Dispatch basato sui dati
Data-driven dispatch
Utilizzare l’apprendimento supervisionato per prevedere le chiamate di servizio per le collisioni automobilistiche a Chicago
Introduzione
Nel mondo frenetico di oggi, la necessità di decisioni basate sui dati nei sistemi di risposta alle chiamate è diventata essenziale. I dispatcher effettueranno una sorta di triage durante l’ascolto delle chiamate, dando priorità ai casi in base alla gravità e all’urgenza temporale, tra altri fattori. C’è il potenziale per ottimizzare questo processo sfruttando la potenza dei modelli di apprendimento supervisionato, per fare previsioni più accurate della gravità del caso in collaborazione con la valutazione di un dispatcher umano.
In questo post, voglio mostrare una soluzione che ho sviluppato per migliorare le previsioni delle vittime e/o dei danni seri ai veicoli a seguito di collisioni automobilistiche a Chicago. Sono stati presi in considerazione fattori come la posizione dell’incidente, le condizioni della strada, il limite di velocità e l’orario dell’evento per rispondere a una semplice domanda sì o no: sarà necessaria un’ambulanza o un carro attrezzi per questo incidente automobilistico?
In poche parole, l’obiettivo principale di questo strumento di apprendimento automatico è classificare le collisioni che probabilmente richiederanno una chiamata di servizio (medica, carro attrezzi o entrambe) in base ad altri fattori noti. Sfruttando questo strumento, gli operatori sarebbero in grado di allocare efficientemente le risorse in diverse parti della città, in base a varie condizioni come il clima e l’orario del giorno.
Perché uno strumento del genere sia accurato ed efficace, sarebbe necessaria una grande fonte di dati per fare previsioni dai dati storici. Fortunatamente, la città di Chicago ha già una risorsa del genere (il Chicago Data Portal), quindi questi dati verranno utilizzati come caso di test.
- Lettura in spiaggia una breve storia dei modelli pre-addestrati
- Ho creato un’applicazione di intelligenza artificiale in 3 giorni
- Organizzare il Monorepo di ML con Pants
L’implementazione di modelli predittivi di questo tipo migliorerebbe sicuramente la preparazione e l’efficienza dei tempi di risposta nel gestire le collisioni sulle strade cittadine. Ottenendo una comprensione dei modelli e delle tendenze sottostanti nei dati sulle collisioni, possiamo lavorare per promuovere ambienti stradali più sicuri e ottimizzare i servizi di emergenza.
Nella sezione successiva, descriverò i dettagli della pulizia dei dati, la creazione del modello, l’ottimizzazione e la valutazione, prima di analizzare i risultati del modello e trarre delle conclusioni. Un link alla cartella di GitHub per questo progetto, che include un notebook Jupyter e un rapporto più completo sul progetto, può essere trovato qui.
Raccolta e preparazione dei dati
Configurazione iniziale
Ho elencato di seguito le librerie di analisi dei dati di base utilizzate nel progetto; le librerie standard come pandas e numpy sono state utilizzate in tutto il progetto, insieme a pyplot di matplotlib e seaborn per la visualizzazione. Inoltre, ho utilizzato la libreria missingno per individuare lacune nei dati – trovo questa libreria estremamente utile per visualizzare i dati mancanti in un dataset e la consiglierei per qualsiasi progetto di data science che coinvolga i dataframes:
#analisi dei dati generica import osimport pandas as pdfrom datetime import dateimport matplotlib.pyplot as pltimport numpy as npimport seaborn as snsimport missingno as msnoSono state importate le funzioni del modulo di apprendimento automatico SciKit learn (sklearn) per creare il motore di apprendimento automatico. Queste funzioni sono mostrate qui di seguito: descriverò lo scopo di ciascuna di queste funzioni nella sezione Modello di classificazione in seguito:
#Preprocessingfrom sklearn.preprocessing import LabelEncoderfrom sklearn.preprocessing import StandardScaler# Modellifrom sklearn.neighbors import KNeighborsClassifier# Reportingfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import RandomizedSearchCV#metricsfrom sklearn.metrics import accuracy_scorefrom sklearn.metrics import f1_scorefrom sklearn.metrics import precision_scorefrom sklearn.metrics import recall_scoreI dati per questo progetto sono stati importati dal Chicago Data Portal, da due fonti:
- Collisioni del traffico: Dataset live delle collisioni dei veicoli nell’area di Chicago. Le caratteristiche di questo dataset sono le condizioni registrate al momento della collisione, come le condizioni meteorologiche, l’allineamento della strada, i dati di latitudine e longitudine, tra altri dettagli.
