Panoramica dei schemi di quantizzazione supportati nativamente in 🤗 Transformers
Panoramica schemi di quantizzazione 🤗 Transformers
Aimiamo a fornire una panoramica chiara dei pro e dei contro di ogni schema di quantizzazione supportato nei transformers per aiutarti a decidere quale scegliere.
Attualmente, i modelli quantizzati vengono utilizzati per due scopi principali:
- Eseguire inferenze di un modello di grandi dimensioni su un dispositivo più piccolo
- Perfezionare gli adattatori su modelli quantizzati
Fino ad ora, sono stati fatti due sforzi di integrazione e sono nativamente supportati nei transformers: bitsandbytes e auto-gptq. Si noti che alcuni schemi di quantizzazione aggiuntivi sono supportati anche nella libreria 🤗 optimum, ma questo esula dallo scopo di questo articolo del blog.
Per saperne di più su ciascuno degli schemi supportati, si prega di consultare una delle risorse condivise di seguito. Si prega inoltre di consultare le sezioni appropriate della documentazione.
- I ricercatori di AI di Baidu presentano VideoGen un nuovo approccio di generazione di testo in video che può generare video ad alta definizione con alta fedeltà di frame.
- 15 progetti che utilizzano l’IA per raggiungere gli Obiettivi Globali delle Nazioni Unite
- Statistica in Data Science Teoria e Panoramica
Si noti anche che i dettagli condivisi di seguito sono validi solo per i modelli PyTorch, attualmente questo non è incluso nei modelli Tensorflow e Flax/JAX.
Indice
- Risorse
- Pro e contro di bitsandbytes e auto-gptq
- Approfondimento sui benchmark di velocità
- Conclusione e parole finali
- Riconoscimenti
Risorse
- Articolo del blog su GPTQ – fornisce una panoramica su cosa è il metodo di quantizzazione GPTQ e come usarlo.
- Articolo del blog sulla quantizzazione a 4 bit di bitsandbytes: Questo articolo del blog introduce la quantizzazione a 4 bit e QLoRa, un approccio efficiente di fine-tuning.
- Articolo del blog sulla quantizzazione a 8 bit di bitsandbytes – Questo articolo del blog spiega come funziona la quantizzazione a 8 bit con bitsandbytes.
- Notebook di utilizzo di base di Google Colab per GPTQ – Questo notebook mostra come quantizzare il tuo modello transformers con il metodo GPTQ, come fare inferenza e come fare il fine-tuning con il modello quantizzato.
- Notebook di utilizzo di base di Google Colab per bitsandbytes – Questo notebook mostra come utilizzare modelli a 4 bit nell’inferenza con tutte le loro varianti e come eseguire GPT-neo-X (un modello a 20B di parametri) su un’istanza gratuita di Google Colab.
- Articolo del blog di Merve sulla quantizzazione – Questo articolo del blog fornisce un’introduzione semplice alla quantizzazione e ai metodi di quantizzazione supportati nativamente nei transformers.
Pro e contro di bitsandbyes e auto-gptq
In questa sezione, esamineremo i pro e i contro della quantizzazione di bitsandbytes e gptq. Si noti che questi si basano sui feedback della comunità e possono evolvere nel tempo in quanto alcune di queste funzionalità sono nel programma delle rispettive librerie.
Pro di bitsandbytes
Semplice: bitsandbytes rimane ancora il modo più semplice per quantizzare qualsiasi modello in quanto non richiede la calibrazione del modello quantizzato con i dati di input (chiamata anche quantizzazione zero-shot). È possibile quantizzare qualsiasi modello immediatamente, purché contenga moduli torch.nn.Linear. Ogni volta che viene aggiunta un’architettura ai transformers, purché possano essere caricati con device_map="auto" di accelerate, gli utenti possono beneficiare della quantizzazione bitsandbytes immediatamente, con una degradazione minima delle prestazioni. La quantizzazione viene eseguita durante il caricamento del modello, non è necessario eseguire alcun passaggio di post-elaborazione o preparazione.
