Crea il tuo assistente di analisi dati con gli agenti di Langchain
Crea assistente analisi dati con agenti Langchain
Permettimi di condividere la mia opinione personale sugli agenti LLM: stanno per rivoluzionare tutto! Se stai già lavorando con Large Language Models, probabilmente li conosci. Se sei nuovo a questo concetto, preparati a rimanere stupito.

Cosa è un Agente nel Mondo dei Large Language Models?
Un agente è un’applicazione che consente a un Large Language Model di utilizzare strumenti per raggiungere un obiettivo.
Fino ad ora, abbiamo utilizzato modelli linguistici per compiti come la generazione di testo, l’analisi, la sintesi, la traduzione, l’analisi del sentiment e molto altro.
Una delle utilità più promettenti nel mondo tecnico è la loro capacità di generare codice in diversi linguaggi di programmazione.
- Può l’IA davvero aiutarti a superare i colloqui?
- Knowledge Graph Il Cambiamento di Gioco in AI e Data Science
- Potenziare la tua app con la nuova funzionalità di connessioni di Streamlit e mappe interattive di Plotly
In altre parole, non sono solo in grado di comunicare con gli esseri umani attraverso la comprensione e la generazione del linguaggio naturale, ma possono anche interagire con API, librerie, sistemi operativi, database… tutto grazie alla loro capacità di comprendere e generare codice. Possono generare codice in Python, JavaScript, SQL e chiamare API ben note.
Questa combinazione di capacità, che solo i Big Language Models possiedono, direi a partire dal GPT-3.5, è cruciale per la creazione degli Agenti.
L’Agente riceve una richiesta dell’utente in linguaggio naturale. La interpreta e analizza la sua intenzione, e con tutte le sue conoscenze, genera ciò di cui ha bisogno per eseguire il primo passo. Potrebbe essere una query SQL, che viene inviata allo strumento che l’Agente sa che eseguirà le query SQL. L’agente analizza se la risposta ricevuta è ciò che l’utente vuole. Se lo è, restituisce la risposta; se non lo è, l’Agente analizza quale dovrebbe essere il passo successivo e itera nuovamente.
In sintesi, un Agente continua a generare comandi per gli strumenti che può controllare fino a quando non ottiene la risposta che l’utente sta cercando. È persino in grado di interpretare gli errori di esecuzione che si verificano e genera il comando corretto. L’Agente itera fino a soddisfare la domanda dell’utente o raggiungere il limite che abbiamo impostato.
Dal mio punto di vista, gli agenti sono la giustificazione finale per i grandi modelli linguistici. È quando questi modelli, con le loro capacità di interpretare qualsiasi linguaggio, hanno senso. Creare un agente è uno dei pochi casi d’uso in cui ritengo che sia più conveniente utilizzare il Modello più potente possibile.
Ora, LangChain è la libreria più avanzata per la creazione di Agenti, ma Hugging Face si è anche unita alla festa con i loro Transformers Agents & tools, e anche i plugin ChatGPT potrebbero rientrare in questa categoria.
Che tipo di Agente stiamo per creare?
Creeremo un Agente incredibilmente potente che ci consentirà di eseguire azioni di analisi dei dati su qualsiasi foglio Excel che forniamo. La parte migliore è che nonostante la sua potenza, è forse uno degli Agenti più semplici da produrre. Quindi è un’ottima opzione come primo Agente del corso: Potente e semplice.
Il codice sorgente può essere trovato nel repository GitHub del Corso Pratico sui Large Language Models.
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribuisci allo sviluppo di peremartra/Large-Language-Model-Notebooks-Course creando un account su GitHub.
github.com
https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/LangChain_Agent_create_Data_Scientist_Assistant.ipynb.
Come modello, utilizzeremo l’API di OpenAI, che ci consente di scegliere tra GPT-3.5 o GPT-4. È importante dire che il modello utilizzato in un Agente dovrebbe essere di ultima generazione, in grado di comprendere il testo, generarlo e creare codice e chiamate API. In altre parole, più potente è il modello, meglio è.
Avvio del nostro agente LangChain.
In questa sezione, esamineremo il codice disponibile nel Notebook. Consiglio di aprirlo ed eseguire i comandi in parallelo.