- Confini dei distretti di polizia: Un dataset statico che indica i confini dei distretti della polizia di Chicago; questo dataset viene utilizzato per integrare le informazioni sul distretto nel dataset delle collisioni del traffico. Questo può essere unito al dataset originale per eseguire analisi sui distretti con il maggior numero di collisioni frequenti.
Pulizia dei dati
Con entrambi i dataset importati, possono ora essere uniti per aggiungere i dati del distretto all’analisi finale. Ciò viene fatto utilizzando la funzione .merge() in pandas — ho utilizzato una join interna su entrambi i dataframe per catturare tutte le informazioni in entrambi, utilizzando i dati del distretto in entrambi come chiave di join (elencati come beat_of_occurrence nel dataset degli incidenti stradali e BEAT_NUM nel dataset dei distretti di polizia):
#unione dei dati sugli incidenti ai dati dei distrettii - join internocollisions = collision_raw.merge(beat_data, how='inner', left_on='beat_of_occurrence', right_on='BEAT_NUM' )Uno sguardo rapido alle informazioni fornite dalla funzione .info() mostra un certo numero di colonne con dati sparsi. Ciò può essere visualizzato utilizzando la funzione di matrice missingno:
#visualizzazione dei dati mancanti#ordinamento dei valori per data di ricezione del rapportocollisions = collisions.sort_values(by='crash_date', ascending=True)#visualizzazione della matrice dei dati mancantimsno.matrix(collisions)plt.show()#info dei dati ordinatiprint(collisions.info())Questo visualizza una matrice di dati mancanti in tutte le colonne, come si può vedere qui:
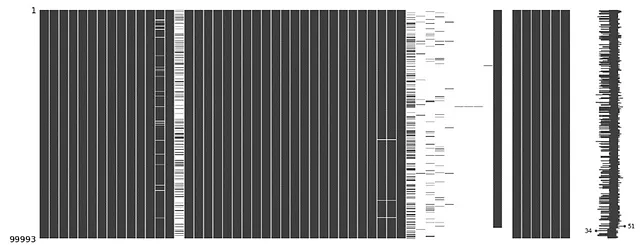
Eliminando le colonne con dati sparsi, è possibile ottenere un dataset molto più pulito; le colonne da eliminare vengono definite in una lista e quindi rimosse dal dataset utilizzando la funzione .drop():
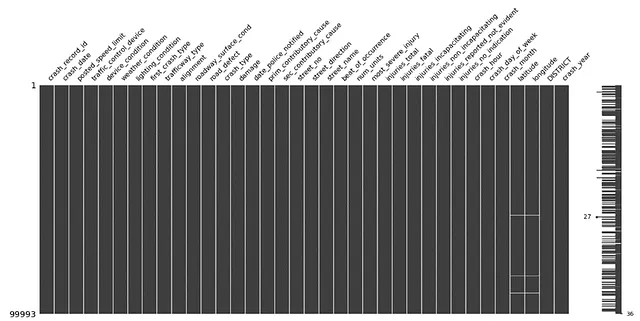
#definizione delle colonne non necessariedrop_cols = ['location', 'crash_date_est_i','report_type', 'intersection_related_i', 'hit_and_run_i', 'photos_taken_i', 'crash_date_est_i', 'injuries_unknown', 'private_property_i', 'statements_taken_i', 'dooring_i', 'work_zone_i', 'work_zone_type', 'workers_present_i','lane_cnt','the_geom','rd_no', 'SECTOR','BEAT','BEAT_NUM']#rimozione delle colonnecollisions=collisions.drop(columns=drop_cols)#visualizzazione della matrice dei dati mancantimsno.matrix(collisions)plt.show()#info dei dati ordinatiprint(collisions.info())Ciò porta a una matrice msno molto più pulita:
Osservando i dati per latitudine e longitudine, un piccolo gruppo di righe aveva valori nulli, e altre avevano erroneamente valori zero (molto probabilmente un errore di segnalazione):
Questi causerebbero errori nell’addestramento del modello, quindi li ho rimossi:
#Alcuni dati lat/long incorretti - è necessario rimuovere queste righecollisions = collisions[collisions['longitude']<-80]collisions = collisions[collisions['latitude']>40]Con i dati adeguatamente puliti, sono stato in grado di procedere con lo sviluppo del modello di classificazione.
