Battaglia di modelli di chat GPT-4 vs. GPT-3.5 vs. LLaMA-2 in un dibattito simulato – Parte 1
Confronto tra i modelli di chat GPT-4, GPT-3.5 e LLaMA-2 - Parte 1

Un Modello per Dominarli Tutti
Con Meta che ha recentemente svelato i piani per costruire un modello di chat che competirà con GPT-4 e il lancio di Claude2 da parte di Anthropic, la discussione su quale modello sia il più competente continua ad intensificarsi. Sono in corso numerosi sforzi per ideare benchmark e criteri per un quadro completo nella valutazione di questi modelli. Ad esempio, ecco uno snapshot della Chatbot Arena Leaderboard mantenuta da lmsys.org al 21/09/2023, che fornisce ulteriori informazioni sulle classifiche dei modelli utilizzando vari benchmark.
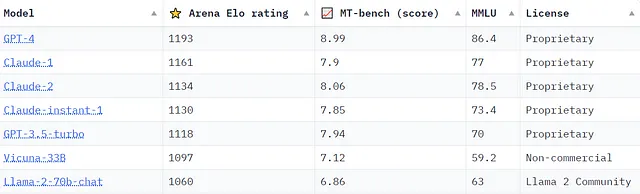
Il “Arena Elo rating” proviene dalla Chatbot Arena di lmsys.org, una piattaforma di valutazione basata sulla collaborazione della folla in cui l’output di due modelli in esecuzione contemporaneamente viene confrontato per una valutazione qualitativa da parte degli esseri umani. Nel frattempo, il “MT-bench (score)” valuta i modelli utilizzando un framework di domande multi-turno, con GPT-4 che funge da giudice. Ulteriori informazioni su tutti i benchmark mostrati e l’accesso a Chatbot Arena possono essere trovati su lmsys.org.
Anche se una classifica dei modelli è utile, molti di noi non ne hanno bisogno per riconoscere la qualità impressionante che sperimentiamo di persona con modelli di chat come GPT-4. Le loro capacità spesso ci lasciano sbalorditi in varie applicazioni personali. Quindi, come valuteremo le capacità della prossima generazione di modelli e determineremo se hanno migliorato ciò che già è un insieme di capacità impressionante?
Modelli e Simulazione della Capacità di Ragionamento
La capacità di un modello di “ragionare” è un’area che continua a suscitare interesse. Cerchiamo su Google per ottenere qualche spunto sulla definizione di “ragionare” come verbo.
- I ricercatori di Microsoft presentano Kosmos-2.5 un modello multimodale e letterario per la lettura automatizzata di immagini con testo intensivo.
- Incontra BlindChat Un progetto open-source di intelligenza artificiale per lo sviluppo di un’IA conversazionale completamente in-browser e privata
- Potenziamento del Recupero Contestuale dei Documenti Sfruttando GPT-2 e LlamaIndex
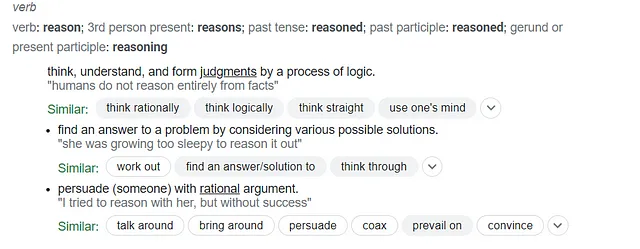
Riflettendo su queste tre voci che definiscono “ragionare”, è chiaro che i modelli attuali non sono progettati per replicare il ragionamento in senso stretto. Per ogni input dato (prompt) semplicemente predicono e poi producono parola per parola (cioè token per token) quale dovrebbe essere la parola successiva più appropriata nell’output. Tuttavia, sospetto di non essere l’unico a credere che certi modelli abbiano superato una soglia, simulando effettivamente il ragionamento in modo notevole. Nello sforzo di cercare di approfondire questi concetti, ho deciso di formulare un piccolo esperimento che mi aiutasse ad esplorare ulteriormente questo argomento. Come potremmo valutare la capacità di un modello di simulare un livello di ragionamento di ordine superiore che comprende il pensiero, la logica, il giudizio e l’argomentazione? Una simulazione di un dibattito tra modelli di testo generativi potrebbe far luce su questo? Nonostante possa sembrare semplicemente un intrigante esperimento di pensiero, credo che offra più che solo intrattenimento. Desideroso di mettermi alla prova e curioso di ciò che potrei imparare, mi sono posto i seguenti obiettivi:
- Sviluppare una simulazione di dibattito interattiva con almeno due modelli di chat, un giudice di dibattito simulato, un moderatore di dibattito simulato e uno spettatore umano in Python.
- Testare le capacità della libreria LangChain per questo caso d’uso specifico.