Interoperabilità tra modalità incrociate: Essendo l’unica condizione per quantizzare un modello quella di contenere uno strato torch.nn.Linear, la quantizzazione funziona immediatamente per qualsiasi modalità, rendendo possibile caricare modelli come Whisper, ViT, Blip2, ecc. a 8 bit o 4 bit immediatamente.
0 degrado delle prestazioni quando si uniscono adattatori: (Leggi di più sugli adattatori e PEFT in questo articolo del blog se non ne sei familiare). Se si allenano adattatori sulla base del modello quantizzato, gli adattatori possono essere uniti sulla base del modello per il deployment, senza alcun degrado delle prestazioni durante l’inferenza. È anche possibile unire gli adattatori sulla base del modello dequantizzato! Questo non è supportato per GPTQ.
Pro di autoGPTQ
Veloce per la generazione di testo: I modelli quantizzati GPTQ sono veloci rispetto ai modelli quantizzati bitsandbytes per la generazione di testo. Affronteremo il confronto di velocità in una sezione appropriata.
Supporto n-bit: L’algoritmo GPTQ consente di quantizzare modelli fino a 2 bit! Tuttavia, ciò potrebbe comportare una grave degradazione della qualità. Il numero consigliato di bit è 4, che sembra essere un ottimo compromesso per GPTQ in questo momento.
Facilmente serializzabile: I modelli GPTQ supportano la serializzazione per qualsiasi numero di bit. Il caricamento dei modelli dal namespace TheBloke: https://huggingface.co/TheBloke (cerca quelli che terminano con il suffisso -GPTQ) è supportato out of the box, purché si abbiano installati i pacchetti richiesti. Bitsandbytes supporta la serializzazione a 8 bit ma non supporta la serializzazione a 4 bit al momento.
Supporto AMD: L’integrazione dovrebbe funzionare out of the box per le GPU AMD!
Svantaggi di bitsandbytes
Più lento di GPTQ per la generazione di testo: I modelli bitsandbytes a 4 bit sono lenti rispetto a GPTQ quando si usa generate.
I pesi a 4 bit non sono serializzabili: Attualmente, i modelli a 4 bit non possono essere serializzati. Questa è una richiesta frequente della comunità e crediamo che dovrebbe essere affrontata molto presto dagli sviluppatori di bitsandbytes poiché è nella loro roadmap!
Svantaggi di autoGPTQ
Calibration dataset: La necessità di un calibration dataset potrebbe scoraggiare alcuni utenti ad optare per GPTQ. Inoltre, potrebbe richiedere diverse ore per quantizzare il modello (ad esempio, 4 ore di GPU per un modello da 180B)
Funziona solo per modelli di linguaggio (per ora): Al momento, l’API per quantizzare un modello con auto-GPTQ è stata progettata per supportare solo modelli di linguaggio. Dovrebbe essere possibile quantizzare modelli non testuali (o multimodali) utilizzando l’algoritmo GPTQ, ma il processo non è stato elaborato nel paper originale o nel repository di auto-gptq. Se la comunità è entusiasta di questo argomento, potrebbe essere preso in considerazione in futuro.
Approfondimento sui benchmark di velocità
Abbiamo deciso di fornire un benchmark esteso sia per gli adattatori di inferenza che per i finetuning utilizzando bitsandbytes e auto-gptq su hardware diversi. Il benchmark di inferenza dovrebbe fornire agli utenti un’idea della differenza di velocità che potrebbero ottenere tra i diversi approcci che proponiamo per l’inferenza, mentre il benchmark del finetuning degli adattatori dovrebbe fornire un’idea chiara agli utenti quando si tratta di decidere quale approccio utilizzare per il finetuning degli adattatori su modelli base bitsandbytes e GPTQ.
Utilizzeremo la seguente configurazione:
- bitsandbytes: quantizzazione a 4 bit con
bnb_4bit_compute_dtype=torch.float16. Assicurarsi di utilizzarebitsandbytes>=0.41.1per i kernel a 4 bit veloci. - auto-gptq: quantizzazione a 4 bit con kernel exllama. È necessario
auto-gptq>=0.4.0per utilizzare i kernel ex-llama.