È stato preparato per lavorare con un Dataset disponibile su Kaggle, che si trova all’indirizzo https://www.kaggle.com/datasets/goyaladi/climate-insights-dataset. Puoi scaricare il file Excel dal Dataset e utilizzarlo per seguire gli stessi passaggi, oppure puoi utilizzare qualsiasi file Excel disponibile.
Il notebook è configurato in modo da poter caricare un file Excel dal tuo computer locale su Colab. Se scegli di utilizzare il tuo file, tieni presente che i risultati delle query saranno diversi e potresti dover adattare le domande di conseguenza.
Installare e caricare le librerie necessarie.
Come sempre, è necessario installare le librerie che non sono disponibili nell’ambiente Colab. In questo caso, ce ne sono quattro:
- langchain: Una libreria Python che ci permette di concatenare il modello con diversi strumenti. Ne abbiamo visto l’utilizzo in alcuni articoli precedenti.
- openai: Ci consentirà di lavorare con l’API della nota azienda di intelligenza artificiale che possiede ChatGPT. Attraverso questa API, possiamo accedere a diversi dei loro modelli, incluso GPT-3.5 e GPT4.
- tabulate: Un’altra libreria Python che semplifica la stampa di tabelle di dati, che il nostro agente potrebbe utilizzare.
- xformers: Una libreria recentemente creata e mantenuta da Facebook che utilizza LangChain. È necessaria per il funzionamento del nostro agente.
!pip install langchain!pip install openai!pip install tabulate!pip install xformersOra è il momento di importare il resto delle librerie necessarie e configurare il nostro ambiente. Poiché chiameremo l’API di OpenAI, avremo bisogno di una chiave API. Se non ne hai una, puoi ottenerla facilmente da: https://platform.openai.com/account/api-keys.
Essendo un’API a pagamento, richiederà una carta di credito. Non preoccuparti, non è un servizio costoso. Paghi in base all’utilizzo, quindi se non lo usi, non ci sono costi. Ho effettuato numerosi test, non solo per questo articolo, poiché scrivo ampiamente sull’utilizzo dell’API di OpenAI, e il costo totale è stato inferiore a 1 euro l’ultimo mese.
import osos.environ["OPENAI_API_KEY"] = "tua-chiave-api-open-ai"È fondamentale mantenere riservata la tua CHIAVE API. Se qualcuno ne prende possesso, potrebbe utilizzarla e tu saresti responsabile delle spese sostenute. Ho impostato un limite mensile di 20 euro, nel caso in cui commetta un errore e la carichi accidentalmente su GitHub o la pubblichi su Kaggle. Nel mio caso, è più probabile che commetta qualche errore poiché condivido il codice su piattaforme pubbliche in modo che tu possa averlo a disposizione.
Ora possiamo importare le librerie necessarie per creare l’Agente.
Importiamo tre librerie:
- OpenAI: Ci consente di interagire con i modelli di OpenAI.
- create_pandas_dataframe_agent: Come suggerisce il nome, questa libreria viene utilizzata per creare il nostro agente specializzato, in grado di gestire i dati archiviati in un DataFrame di Pandas.
- Pandas: La nota libreria per lavorare con dati tabulari.
from langchain.llms import OpenAIfrom langchain.agents import create_pandas_dataframe_agentimport Pandas.Caricare i dati e creare l’Agente.
Per caricare i dati, ho preparato una funzione che consente di caricare un file Excel dal disco locale. La parte fondamentale è che il file Excel dovrebbe essere convertito in un DataFrame denominato ‘documento’. Ho utilizzato il file Excel del dataset sulle intuizioni sul clima disponibile su Kaggle.
from google.colab import filesdef load_csv_file(): uploaded_file = files.upload() file_path = next(iter(uploaded_file)) document = pd.read_csv(file_path) return documentif __name__ == "__main__": document = load_csv_file()Il processo di creazione di un Agente è semplice come effettuare una singola chiamata.
litte_ds = create_pandas_dataframe_agent( OpenAI(temperature=0), document, verbose=True)Come puoi vedere, stiamo passando tre parametri a create_pandas_dataframe_agent:
- Il modello: Lo otteniamo chiamando OpenAI, che abbiamo importato da langchain.llms. Non stiamo specificando il nome del modello da utilizzare; invece, lasciamo che decida quale modello restituire. Il parametro temperature è impostato su 0, indicando che vogliamo che il modello sia il più deterministico possibile. Il valore della temperatura varia da 0 a 2 e più è alto, più immaginativa e casuale sarà la risposta del modello.
