Aprire a forza la libreria Transformers di Hugging Face
Apri la libreria Transformers di Hugging Face
Una guida rapida all’uso di LLM open-source
Questo è il terzo articolo di una serie sull’uso di grandi modelli linguistici (LLM) nella pratica. Qui fornirò una guida per principianti alla libreria Hugging Face Transformers, che offre un modo facile e gratuito per lavorare con una vasta gamma di modelli linguistici open-source. Inizierò rivedendo i concetti chiave e poi passerò al codice di esempio in Python.
Nell’articolo precedente di questa serie, abbiamo esplorato l’API Python di OpenAI e l’abbiamo utilizzata per creare un chatbot personalizzato. Uno svantaggio di questa API, però, è che le chiamate all’API hanno un costo, il che potrebbe non essere scalabile per alcuni casi d’uso.
In questi scenari, potrebbe essere vantaggioso rivolgersi a soluzioni open-source. Un modo popolare per farlo è attraverso la libreria Transformers di Hugging Face.
Cosa è Hugging Face?
Hugging Face è un’azienda di intelligenza artificiale che è diventata un importante punto di riferimento per l’apprendimento automatico open-source. La loro piattaforma ha 3 elementi principali che consentono agli utenti di accedere e condividere risorse di apprendimento automatico.
- I ricercatori di Google DeepMind presentano RT-2 un nuovo modello Visione-Linguaggio-Azione (VLA) che impara sia dai dati web che da quelli robotici e li trasforma in azione.
- 3 Funzioni Pandas per il merge dei DataFrame
- Il CEO di NVIDIA, Jensen Huang, torna a SIGGRAPH
Il primo è il loro repository in rapida crescita di modelli di apprendimento automatico open-source pre-addestrati per cose come l’elaborazione del linguaggio naturale (NLP), la visione artificiale e altro ancora. Il secondo è la loro libreria di set di dati per addestrare modelli di apprendimento automatico per quasi ogni compito. Terzo e ultimo, c’è Spaces, che è una collezione di app di apprendimento automatico open-source ospitate da Hugging Face.
La potenza di queste risorse è che sono generate dalla comunità, il che sfrutta tutti i vantaggi dell’open-source (ovvero senza costi, ampia varietà di strumenti, risorse di alta qualità e rapida velocità di innovazione). Mentre queste rendono la creazione di progetti di apprendimento automatico potenti più accessibile rispetto al passato, c’è un altro elemento chiave dell’ecosistema Hugging Face: la libreria Transformers.
🤗Transformers
Transformers è una libreria Python che facilita il download e l’addestramento di modelli di apprendimento automatico all’avanguardia. Sebbene sia stata inizialmente creata per sviluppare modelli di linguaggio, la sua funzionalità si è estesa per includere modelli per la visione artificiale, l’elaborazione audio e altro ancora.
Due grandi punti di forza di questa libreria sono, in primo luogo, l’integrazione facile con i repository di Modelli, Set di dati e Spaces di Hugging Face (previously mentioned), e in secondo luogo, il supporto della libreria ad altri popolari framework di apprendimento automatico come PyTorch e TensorFlow.
Ciò si traduce in una piattaforma semplice e flessibile all-in-one per il download, l’addestramento e il deployment di modelli e app di apprendimento automatico.
Pipeline()
Il modo più semplice per iniziare a utilizzare la libreria è tramite la funzione pipeline(), che astrae le attività di NLP (e altre) in una sola riga di codice. Ad esempio, se vogliamo fare un’analisi di sentimenti, dovremmo selezionare un modello, tokenizzare il testo di input, passarlo attraverso il modello e decodificare l’output numerico per determinare l’etichetta del sentiment (positivo o negativo).
Anche se potrebbe sembrare un sacco di passaggi, possiamo fare tutto questo in una sola riga tramite la funzione pipeline(), come mostrato nel frammento di codice qui sotto.
pipeline(task="sentiment-analysis")("Love this!")# output -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]Ovviamente, l’analisi dei sentimenti non è l’unica cosa che possiamo fare qui. Quasi ogni attività di NLP può essere svolta in questo modo, ad esempio riassunto, traduzione, domanda-risposta, estrazione di caratteristiche (ovvero embedding di testo), generazione di testo, classificazione a zero-shot e altro ancora. Per una lista completa delle attività integrate, consulta la documentazione di pipeline().