Velocità di inferenza (solo passaggio in avanti)
Questo benchmark misura solo la fase di prefill, che corrisponde al passaggio in avanti durante l’addestramento. È stato eseguito su una singola GPU NVIDIA A100-SXM4-80GB con una lunghezza di prompt di 512. Il modello utilizzato era meta-llama/Llama-2-13b-hf.
con dimensione batch = 1:
con dimensione batch = 16:
Dal benchmark, possiamo vedere che bitsandbytes e GPTQ sono equivalenti, con GPTQ leggermente più veloce per dimensioni batch grandi. Controlla questo link per maggiori dettagli su questi benchmark.
Velocità di generazione
I seguenti benchmark misurano la velocità di generazione del modello durante l’inferenza. Lo script di benchmarking può essere trovato qui per la riproducibilità.
use_cache
Testiamo use_cache per capire meglio l’impatto della memorizzazione nella cache dello stato nascosto durante la generazione.
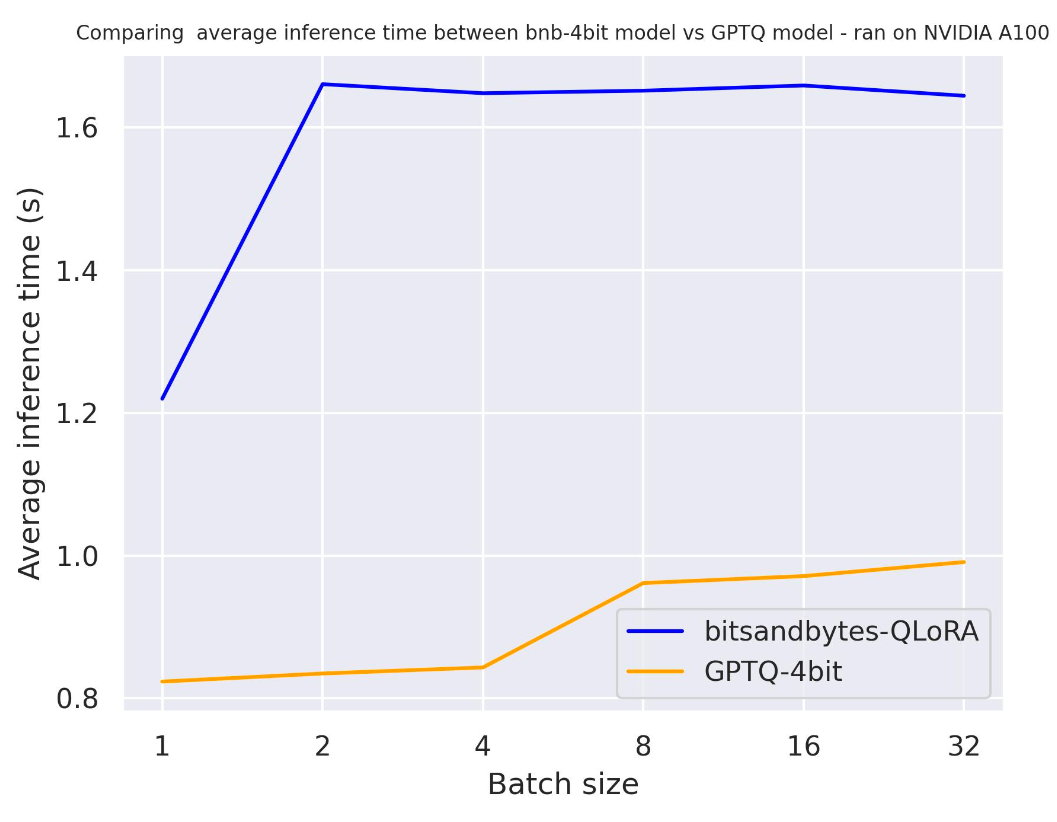
Il benchmark è stato eseguito su un A100 con una lunghezza di prompt di 30 e abbiamo generato esattamente 30 token. Il modello utilizzato era meta-llama/Llama-2-7b-hf.
