT: il problema principale di BERT è che ogni volta vengono passate e processate contemporaneamente due frasi, rendendo difficile ottenere embeddings che rappresentino indipendentemente una singola frase.
I ricercatori hanno cercato di eliminare questo problema utilizzando l’embedding del token [CLS] in uscita nella speranza che contenesse informazioni sufficienti per rappresentare una frase. Tuttavia, il [CLS] si è rivelato del tutto inutile per questo compito semplicemente perché è stato inizialmente pre-addestrato in BERT per la previsione della frase successiva.
Un altro approccio consisteva nel passare una singola frase a BERT e quindi fare la media degli embeddings dei token di output. Tuttavia, i risultati ottenuti erano ancora peggiori rispetto alla semplice media degli embeddings GLoVe.
La derivazione di embeddings di frasi indipendenti è uno dei principali problemi di BERT. Per alleviare questo aspetto, è stato sviluppato SBERT.
SBERT
SBERT introduce il concetto di rete Siamese, il che significa che ogni volta che due frasi vengono passate indipendentemente attraverso lo stesso modello BERT. Prima di discutere dell’architettura di SBERT, facciamo riferimento ad una nota sottile sulle reti Siamese:
La maggior parte delle volte nei documenti scientifici, un’architettura di rete Siamese viene rappresentata con diversi modelli che ricevono così tanti input. In realtà, può essere considerata come un singolo modello con la stessa configurazione e pesi condivisi su diversi input paralleli. Ogni volta che i pesi del modello vengono aggiornati per un singolo input, vengono aggiornati allo stesso modo per gli altri input.
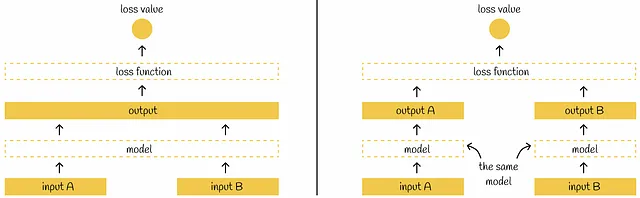
Tornando a SBERT, dopo aver passato una frase attraverso BERT, viene applicato uno strato di pooling agli embeddings di BERT per ottenere la loro rappresentazione di dimensione inferiore: i vettori iniziali di 512 dimensioni 768 vengono trasformati in un singolo vettore di 768 dimensioni. Per lo strato di pooling, gli autori di SBERT propongono di scegliere un layer di mean-pooling come uno di default, anche se menzionano anche che è possibile utilizzare la strategia di max-pooling o semplicemente prendere l’output del token [CLS].
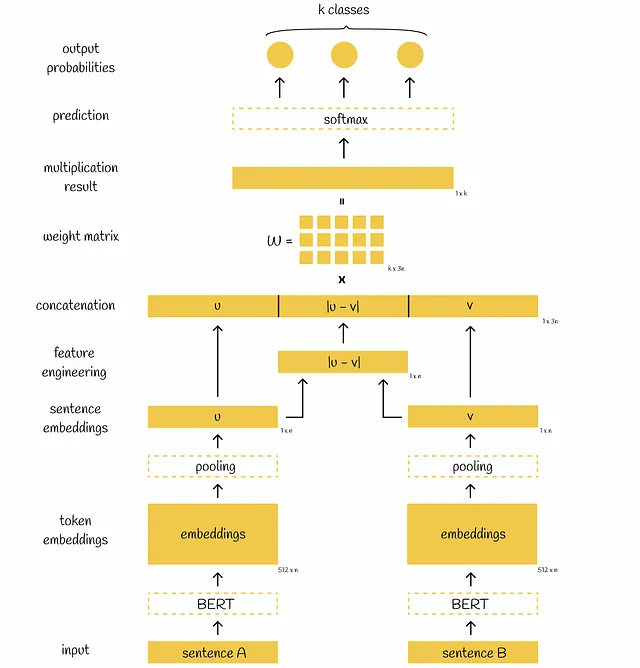
Quando entrambe le frasi vengono passate attraverso gli strati di pooling, otteniamo due vettori di 768 dimensioni u e v. Utilizzando questi due vettori, gli autori propongono tre approcci per ottimizzare diversi obiettivi che saranno discussi di seguito.