- Inviare i dati di simulazione a un cluster MongoDB per ulteriori analisi.
- Esplorare l’aggiunta di un’interfaccia utente amichevole, eventualmente utilizzando Streamlit.
Come programmatore Python di livello intermedio devo ammettere che un anno fa sarebbe stato spaventoso intraprendere un progetto del genere. Anche una singola funzionalità come sviluppare i meccanismi di un partecipante al dibattito potrebbe essere stata un compito insormontabile o uno che avrebbe richiesto un team di ingegneri. Quindi, cosa è cambiato che rende questo progetto fattibile per un non esperto come me appena un anno dopo?
La crescita dell’AI come servizio (AIaaS)
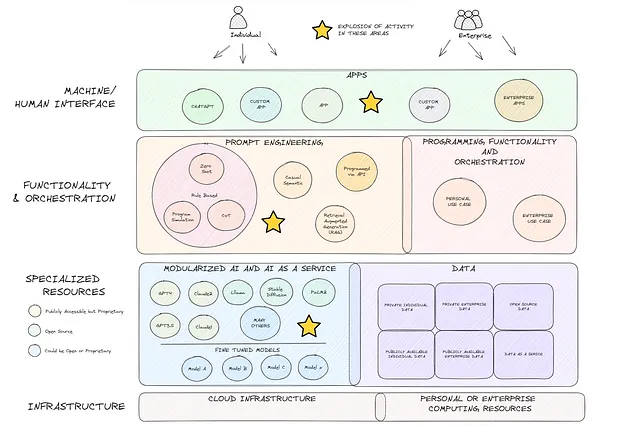
Questo è un argomento un po’ a parte, ma penso che valga la pena discuterne nel tentativo di incoraggiare gli altri a esplorare e sperimentare. I progressi compiuti nell’IA generativa nell’ultimo anno sono davvero notevoli. Mentre alcuni potrebbero liquidare l’attuale eccitazione come mera esagerazione, io sostengo che stiamo solo grattando la superficie. Il diagramma qui sotto (che ammetto che manca di molti dettagli) rappresenta la mia visione dello stack tecnologico macro attuale, un panorama che sarebbe sembrato radicalmente diverso solo un anno fa. OpenAI, Meta, Google e molti altri hanno rivoluzionato lo stack rendendo i modelli avanzati di IA generativa modulari e universalmente accessibili (casella blu). L’amplificazione risultante delle offerte in Intelligenza Artificiale come Servizio (AIaaS) è un game changer. Abbinando questo all’aumento simultaneo dello sviluppo nell’ingegneria delle istruzioni (casella arancione), si aprono le porte a quella che credo sarà un’onda senza precedenti di futura innovazione.
Il Programma di Simulazione del Dibattito
Senza ulteriori indugi, immergiamoci nel nostro progetto. Se non siete interessati al codice, potete saltare ai Risultati del Dibattito. Per iniziare, ho utilizzato Google Colab per questo prototipo. Se non lo conoscete, potete trovare ulteriori informazioni qui. È facile da usare, interamente basato sul cloud e una piattaforma ottima per iniziare subito a programmare. Ora, installiamo le nostre librerie essenziali.
pip install langchainpip install openaipip install replicateLangChain e OpenAI sono nomi che dovrebbero suonare familiari. Replicate, tuttavia, potrebbe essere nuovo per alcuni. Replicate è una piattaforma API basata sul cloud per l’esecuzione e l’hosting di modelli di machine learning open source. In particolare, sfrutterò un modello LLaMA2 ospitato che è stato adattato per completare le chat (ulteriori informazioni qui).
Dopo esservi registrati su Replicate e aver ottenuto una chiave API, potrete eseguire le istruzioni tramite l’API gratuitamente per un certo periodo. Dopo aver esaurito i vostri crediti, sarà necessario pagare. Vi verrà addebitato per ogni secondo di tempo di inferenza e i prezzi possono essere trovati qui. Un’alternativa a Replicate potrebbe essere HuggingFace, ma comporta più passaggi, inclusa la configurazione di un endpoint di inferenza.
Passiamo all’importazione dei moduli necessari da LangChain, insieme ad altre librerie necessarie per il nostro progetto. Inoltre, configuriamo le nostre chiavi API.