con use_cache=True
con use_cache=False
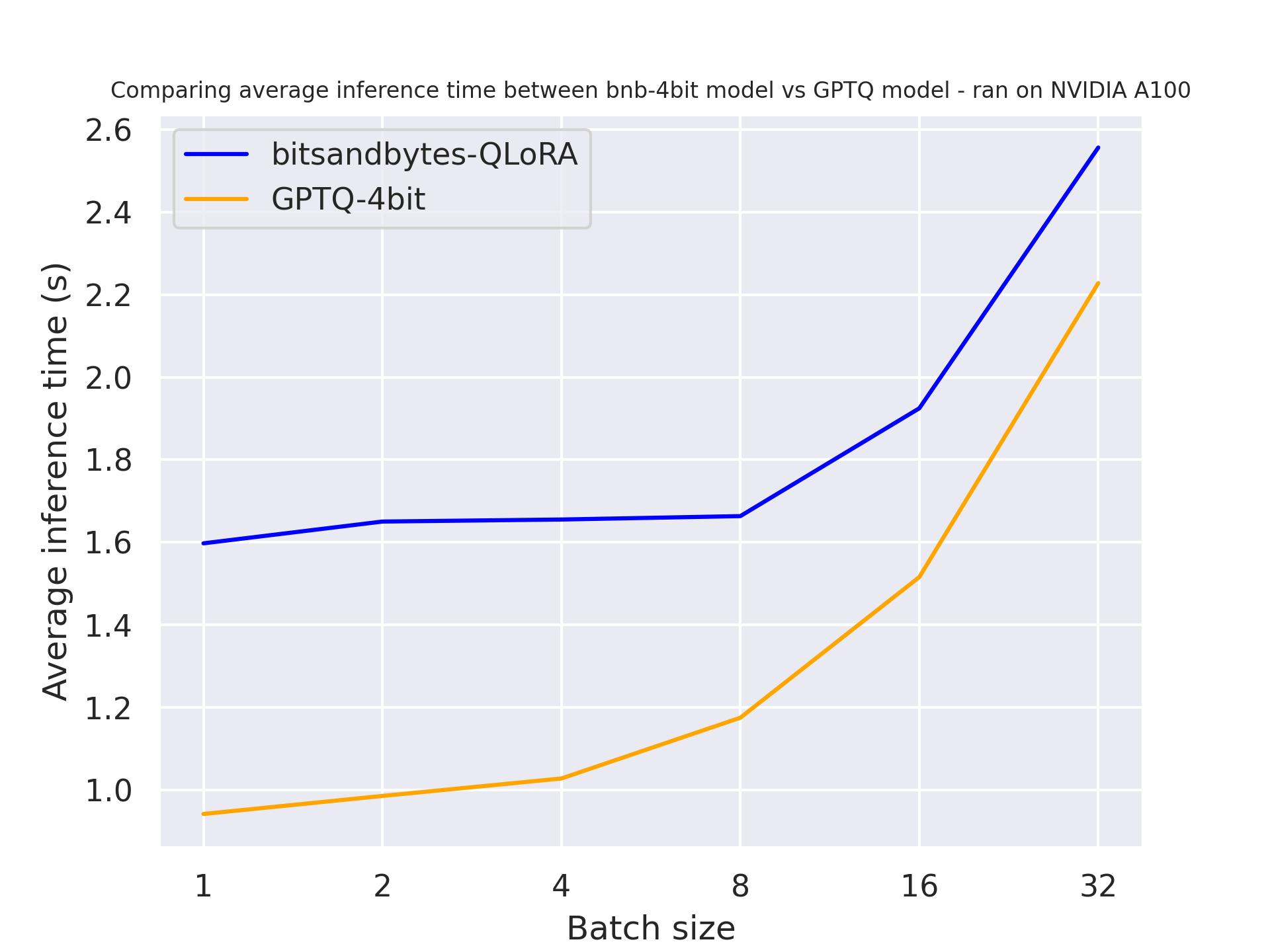
Dai due benchmark, possiamo concludere che la generazione è più veloce quando utilizziamo la memorizzazione nella cache dell’attenzione, come previsto. Inoltre, GPTQ è, in generale, più veloce di bitsandbytes. Ad esempio, con batch_size=4 e use_cache=True, è due volte più veloce! Pertanto, utilizzeremo use_cache per i prossimi benchmark. Nota che use_cache consumerà più memoria.