Funzione obiettivo di classificazione
Lo scopo di questo problema è classificare correttamente una coppia di frasi in una delle varie classi.
Dopo la generazione degli embeddings u e v, i ricercatori hanno trovato utile generare un altro vettore derivato da questi due come la differenza assoluta elemento per elemento |u-v|. Hanno anche provato altre tecniche di ingegnerizzazione delle features, ma questa ha mostrato i migliori risultati.
Infine, i tre vettori u, v e |u-v| vengono concatenati, moltiplicati per una matrice di pesi addestrabili W e il risultato della moltiplicazione viene alimentato al classificatore softmax che restituisce le probabilità normalizzate delle frasi corrispondenti alle diverse classi. Viene utilizzata la funzione di perdita cross-entropy per aggiornare i pesi del modello.
Uno dei problemi più popolari utilizzati per essere risolti con questo obiettivo è l’NLI (Natural Language Inference), dove per una coppia di frasi A e B che definiscono l’ipotesi e il presupposto, è necessario prevedere se l’ipotesi è vera (entailment), falsa (contradiction) o indeterminata (neutral) dato il presupposto. Per questo problema, il processo di inferenza è lo stesso del training.
Come indicato nel paper, il modello SBERT è originariamente addestrato su due dataset SNLI e MultiNLI che contengono un milione di coppie di frasi con etichette corrispondenti di entailment, contradiction o neutral. Dopo di ciò, i ricercatori del paper menzionano i dettagli sui parametri di sintonizzazione di SBERT:
“Abbiamo sintonizzato SBERT con una funzione obiettivo softmax-classifier a 3 vie per una epoca. Abbiamo utilizzato una dimensione di batch di 16, l’ottimizzatore Adam con un tasso di apprendimento di 2e−5 e una fase di riscaldamento del tasso di apprendimento lineare su 10% dei dati di addestramento. La nostra strategia di pooling predefinita è quella del mean.”
Funzione obiettivo di regressione
In questa formulazione, dopo aver ottenuto i vettori u e v, il punteggio di similarità tra di loro viene calcolato direttamente utilizzando una metrica di similarità scelta. Il punteggio di similarità previsto viene confrontato con il valore reale e il modello viene aggiornato utilizzando la funzione di perdita MSE. Per impostazione predefinita, gli autori scelgono la similarità del coseno come metrica di similarità.
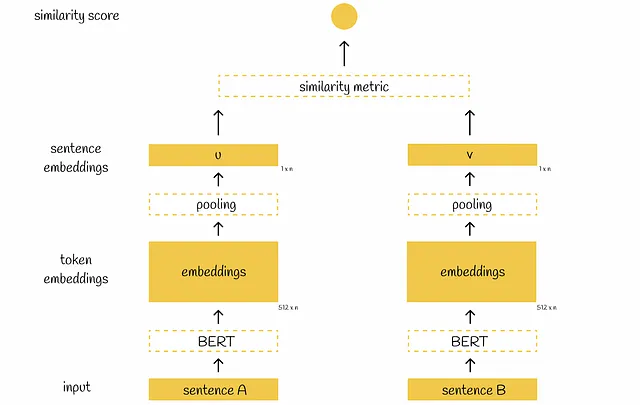
Durante l’inferring, questa architettura può essere utilizzata in uno dei due modi:
- Con una coppia di frasi data, è possibile calcolare il punteggio di similarità. Il flusso di lavoro di inferring è assolutamente lo stesso di quello di addestramento.
- Per una data frase, è possibile estrarre la sua embedding di frase (subito dopo l’applicazione del pooling layer) per un uso successivo. Questo è particolarmente utile quando si dispone di una vasta collezione di frasi con l’obiettivo di calcolare i punteggi di similarità a coppie tra di loro. Eseguendo ogni frase attraverso BERT solo una volta, si estraggono tutte le embedding di frase necessarie. Dopo di che, è possibile calcolare direttamente la metrica di similarità scelta tra tutti i vettori (senza dubbio, richiede comunque un numero quadratico di confronti, ma allo stesso tempo si evitano i calcoli di inferring quadratici con BERT come prima).
