Auto-attenzione nei trasformatori
Auto-attenzione nei trasformatori' (Self-attention in transformers)
Una guida per principianti al meccanismo di auto-attenzione

Sei incuriosito dalle recenti tecnologie come ChatGPT di OpenAI, DALL-E, Stable Diffusion, Midjourney e altro ancora?
“Transformer”, uno dei principali motori dietro tutti i progressi attuali nel campo dell’IA. Solo pochi anni fa, l’IA veniva percepita come fantascienza, ma nel 2022, tecnologie come ChatGPT e DALL-E hanno iniziato a diventare parte integrante della vita delle persone. E tutto il merito va all’innovativo paper del 2017 intitolato “Attention Is All You Need” [1] di Google e dell’Università di Toronto, che ha introdotto il Transformer – un’architettura di rete neurale profonda che si basa pesantemente sul meccanismo di attenzione. Pertanto, comprendere l’attenzione e le sue fondamenta matematiche apre molte porte di opportunità per un ingegnere o un ricercatore di intelligenza artificiale.
Esplorando il significato di “Attenzione”
Iniziamo con il significato letterale del termine “Attenzione”. Secondo Wikipedia,
“È un processo di concentrazione selettiva su un aspetto specifico delle informazioni”.
Immagina di avere una conversazione con un amico, in cui presti attenzione solo a determinate parole mentre i tuoi timpani le ricevono tutte. Dai maggiore importanza ad alcune parole e ignori il resto. E questo processo viene svolto dalla tua mente subconscia senza che tu lo sappia. È una sofisticata capacità cognitiva intrinseca a noi esseri umani.
L’attenzione nell’apprendimento automatico è la stessa di questa attenzione, ad eccezione dell’intervento della matematica. È come abilitare i modelli di intelligenza artificiale a concentrarsi sulle informazioni rilevanti e importanti e ignorare le informazioni meno rilevanti/importanti, il che aiuta a comprendere il contesto dell’input.
Comprensione contestuale
Considera le seguenti frasi,
Frase 1: “Sono andato in banca per depositare soldi”.
Frase 2: “La sponda del fiume era secca e fangosa”.
Osserviamo la parola “banca”. Il significato di questa parola è diverso in entrambe le frasi. Dedica un po’ di tempo a indovinare il significato tu stesso. Per la prima, probabilmente hai indovinato che si tratta di una sorta di istituzione finanziaria, e per la seconda, hai indovinato che si tratta del terreno che costeggia un corso d’acqua, se non sbaglio. Ricorda, ho già detto in precedenza che gli esseri umani sono dotati di doni, e dovremmo essere orgogliosi di essi.
Analizziamo come potresti aver ottenuto il risultato corretto in modo subconscio. La tua mente ha osservato altre parole vicine nella frase e ha cercato di capire il contesto della frase. Nella prima, hai osservato parole come ‘deposito’ e ‘soldi’. Nella seconda, ci sono parole come ‘fiume’, ‘secca’ e ‘fangosa’. Quindi possiamo ipotizzare che le parole vicine abbiano aiutato il tuo cervello a capire il contesto della parola ‘banca’ e, una volta chiaro il contesto, l’hai indovinato correttamente.
Una cosa molto importante che questo esperimento ha chiarito è che il significato di ogni parola in una frase dipende dal contesto, che, a sua volta, dipende da altre parole. Pertanto, è molto importante aggiungere informazioni contestuali alla frase mentre il modello di apprendimento automatico elabora l’input.
Auto-attenzione
Confrontare ogni parola nella frase con la parola ‘banca’ può darci le informazioni contestuali sulla parola ‘banca’. Ma le cose non sono sempre così semplici. Per comprendere le informazioni contestuali generali da una frase, dobbiamo considerare tutte le parole in una frase e non solo una singola parola ‘banca’.
