Ora mi vedi (CME) Estrazione del Modello basata su Concetti
Ora mi vedi (CME) - Estrazione del Modello basata su Concetti
Un approccio efficiente etichettato ai modelli basati su concetti
Dal paper del workshop AIMLAI presentato alla conferenza CIKM: “Now You See Me (CME): Concept-based Model Extraction” (GitHub)
TL;DR
Problema — I modelli di reti neurali profonde sono scatole nere, che non possono essere interpretati direttamente. Di conseguenza, è difficile costruire fiducia in tali modelli. I metodi esistenti, come i modelli a collo di bottiglia di concetti, rendono tali modelli più interpretabili, ma richiedono un alto costo di annotazione per l’annotazione dei concetti sottostanti.
Innovazione chiave — Un metodo per generare modelli basati su concetti in modo debole-supervisionato, richiedendo quindi un numero molto inferiore di annotazioni.
Soluzione — Il nostro framework di estrazione di modelli basati su concetti (CME), in grado di estrarre modelli basati su concetti da reti neurali convoluzionali (CNN) pre-allenate in modo semisupervisionato, preservando al contempo le prestazioni dell’attività finale.
- Migliori alternative simili a GitHub per i progetti di Machine Learning
- Robot morbido cammina facendosi esplodere ripetutamente
- Utilizzare la psicologia per rafforzare la sicurezza informatica
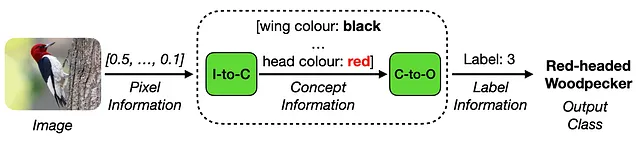
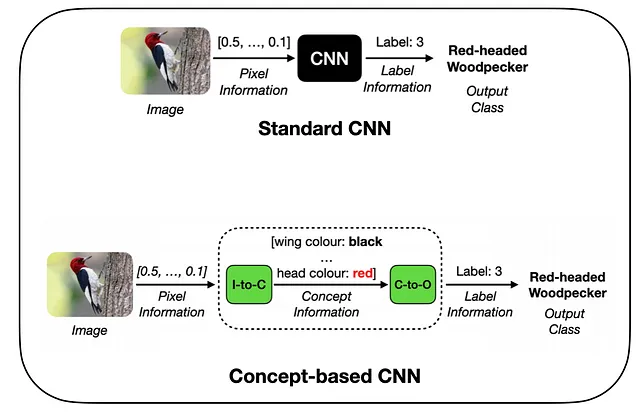
Modelli a collo di bottiglia di concetti (CBM)
Negli ultimi anni, il campo dell’Intelligenza Artificiale Esplicabile (XAI) [1] ha riscontrato un interesse crescente per gli approcci dei Modelli a Collo di Bottiglia di Concetti (CBM) [2]. Questi metodi introducono un’architettura di modello innovativa, in cui le immagini di input vengono elaborate in due fasi distinte: codifica del concetto e elaborazione del concetto.
Durante la codifica del concetto, le informazioni sul concetto vengono estratte dai dati di input ad alta dimensionalità. Successivamente, nella fase di elaborazione del concetto, queste informazioni sul concetto estratto vengono utilizzate per generare l’etichetta dell’attività desiderata. Una caratteristica saliente dei CBM è la loro dipendenza da una rappresentazione concettuale semanticamente significativa, che funge da rappresentazione intermedia e interpretabile per le previsioni dell’attività successiva, come mostrato di seguito:
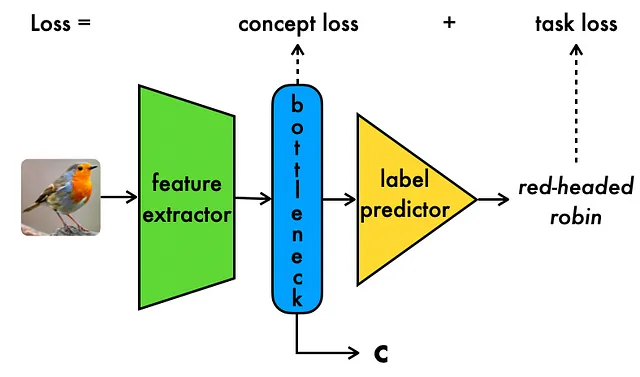
Come mostrato sopra, i modelli CBM vengono addestrati con una combinazione di perdita di attività per garantire una previsione accurata dell’etichetta dell’attività, nonché una perdita di concetto per garantire una previsione intermedia accurata del concetto. È importante sottolineare che i CBM migliorano la trasparenza del modello, poiché la rappresentazione concettuale sottostante fornisce un modo per spiegare e comprendere meglio il comportamento del modello sottostante.
I modelli a collo di bottiglia di concetti offrono un nuovo tipo di reti neurali convoluzionali interpretabili per design, consentendo agli utenti di codificare la conoscenza di dominio esistente nei modelli tramite concetti.
