NLP moderna Una panoramica dettagliata. Parte 1 Transformers
Modern NLP A detailed overview. Part 1 Transformers

Nell’ultimo mezzo decennio, abbiamo assistito a enormi progressi nel campo del Natural Language Processing con l’introduzione di idee come BERT e GPT. In questo articolo, ci proponiamo di approfondire i dettagli del miglioramento in modo graduale e vedere l’evoluzione che hanno portato.
L’attenzione è tutto ciò di cui hai bisogno
Nel 2017, Ashish Vaswani, di Google Brains, insieme a colleghi dell’Università di Toronto, ha presentato un’idea per compiti di sequenza in sequenza come la traduzione linguistica neurale e la parafrasi, diversa dall’approccio esistente di una parola alla volta seguito da LSTMs e RNNs.
Il problema con l’architettura attuale delle RNNs che è stato rilevato era:
- Incontra DERA Un framework AI per migliorare il completamento dei modelli di lingua con agenti risolutivi abilitati per il dialogo
- Il team di hacker etici di Google rendere l’IA più sicura
- Utilizzare un Keras Tuner per l’ottimizzazione degli iperparametri di un modello TensorFlow
- Aggiungendo una parola alla volta, nel caso di sequenze lunghe, era difficile mantenere le informazioni. Nei modelli strutturati encoder-decoder che utilizzano RNN e LSTM, i vettori nascosti venivano passati da un time-stamp all’altro. Quindi, nell’ultimo passaggio, passiamo il vettore di contesto finale al decoder. Il vettore di contesto nascosto passato al decoder ha una maggiore influenza sulle ultime parole rispetto alle prime parole della sequenza, poiché le informazioni si affievoliscono nel tempo.
- Per rimuovere il problema menzionato nel primo punto, è stata introdotta una meccanica di attenzione. Ciò suggeriva che durante la decodifica, prestiamo attenzione separata alle parole nella sequenza di input. Ogni parola nella sequenza di input ottiene un vettore di peso di attenzione specifico, che viene quindi moltiplicato per il vettore di parola per creare una somma pesata di vettori. Ma il problema era che, facendo questo passo per passo, ci voleva troppo tempo per i calcoli e non eliminava completamente la perdita di informazioni.
L’idea
I Transformers hanno suggerito l’uso di un concetto chiamato self-attention. Il modello prende l’intera frase in un solo momento e quindi utilizza l’auto-attenzione per decidere quanto sono importanti le altre parole nella frase nel contesto della parola corrente. Quindi, rispetto all’architettura ricorrente attuale, ha alcuni vantaggi:
- Nel rilevare i pesi, abbiamo già tutte le parole, quindi non c’è possibilità di perdita di informazioni e otteniamo anche il contesto da entrambi i lati. Cioè, conosciamo sia le parole precedenti alla parola selezionata che le parole che la seguono, il che aiuta a formare un contesto migliore, rispetto alla struttura ricorrente (ad eccezione del caso di Bi-LSTM).
- Dato che abbiamo a disposizione l’intera frase e abbiamo anche bisogno di trovare l’importanza di tutte le altre parole per ogni parola nella frase, possiamo farlo in parallelo per tutte le parole. Ciò risparmia molto tempo di elaborazione e porta a una piena utilizzazione della potenza di elaborazione.
Self-Attention: Il Blocco di Costruzione
Il meccanismo di auto-attenzione cerca di trovare quanto sono importanti altre parole rispetto a una particolare parola, quindi crea un vettore di contesto combinato per rappresentare quella parola. Fondamentalmente, significa che se scegli una parola nella frase, quanto quella è correlata alle altre parole nella frase? Come tutti sappiamo, le parole definiscono il contesto della frase e il significato di una parola dipende spesso da quel contesto. Questo è un modo per scoprire il contesto della frase e le parole correlate.
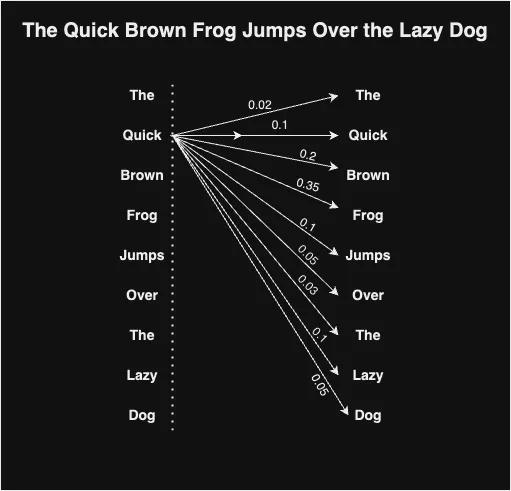
Per ottenere questo, vengono utilizzati tre vettori, ovvero Query (Qi), Key (Ki) e Value (Vi), per ogni embedding di parola di input (xi) nella frase. La lunghezza del vettore di embedding x è suggerita essere 512, secondo l’articolo. Per ottenere questi vettori, vengono prima definiti tre matrici di peso: Wq, Wv e Wk. Moltiplichiamo ciascun vettore di parola di input Xi con la matrice di peso corrispondente per ottenere i vettori di chiave, query e valore risultanti per la parola data.