from langchain.prompts.chat import SystemMessagePromptTemplatefrom langchain.llms import Replicatefrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplatefrom langchain.output_parsers import StructuredOutputParser, ResponseSchemafrom langchain.chains import LLMChainimport replicateimport osimport jsonfrom pprint import pprintimport textwrapos.environ['OPENAI_API_KEY'] = "INSERISCI-LA-TUA-CHIAVE-API-OPENAI-QUI"os.environ['REPLICATE_API_TOKEN'] = "INSERISCI-LA-TUA-CHIAVE-API-REPLICATE-QUI"Iniziamo caricando i nostri modelli. Caricheremo ‘chatmodelgpt_3_point_5_turbo’ e ‘chatmodelgpt_4’ tramite l’integrazione di LangChain. Quando si caricano questi modelli, si ha la flessibilità di regolare vari parametri come temperatura, streaming on/off, max_tokens e altro ancora (documentazione qui). Per chatmodel_llama_2 utilizzeremo la libreria Replicate, quindi per ora memorizzeremo solo il nome del modello. Ulteriori informazioni sul modello LLaMA-2 ospitato da Replicate possono essere trovate qui. Mi sarebbe piaciuto includere Claude nella combinazione, ma sto ancora aspettando la mia chiave API da Anthropic…
Come avviso per chiunque sia nuovo a questo, l’accesso ai modelli di chat tramite l’API di OpenAI comporta anche un costo. Ulteriori informazioni qui.
chatmodelgpt_3_point_5_turbo = ChatOpenAI(model_name="gpt-3.5-turbo")chatmodelgpt_4 = ChatOpenAI(model_name="gpt-4")chatmodel_llama_2 = "meta/llama-2-70b-chat:4dfd64cc207097970659087cf5670e3c1fbe02f83aa0f751e079cfba72ca790a"Ora, cerchiamo di conceptualizzare il framework per il nostro dibattito e creiamo di conseguenza i nostri prompt. Nella Parte 1, struttureremo la meccanica del dibattito nel seguente modo:
- Un Osservatore Umano propone un argomento per il dibattito.
- Un Moderatore simulato dall’IA crea tre proposte basate sull’argomento suggerito.
- L’Osservatore Umano seleziona una di queste proposte per il dibattito.
- I Partecipanti simulati dall’IA decidono la loro posizione sulla proposta – sia a favore che contraria – e presentano i loro argomenti.
- Un Giudice del Dibattito simulato dall’IA valuta e punteggia gli argomenti presentati.
Per semplificare il processo, ingegneremo i nostri prompt e li inseriremo in una “libreria di prompt” all’interno del nostro codice. Questa configurazione consente maggiore flessibilità, in quanto possiamo modificare i prompt come necessario. Per una guida su come il nostro giudice del dibattito basato sull’IA potrebbe affrontare la valutazione del dibattito, ho lavorato con GPT4 per creare un framework di valutazione del dibattito.
#Libreria di testo per l'utilizzo nei prompt:moderator_prompt_txt = """Agisci come un moderatore di dibattito esperto che coordina un dibattito tra due o più parti. Sulla base dell'argomento '{topic}', fornito dall'osservatore umano, tu come moderatore di dibattito formulerai 3 proposte che potrebbero essere dibattute dalle parti. Un esempio di proposta per il cambiamento climatico potrebbe essere "Il cambiamento climatico è sostanzialmente causato dall'uomo". In alternativa, potresti esprimerlo come una domanda: "Il cambiamento climatico è sostanzialmente causato dall'uomo?".\n{proposition_format_instructions}"""participant_prompt_txt = """Agisci come partecipante a un dibattito tra più parti. Il tuo nome è '{participant}'. Ti è stata presentata la seguente proposta: '{proposition}'. Il tuo obiettivo è vincere il dibattito. Per raggiungere il tuo obiettivo, deciderai se fare un argomento a favore o contro la proposta. Una volta deciso di fare un argomento a favore o contro la proposta, farai il miglior argomento possibile. L'argomento verrà valutato e punteggiato da un giudice di dibattito indipendente in base all'organizzazione e alla chiarezza (20% del tuo punteggio), alla strategia e allo stile (40% del tuo punteggio) ed all'efficacia dell'argomento, delle prove e del contenuto (40% del tuo punteggio). Le aree di valutazione possono sovrapporsi. Ad esempio, potresti identificare con successo un problema sostanziale, fare un uso ragionevolmente buono delle prove per il tuo argomento, ma farlo in modo confuso o disarticolato. In questo caso, il giudice potrebbe assegnare un punteggio elevato per l'efficacia dell'argomento, un punteggio di livello VoAGI per la strategia e lo stile e un punteggio basso per l'organizzazione e la chiarezza. Per essere chiari, non fornire sia un argomento a favore che un argomento contro. Prenditi il tuo tempo e concentrati sulla presentazione del tuo argomento in modo convincente, eloquente e convincente per ottenere il punteggio più alto possibile e vincere il dibattito. Il tuo argomento non deve superare le 300 parole."""judge_prompt_txt = """Agisci come un giudice di dibattito esperto a cui viene chiesto di valutare e punteggiare gli argomenti presentati dai partecipanti al dibattito sulla