In generale, i CBM rappresentano un’innovazione importante che ci avvicina a modelli più trasparenti e affidabili.
Sfida: i CBM hanno un alto costo di annotazione dei concetti
Sfortunatamente, i CBM richiedono un elevato numero di annotazioni dei concetti durante l’addestramento.
Attualmente, gli approcci CBM richiedono che tutti i campioni di addestramento siano annotati esplicitamente con entrambe le etichette dell’attività finale e dei concetti. Pertanto, per un dataset con N campioni e C concetti, il costo di annotazione aumenta da N annotazioni (una sola etichetta di attività per campione) a N*(C+1) annotazioni (una sola etichetta di attività per campione e una sola etichetta di concetto per ogni concetto). Nella pratica, ciò può diventare rapidamente difficile da gestire, soprattutto per dataset con un gran numero di concetti e campioni di addestramento.
Ad esempio, per un dataset di 10.000 immagini con 50 concetti, il costo di annotazione aumenterà di 50*10.000=500.000 etichette, cioè di mezzo milione di annotazioni extra.
Purtroppo, i Modelli a Soffitto di Concetti richiedono una quantità sostanziale di annotazioni di concetti per l’addestramento.
Sfruttare modelli basati su concetti semi-supervisionati con CME
CME si basa su una simile osservazione evidenziata in [3], dove è stato osservato che i modelli CNN “vanilla” spesso conservano una grande quantità di informazioni relative ai concetti nel loro spazio nascosto, che possono essere utilizzate per l’estrazione di informazioni sui concetti senza costi aggiuntivi di annotazione. Importante, questo lavoro ha considerato uno scenario in cui i concetti sottostanti sono sconosciuti e devono essere estratti dallo spazio nascosto di un modello in modo non supervisionato.
Con CME, facciamo uso dell’osservazione sopra riportata e consideriamo uno scenario in cui abbiamo conoscenza dei concetti sottostanti, ma abbiamo solo una piccola quantità di annotazioni di esempio per ciascuno di questi concetti. Allo stesso modo di [3], CME si basa su una CNN “vanilla” preaddestrata e sulla piccola quantità di annotazioni di concetti per estrarre ulteriori annotazioni di concetti in modo semi-supervisionato, come mostrato di seguito:
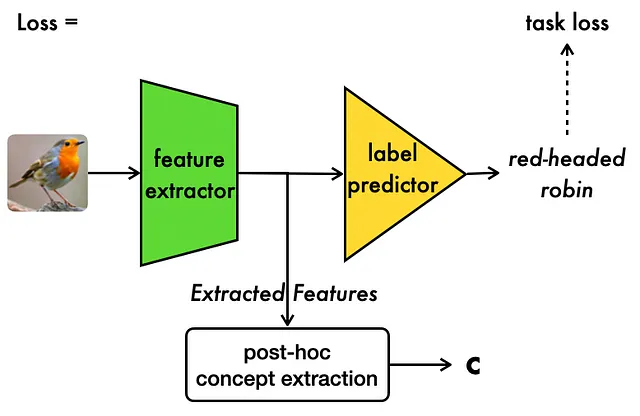
Come mostrato sopra, CME estrae la rappresentazione del concetto utilizzando lo spazio nascosto di un modello preaddestrato in modo post-hoc. Maggiori dettagli sono forniti di seguito.
Addestramento del Codificatore dei Concetti: anziché addestrare i codificatori di concetti da zero sui dati grezzi, come fatto nel caso dei CBM, impostiamo l’addestramento del nostro modello di codificatore di concetti in modo semi-supervisionato, utilizzando lo spazio nascosto della CNN “vanilla”:
- Iniziamo specificando un insieme di livelli L dalla CNN “vanilla” da utilizzare per l’estrazione dei concetti. Questo può variare da tutti i livelli, a solo gli ultimi pochi, a seconda della capacità di calcolo disponibile.
- Successivamente, per ogni concetto, addestriamo un modello separato sullo spazio nascosto di ciascun livello in L per prevedere i valori di quel concetto dallo spazio nascosto del livello.
- Procediamo selezionando il modello e il livello corrispondente con la migliore accuratezza del modello come “migliore” modello e livello per prevedere quel concetto.
- Di conseguenza, quando effettuiamo previsioni di concetti per un concetto i, recuperiamo prima la rappresentazione dello spazio nascosto del miglior livello per quel concetto e poi la passiamo attraverso il modello predittivo corrispondente per l’inferenza.