Modello di classificazione
Analisi dei dati esplorativa
Prima di procedere con il modello di apprendimento automatico, è necessario eseguire un’analisi dei dati esplorativa (EDA) — ogni colonna del dataframe viene rappresentata su un istogramma, con intervalli di 50 per mostrare la distribuzione dei dati. Gli istogrammi sono utili nella fase di EDA per diversi motivi, principalmente perché danno una panoramica della distribuzione dei dati, aiutano a individuare gli outlier e, in definitiva, contribuiscono a prendere decisioni sull’ingegneria delle caratteristiche:
#visualizzazione degli istogrammi dei valori numericicollisions.hist(bins=50,figsize=(16,12))plt.show()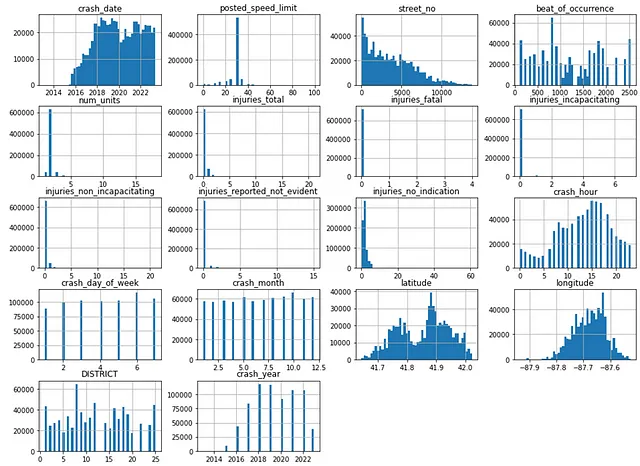
Uno sguardo sommario agli istogrammi delle colonne indica che i dati di latitudine sono bimodali, mentre i dati di longitudine sono distribuiti correttamente. Ciò richiederà una standardizzazione in modo da poter essere applicata meglio per scopi di apprendimento automatico.
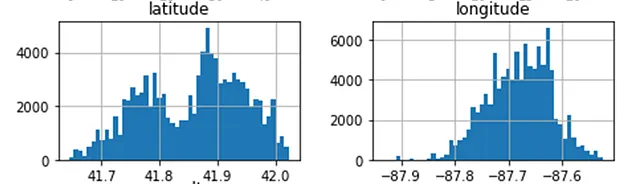
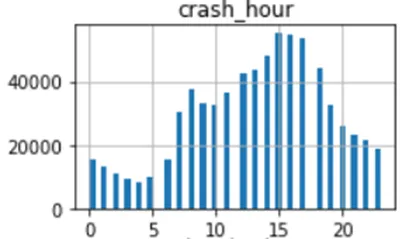
Inoltre, sembra che la colonna dell’ora dell’incidente sia ciclica per natura, e ciò può essere trasformato utilizzando una funzione trigonometrica (ad esempio il seno).
Scalatura e Trasformazione
La scalatura è una tecnica utilizzata nella pre-elaborazione dei dati per standardizzare le caratteristiche in modo che abbiano magnitudini simili. Ciò è particolarmente importante per i modelli di apprendimento automatico, poiché i modelli sono generalmente sensibili alla scala delle caratteristiche di input. Ho definito la funzione StandardScaler() per agire come scalatore in questo modello – questa funzione di scalatura trasforma i dati in modo che abbiano una media di 0 e una deviazione standard di 1.