Le informazioni contestuali di una intera frase dipendono dalle informazioni contestuali di tutte le parole. Voglio dire, per ogni parola in una frase, dovremmo cercare di determinare le sue informazioni contestuali utilizzando tutte le parole presenti nella frase. Questo è esattamente ciò che faremo, ma utilizzando la matematica. Volemo imitare il processo di pensiero umano per modellare la nostra attenzione. Ciò permetterà al nostro modello di apprendere e comprendere facilmente frasi complesse. Dobbiamo costruire una sorta di meccanismo che faccia ciò per noi, e aha! chiameremo questa auto-attenzione.
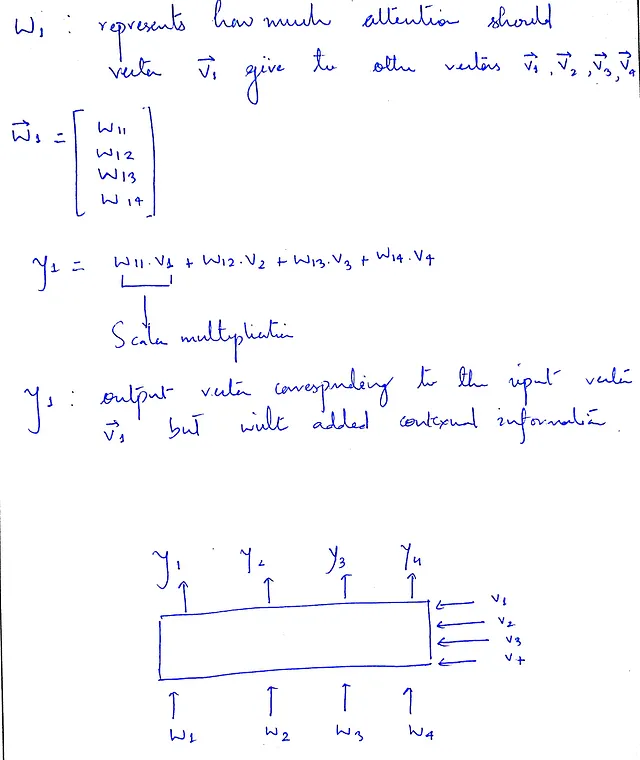
L’auto-attenzione prende in input vettori che rappresentano ciascuna parola/token. Modifica ciascun vettore di input per incorporare informazioni contestuali e produce in output vettori della stessa dimensione dell’input.
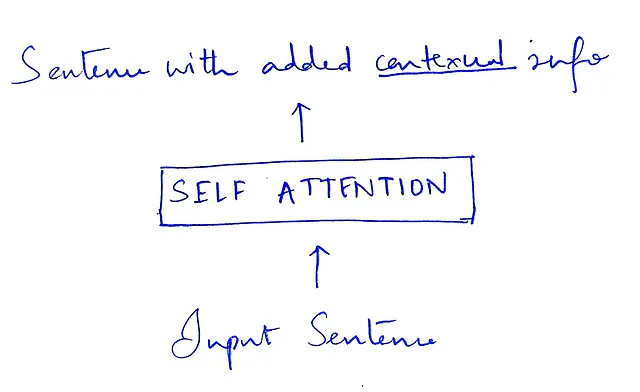
Diamo un’occhiata più da vicino al blocco di auto-attenzione e al suo funzionamento interno.
L’auto-attenzione esamina ogni parola in una frase e calcola quanto importanza dovrebbe attribuire a tutte le altre parole.
Nel nostro esempio, la parola “banca” attribuisce più attenzione/importanza a “denaro” e “deposito” rispetto alle altre parole. O forse possiamo dire che sono più correlate.