Qi = Xi * Wq
Vi = Xi * Wv
Ki = Xi * Wk
Per determinare l’importanza di una parola xi nel contesto della parola xj, è necessario calcolare il prodotto scalare tra il vettore chiave Ki corrispondente alla parola xi e il vettore di interrogazione Qj per la parola xj. Il risultato del prodotto scalare viene quindi diviso per la radice quadrata della dimensione del vettore Ki, che è 8 in quanto la dimensione di k è 64 come indicato nel paper. Come suggerito nel paper, se non dividiamo, il valore del prodotto scalare diventa troppo grande, il che porta a valori softmax troppo ripidi e quindi a gradienti sbagliati per un apprendimento fluido.
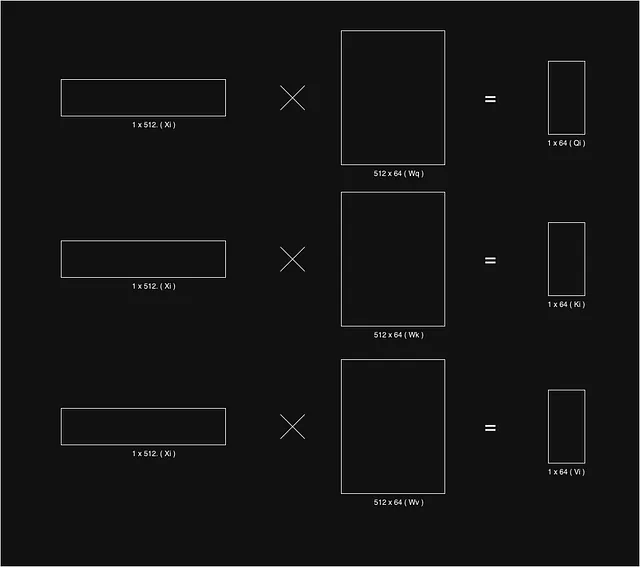
Una volta determinata l’importanza di tutte le parole per una parola data, applichiamo la funzione softmax sui risultati di tutte le parole. La funzione softmax fornisce l’importanza finale di tutte le singole parole in modo che la loro somma sia pari a 1. Successivamente, vengono considerati i vettori Vi per le parole, moltiplichiamo i vettori Vi per la loro importanza corrispondente. L’intuizione è che i vettori di valore creino la rappresentazione delle parole, mentre i fattori di importanza conferiscono peso al contesto della parola oggetto. Se una parola non ha relazione con la parola di contesto, il suo valore di importanza sarà molto basso e quindi il vettore prodotto finale sarà molto basso e possiamo trascurare la sua importanza per il compito. Infine, sommiamo tutti questi vettori di valori pesati per creare il vettore di contesto finale per quella particolare parola, che otteniamo dal blocco di attenzione.

Attenzione multipla
Abbiamo visto come funziona l’attenzione e produce vettori di contesto per ogni parola. Gli autori del paper hanno utilizzato l’attenzione multipla per ottenere un vettore di contesto composito imparziale. Hanno utilizzato 8 di queste attenzioni, che forniscono 8 diversi vettori di contesto per una parola. L’idea è che, poiché ciascuna delle matrici di pesi interne, ossia Wq, Wv e Wk, viene inizializzata casualmente, la variazione dei punti di inizializzazione in ciascuna attenzione può aiutare a catturare una serie di diverse caratteristiche nei vettori di contesto.
Infine, per ogni parola, abbiamo 8 vettori di contesto che concateniamo insieme per ottenere il vettore di contesto rappresentativo per una data parola.