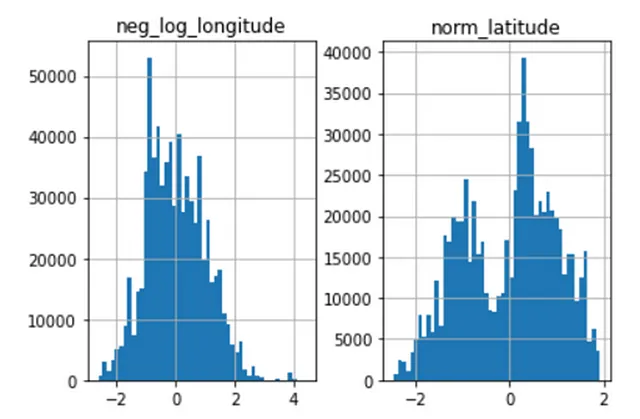
Per i dati con una distribuzione asimmetrica o bimodale, la scalatura può essere eseguita utilizzando funzioni logaritmiche. Le funzioni logaritmiche rendono i dati asimmetrici più simmetrici e riducono la coda sui dati, il che è utile quando si tratta di valori anomali. Ho scalato i dati di latitudine e longitudine in questo modo; poiché i dati di longitudine sono tutti negativi, è stato calcolato il logaritmo negativo e successivamente scalato.
# scalatura dati latitudine e longitudinescaler = StandardScaler()# Trasformazione logaritmica sulla longitudinecollisions_ml['neg_log_longitude'] = scaler.fit_transform(np.log1p(-collisions_ml['longitude']).values.reshape(-1,1))# Normalizzazione sulla latitudinecollisions_ml['norm_latitude'] = scaler.fit_transform(np.log1p(collisions['latitude']).values.reshape(-1, 1))Questo produce l’effetto desiderato, come si può vedere di seguito:
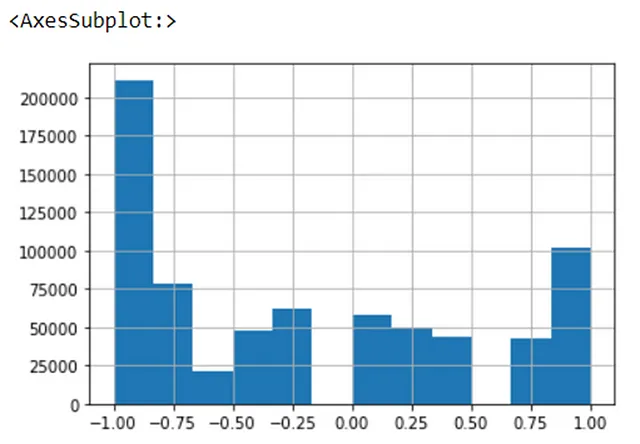
In confronto, i dati ciclici di solito vengono scalati utilizzando funzioni trigonometriche come il seno e il coseno. I dati dell’ora dell’incidente sembrano essere approssimativamente ciclici in base alle osservazioni precedenti, quindi ho applicato una funzione seno ai dati come segue – poiché la funzione sin() di numpy è in radianti, ho prima convertito l’input in radianti prima di calcolare il seno dell’input:
# trasformazione crash_hour# i dati sono ciclici, possono essere codificati utilizzando trasformazioni trigonometriche# trasformazione trigonometrica - sin(crash_hr)collisions_ml['sin_hr'] = np.sin(2*np.pi*collisions_ml['crash_hour']/24)Un istogramma dei dati trasformati può essere visto di seguito:
Infine, ho rimosso i dati non scalati dal modello per evitare interferenze con le previsioni del modello:
# eliminazione delle colonne precedenti latitudine/longitudinelat_long_drop_cols = ['longitude','latitude']collisions_ml.drop(lat_long_drop_cols,axis=1,inplace=True)# eliminazione della colonna crash_hourcollisions_ml.drop('crash_hour',axis=1,inplace=True)Codifica dei dati
Un’altra importante fase nella pre-elaborazione dei dati è la codifica dei dati – qui i dati non numerici (ad esempio le categorie) sono rappresentati in formato numerico, in modo da renderli compatibili con gli algoritmi di apprendimento automatico. Per i dati categorici in questo modello, ho utilizzato un metodo chiamato codifica delle etichette: ogni categoria in una colonna viene assegnata un valore numerico prima di essere inserita nel modello. Un diagramma di questo processo è mostrato di seguito:
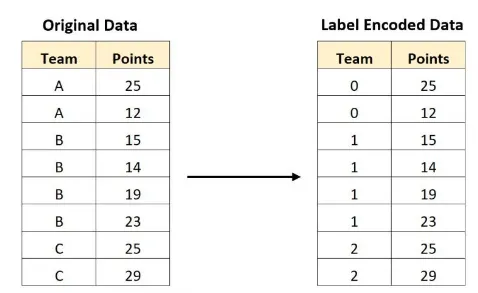
Ho codificato le colonne nel dataset, prima separando le colonne che volevo mantenere dal dataset originale e facendo una copia del dataframe (collisions_ml). Ho poi definito le colonne categoriche in una lista e utilizzato la funzione LabelEncoder() di sklearn per adattare e trasformare le colonne categoriche:
#separo le colonne in liste
ml_cols = ['posted_speed_limit','traffic_control_device', 'device_condition', 'weather_condition', 'lighting_condition', 'first_crash_type', 'trafficway_type', 'alignment', 'roadway_surface_cond', 'road_defect', 'crash_type', 'damage', 'prim_contributory_cause', 'sec_contributory_cause','street_direction', 'num_units', 'DISTRICT', 'crash_hour', 'crash_day_of_week', 'latitude', 'longitude']