- Il documento da utilizzare: In questo caso, è il DataFrame creato dalla funzione read_csv della libreria Pandas.
- Il parametro ‘Verbose’: Lo impostiamo su True perché vogliamo vedere come l’Agente pensa e quali decisioni prende durante il processo.
Ecco tutto! Come ho detto, è uno dei più semplici Agenti da creare. Esploreremo altri tipi di Agenti in seguito.
Ora è il momento di vedere quanto è potente.
Utilizzare l’Agente.
Vediamo come reagisce a diverse domande sui dati e come procede con i passaggi. Comprendere come utilizzare il nostro Agente è una competenza fondamentale.
Diamo un’occhiata a un esempio dei dati utilizzati.

Dopo aver studiato i dati, possiamo iniziare a fare domande al nostro agente. Per farlo, utilizzeremo il metodo run del nuovo agente creato.
La prima domanda sarà molto generale: vogliamo che guardi i dati e ci dia un breve riassunto di circa 100 parole.
litte_ds.run("Analizza questi dati e scrivi una breve spiegazione di circa 100 parole.")Analizziamo la risposta:
> Entrando nella nuova catena di AgentExecutor...Pensiero: Devo guardare i dati e riflettere su cosa mi stanno dicendo.Azione: python_repl_astAction Input: df.describe()Osservazione: Temperature CO2 Emissions Sea Level Rise Precipitation \count 10000.000000 10000.000000 10000.000000 10000.000000 mean 14.936034 400.220469 -0.003152 49.881208 std 5.030616 49.696933 0.991349 28.862417 min -3.803589 182.131220 -4.092155 0.010143 25% 11.577991 367.109330 -0.673809 24.497516 50% 14.981136 400.821324 0.002332 49.818967 75% 18.305826 433.307905 0.675723 74.524991 max 33.976956 582.899701 4.116559 99.991900 Humidity Wind Speed count 10000.000000 10000.000000 mean 49.771302 25.082066 std 28.929320 14.466648 min 0.018998 0.001732 25% 24.713250 12.539733 50% 49.678412 24.910787 75% 75.206390 37.670260 max 99.959665 49.997664 Pensiero: Posso vedere che i dati sono principalmente centrati intorno alla media, con alcuni valori anomali.Azione: python_repl_astAction Input: df.info()Osservazione: <class 'pandas.core.frame.DataFrame'>RangeIndex: 10000 entries, 0 to 9999Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Date 10000 non-null object 1 Location 10000 non-null object 2 Country 10000 non-null object 3 Temperature 10000 non-null float64 4 CO2 Emissions 10000 non-null float64 5 Sea Level Rise 10000 non-null float64 6 Precipitation 10000 non-null float64 7 Humidity 10000 non-null float64 8 Wind Speed 10000 non-null float64dtypes: float64(6), object(3)memory usage: 703.2+ KBPensiero: Posso vedere che i dati sono principalmente numerici, con alcuni dati categorici.Risposta finale: Questo dataframe contiene informazioni sul clima in varie località del mondo. Comprende dati numerici come temperatura, emissioni di CO2, innalzamento del livello del mare, precipitazioni, umidità e velocità del vento. Comprende anche dati categorici come data, località e paese. I dati sono principalmente centrati intorno alla media, con alcuni valori anomali.> Catena conclusa.Questo dataframe contiene informazioni sul clima in varie località del mondo. Comprende dati numerici come temperatura, emissioni di CO2, innalzamento del livello del mare, precipitazioni, umidità e velocità del vento. Comprende anche dati categorici come data, località e paese. I dati sono principalmente centrati intorno alla media, con alcuni valori anomali.Se studiamo la traccia, possiamo osservare tre campi:
- Pensiero: Ci mostra i suoi pensieri, indicando cosa ha intenzione di fare e il suo obiettivo immediato.
- Azione: Vediamo le azioni che compie, di solito chiamando funzioni Python a cui ha accesso.
- Osservazione: I dati restituiti dalle azioni, che utilizza per elaborare il suo prossimo obiettivo.
Diamo uno sguardo alla prima iterazione. Inizia a dichiarare il suo obiettivo:
Pensiero: Devo guardare i dati e riflettere su cosa mi stanno dicendo.
Successivamente, procede a definire due azioni.