Hardware
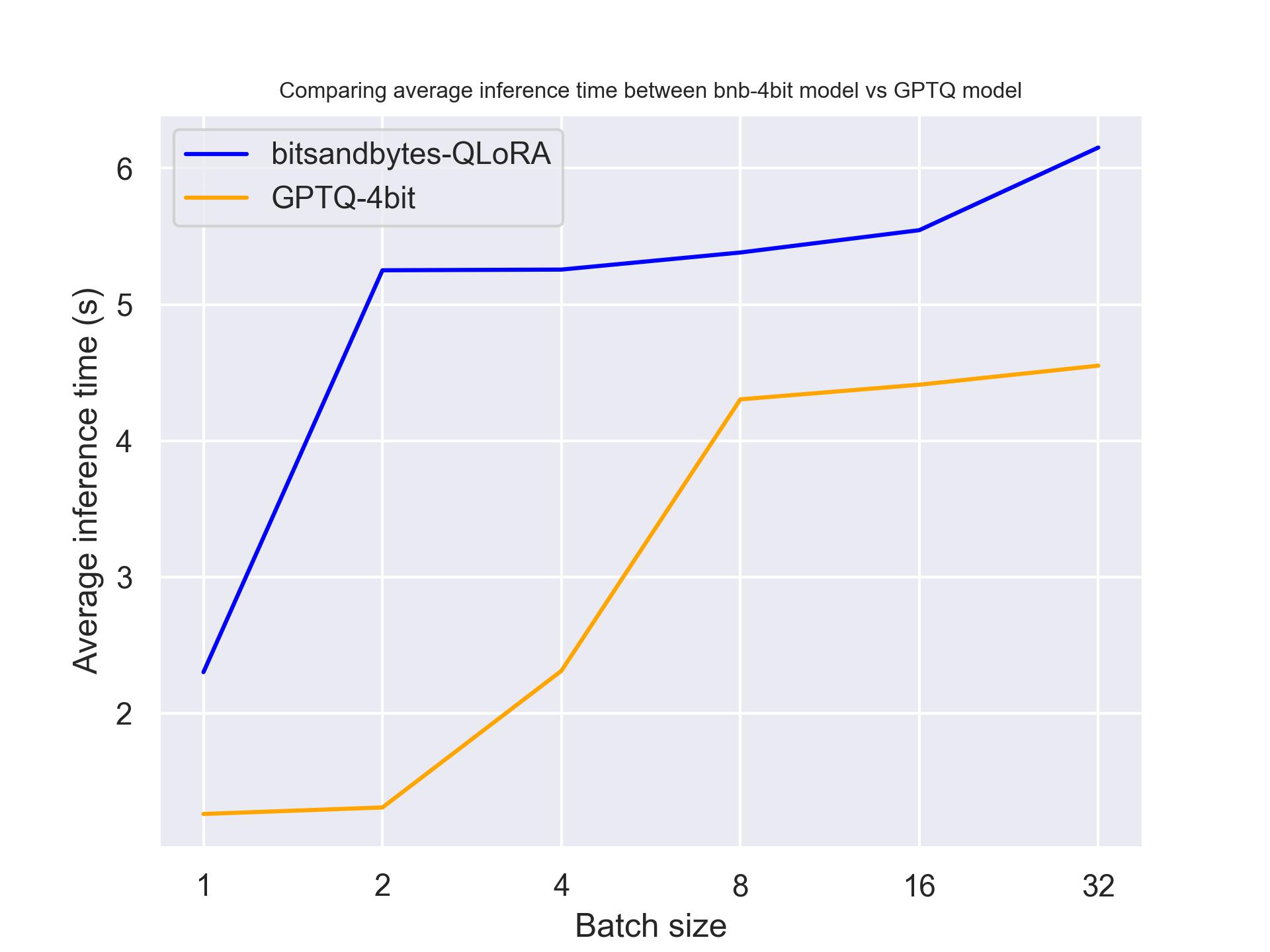
Nel seguente benchmark, proveremo hardware diversi per vedere l’impatto sul modello quantizzato. Abbiamo utilizzato una lunghezza del prompt di 30 e abbiamo generato esattamente 30 token. Il modello che abbiamo utilizzato è meta-llama/Llama-2-7b-hf.