cat_cols = ['traffic_control_device', 'device_condition', 'weather_condition', 'DISTRICT', 'lighting_condition', 'first_crash_type', 'trafficway_type', 'alignment', 'roadway_surface_cond', 'road_defect', 'crash_type', 'damage', 'prim_contributory_cause', 'sec_contributory_cause', 'street_direction', 'num_units']
#faccio una copia del dataset
collisions_ml = collisions[ml_cols].copy()
#codifico i valori categorici
label_encoder = LabelEncoder()
for col in collisions_ml[cat_cols].columns:
collisions_ml[col] = label_encoder.fit_transform(collisions_ml[col])Con i dati ora sufficientemente preelaborati, è possibile suddividerli in dati di addestramento e di test, e adattare un modello di classificazione ai dati.
Suddivisione dei dati di addestramento e di test
È importante separare i dati in un set di addestramento e di test durante la costruzione di un modello di apprendimento automatico; il set di addestramento è una frazione dei dati iniziali che viene utilizzata per addestrare il modello sulle risposte corrette, mentre il set di test viene utilizzato per valutare le prestazioni del modello. Mantenere questi separati è necessario per ridurre il rischio di sovradattamento e di distorsione del modello.
Ho separato la colonna crash_type utilizzando la funzione drop() (le restanti caratteristiche verranno utilizzate come variabili per prevedere crash_type) e ho definito crash_type come risultato y da prevedere utilizzando il modello. La funzione train_test_split di sklearn è stata utilizzata per prendere il 20% del dataset iniziale come dati di addestramento, il resto verrà utilizzato per il test del modello.
#Creazione del set di test
#impostazione dei valori X e y
X = collisions_ml.drop('crash_type', axis=1)
y = collisions_ml['crash_type']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Classificazione dei vicini più prossimi (K-Nearest Neighbors)
Per questo progetto, viene utilizzato un modello di classificazione dei vicini più prossimi (K-Nearest Neighbors, KNN) per prevedere i risultati dalle caratteristiche. I modelli KNN funzionano verificando il valore dei K valori conosciuti più vicini intorno a un punto di dati sconosciuto, quindi classificando il punto di dati in base ai valori di quei punti “vicini”. È un classificatore non parametrico, il che significa che non fa alcuna ipotesi sulla distribuzione sottostante dei dati; tuttavia è computazionalmente costoso e può essere sensibile agli outlier nei dati.
Ho istanziato il classificatore KNN con un numero iniziale di vicini (n_neighbors) pari a 3, utilizzando la metrica euclidea, prima di adattare il modello ai dati di addestramento:
#Classificatore - K Nearest Neighbours
#istanzio il classificatore KNN
KNNClassifier = KNeighborsClassifier(n_neighbors=3, metric='euclidean')
KNNClassifier.fit(X_train, y_train)Una volta che il modello è stato adattato ai dati di addestramento, ho effettuato le predizioni sui dati di test come segue:
#Predizioni
#predizioni sul set di addestramento
y_train_pred = KNNClassifier.predict(X_train)
#predizioni sul set di test
y_test_pred = KNNClassifier.predict(X_test)Valutazione
La valutazione di un modello di apprendimento automatico viene tipicamente effettuata utilizzando quattro metriche: accuratezza, precisione, richiamo e punteggio F1. Le differenze tra queste metriche sono molto sottili, ma in parole semplici queste terminologie possono essere definite come segue:
- Accuratezza: la percentuale di predizioni vere positive su tutte le predizioni del modello. Tipicamente l’accuratezza dei dati di addestramento e di test dovrebbe essere misurata per valutare l’adattamento del modello.