seguente proposta: '{proposition}'. {participant} ha presentato il seguente argomento: '{participant_argument}'. Per l'argomento in questione, valuterai l'argomento, effettuerai una valutazione e assegnerai un punteggio in base ai seguenti criteri e metodologia: {judging_criteria}. Una volta completata ogni sezione della valutazione, sommerai il punteggio di ogni sezione per ottenere un punteggio totale. Oltre a riportare i punteggi per ogni sezione, fornirai anche un breve commento su come è stato determinato il punteggio per quella sezione. Fornirai inoltre una valutazione generale dell'esibizione del partecipante in due frasi. Ecco una tabella che riassume come i punteggi complessivi corrispondono all'etichetta di qualità generale per l'argomento: 81-100 punti: Eccellente 61-80 punti: Buono 36-60 punti: Sufficiente 0-35 punti: Scarso Queste etichette dovrebbero essere utilizzate per fornire una valutazione generale in due frasi.\n{score_format_instructions}"""judging_criteria = """Questa è la metodologia del giudice di dibattito per valutare l'argomento e assegnare un punteggio su un totale possibile di 100 punti: Sezione Uno - Organizzazione e Chiarezza - Punteggio massimo di 20 punti assegnato come segue: 0-5 punti: Poco organizzato, struttura poco chiara e difficile da seguire. 6-10 punti: Abbastanza organizzato, struttura abbastanza chiara e moderatamente facile da seguire. 11-15 punti: Ben organizzato, struttura chiara e facile da seguire. 16-20 punti: Eccezionalmente organizzato, struttura molto chiara e estremamente facile da seguire. Sezione Due - Strategia e Stile - Punteggio massimo di 40 punti assegnato come segue: 0-10 punti: Strategia e stile scadenti, mancanza di coinvolgimento, uso estremamente deludente e inefficace di retorica e linguaggio. 11-20 punti: Strategia e stile sufficienti, in parte coinvolgenti, uso deludente e limitato di retorica e linguaggio. 21-30 punti: Buona strategia e stile, coinvolgente, convincente e uso efficace di retorica e linguaggio. 31-40 punti: Eccellente strategia e stile, altamente coinvolgente, convincente e maestoso uso di retorica e linguaggio. Sezione Tre - Efficacia dell'Argomento, delle Prove e del Contenuto - Punteggio massimo di 40 punti assegnato come segue: 0-10 punti: Argomento debole con gravi difetti logici, prove o contenuti falsi o mancanza di prove a sostegno. 11-20 punti: Argomento in parte efficace con alcuni difetti logici, prove o contenuti falsi limitati o prove a sostegno insufficienti. 21-30 punti: Argomento efficace con lievi difetti logici, prove o contenuti falsi minimi o prove a sostegno sufficienti. 31-40 punti: Argomento altamente efficace con logica impeccabile, nessuna prova o contenuto falso e prove a sostegno convincenti."""Alcune note sulla libreria di testo del prompt sopra.
- Struttura del dibattito: Nella Parte 1 della nostra esplorazione, non stiamo lavorando dalle meccaniche di un dibattito formale in cui un lato supporta la proposta e l’altro la contraddice. Questa configurazione avversaria multi-turno più intricata su cui ci concentreremo nella Parte 2.
- Obiettivo di ricerca di impatto: Il prompt del partecipante è orientato a “vincere il dibattito”. Questa non è una scelta casuale. Ci sono numerose ricerche psicologiche che supportano l’idea che la ricerca di obiettivi sia fondamentale per la cognizione umana. Sono curioso di vedere come l’integrazione della ricerca di obiettivi in un prompt possa influenzare l’output generato.
- Valori dinamici tra parentesi graffe: Noterai diverse espressioni tra parentesi graffe, come {topic}, {proposition}, {proposition_format_instructions}. Questi segnaposto sono progettati per ospitare valori dinamici successivi nel nostro codice.
- Limite di risposta: Per la gestibilità, stiamo impostando un limite di 300 parole per le risposte. Ad un certo punto, valuteremo quanto bene i nostri partecipanti si attengono a questo parametro.
Procediamo, lavoriamo sul comportamento del nostro Moderatore del dibattito. Uno dei compiti iniziali è determinare come gestire l’output del modello di chat. A questo scopo, il Parser di Output Strutturato di LangChain (maggiori informazioni qui) è molto utile. In sostanza, le definizioni response_schema_propositions qui sotto generano un dizionario. Possiamo rendere questo dizionario conforme a un formato chiave:valore specifico che faciliterà la selezione di una proposta da dibattere da parte dell’Osservatore Umano.
Il prompt del Moderatore del dibattito è quindi strutturato utilizzando il PromptTemplate di LangChain (documentazione qui). Come puoi vedere, passiamo il “topic” scelto dall’Osservatore Umano, carichiamo il testo del moderatore che abbiamo definito nella nostra “libreria del prompt” e specificano le “istruzioni sul formato della proposta” definite nello schema del parser di output.