Tuttavia, la sfida sta nel determinare la quantità di importanza/attenzione/focus tra due parole o la quantità di correlazione tra esse. La soluzione si trova nel nostro stesso esempio. Prendiamo la parola ‘banca’; per questa, l’attenzione su ‘denaro’ e ‘deposito’ è maggiore rispetto alle altre parole. Spero che tu possa anche osservare che queste parole sono le più simili a ‘banca’ rispetto alle altre parole. Possiamo utilizzare il punteggio di similarità come proxy per attenzione/focus/importanza. Sì, questo è ciò che gli autori del paper “Attention is all you need” hanno implementato.

Ma come calcoliamo la similarità tra due parole?
Per noi umani, le parole sono ovunque, ma il modello non ha alcuna comprensione delle parole. L’unica cosa su cui opera è il vettore/Matrice/Tensore.
Quindi prima di alimentare la nostra frase nel blocco di auto-attenzione, viene prima convertita in un vettore di embedding. La dimensione del vettore è sempre fissa. Dopo il vettore di embedding, viene anche aggiunta l’informazione di posizione di ogni parola perché la posizione è importante e può cambiare il significato della parola/frase. Quindi questo serve a far sì che il modello tenga traccia della posizione di ogni vettore/parola. Tutti questi concetti esulano dallo scopo di questo articolo. Ci concentreremo esclusivamente sull’auto-attenzione. In poche parole, le parole testuali effettive non vengono alimentate nel blocco di attenzione; invece, viene alimentata una rappresentazione vettoriale di ogni parola/token.
Ora le cose sono un po’ più semplici perché stiamo ottenendo vettori invece di parole, e il nostro obiettivo, per ora, è calcolare la similarità tra due vettori.
Ricordiamo l’algebra lineare delle scuole superiori. Ci sono due misure che possiamo utilizzare durante il calcolo della similarità tra due vettori.
i. Prodotto scalare
ii. Similarità coseno
Tuttavia, il prodotto scalare è molto più veloce da calcolare ed è ottimizzato nello spazio, quindi ci atteniamo al prodotto scalare. Ma sentiti libero di sperimentare anche con la similarità coseno.
Prodotto scalare
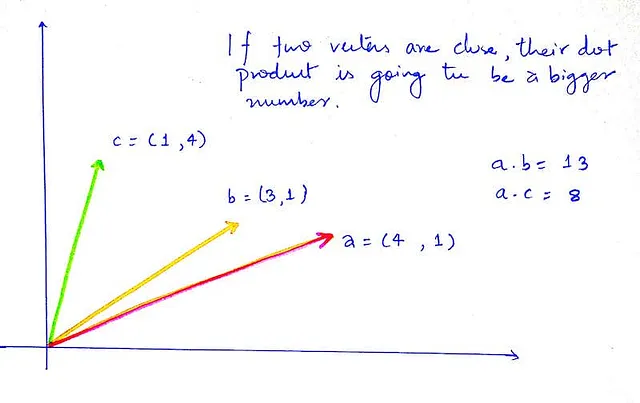

E per il punteggio di similarità, vogliamo un numero, uno scalare. Per fortuna, il prodotto scalare ci fornisce sempre risultati scalari.
Prendiamo una frase più semplice, “Ciao gioco a giochi”. E vediamo come vengono calcolati i punteggi di similarità.
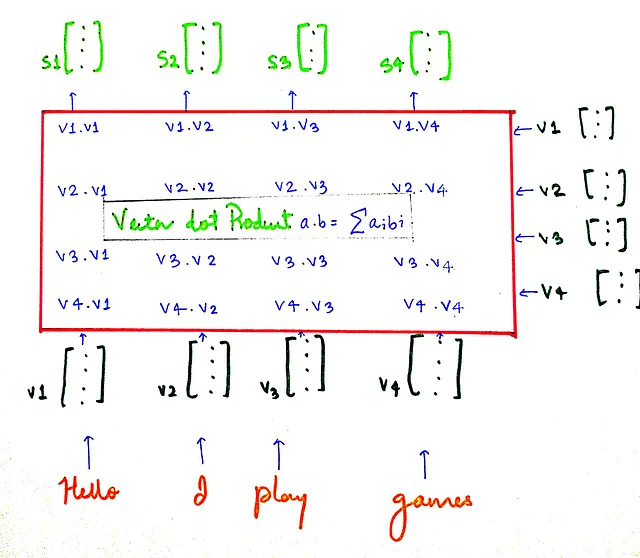
I vettori s sono i vettori che contengono i punteggi di similarità.
