I ricercatori di Microsoft presentano Kosmos-2.5 un modello multimodale e letterario per la lettura automatizzata di immagini con testo intensivo.
I ricercatori di Microsoft presentano Kosmos-2.5, un modello multimodale e letterario per la lettura automatizzata di immagini con testo intensivo.


Negli ultimi anni, i grandi modelli linguistici (LLM) hanno guadagnato importanza nell’intelligenza artificiale, ma si sono principalmente concentrati sul testo e hanno faticato a comprendere i contenuti visivi. I modelli linguistici multimodali (MLLM) sono emersi per colmare questa lacuna. I MLLM combinano informazioni visive e testuali in un unico modello basato su Transformer, consentendo loro di apprendere e generare contenuti da entrambe le modalità, rappresentando un notevole avanzamento nelle capacità dell’IA.
KOSMOS-2.5 è un modello multimodale progettato per gestire due compiti di trascrizione strettamente correlati all’interno di un framework unificato. Il primo compito consiste nella generazione di blocchi di testo con consapevolezza spaziale e nell’assegnazione di coordinate spaziali alle righe di testo all’interno di immagini ricche di testo. Il secondo compito si concentra sulla produzione di un output di testo strutturato in formato markdown, catturando vari stili e strutture.
Entrambi i compiti sono gestiti da un singolo sistema, utilizzando un’architettura condivisa basata su Transformer, prompt specifici per il compito e rappresentazioni testuali adattabili. L’architettura del modello combina un codificatore di visione basato su ViT (Vision Transformer) con un decodificatore di linguaggio basato sull’architettura del Transformer, collegati tramite un modulo di campionamento.
- Incontra BlindChat Un progetto open-source di intelligenza artificiale per lo sviluppo di un’IA conversazionale completamente in-browser e privata
- Potenziamento del Recupero Contestuale dei Documenti Sfruttando GPT-2 e LlamaIndex
- HeyGen Review Il miglior generatore di video AI per le aziende?
Per addestrare questo modello, viene sottoposto a pretraining su un ampio dataset di immagini ricche di testo, che includono righe di testo con bounding box e testo markdown semplice. Questo approccio di addestramento a doppio compito migliora le capacità complessive di multimedialità di KOSMOS-2.5.
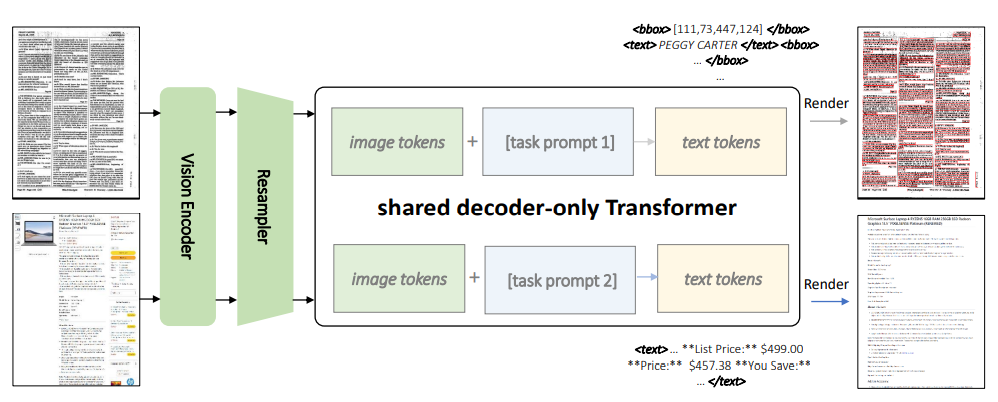
L’immagine sopra mostra l’architettura del modello di KOSMOS-2.5. Le prestazioni di KOSMOS-2.5 vengono valutate in due compiti principali: riconoscimento del testo a livello di documento end-to-end e generazione di testo da immagini in formato markdown. I risultati sperimentali hanno dimostrato la sua forte capacità di comprendere compiti di immagini con testo intenso. Inoltre, KOSMOS-2.5 mostra promettenti capacità in scenari che coinvolgono l’apprendimento few-shot e zero-shot, rendendolo uno strumento versatile per applicazioni reali che trattano immagini ricche di testo.
Nonostante questi risultati promettenti, il modello attuale presenta alcune limitazioni, offrendo preziose direzioni di ricerca future. Ad esempio, KOSMOS-2.5 attualmente non supporta un controllo dettagliato degli elementi del documento utilizzando istruzioni in linguaggio naturale, nonostante sia stato pre-addestrato su input e output che coinvolgono le coordinate spaziali del testo. Nel panorama della ricerca più ampio, una direzione significativa consiste nel continuare a sviluppare le capacità di scalabilità del modello.