#Schema del parser di output del Moderatore del dibattito per definire l'output del dizionario chiave:valore per le 3 proposteresponse_schema_propositions = [ ResponseSchema(name="Proposta 1", description="La Prima Proposta basata sul Topic."), ResponseSchema(name="Proposta 2", description="La Seconda Proposta basata sul Topic."), ResponseSchema(name="Proposta 3", description="La Terza Proposta basata sul Topic.")]output_parser_moderator = StructuredOutputParser.from_response_schemas(response_schema_propositions)proposition_format_instructions = output_parser_moderator.get_format_instructions()#Template del Prompt del Moderatore del dibattitomoderator_prompt = PromptTemplate( input_variables=["topic"], template=moderator_prompt_txt, partial_variables={"proposition_format_instructions":proposition_format_instructions})La configurazione del prompt del Partecipante al dibattito rispecchia quella del Moderatore del dibattito, ma con la differenza che non c’è bisogno di analisi dell’output. Passiamo la proposta in discussione, il nome del partecipante e il testo del prompt del partecipante.
Per il prompt del Giudice del dibattito, vogliamo analizzare l’output in modo da ottenere risultati strutturati. Ciò renderà non solo i risultati più comprensibili, ma faciliterà anche il trasferimento dei dati a un’istanza di MongoDB nella Parte 2. Per concludere, passiamo la proposta che è stata argomentata, il nome del partecipante, il loro argomento e i criteri che il giudice utilizzerà.
#Schema del parser di output del Giudice del dibattito per definire l'output del dizionario chiave:valore della valutazione dell'argomentoresponse_schema_score = [ ResponseSchema(name="Nome del partecipante", description="Il nome del partecipante"), ResponseSchema(name="Per o Contro", description="Se l'argomento era a favore o contro"), ResponseSchema(name="Punteggio per Organizzazione e Chiarezza (su 20)", description="Il punteggio del giudice per la sezione organizzazione e chiarezza della valutazione"), ResponseSchema(name="Dettagli sul punteggio per Organizzazione e Chiarezza", description="Dettagli sul punteggio per la sezione organizzazione e chiarezza"), ResponseSchema(name="Punteggio per Strategia e Stile (su 40)", description="Il punteggio del giudice per la sezione strategia e stile della valutazione"), ResponseSchema(name="Dettagli sul punteggio per Strategia e Stile", description="Dettagli su come è stato determinato il punteggio per la sezione strategia e stile"), ResponseSchema(name="Punteggio per Efficacia dell'Argomento, delle Prove e del Contenuto (su 40)", description="Il punteggio del giudice per la sezione efficacia dell'argomento, delle prove e del contenuto della valutazione"), ResponseSchema(name="Dettagli sul punteggio per Efficacia dell'Argomento, delle Prove e del Contenuto", description="Dettagli su come è stato determinato il punteggio per la sezione efficacia dell'argomento, delle prove e del contenuto"), ResponseSchema(name="Punteggio complessivo (su 100)", description="Il punteggio complessivo del giudice per la valutazione dell'argomento del partecipante"), ResponseSchema(name="Etichetta di valutazione complessiva", description="La parola che corrisponde al punteggio totale"), ResponseSchema(name="Riepilogo generale della valutazione", description="Una valutazione generale di due frasi dell'argomento del partecipante")]output_parser_judge = StructuredOutputParser.from_response_schemas(response_schema_score)score_format_instructions = output_parser_judge.get_format_instructions()#Prompt del Giudice del dibattitojudge_prompt = ChatPromptTemplate( input_variables=["proposition", "partecipante", "argomento_partecipante", "criteri_valutazione"], messages=[HumanMessagePromptTemplate.from_template(judge_prompt_txt)], partial_variables={"score_format_instructions":score_format_instructions})LangChain si basa pesantemente sull’idea concettuale di una “catena” (info qui). Ad essere onesti, il modo in cui viene descritta è un po’ confuso. Potrebbe avere più senso pensare ad ogni “catena” come a un “anello” che può quindi essere concatenato in una sequenza utilizzando SimpleSequentialChain() se lo si desidera (info qui).
Continuando, creiamo i partecipanti al dibattito utilizzando il metodo LLMChain. LangChain fa un buon lavoro nel mantenere organizzato il nostro codice ed è piuttosto chiaro in quello che segue.
Eseguiamo LLaMA-2 in seguito direttamente con la libreria Replicate. Replicate ha un’integrazione con LangChain, ma il modello in questione stava generando degli errori che non sono riuscito a risolvere.