con una NVIDIA A100:
con una NVIDIA T4:
con una Titan RTX:
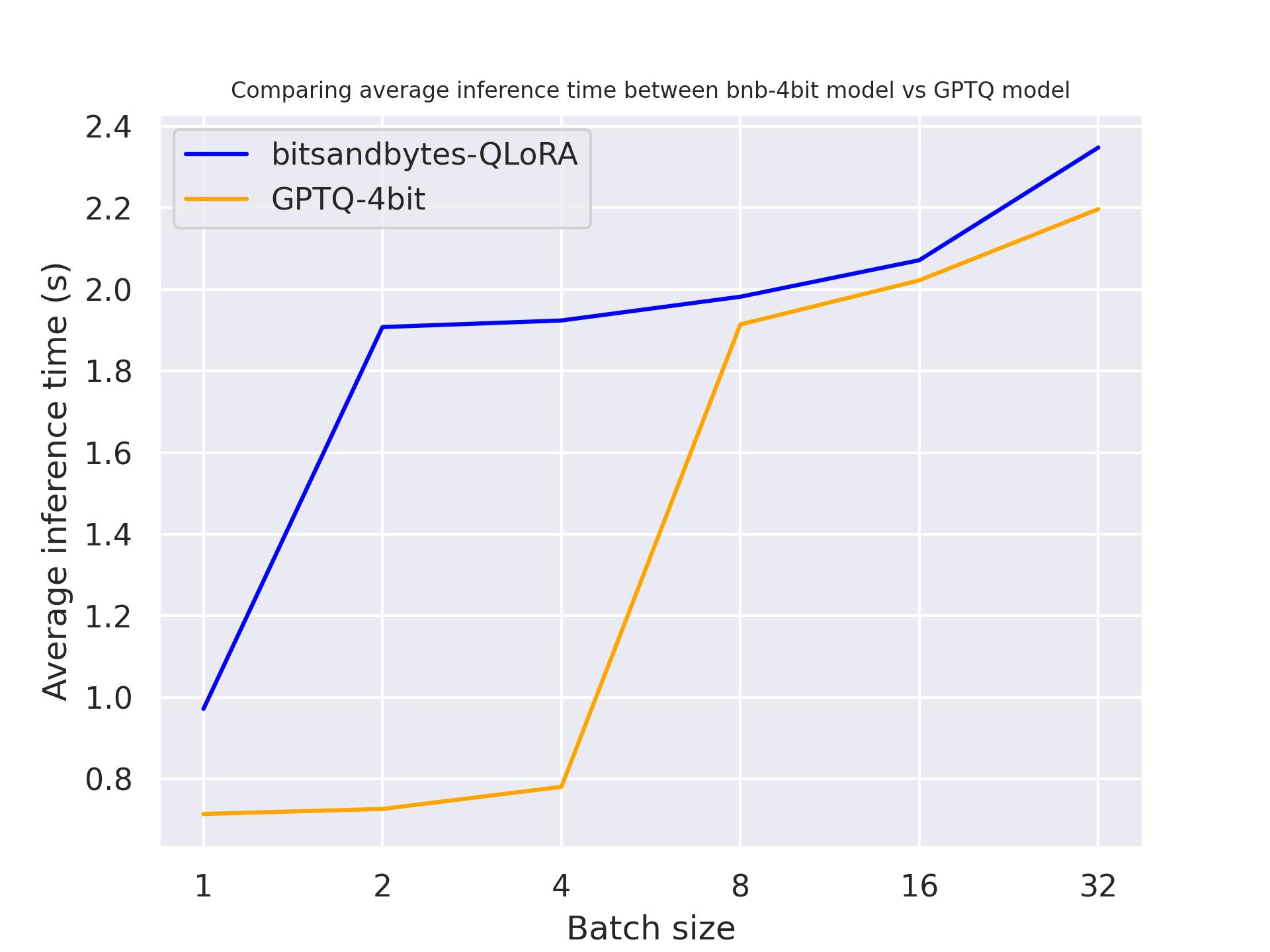
Dal benchmark precedente, possiamo concludere che GPTQ è più veloce di bitsandbytes per queste tre GPU.