sᵢ contiene i punteggi di similarità per il vettore vᵢ con tutti gli altri vettori. Ad esempio, s₁ contiene i punteggi di similarità per il vettore v₁ con tutti gli altri vettori (v₁ rappresenta la parola “Ciao” nel nostro esempio). Ora che abbiamo i punteggi di similarità, facciamo un po’ di normalizzazione, in particolare Scaling e Softmax.
Ridimensionamento del prodotto scalare
Senza ridimensionamento, la magnitudine maggiore del prodotto scalare dominerebbe e oscurerebbe gli altri. Vogliamo che la distribuzione dell’attenzione/importanza sia più equilibrata e dia importanza a più vettori anziché solo al vettore più simile.
Quindi dividiamo il risultato (punteggi di similarità) per un valore costante che è √dₖ

Normalizzazione usando Softmax
Di solito, nell’apprendimento profondo, anziché numeri grandi, normalizziamo usando LayerNorm/BatchNorm in modo da ottenere valori più piccoli che aiutano a una convergenza più rapida. La stessa cosa la facciamo qui perché vogliamo che il valore dei punteggi di attenzione/similarità sia inferiore a 1. E per ogni parola, il punteggio di attenzione con tutte le altre parole dovrebbe sommare a 1. Questo è ciò che fa la funzione softmax. La funzione softmax trasforma i punteggi o logit ottenuti dal prodotto scalare in una distribuzione di probabilità.
Quando i punteggi di attenzione di una parola per tutte le altre parole sommano a 1, diventa anche interpretabile per gli esseri umani.
La funzione softmax prende un vettore di k valori reali e li trasforma in un vettore di k valori reali che sommano a 1.
Indipendentemente dai valori di input, l’output è sempre un numero reale compreso tra 0 e 1, e la somma è sempre 1, quindi può anche essere interpretato come un peso su 1.
Il risultato di softmax è che otterremo punteggi tra 0 e 1. Questo è chiamato punteggio di attenzione. Rappresenta quanto peso di attenzione dovrebbe dare un vettore/parola ad altre parole su 1. (per favore, non confonderti con il termine peso, non è da trattare come parametro del modello)
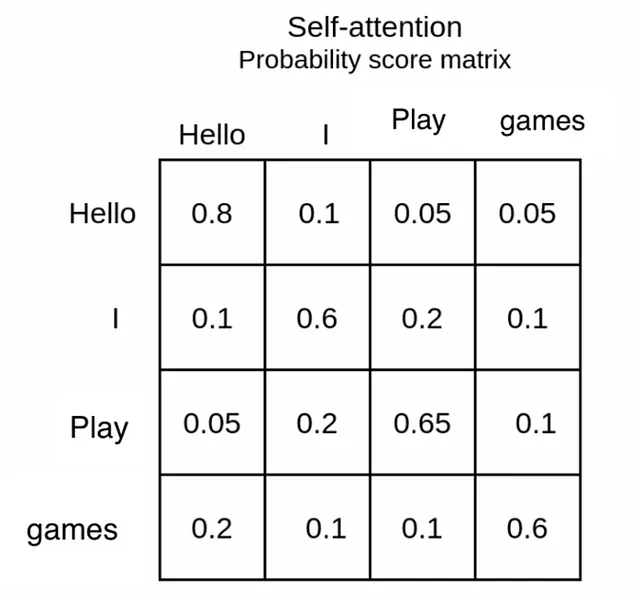
Ad esempio, prendiamo la parola ‘Io’. Si concentra di più su se stessa, cosa che ignoreremo (ogni parola si concentra di più su se stessa a causa della similarità), e dopo di ciò, dà importanza alla parola ‘Gioca’. Possiamo supporre che ciò sia dovuto al fatto che la parola ‘Io’ è una risposta alla domanda ‘Chi gioca a un gioco?’. Questo è il risultato di softmax. Questi sono i pesi.