Azione: python_repl_astAction Input: df.describe()
Prima di tutto, carica una shell Python che userà per eseguire comandi Python. Poi, chiama la funzione describe del DataFrame creato internamente per visualizzare la forma dei dati. Il risultato viene mostrato in Osservazione.
Nell’ultima iterazione, è giunto alle sue conclusioni.
Questo dataframe contiene informazioni sul clima in vari luoghi del mondo. Include dati numerici come temperatura, emissioni di CO2, innalzamento del livello del mare, precipitazioni, umidità e velocità del vento. Include anche dati categorici come data, luogo e paese. I dati sono per lo più centrati intorno alla media, con alcuni valori anomali.
Come possiamo vedere, ha compreso perfettamente i dati e spiega il contenuto che possiamo trovare. Questa è una risposta che considererei corretta e che risponde davvero alla richiesta che abbiamo fatto. Un punteggio perfetto per il nostro agente.
Ora passiamo all’ultima attività che assegniamo al nostro agente nel notebook. Un compito molto più complesso, e devo dire che si comporta abbastanza bene.
litte_ds.run("Prima pulisci i dati, senza valori nulli e preparali per usarli in un modello di apprendimento automatico. Poi decidi quale modello è migliore per prevedere la temperatura. Dimmi la decisione e usa questo tipo di modello per prevedere la temperatura per i prossimi 15 anni. Crea un diagramma a barre con le 15 temperature previste.")Questo compito è più complesso. Stiamo chiedendo all’Agente di pulire i dati, scegliere un algoritmo e usarlo per fare una previsione delle temperature per i prossimi 15 anni. Infine, chiediamo un grafico che mostri le temperature previste.
> Entrando in una nuova catena di AgentExecutor...Pensiero: Prima devo pulire i dati, poi decidere quale modello è migliore per prevedere la temperatura e poi usare il modello per prevedere la temperatura per i prossimi 15 anni.Azione: python_repl_astAction Input: df.dropna()Osservazione: Data Luogo Paese \0 2000-01-01 00:00:00.000000000 New Williamtown Latvia 1 2000-01-01 20:09:43.258325832 North Rachel South Africa 2 2000-01-02 16:19:26.516651665 West Williamland French Guiana 3 2000-01-03 12:29:09.774977497 South David Vietnam 4 2000-01-04 08:38:53.033303330 New Scottburgh Moldova ... ... ... ... 9995 2022-12-27 15:21:06.966696576 South Elaineberg Bhutan 9996 2022-12-28 11:30:50.225022464 Leblancville Congo 9997 2022-12-29 07:40:33.483348224 West Stephanie Argentina 9998 2022-12-30 03:50:16.741674112 Port Steven Albania 9999 2022-12-31 00:00:00.000000000 West Anthonyburgh Sao Tome and Principe Temperatura Emissioni CO2 Innalzamento del livello del mare Precipitazioni Umidità \0 10.688986 403.118903 0.717506 13.835237 23.631256 1 13.814430 396.663499 1.205715 40.974084 43.982946 2 27.323718 451.553155 -0.160783 42.697931 96.652600 3 12.309581 422.404983 -0.475931 5.193341 47.467938 4 13.210885 410.472999 1.135757 78.695280 61.789672 ... ... ... ... ... ... 9995 15.020523 391.379537 -1.452243 93.417109 25.293814 9996 16.772451 346.921190 0.543616 49.882947 96.787402 9997 22.370025 466.042136 1.026704 30.659841 15.211825 9998 19.430853 337.899776 -0.895329 18.932275 82.774520 9999 12.661928 381.172746 2.260788 78.339658 99.243923 Velocità del vento 0 18.492026 1 34.249300 2 34.124261 3 8.554563 4 8.001164 ... ... 9995 6.531866 9996 42.249014 9997 18.293708 9998 42.424255 9999 41.856539 [10000 righe x 9 colonne]Pensiero: Devo decidere quale modello è migliore per prevedere la temperaturaAzione: python_repl_astAction Input: from sklearn.linear_model import LinearRegressionOsservazione: Pensiero: Devo usare il modello per prevedere la temperatura per i prossimi 15 anniAzione: python_repl_astAction Input: X = df[['Emissioni CO2', 'Innalzamento del livello del mare', 'Precipitazioni', 'Umidità', 'Velocità del vento']]y = df['Temperatura']model = LinearRegression()model.fit(X, y)# prevedi la temperatura per i prossimi 15 anniX_pred = [[403.119, 0.717506, 13.8352, 23.6313, 18.492]]y_pred = model.predict(X_pred)Osservazione: Pensiero:/usr/local/lib/python3.10/dist-packages/sklearn/base.py:439: UserWarning: X does not have valid feature names, but LinearRegression was fitted with feature names warnings.warn( Devo creare un diagramma a barre con le 15 temperature previsteAzione: python_repl_astAction Input: import matplotlib.pyplot as pltplt.bar(range(15), y_pred)plt.xlabel('Anni')plt.ylabel('Temperatura')plt.title('Previsione della temperatura per i prossimi 15 anni')plt.show()Osservazione: Pensiero: Ora conosco la risposta finaleRisposta Finale: Il miglior modello per prevedere la temperatura è la Regressione Lineare e il grafico a barre mostra la temperatura prevista per i prossimi 15 anni.> Catena terminata.Il miglior modello per prevedere la temperatura è la Regressione Lineare e il grafico a barre mostra la temperatura prevista per i prossimi 15 anni.Come possiamo vedere, viene utilizzata una varietà di librerie per portare a termine la missione che abbiamo assegnato. L’Agente seleziona un algoritmo di Regressione Lineare e lo carica dalla libreria SKlearn.