Nell’esempio di codice sopra, poiché non abbiamo specificato un modello, è stato utilizzato il modello predefinito per l’analisi dei sentimenti (ovvero distilbert-base-uncased-finetuned-sst-2-english). Tuttavia, se volessimo essere più espliciti, avremmo potuto utilizzare la seguente riga di codice.
pipeline(task="sentiment-analysis", model='distilbert-base-uncased-finetuned-sst-2-english')("Mi piace!")# output -> [{'label': 'POSITIVE', 'score': 0.9998745918273926}]Uno dei maggiori vantaggi della libreria Transformers è che avremmo potuto utilizzare facilmente uno qualsiasi dei più di 28.000 modelli di classificazione del testo presenti nel repository dei modelli di Hugging Face semplicemente cambiando il nome del modello passato alla funzione pipeline().
Modelli
Esiste un vasto repository di modelli pre-addestrati disponibili su Hugging Face (277.528 al momento in cui scrivo). Quasi tutti questi modelli possono essere utilizzati facilmente tramite Transformers, utilizzando la stessa sintassi che abbiamo visto nel blocco di codice precedente.
Tuttavia, i modelli su Hugging Face non sono solo per la libreria Transformers. Ci sono modelli per altri framework di apprendimento automatico popolari come PyTorch, Tensorflow, Jax. Ciò rende il repository dei modelli di Hugging Face utile anche per i praticanti di ML al di là del contesto della libreria Transformers.
Per vedere come navigare nel repository, consideriamo un esempio. Supponiamo che vogliamo un modello che possa generare testo, ma vogliamo che sia disponibile tramite la libreria Transformers in modo da poterlo utilizzare in una sola riga di codice (come abbiamo fatto sopra). Possiamo facilmente visualizzare tutti i modelli che soddisfano questi criteri utilizzando i filtri “Tasks” e “Libraries”.
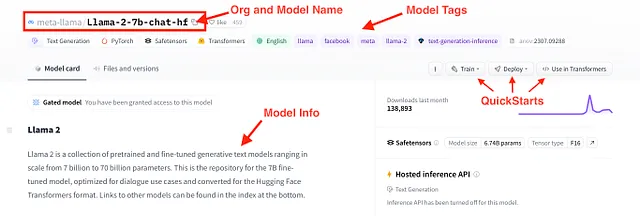
Un modello che soddisfa questi criteri è il nuovo rilasciato Llama 2. Più precisamente, Llama-2-7b-chat-hf, che è un modello della famiglia Llama 2 con circa 7 miliardi di parametri, ottimizzato per le chat e nel formato Hugging Face Transformers. Possiamo ottenere ulteriori informazioni su questo modello tramite la sua model card, che viene mostrata nella figura qui sotto.
Installazione 🤗Transformers (con Conda)
Ora che abbiamo un’idea di base delle risorse offerte da Hugging Face e dalla libreria Transformers, vediamo come possiamo utilizzarle. Iniziamo installando la libreria e le altre dipendenze.
Hugging Face fornisce una guida all’installazione sul suo sito web. Quindi, non cercherò di duplicare quella guida qui (poveramente). Tuttavia, fornirò una guida rapida in 2 passaggi su come configurare l’ambiente conda per il codice di esempio qui sotto.
Passo 1) Il primo passo è scaricare il file hf-env.yml disponibile nel repository GitHub. Puoi scaricare direttamente il file o clonare l’intero repository.
Passo 2) Successivamente, nel tuo terminale (o prompt dei comandi di Anaconda), puoi creare un nuovo ambiente conda basato su hf-env.yml utilizzando i seguenti comandi
>>> cd <directory con hf-env.yml>>>> conda env create --file hf-env.ymlPotrebbe richiedere un paio di minuti per l’installazione, ma una volta completata, dovresti essere pronto!
Codice di Esempio: NLP con 🤗Transformers
Con le librerie necessarie installate, passiamo ad alcuni esempi di codice. Qui esamineremo 3 casi d’uso di NLP, ovvero, analisi del sentiment, riassunto e generazione di testo conversazionale, utilizzando la funzione pipeline().
Alla fine, utilizzeremo Gradio per generare rapidamente un’interfaccia utente (UI) per uno qualsiasi di questi casi d’uso e lo distribuiremo come un’app su Hugging Face Spaces. Tutto il codice di esempio è disponibile nel repository GitHub.