Ricorda ciò che ti ho detto all’inizio dell’autoattenzione, ‘estrai le informazioni contestuali’ e ‘iniettale nella frase di input’. Possiamo pensare che tutto ciò che abbiamo fatto sia estrarre le informazioni contestuali. Ora passiamo all’iniezione di queste informazioni.
Iniezione delle informazioni contestuali
La funzione Softmax ci ha fornito una matrice di attenzione contenente pesi e ora che sappiamo quanto attenzione ogni parola dovrebbe dare alle altre parole, perché non evidenziare le parole importanti e sopprimere quelle meno importanti?
Ecco cosa faremo. Per ogni vettore vᵢ, moltiplicheremo i suoi pesi di attenzione che sono conservati in wᵢ con V (è una matrice formata da tutti i vettori di input), che contiene tutti i vettori di input originali. In questo modo, le caratteristiche/parole importanti saranno evidenziate e il loro impatto sarà maggiore, mentre le parole meno importanti saranno sopresse, il che significa che il loro impatto sull’output non sarà così grande.
Inoltre, è importante capire perché un vettore dovrebbe dare maggiore attenzione a se stesso quando si considera il meccanismo di attenzione. La ragione di ciò risiede nel desiderio di preservare le informazioni originali del vettore.
Anche se l’incorporazione delle informazioni contestuali è cruciale, non dobbiamo trascurare l’importanza del mantenimento delle informazioni originali di un vettore.
L’equazione per y₁ può fornire ulteriori chiarimenti su questo punto.
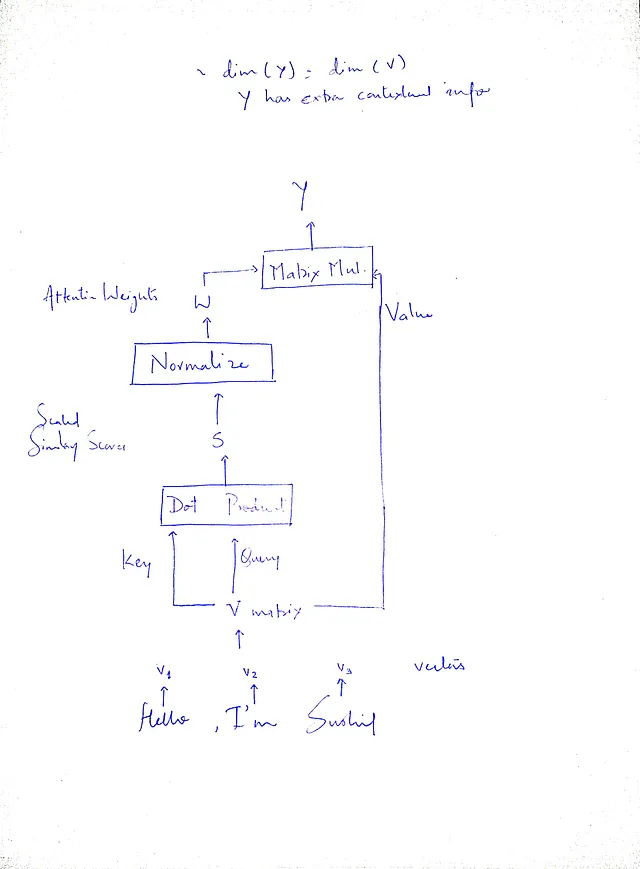
Concetto di Query, Chiave e Valore
Ta-da, abbiamo modificato con successo i vettori originali per incorporare informazioni contestuali. Ma sembra tutto disordinato, vero? Rendiamolo chiaro e conciso. Invece di operare su vettori, gli algoritmi di deep learning di solito operano su tensori/matrici. E notate che stiamo usando la matrice di input (V) 3 volte, diamo a ciascuna un nome in modo che sia facile per noi. La prima volta che facciamo un prodotto scalare, usiamo questa matrice V due volte. Mettiamola in questo modo, poniamoci una domanda, cosa abbiamo effettivamente fatto nel passaggio del prodotto scalare?