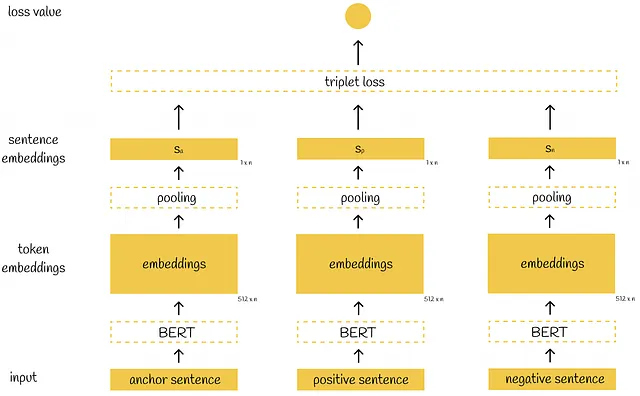
Funzione obiettivo del triplet
La funzione obiettivo del triplet introduce una perdita del triplet che viene calcolata su tre frasi di solito chiamate ancoraggio, positiva e negativa. Si assume che le frasi di ancoraggio e positive siano molto vicine tra loro mentre l’ancoraggio e la negativa siano molto diverse. Durante il processo di addestramento, il modello valuta quanto le coppie (ancoraggio, positiva) siano più vicine rispetto alle coppie (ancoraggio, negativa). Matematicamente, la seguente funzione di perdita viene minimizzata:
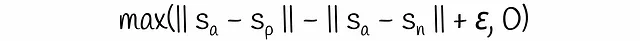
Il margine ε garantisce che una frase positiva sia più vicina all’ancoraggio di almeno ε rispetto alla frase negativa rispetto all’ancoraggio. In caso contrario, la perdita diventa maggiore di 0. Per impostazione predefinita, in questa formula, gli autori scelgono la distanza euclidea come norma del vettore e il parametro ε è impostato su 1.
L’architettura SBERT triplet si differenzia dalle due precedenti perché il modello ora accetta contemporaneamente tre frasi di input (anziché due).
Codice
SentenceTransformers è una libreria Python all’avanguardia per la creazione di embedding di frasi. Contiene diversi modelli preaddestrati per diverse attività. La creazione di embedding con SentenceTransformers è semplice e di seguito è mostrato un esempio nel frammento di codice sottostante.
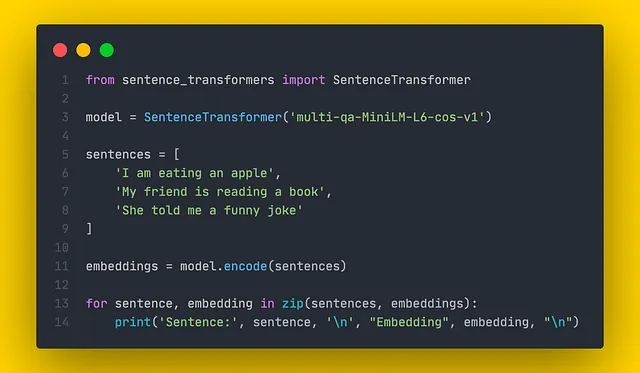
Gli embedding creati possono quindi essere utilizzati per il confronto di similarità. Ogni modello è addestrato per una determinata attività, quindi è sempre importante scegliere una metrica di similarità appropriata per il confronto facendo riferimento alla documentazione.
Conclusioni
Abbiamo esaminato uno dei modelli NLP avanzati per ottenere embedding di frasi. Riducendo il numero quadratico di esecuzioni di inferenza di BERT a lineare, SBERT ottiene una crescita massiccia in velocità mantenendo al contempo un’alta precisione.
Per comprendere finalmente quanto sia significativa questa differenza, è sufficiente fare riferimento all’esempio descritto nel documento in cui i ricercatori hanno cercato di trovare la coppia più simile tra n = 10000 frasi. Su una moderna GPU V100, questa procedura ha richiesto circa 65 ore con BERT e solo 5 secondi con SBERT! Questo esempio dimostra che SBERT è un enorme avanzamento nell’NLP.
Risorse
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- SentenceTransformers Documentation | SBERT.net
- Natural Language Inference | Papers with code
Tutte le immagini, salvo diversa indicazione, sono dell’autore