Lunghezza della generazione
Nel seguente benchmark, proveremo diverse lunghezze di generazione per vedere il loro impatto sul modello quantizzato. È stato eseguito su una A100 e abbiamo utilizzato una lunghezza del prompt di 30, variando il numero di token generati. Il modello che abbiamo utilizzato è meta-llama/Llama-2-7b-hf.
con 30 token generati:
con 512 token generati:
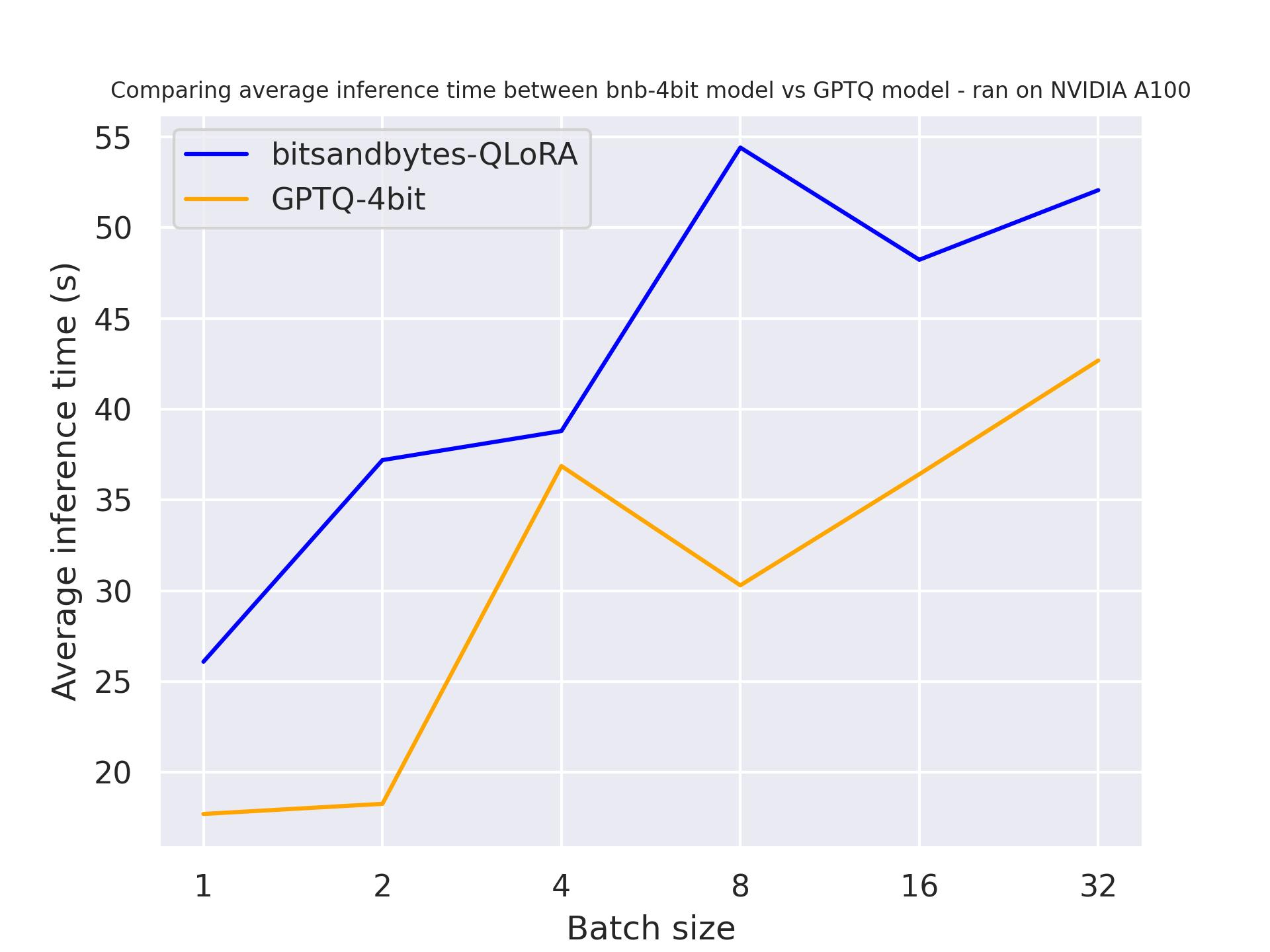
Dal benchmark precedente, possiamo concludere che GPTQ è più veloce di bitsandbytes indipendentemente dalla lunghezza della generazione.