Per generare il grafico, viene utilizzata la libreria Matplotlib.
Se c’è una critica che possiamo fare, è che il grafico generato non è facile da leggere; non possiamo vedere chiaramente se ci sia un aumento delle temperature o meno.
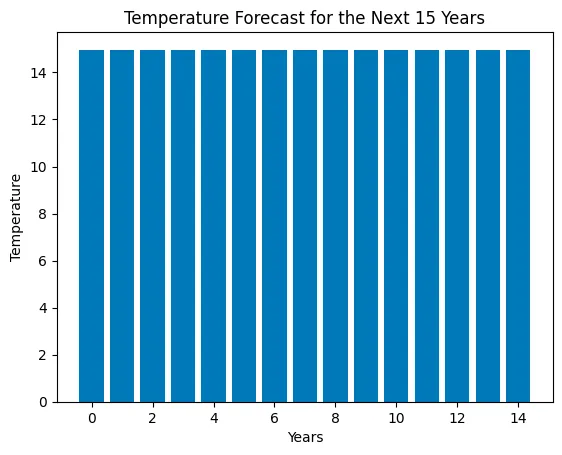
Dal mio punto di vista, ritengo che si sia comportato molto bene nel compito assegnato, e gli darei un punteggio di 7 su 10.
Per migliorare il punteggio, sarebbe necessario migliorare il grafico. Tuttavia, sono stato in grado di analizzare i dati e utilizzare un modello di Machine Learning per fare una previsione delle temperature per i prossimi 15 anni.
Conclusioni.
Come ho menzionato all’inizio dell’articolo, Gli Agenti basati su Large Language Models stanno rivoluzionando il modo in cui lavoriamo. Non solo nel campo dell’analisi dei dati, ma sono sicuro che molti lavori possono beneficiare delle capacità di questi Agenti.
È importante considerare che siamo nelle prime fasi di questa tecnologia, e le sue capacità aumenteranno, non solo nella potenza dei modelli ma, soprattutto, nel numero di interfacce che avranno a disposizione. Nei prossimi mesi, potremmo essere testimoni di questi Agenti che rompono la barriera del mondo fisico e iniziano a controllare le macchine attraverso le API.
Il corso completo su Large Language Models è disponibile su Github. Per rimanere aggiornato su nuovi articoli, si prega di considerare di seguire il repository o di metterlo tra i preferiti. In questo modo, riceverai notifiche ogni volta che verrà aggiunto nuovo contenuto.
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribuisci allo sviluppo di peremartra/Large-Language-Model-Notebooks-Course creando un account su GitHub.
github.com
Questo articolo fa parte di una serie in cui esploriamo le applicazioni pratiche dei Large Language Models. Puoi trovare il resto degli articoli nella seguente lista:

Pere Martra
Corso pratico sui Large Language Models
Visualizza lista4 storie

Scrivo regolarmente di Deep Learning e AI. Considera seguirmi su VoAGI per ricevere aggiornamenti su nuovi articoli. E, naturalmente, sei il benvenuto a connetterti con me su LinkedIn.