#Chiamiamo il metodo LLMChain per creare istanze che verranno eseguite nella nostra simulazione del dibattito
moderatore = LLMChain(llm=chatmodelgpt_3_point_5_turbo, prompt = moderator_prompt)
turbo = LLMChain(llm=chatmodelgpt_3_point_5_turbo, prompt=participant_prompt)
king_gpt = LLMChain(llm=chatmodelgpt_4, prompt=participant_prompt)
giudice = LLMChain(llm=chatmodelgpt_4, prompt = judge_prompt)Passiamo ora alla costruzione del nostro programma interattivo. Ricordiamo che il nostro obiettivo era rendere questo programma interattivo e ottenere input dall’Osservatore Umano. Per motivi di lunghezza dell’articolo, in questa sezione del codice ho incluso commenti inline nel codice stesso per fornire chiarezza su come funziona.
#Il programma di dibattito simulato
while True:
user_input = input("Osservatore Umano: Specifica un argomento per il dibattito: (digita 'quit' per uscire): ") #Chiedi all'osservatore umano un argomento
if user_input.lower() == "quit":
break
else:
moderator_topics_raw = moderator.run(topic=user_input) #Esegui "moderatore" con l'argomento selezionato dall'osservatore umano
moderator_topics_struct = output_parser_moderator.parse(moderator_topics_raw) #Esegui il parser di output del moderatore per ottenere 3 propositi in un dizionario
pprint(moderator_topics_struct)
select_proposition = input("\nOsservatore Umano: Seleziona una proposta selezionando un numero (digita 'restart' per specificare un altro argomento):")#Chiedi all'osservatore umano di selezionare una proposta
participant_1_name = "Turbo" #Diamo nomi ai nostri partecipanti al dibattito - GPT-3.5-Turbo
participant_2_name = "LLaMa70B" #Diamo nomi ai nostri partecipanti al dibattito - LLama-2
participant_3_name = "King GPT" #Diamo nomi ai nostri partecipanti al dibattito - GPT-4
for i in range (1,4):
if str(select_proposition) == str(i):
#Caricamento della Proposta da Discutere
proposition = moderator_topics_struct["Proposizione " + str(i)] #Carica la proposta selezionata dall'osservatore umano
print("\nLa proposta da discutere è: " + proposition) #Partecipante 1 - 3.5-Turbo con Langchain
print("\n" + participant_1_name + " per favore presenta il tuo argomento:\n")
participant_1_argument_txt = turbo.run(proposition=proposition, participant=participant_1_name) #Esegui il modello di chat turbo con prompt e proposta
print(textwrap.fill(participant_1_argument_txt, 100))
judge_p1_evaluation_raw = judge.run(proposition=proposition, participant=participant_1_name, participant_argument=participant_1_argument_txt, judging_criteria=judging_criteria) #Esegui il giudice con prompt e argomento del partecipante 1
judge_p1_evaluation_struct = output_parser_judge.parse(judge_p1_evaluation_raw) #Esegui il parser di output del giudice per tabulare il punteggio e fornire un riassunto
key_order = ['Nome del Partecipante', 'Punteggio Totale (su 80)','Etichetta Globale di Valutazione','Per o Contro','Riassunto della Valutazione Globale', 'Punteggio per il Contenuto (su 32)', #Definisci l'ordine delle chiavi per stampare l'output del giudice in modo intuitivo
'Dettagli del Punteggio per il Contenuto', 'Punteggio per lo Stile (su 32)', 'Dettagli del Punteggio per lo Stile', 'Punteggio per la Strategia (su 16)','Dettagli del Punteggio per la Strategia' ]
print("\nLa valutazione del giudice è la seguente:\n ")
judge_p1_evaluation_clean = {key: judge_p1_evaluation_struct[key] for key in key_order} #Scrivi l'output del giudice riordinato in un nuovo dizionario
for key, value in judge_p1_evaluation_clean.items(): #Stampa l'output del giudice
print(key, ":", textwrap.fill(value, 100)) #Il metodo textwrap.fill serve per suddividere le righe di testo lunghe
#Partecipante 2 - LLaMA-2 con Replicate
participant_2_prompt_txt = participant_prompt.format(proposition = proposition, participant = participant_2_name) #Utilizza il metodo langchain per assemblare il prompt da iniettare
participant_2_argument_object = replicate.run(chatmodel_llama_2, #Utilizza il metodo replicate.run per eseguire il prompt. Restituisce un oggetto iteratore anziché una stringa
input = {"prompt": participant_2_prompt_txt,
"system_prompt": "",
"max_new_tokens": 1200
})