Analisi del Sentimento
Iniziamo con l’analisi del sentimento. Ricordate prima quando abbiamo utilizzato la funzione pipeline per fare qualcosa come il blocco di codice qui sotto, dove creiamo un classificatore che può etichettare il testo di input come positivo o negativo.
from transformers import pipelineclassifier = pipeline(task="sentiment-analysis", \ model="distilbert-base-uncased-finetuned-sst-2-english")classifier("Lo odio.")# output -> [{'label': 'NEGATIVE', 'score': 0.9997110962867737}]Per fare un passo avanti, invece di elaborare il testo uno per uno, possiamo passare una lista al classificatore per elaborarla come un batch.
text_list = ["Questo è fantastico", \ "Grazie per niente", \ "Devi lavorare sul tuo viso", \ "Sei bellissima, non cambiare mai!"]classifier(text_list)# output -> [{'label': 'POSITIVE', 'score': 0.9998785257339478},# {'label': 'POSITIVE', 'score': 0.9680058360099792},# {'label': 'NEGATIVE', 'score': 0.8776106238365173},# {'label': 'POSITIVE', 'score': 0.9998120665550232}]Tuttavia, i modelli di classificazione del testo su Hugging Face non sono limitati solo al sentimento positivo-negativo. Ad esempio, il modello “roberta-base-go_emotions” di SamLowe genera una serie di etichette di classe. Possiamo applicare facilmente questo modello al testo, come mostrato nel frammento di codice qui sotto.
classifier = pipeline(task="text-classification", \ model="SamLowe/roberta-base-go_emotions", top_k=None)classifier(text_list[0])# output -> [[{'label': 'ammirazione', 'score': 0.9526104927062988},# {'label': 'approvazione', 'score': 0.03047208860516548},# {'label': 'neutrale', 'score': 0.015236231498420238},# {'label': 'eccitazione', 'score': 0.006063772831112146},# {'label': 'gratitudine', 'score': 0.005296189337968826},# {'label': 'gioia', 'score': 0.004475208930671215},# ... e molti altriSintesi
Un altro modo in cui possiamo utilizzare la funzione pipeline() è per la sintesi del testo. Anche se questa è un’attività completamente diversa dall’analisi del sentimento, la sintassi è quasi identica.
Prima carichiamo un modello di sintesi. Poi passiamo del testo insieme a un paio di parametri di input.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")text = """Hugging Face è un'azienda di intelligenza artificiale che è diventata un importante centro per l'apprendimento automatico open-source. La loro piattaforma ha 3 elementi principali che permettono agli utenti di accedere e condividere risorse di apprendimento automatico. Primo, c'è il loro repository in rapida crescita di modelli di apprendimento automatico open-source pre-addestrati per cose come l'elaborazione del linguaggio naturale (NLP), la visione artificiale e altro ancora. Secondo, c'è la loro libreria di dataset per l'addestramento di modelli di apprendimento automatico per quasi ogni compito. Terzo e infine, ci sono gli Spazi, che sono una collezione di apprendimento automatico open-source. Il potere di queste risorse è che sono generate dalla comunità, il che sfrutta tutti i vantaggi del software open-source, ovvero senza costi, ampia diversità di strumenti, risorse di alta qualità e un ritmo di innovazione rapido. Sebbene questo renda la costruzione di progetti di apprendimento automatico potenti più accessibile rispetto al passato, c'è un altro elemento chiave dell'ecosistema di Hugging Face: la loro libreria Transformers."""summarized_text = summarizer(text, min_length=5, max_length=140)[0]['summary_text']print(summarized_text)# output -> 'Hugging Face è un'azienda di intelligenza artificiale che è diventata un importante centro per l'apprendimento automatico open-source. Hanno 3 elementi principali che permettono agli utenti di accedere e condividere risorse di apprendimento automatico.' Per casi d’uso più sofisticati, potrebbe essere necessario utilizzare più modelli in successione. Ad esempio, possiamo applicare l’analisi del sentimento al testo sintetizzato per velocizzare l’esecuzione.
classifier(summarized_text)# output -> [[{'label': 'neutrale', 'score': 0.9101783633232117}, # {'label': 'approvazione', 'score': 0.08781372010707855}, # {'label': 'realizzazione', 'score': 0.023256294429302216}, # {'label': 'fastidio', 'score': 0.006623792927712202}, # {'label': 'ammirazione', 'score': 0.004981081001460552}, # {'label': 'disapprovazione', 'score': 0.004730119835585356}, # {'label': 'ottimismo', 'score': 0.0033590723760426044}, # ... e molti altriConversazionale
Finalmente, possiamo utilizzare modelli sviluppati appositamente per generare testo conversazionale. Poiché le conversazioni richiedono che i prompt e le risposte passate vengano passati alle risposte del modello successivo, la sintassi è leggermente diversa qui. Tuttavia, iniziamo istanziando il nostro modello utilizzando la funzione pipeline().
chatbot = pipeline(model="facebook/blenderbot-400M-distill")Successivamente, possiamo utilizzare la classe Conversation() per gestire l’andata e ritorno. La inizializziamo con un prompt dell’utente, quindi la passiamo al modello del chatbot dal blocco di codice precedente.