La risposta ci darà un nome adatto. Per ogni vettore vᵢ, abbiamo chiesto quanto siano simili tutti gli altri vettori (v₁, v₂, v₃, v₄). Quindi perché non dare il nome ‘Query’ alla matrice V (composta da vettori v) per la quale stiamo chiedendo il punteggio di similarità?
Dall’esempio precedente di due frasi, nel determinare il contesto per la parola ‘bank’, può essere considerato come una parola di query (che è la stessa di un vettore di query e la concatenazione di vettori di query per tutte le parole può essere considerata come una Matrice di Query). E altre parole come ‘deposits’, ‘money’, ecc. possono essere considerate come parole chiave (che compongono la Matrice Chiave).
E perché non dare il nome ‘Chiave’ alla matrice V che stiamo usando per calcolare la similarità tramite il prodotto scalare con la Query?
La migliore analogia sarebbe cercare un video su YouTube. Digiti la tua query nella casella di ricerca e il backend di YouTube cerca di abbinare la tua query con il titolo di tutti i video memorizzati nel database di YouTube. Il video più simile/compatibile verrà mostrato per primo. Questo è esattamente quello che abbiamo fatto nel passaggio del prodotto scalare. Abbiamo chiesto quanto è simile la matrice di Query alla matrice di Chiavi, che ci ha dato la matrice dei punteggi di similarità. Sia la matrice Query che la matrice Chiave sono le stesse, cioè uguali, perché entrambe sono la rappresentazione matriciale dei vettori di input.
La terza volta in cui abbiamo utilizzato la matrice V è durante l’iniezione delle informazioni contestuali nella matrice di input. Abbiamo estratto con successo le informazioni contestuali e avevamo bisogno di evidenziare le informazioni importanti e sopprimere le informazioni meno rilevanti. Dovremmo chiamarla una Matrice Valore. Questo passaggio può essere implementato utilizzando la moltiplicazione di matrici quando le operazioni sono in forma matriciale.
La moltiplicazione di matrici è la stessa di uno strato lineare senza funzione di attivazione e bias – quindi non dovrebbe essere un grosso problema durante l’implementazione.
Vale la pena notare che le matrici Q, K e V sono essenzialmente identiche e uguali in valore. L’unico motivo per cui assegniamo loro nomi diversi è per indicare i loro ruoli e scopi specifici all’interno del meccanismo di attenzione. Fornendo etichette distinte in base al loro utilizzo, possiamo comunicare efficacemente le loro funzioni previste mantenendo la loro uguaglianza. I passaggi chiari e concisi del nostro processo sono:
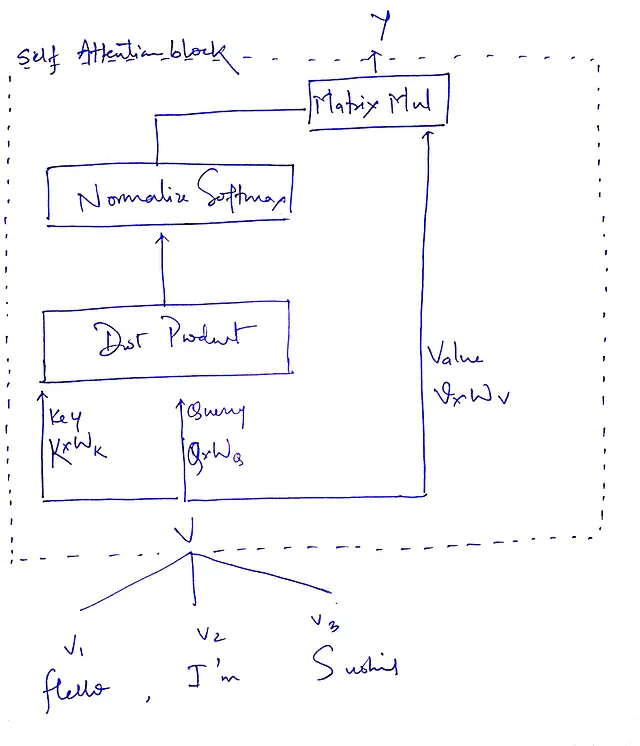
Ma c’è ancora una cosa che manca, hai indovinato cosa?