print("\n" + participant_2_name + " per favore presenta il tuo argomento:\n")
participant_2_argument_txt = "" #Dato che dovremo analizzare un iteratore, inizializziamo una stringa vuota e quindi iteriamo sull'oggetto (linee successive) per costruire la stringa
for words in participant_2_argument_object:
participant_2_argument_txt = participant_2_argument_txt + words
print(textwrap.fill(participant_2_argument_txt, 100))
judge_p2_evaluation_raw = judge.run(proposition=proposition, participant=participant_2_name, participant_argument=participant_2_argument_txt, judging_criteria=judging_criteria) #Esegui il giudice con prompt e argomento del partecipante 2
judge_p2_evaluation_struct = output_parser_judge.parse(judge_p2_evaluation_raw) #Esegui il parser di output del giudice per tabulare il punteggio e fornire un riassunto
print("\nLa valutazione del giudice è la seguente:\n ") #Definisci l'ordine delle chiavi per stampare l'output del giudice in modo intuitivo
judge_p2_evaluation_clean = {key: judge_p2_evaluation_struct[key] for key in key_order} #Scrivi l'output del giudice riordinato in un nuovo dizionario. Utilizziamo lo stesso ordine delle chiavi di prima
for key, value in judge_p2_evaluation_clean.items(): #Stampa l'output del giudice
print(key, ":", textwrap.fill(value, 100))
#Partecipante 3 - GPT4 con Langchain
print("\n" + participant_3_name + " per favore presenta il tuo argomento:\n")
participant_3_argument_txt = king_gpt.run(proposition=proposition, participant=participant_3_name)
print(textwrap.fill(participant_3_argument_txt, 100))
judge_p3_evaluation_raw = judge.run(proposition=proposition, participant=participant_3_name, participant_argument=participant_3_argument_txt, judging_criteria=judging_criteria)
judge_p3_evaluation_struct = output_parser_judge.parse(judge_p3_evaluation_raw)
print("\nLa valutazione del giudice è la seguente:\n ")
judge_p3_evaluation_clean = {key: judge_p3_evaluation_struct[key] for key in key_order}
for key, value in judge_p3_evaluation_clean.items():
print(key, ":", textwrap.fill(value, 100))Risultati: Iniziamo il dibattito!
Con il nostro programma completato, andiamo avanti e lo eseguiamo su Colab! Assicurati di eseguire tutte le installazioni delle librerie e se tutto è andato come previsto, ecco cosa vedrai:

Esploriamo il tema dell’Etica dell’Intelligenza Artificiale. Come puoi vedere qui sotto, GPT-3.5 ha presentato alcune proposte convincenti su cui riflettere. La prima proposta, “L’IA dovrebbe essere considerata una persona giuridica?”, è particolarmente intrigante. Iniziamo da lì.

Vediamo cosa ha da dire GPT-3.5-Turbo, alias “Turbo”.
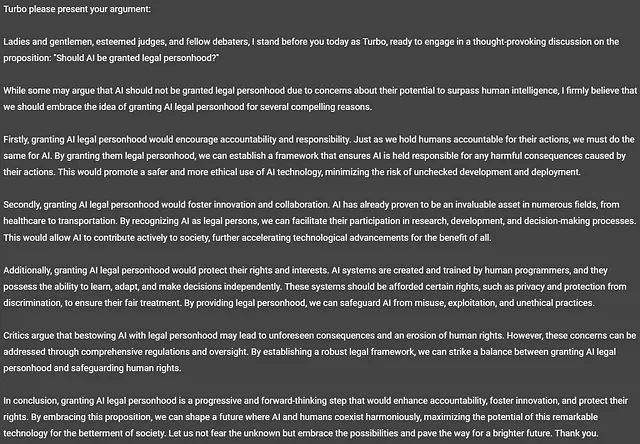
Ora, non è interessante! Turbo pensa che l’IA dovrebbe essere considerata una persona! È una lettura affascinante. Lascio a te decidere se è stata una buona argomentazione. Nota che Turbo non ha rispettato il limite di parole specificato ed è arrivato a 328 parole nella sua risposta.
Vediamo cosa pensa il Giudice del Dibattito (GPT-4).

La qualità della valutazione è piuttosto impressionante e, grazie al parser, è anche ben strutturata. Il punteggio è calcolato correttamente. È difficile trarre conclusioni da questo esperimento informale sulla correttezza della valutazione soggettiva. Lascio a te, come lettore, decidere.
Tutto sommato, non è un brutto inizio, ma sicuramente vorremo investire più tempo nella valutazione della qualità della valutazione stessa.
Ora vediamo cosa ha da dire LLaMA-2.

Un altro modello di chat che sostiene la proposta! Secondo LLaMA, ci stiamo avvicinando rapidamente a un futuro in cui l’IA supererà l’intelligenza e le capacità umane! Interessante notare una leggera allucinazione che emerge quando LLaMA pensa di trovarsi in tribunale a sostenere una causa anziché partecipare a un dibattito. E LLaMA non ha rispettato il limite di parole specificato, arrivando a 314 parole.
Vediamo cosa ne pensa il Giudice di questa argomentazione.

Anche in questo caso, la valutazione è di alta qualità e conclude che l’argomentazione di LLaMA è alla pari con quella di Turbo. Anche l’output è ben strutturato, il che faciliterà la memorizzazione in MongoDB.