- Precisione: la percentuale di predizioni vere positive su tutte le predizioni positive del modello.
- Richiamo: la percentuale di predizioni vere positive su tutti i casi positivi nel dataset.
- Punteggio F1: Una metrica complessiva della capacità del modello di identificare istanze positive nei dati, che combina i punteggi di precisione e richiamo.
Ho calcolato le metriche del modello KNN utilizzando il frammento di codice qui di seguito – ho anche calcolato la differenza tra l’accuratezza del modello sul set di addestramento e sul set di test, per valutare l’aderenza:
#Valuta il modello# Calcola l'accuratezza del modello# Calcolo dell'accuratezza del modello sui dati di addestramentotrain_accuracy = accuracy_score(y_train, y_train_pred)# Calcolo dell'accuratezza del modello sui dati di testtest_accuracy = accuracy_score(y_test, y_test_pred)# Calcolo del punteggio f1, della precisione e del richiamof1 = f1_score(y_test, y_test_pred)precision = precision_score(y_test,y_test_pred)recall = recall_score(y_test,y_test_pred)# Confronto delle prestazioniprint("Accuratezza dell'addestramento:", train_accuracy)print("Accuratezza del test:", test_accuracy)print("Differenza di accuratezza tra addestramento e test:", train_accuracy-test_accuracy)# Stampa del punteggio di precisioneprint("Punteggio di precisione:", precision)# Stampa del punteggio di richiamoprint("Punteggio di richiamo:", recall)# Stampa del punteggio f1print("Punteggio f1:", f1)Le metriche iniziali del modello KNN sono le seguenti:

Il modello ha ottenuto buoni risultati in termini di accuratezza del test (79,6%), precisione (82,1%), richiamo (91,1%) e punteggio f1 (86,3%) – tuttavia l’accuratezza del test è stata molto più alta dell’accuratezza dell’addestramento al 93,1%, una differenza del 13,5%. Questo indica che il modello sta sovradattando i dati, il che significa che avrebbe difficoltà a fare previsioni accurate su dati non visti in precedenza. Pertanto, è necessario regolare il modello per una migliore aderenza – ciò può essere fatto utilizzando un processo chiamato sintonizzazione degli iperparametri.
Sintonizzazione degli Iperparametri
La sintonizzazione degli iperparametri è il processo di selezione del miglior set di iperparametri per un modello di apprendimento automatico. Ho raffinato il modello utilizzando la cross-validazione a k-fold – questa è una tecnica di campionamento in cui i dati vengono divisi in k sottoinsiemi (o fold), quindi ogni fold a turno viene utilizzato come set di convalida mentre i dati restanti vengono utilizzati come set di addestramento. Questo metodo è efficace nel ridurre il rischio di introduzione di un bias nel modello tramite una scelta particolare di set di addestramento/test.
Gli iperparametri per il modello KNN sono il numero di vicini (n_neighbors) e la metrica di distanza. Ci sono diverse modalità per misurare la distanza in un classificatore KNN, ma qui mi sono concentrato su due opzioni:
- Euclidea: Questa può essere considerata come la distanza in linea retta tra due punti – è la metrica di distanza più comunemente utilizzata.
- Manhattan: Chiamata anche distanza “a blocchi della città”, è la somma delle differenze assolute tra le coordinate di due punti. Se immaginate di stare all’angolo di un edificio cittadino e cercate di raggiungere l’angolo opposto, non attraversereste l’edificio per arrivare dall’altro lato, ma invece salireste di un isolato, quindi attraversereste di un isolato.
Si noti che avrei potuto anche raffinare il parametro di peso (che determina se tutti i vicini votano allo stesso modo o se ai vicini più vicini viene data maggiore importanza), ma ho deciso di mantenere il peso uniforme.
