Realizzazione di una nuova conferenza di calcio universitario – Regressione
New university football conference creation - Regression
Benvenuti alla parte 2 della mia serie sulla riallocazione delle conferenze! Lo scorso estate, quando la riallocazione delle conferenze era in pieno svolgimento, Tony Altimore ha pubblicato uno studio su Twitter che mi ha ispirato a fare la mia analisi sulla riallocazione delle conferenze. Questa serie è organizzata in quattro parti (e la motivazione completa si trova nella parte 1):
- Riallocazione delle conferenze di calcio universitario – Analisi esplorativa dei dati in Python
- Riallocazione delle conferenze di calcio universitario – Regressione
- Riallocazione delle conferenze di calcio universitario – Clustering
- Riallocazione delle conferenze di calcio universitario – node2vec
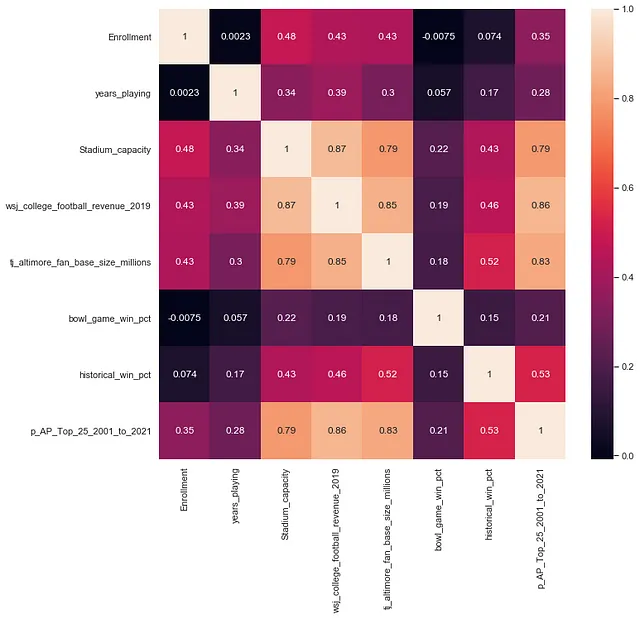
Spero che ogni parte della serie ti fornisca una prospettiva nuova sul futuro del tanto amato gioco del calcio universitario. Per coloro che non hanno letto la parte 1, una breve sinossi è che ho creato il mio set di dati compilato da fonti su tutto il web. Questi dati includono informazioni di base su ogni programma FBS, un’approximazione non canonica di tutte le rivalità del calcio universitario, dimensioni dello stadio, prestazioni storiche, frequenza di apparizioni nelle classifiche AP top 25, se la scuola è un’istituzione AAU o R1 (storicamente importante per l’appartenenza al Big Ten e Pac 12), il numero di scelte al draft NFL, dati sulle entrate del programma dal 2017 al 2019, e una stima recente delle dimensioni delle tifoserie di calcio universitario. Come si è scoperto, la capacità dello stadio, le entrate del 2019 e il successo storico nelle classifiche AP sono correlati in modo significativo con la stima delle dimensioni della tifoseria nell’analisi di Tony Altimore:
Apprendimento supervisionato
Quindi, mi sono chiesto: possiamo creare un semplice modello di regressione per stimare la dimensione della tifoseria?
- Previsione su più orizzonti un esempio con i dati meteorologici
- Best practice di ingegneria del software per scrivere codice ML mantenibile
- Serie di apprendimento non supervisionato esplorazione di mappe auto-organizzanti
In generale, possiamo dividere l’apprendimento automatico in apprendimento supervisionato e non supervisionato. Nell’apprendimento supervisionato, l’obiettivo è prevedere una classe discreta o una variabile continua predefinita. Nell’apprendimento non supervisionato, l’obiettivo è scoprire tendenze nei dati che non sono ovvie. La regressione è un tipo di apprendimento supervisionato in cui il target di previsione è una variabile continua. Una guida di riferimento molto utile è stata realizzata da Shervine e Afshine Amidi. (È stata tradotta in…