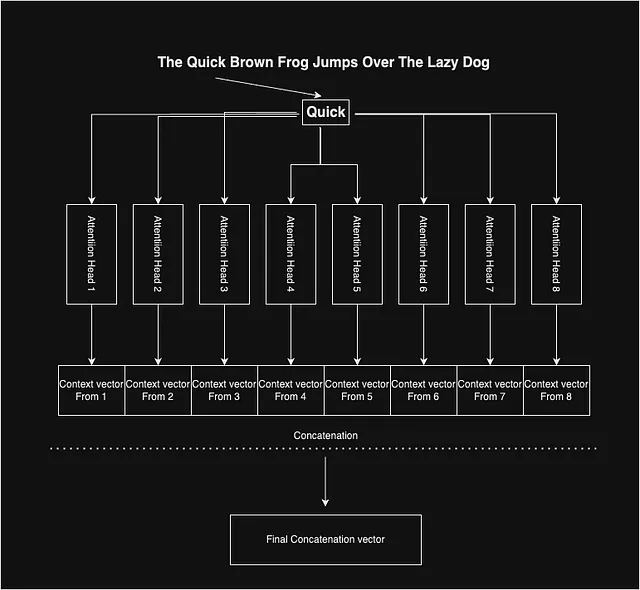
Blocco di auto-attenzione: mettendo tutto insieme
Tutto ciò di cui abbiamo discusso finora si basa su una particolare parola nella frase, ma dobbiamo considerare tutte le parole nella frase e rendere il sistema parallelo.
Il paper suggerisce di utilizzare embedding di lunghezza 512 per rappresentare ogni parola nella frase. Ora, sappiamo già che, per le attività di NLP, di solito è necessario utilizzare il zero-padding per uniformare la lunghezza delle frasi. Successivamente, sovrapponiamo tutti i vettori di parole di dimensione 512 l’uno sull’altro e poiché c’è un numero fisso di parole in una frase, otteniamo un vettore bidimensionale di dimensione fissa per rappresentare l’intera frase, che viene inviato attraverso l’intero meccanismo di attenzione.
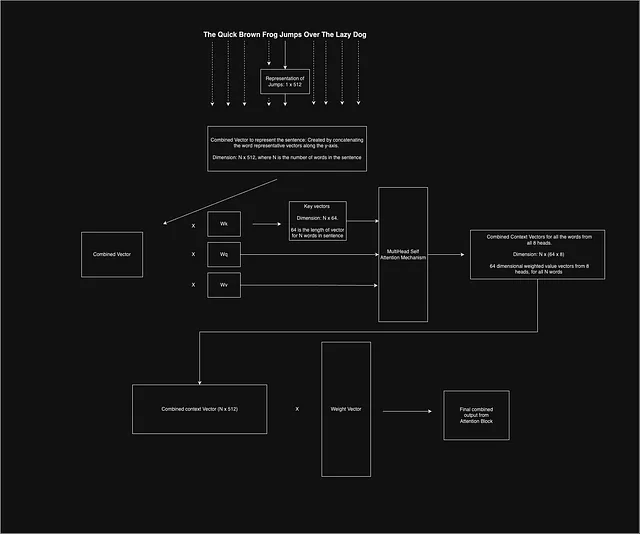
Una volta ottenuto il vettore di contesto combinato per tutte le parole, viene moltiplicato per un’altra matrice di pesi, che concentra l’apprendimento e riduce la dimensione del vettore.
Transformer: L’architettura
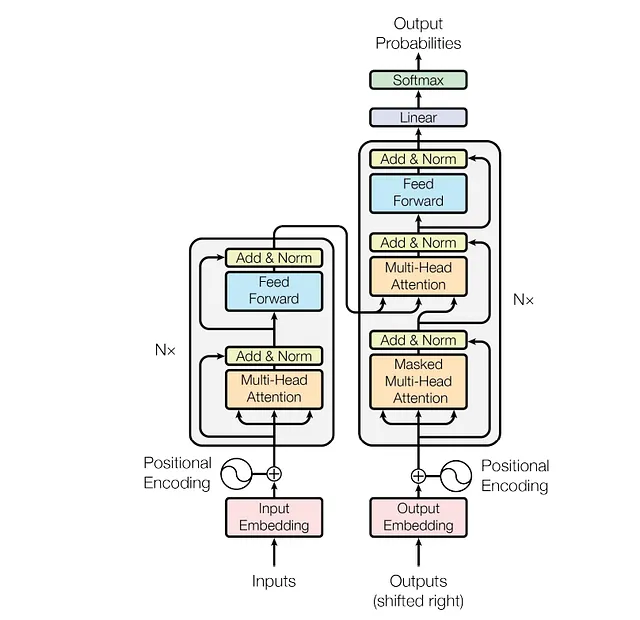
Il Transformer segue anche un’architettura standard Encoder-Decoder. Per facilitare e migliorare l’apprendimento, la dimensione dei vettori di parole e delle uscite dei livelli è mantenuta a 512. L’apprendimento del modello avviene in modo auto-regressivo, cioè le parole vengono generate una per volta, e per la previsione della parola (t+1), si attacca l’output della parola t-esima all’input e lo si alimenta al modello.