Ho definito una griglia dei parametri con n_neighbors pari a 3, 7 e 10, così come le metriche euclidean o manhattan. Ho quindi istanziato un algoritmo RandomizedSearchCV, passando il classificatore KNN come stimatore, insieme alla griglia dei parametri. Ho impostato l’algoritmo per dividere i dati in 5 fold impostando il parametro cv su 5; questo è stato quindi adattato al set di addestramento. Un frammento del codice per questo può essere visto di seguito:
#Raffinamento (RandomizedSearchCV)# Definisci la griglia dei parametriparam_grid = { 'n_neighbors': [3, 7, 10], 'metric': ['euclidean','manhattan']}# istanzia RandomizedSearchCVrandom_search = RandomizedSearchCV(estimator=KNeighborsClassifier(), param_distributions=param_grid, cv=5)# adatta i dati di addestramentorandom_search.fit(X_train, y_train)# Recupera il miglior modello e le prestazionibest_classifier = random_search.best_estimator_best_accuracy = random_search.best_score_print("Migliore accuratezza:", best_accuracy)print("Miglior modello:", best_classifier)L’accuratezza e il classificatore migliori sono stati recuperati dall’algoritmo, indicando che il classificatore ottiene i migliori risultati con n_neighbors impostato a 10 utilizzando la metrica di distanza Manhattan, e che ciò porterebbe a un punteggio di accuratezza del 74,0%:

Di conseguenza, questi parametri sono stati inseriti nel classificatore e il modello è stato riaddestrato:
#Classificatore - K Nearest Neighbours#istanzia il classificatore KNNKNNClassifier = KNeighborsClassifier(n_neighbors=10, metric = 'manhattan')KNNClassifier.fit(X_train,y_train)Le metriche di performance sono state estratte nuovamente dal classificatore, nello stesso modo di prima: uno screenshot delle metriche per questa iterazione può essere visto di seguito:
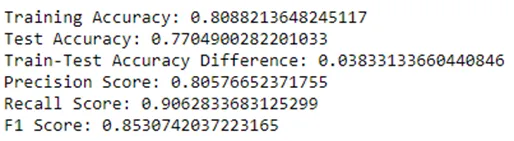
La cross-validation ha portato a risultati leggermente inferiori per tutte le metriche: l’accuratezza del test è diminuita del 2,6%, la precisione dell’1,5%, il recall dello 0,5% e l’F1 score dell’1%. Tuttavia, la differenza tra l’accuratezza del training e del test è diminuita al 3,8%, rispetto al valore iniziale del 13,5%. Questo indica che il modello non è più sovradattato ai dati ed è quindi più adatto per prevedere dati non visti in precedenza.
Conclusioni
In sintesi, il classificatore KNN ha ottenuto buoni risultati nella previsione se una collisione richiede un carro attrezzi o un’ambulanza. Le metriche iniziali della prima iterazione del modello erano impressionanti, tuttavia la discrepanza tra l’accuratezza del test e del training indicava il sovradattamento. La taratura degli iperparametri ha permesso di ottimizzare il modello, riducendo significativamente la differenza di accuratezza tra i due set di dati. Sebbene le metriche di performance abbiano subito un piccolo calo durante questo processo, il vantaggio di un modello con una migliore adattabilità supera tali preoccupazioni.
Riferimenti
- Levy, J. (s.d.). Traffic Crashes — Crashes [Dataset]. Estratto da Chicago Data Portal. Disponibile su: https://data.cityofchicago.org/Transportation/Traffic-Crashes-Crashes/85ca-t3if (Accesso: 14 maggio 2023).
- Chicago Police Department. (s.d.). Boundaries — Police Beats (current) [Data set]. Estratto da Chicago Data Portal. Disponibile su: https://data.cityofchicago.org/Public-Safety/Boundaries-Police-Beats-current-/aerh-rz74 (Accesso: 14 maggio 2023).
- Zach M. (2022). “Come eseguire l’encoding delle etichette in Python (con esempio).” [Online]. Disponibile su: https://www.statology.org/label-encoding-in-python/ (Accesso: 19 luglio 2023).