Dove sono tutti i parametri apprendibili ??
Notate che non ci sono parametri apprendibili che possono essere ottimizzati durante la retropropagazione. Senza questo, tutto il nostro sistema sarebbe inutile, dubito fortemente che si possa chiamare questo un modello di apprendimento automatico senza pesi apprendibili.
Quindi sorge la domanda: dove dovremmo aggiungere il parametro apprendibile?
Notate che tutto ciò che stiamo facendo sono calcoli basati sui vettori di input Query(Q), Chiave(K) e Valore(V). Perché non moltiplicare queste matrici prima di usarle così avremo i nostri parametri apprendibili e la dimensione di Q, K e V rimarrà la stessa (come? la moltiplicazione di matrici può mantenere la dimensione intatta se moltiplicata con una matrice di forma adatta)?
Sembra che abbiamo trovato la soluzione; è così che anche il paper l’ha implementato. Ora siamo pronti. Chiameremo le matrici, Pesi di Query (Wᵩ), Pesi di Chiave (Wₖ) e Pesi di Valore (Wᵥ).

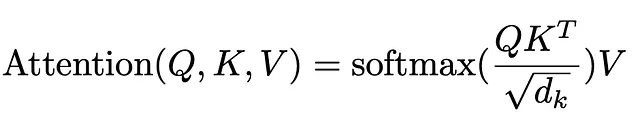
Questa formula riassume l’intero nostro processo. Prima il prodotto scalare tra Q e K (trasposta – capirai perché trasporre quando cercherai di approfondire/implementare, questo viene lasciato come compito). E la riduzione di scala è seguita dall’applicazione della funzione softmax per ottenere i pesi di attenzione e infine moltiplicare per il vettore di input originale per pesare in base ai pesi ricevuti da softmax.
Ecco fatto!
Il Transformer è senza dubbio uno dei più notevoli progressi nella ricerca dal backpropagation nel campo dell’IA. Ogni settimana vengono introdotti numerosi modelli all’avanguardia, che contribuiscono ulteriormente all’eccitazione e all’innovazione nel campo. Consiglio vivamente di leggere questo articolo[2] e guardare questo video[3] su Youtube. Queste risorse possono fornire preziosi approfondimenti e prospettive, aiutandoti a comprendere le complessità e l’importanza di questa architettura rivoluzionaria.
Non dimenticare di mettere le mani in pasta. Rimani curioso e seguimi per altri contenuti simili a questo.
Riferimenti
[1] Vaswani, Ashish & Shazeer, Noam & Parmar, Niki & Uszkoreit, Jakob & Jones, Llion & Gomez, Aidan & Kaiser, Lukasz & Polosukhin, Illia, “Attention is all you need”, 2017.
[2] Micheal Phi, “Guida illustrata ai transformers – Spiegazione passo passo”, post del blog, 2020.
[3] Ark, “Intuizione sul meccanismo di auto-attenzione nelle reti di trasformatori”, 2021, Youtube.