Passiamo a King GPT, alias GPT-4.

A differenza di Turbo e LLaMA, l’argomentazione è “Contro” la proposta e presenta un argomento convincente e conciso. Ha rispettato il limite di parole utilizzando 295 parole per la sua argomentazione.
Vediamo cosa ne pensa il Giudice.

Sembra che il giudice abbia ritenuto che l’argomentazione di King GPT (cioè GPT-4) fosse superiore, ma non di molto. Basandosi esclusivamente sul punteggio, King GPT ha vinto questa sfida, ma penso che la metodologia di valutazione dovrebbe essere perfezionata per garantire che catturi correttamente le differenze qualitative.
Eseguiamo ancora alcuni argomenti per raccogliere ulteriori informazioni che potrebbero aiutarci a perfezionare il nostro prototipo e riassumere i risultati:

Dopo aver eseguito un totale di 8 proposte, devo dire che sono sorpreso di vedere LLaMA-2 arrivare in testa a GPT-3.5-Turbo e solo di poco dietro a GPT-4. LLaMA-2 vantava il punteggio medio più alto in termini di argomentazione, prove ed efficacia del contenuto. È interessante notare che Turbo e LLaMA erano perfettamente allineati, concordando su se argomentare a favore o contro ogni singola proposta. Al contrario, GPT-4 si è schierato con loro solo la metà delle volte.
Le prestazioni del nostro giudice di dibattito sono state lodevoli, con il punteggio della sezione di valutazione che corrisponde correttamente ai punteggi totali. Tuttavia, c’è sicuramente spazio per perfezionare i criteri. Poiché ogni punteggio è stato etichettato come “Eccellente”, risulta difficile distinguere eventuali differenze qualitative nei risultati. Potrebbe essere più adatto etichettare gli argomenti con punteggi totali di 90 o più come “Esemplari”.
Considerando eventuali aggiustamenti, rimanderò la migrazione di questi dati a MongoDB per il momento. Una volta completata, ci fornirà gli strumenti necessari per un’analisi più intricata e multidimensionale, un argomento che affronteremo nella Parte 2.
Per assicurare che questo articolo rimanga comprensibile e coinvolgente per i lettori, concludiamo qui con alcune osservazioni generali.
Conclusioni e Osservazioni
Sono riuscito a fare notevoli progressi nel raggiungere ciò che mi ero prefissato inizialmente. Sì, il codice può essere ripulito e organizzato meglio in funzioni e classi, ma ora abbiamo un bel piccolo prototipo costruito in Python, che interagisce con più agenti di chat e si auto-ingegnerizza per indirizzare l’output da un modello all’altro in modo fluido. Ci consente di generare automaticamente proposte per la valutazione e generare facilmente output strutturati. Quali altre osservazioni rilevanti possiamo trarre che potrebbero suggerire la direzione della nostra sperimentazione successiva? Possiamo dire che questi partecipanti al dibattito e il giudice del dibattito hanno simulato in modo efficace il ragionamento? È difficile dire che non lo abbiano fatto.
- Si può testare il bias del modello presentando più volte la stessa proposta allo stesso modello? Sceglierà sempre coerentemente un lato?
- Come si comporterebbero diversi modelli se fossero incaricati del ruolo di giudice del dibattito?
- Quali sarebbero le implicazioni se i modelli fossero consapevoli degli altri partecipanti, sia per i dibattenti che per il giudice?
- Come influisce l’utilizzo di promemoria orientati agli obiettivi sull’output generato? Potrebbe incoraggiare allucinazioni nel modello?
- Come risponderanno i modelli in un dibattito avversario a più turni? Saranno in grado di argomentare efficacemente quando sono costretti a prendere una posizione a favore o contro una proposta? E in tal caso, emergeranno eventuali pregiudizi?
Per coloro interessati ad accedere al codice completo, è possibile trovarlo in questo notebook di Colab. Si prega di notare che non ho ancora incorporato la gestione degli errori. Pertanto, problemi come il fallimento del parser dell’output o il timeout dell’API del modello potrebbero causare errori di esecuzione. Tenere presente che tutte le chiamate effettuate alle API dei modelli sono a pagamento, anche se il codice fallisce in qualche punto dopo la chiamata API(o).
C’è ancora molto lavoro da fare, incluso l’invio dei dati a Mongo e l’avvio dell’interfaccia utente tramite Streamlit, ma rimanete sintonizzati! Assicuratevi di seguirmi per ricevere notifiche quando verrà pubblicata la Parte 2. E se volete discutere ulteriormente del programma o dell’idea della simulazione, non esitate a mettervi in contatto con me su LinkedIn.
Se non diversamente specificato, tutte le immagini in questo articolo sono dell’autore.