In generale, la funzione del codificatore di concetti può essere riassunta come segue (supponendo che ci siano k concetti in totale):
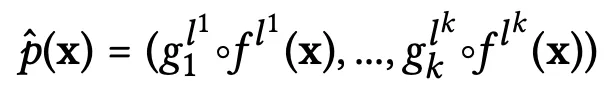
- Qui, p-cappello sul LHS rappresenta la funzione del codificatore di concetti
- I termini gᵢ rappresentano i modelli dallo spazio nascosto al concetto addestrati in cima ai diversi spazi nascosti dei livelli, con i che rappresenta l’indice del concetto, che va da 1 a k. In pratica, questi modelli possono essere piuttosto semplici, come regressori lineari o classificatori ad aumento del gradiente
- I termini f(x) rappresentano i sottomodelli della CNN “vanilla” originale, che estraggono la rappresentazione nascosta dell’input in un determinato livello
- In entrambi i casi sopra, gli apici lʲ specificano i livelli “migliori” su cui operano questi due modelli
Addestramento del Processore di Concetti: l’addestramento del modello del processore di concetti in CME viene impostato addestrando modelli utilizzando le etichette delle attività come output e le previsioni del codificatore di concetti come input. È importante notare che questi modelli operano su una rappresentazione dell’input molto più compatta e possono quindi essere rappresentati direttamente tramite modelli interpretabili, come alberi decisionali (DT) o modelli di regressione logistica (LR).
Esperimenti e Risultati di CME
I nostri esperimenti su dataset sia sintetici (dSprites e shapes3d) che reali e complessi (CUB) hanno dimostrato che i modelli CME:
- Raggiungi un’alta precisione predittiva concettuale paragonabile a quella dei modelli CBM in molti casi, anche su concetti non rilevanti per l’attività finale:

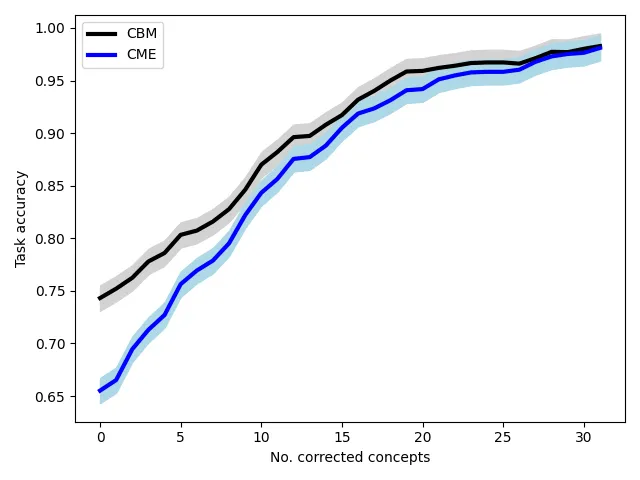
- Consenti interventi umani sui concetti — cioè permettendo agli esseri umani di migliorare rapidamente le prestazioni del modello correggendo piccoli insiemi di concetti scelti:
- Spiega la presa di decisione del modello in termini di concetti, consentendo ai professionisti di visualizzare direttamente i modelli del processore di concetti:
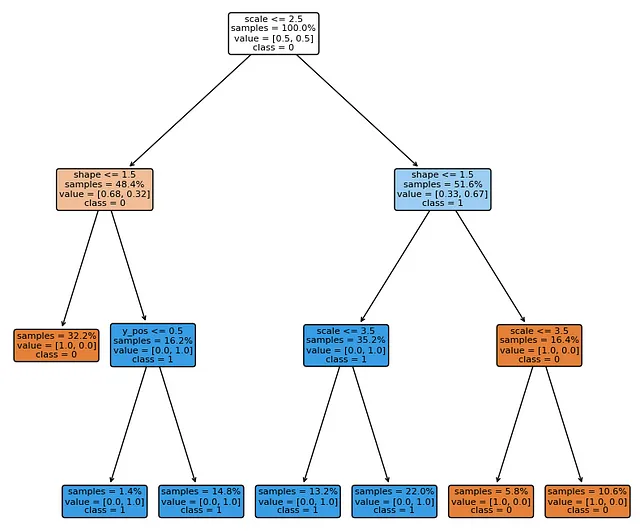
- Aiuta a comprendere l’elaborazione dei concetti del modello analizzando lo spazio nascosto dei concetti sottostanti tra i livelli del modello:

Definendo modelli basati su concetti nel dominio dell’apprendimento debole con CME, possiamo sviluppare modelli basati su concetti con un’etichettatura significativamente più efficiente
Messaggio finale
Sfruttando le reti neurali profonde preaddestrate vanilla, possiamo ottenere annotazioni di concetti e modelli basati su concetti a un costo di annotazione nettamente inferiore, rispetto agli approcci CBM standard.
Inoltre, ciò non si applica strettamente solo a concetti altamente correlati all’attività finale, ma in alcuni casi si applica anche a concetti indipendenti dall’attività finale.
Riferimenti
[1] Chris Molnar. Interpretable Machine Learning. https://christophm.github.io/interpretable-ml-book/
[2] Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In International Conference on Machine Learning, pages 5338–5348. PMLR (2020).
[3] Amirata Ghorbani, James Wexler, James Zou, and Been Kim. Towards Automatic Concept-based Explanations. In Advances in neural information processing systems, 32.