from transformers import Conversationconversation = Conversation("Ciao, sono Shaw, come stai?")conversation = chatbot(conversation)print(conversation)# output -> ID Conversazione: 9248ee7d-2a58-4355-9fba-525189fae206 # utente >> Ciao, sono Shaw, come stai? # chatbot >> Sto bene. Come stai questa sera? Sono appena tornato a casa dal lavoro. Per mantenere la conversazione in corso, possiamo utilizzare il metodo add_user_input() per aggiungere un altro prompt alla conversazione. Quindi passiamo nuovamente l’oggetto conversation al chatbot.
conversation.add_user_input("Dove lavori?")conversation = chatbot(conversation)print(conversation)# output -> ID Conversazione: 9248ee7d-2a58-4355-9fba-525189fae206 # utente >> Ciao, sono Shaw, come stai? # chatbot >> Sto bene. Come stai questa sera? Sono appena tornato a casa dal lavoro.# utente >> Dove lavori? # chatbot >> Lavoro in un negozio di alimentari. E tu? Cosa fai per vivere? Interfaccia utente del chatbot con Gradio
Anche se otteniamo la funzionalità base del chatbot con la libreria Transformer, questa è un modo scomodo per interagire con un chatbot. Per rendere l’interazione un po’ più intuitiva, possiamo utilizzare Gradio per creare una front-end in poche righe di codice Python.
Ciò viene fatto con il codice mostrato di seguito. In alto, inizializziamo due liste per memorizzare i messaggi dell’utente e le risposte del modello, rispettivamente. Poi definiamo una funzione che prenderà il prompt dell’utente e genererà un output del chatbot. Successivamente, creiamo l’interfaccia utente del chat utilizzando la classe Gradio ChatInterface(). Infine, avviamo l’applicazione.
message_list = []response_list = []def vanilla_chatbot(message, history): conversation = Conversation(text=message, past_user_inputs=message_list, generated_responses=response_list) conversation = chatbot(conversation) return conversation.generated_responses[-1]demo_chatbot = gr.ChatInterface(vanilla_chatbot, title="Chatbot Vanilla", description="Inserisci del testo per iniziare a chattare.")demo_chatbot.launch()In questo modo verrà creata l’interfaccia utente tramite un URL locale. Se la finestra non si apre automaticamente, è possibile copiare e incollare l’URL direttamente nel browser.
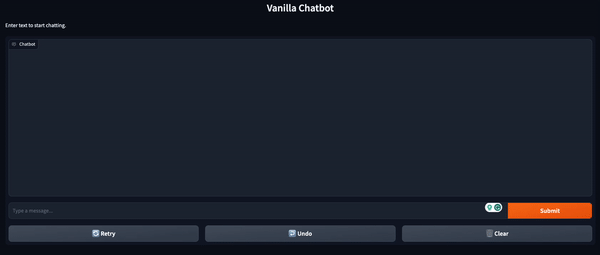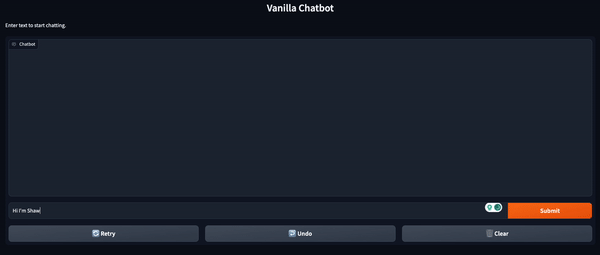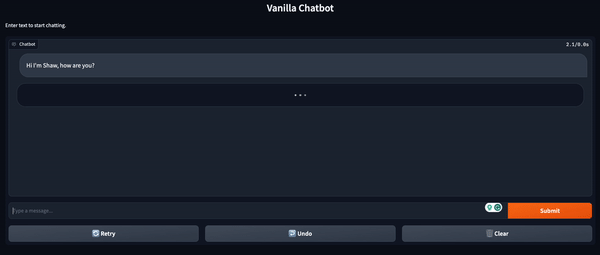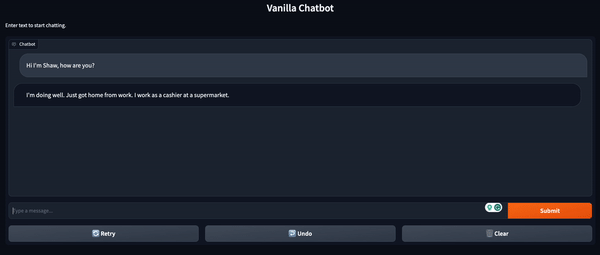
Spazi Hugging Face
Per andare un passo avanti, possiamo distribuire rapidamente questa interfaccia utente tramite Spazi Hugging Face. Questi sono repository Git ospitati da Hugging Face e potenziati da risorse computazionali. Sono disponibili opzioni gratuite e a pagamento a seconda del caso d’uso. Qui ci atteniamo all’opzione gratuita.