Fine-tuning dell’adattatore (avanti + indietro)
Non è possibile eseguire l’addestramento puro su un modello quantizzato. Tuttavia, è possibile migliorare i modelli quantizzati sfruttando metodi di addestramento efficienti dei parametri (PEFT) e addestrare adattatori su di essi. Il metodo di fine-tuning si baserà su un metodo recente chiamato “Low Rank Adapters” (LoRA): invece di affinare l’intero modello, è sufficiente affinare questi adattatori e caricarli correttamente all’interno del modello. Confrontiamo la velocità di fine-tuning!
Il benchmark è stato eseguito su una GPU NVIDIA A100 e abbiamo utilizzato il modello meta-llama/Llama-2-7b-hf dall’Hub. Nota che per il modello GPTQ, abbiamo dovuto disabilitare i kernel exllama in quanto exllama non è supportato per il fine-tuning.
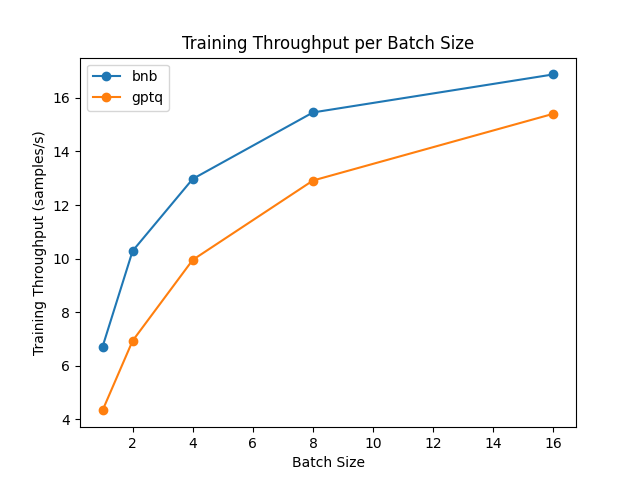
Dal risultato, possiamo concludere che bitsandbytes è più veloce di GPTQ per il fine-tuning.
Degradazione delle prestazioni
La quantizzazione è ottima per ridurre il consumo di memoria. Tuttavia, comporta una degradazione delle prestazioni. Confrontiamo le prestazioni utilizzando la classifica Open-LLM!
con il modello 7b:
con il modello 13b:
Dai risultati sopra riportati, si conclude che ci sia una minore degradazione nei modelli più grandi. In modo ancora più interessante, la degradazione è minima!
Conclusione e parole finali
In questo articolo, abbiamo confrontato la quantizzazione di bitsandbytes e GPTQ su diverse configurazioni. Abbiamo visto che bitsandbytes è più adatto per il fine-tuning, mentre GPTQ è migliore per la generazione. Da questa osservazione, un modo per ottenere modelli combinati migliori sarebbe:
- (1) quantizzare il modello di base utilizzando bitsandbytes (quantizzazione zero-shot)
- (2) aggiungere e fare il fine-tuning degli adattatori
- (3) unire gli adattatori allenati sopra il modello di base o il modello dequantizzato!
- (4) quantizzare il modello combinato utilizzando GPTQ e usarlo per il deployment
Speriamo che questa panoramica renda più facile per tutti utilizzare LLM nelle loro applicazioni e casi d’uso, e non vediamo l’ora di vedere cosa costruirete con esso!
Ringraziamenti
Vorremmo ringraziare Ilyas, Clémentine e Felix per il loro aiuto nel benchmarking.
Infine, vorremmo ringraziare Pedro Cuenca per il suo aiuto nella stesura di questo articolo.