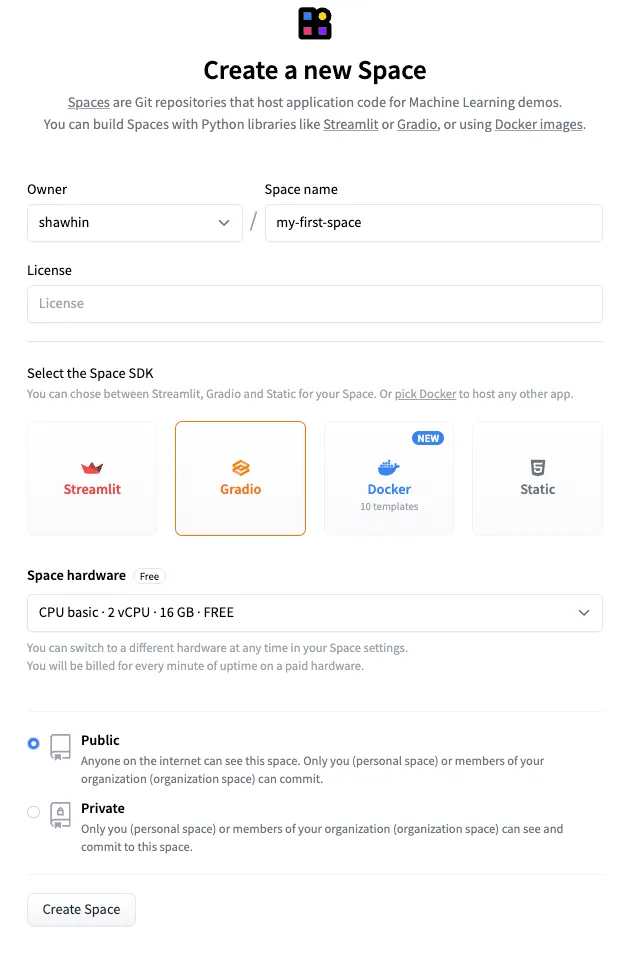
Per creare un nuovo spazio, andiamo prima alla pagina degli Spazi e clicchiamo su “Crea nuovo spazio”. Quindi, configuriamo lo spazio dandogli il nome ad esempio “my-first-space” e selezionando Gradio come SDK. Quindi clicchiamo su “Crea spazio”.
Successivamente, è necessario caricare i file app.py e requirements.txt nello Spazio. Il file app.py contiene il codice utilizzato per generare l’interfaccia utente Gradio, mentre il file requirements.txt specifica le dipendenze dell’applicazione. I file per questo esempio sono disponibili nel repository di GitHub e nello Spazio di Hugging Face.
Infine, inviamo il codice allo Spazio proprio come faremmo su GitHub. Il risultato finale è un’applicazione pubblica ospitata su Hugging Face Spaces.
Link dell’app: https://huggingface.co/spaces/shawhin/my-first-space
Conclusioni
Hugging Face è diventato sinonimo di modelli di linguaggio open-source e di apprendimento automatico. Il vantaggio più grande del loro ecosistema è che offre a sviluppatori, ricercatori e smanettoni di piccole dimensioni l’accesso a risorse di ML potenti.
Sebbene abbiamo coperto molte cose in questo post, abbiamo solo grattato la superficie di ciò che l’ecosistema di Hugging Face può fare. Nei futuri articoli di questa serie, esploreremo casi d’uso più avanzati e vedremo come affinare i modelli utilizzando 🤗Transformers.
👉 Ulteriori informazioni sui LLM: Introduzione | OpenAI API
Risorse
Contatti: Il mio sito web | Prenota una chiamata | Chiedimi qualsiasi cosa
Social: YouTube 🎥 | LinkedIn | Twitter
Supporto: Diventa un membro ⭐️ | Offrimi un caffè ☕️
Gli imprenditori dei dati
Una comunità per imprenditori nello spazio dei dati. 👉 Unisciti a Discord!
VoAGI.com
[1] Hugging Face — https://huggingface.co/
[2] Corso di Hugging Face — https://huggingface.co/learn/nlp-course/chapter1/1