Encoder: Gli autori hanno utilizzato moduli con 2 sottolivelli. Il primo livello contiene un’attenzione multihead, di cui abbiamo discusso in precedenza, e il secondo sottolivello è un livello di alimentazione completamente connesso. Il livello di alimentazione completamente connesso è costituito da 2 livelli di rete neurale normale connessi. L’input e l’output dei livelli di alimentazione completamente connessi sono di dimensione 512, ma la dimensionalità interna è di 2048, cioè il numero di nodi nel livello interno è 2048. Il livello completamente connesso utilizza l’attivazione ReLU. Gli autori hanno anche utilizzato un livello di addizione e normalizzazione per rendere più fluido l’apprendimento e evitare perdite di informazioni come abbiamo visto in vari casi di NLP e visione artificiale.
Quindi, l’equazione diventa
Output = Norm( x + f(x)), dove x è l’input e f() è la trasformazione del livello, che può essere un livello di alimentazione completamente connesso o un blocco di attenzione.
Ci sono 6 moduli di questo tipo nel blocco di codifica.
Decoder: Questo è molto simile al blocco di codifica. Anche questo ha 6 moduli e un’architettura simile. L’unica differenza è che, oltre ai 2 sottolivelli già presenti, il blocco del decoder introduce un terzo sottolivello, che è anche un livello di attenzione, ma gli input sono mascherati in modo che il modello non possa utilizzare la parola del tempo (t+1) come input durante la previsione della parola t-esima. Il sottolivello di attenzione multihead, senza la maschera, prende il valore dal codificatore del livello corrispondente. Quindi, il livello prende in input dal precedente livello del decoder e dal livello corrispondente del codificatore.
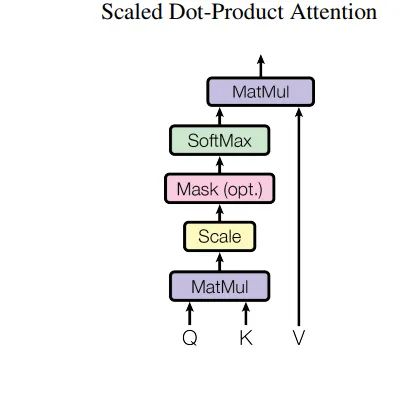
Il livello di attenzione è stato utilizzato dal modello in 3 modi diversi, secondo gli autori, durante l’addestramento. Come già sappiamo, inseriamo tre vettori per tutte le parole, Key, Query e Value, nei blocchi di attenzione, gli autori hanno utilizzato questo per addestrare meglio il modello.
Opzione 1: In questo caso, le query provengono dal precedente livello del decoder e le chiavi e i valori di memoria provengono dall’output del codificatore. Ciò consente a ogni posizione nel decoder di prestare attenzione a tutte le posizioni nella sequenza di input.

Opzione 2: In questo caso, i valori e le query provengono dall’output del livello precedente nel codificatore. Ogni posizione nel codificatore può prestare attenzione a tutte le posizioni nel livello precedente del codificatore.
Opzione 3: In questo caso, i valori e le query provengono dall’output del livello precedente nel decoder. Ogni posizione nel decoder può prestare attenzione a tutte le posizioni nel livello precedente del decoder. Ora, questo porta all’importanza dell’attenzione multihead mascherata, poiché il modello non può vedere le parole a t+1, la proprietà auto-regressiva è preservata.
Infine, gli autori hanno utilizzato un livello di trasformazione lineare seguito da un livello softmax.
Codifica Posizionale
Oltre al modello, questo articolo ha introdotto anche il concetto di codifica posizionale. Il problema era, dato che questo articolo non utilizza reti ricorrenti o convoluzionali e non è basato sul passaggio del tempo, gli autori hanno ritenuto che ci dovrebbe essere qualcosa per indicare la posizione delle parole, poiché questa svolge un ruolo importante nell’esprimere il significato della frase.
Per risolvere questo problema, gli autori hanno introdotto due stime.
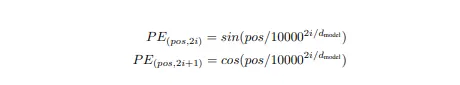
dove pos è la posizione della parola, i è la dimensione e dmodel = 512, la dimensione dell’input. Le dimensioni delle codifiche sono anche mantenute a dimensione 512, in modo che possano essere aggiunte facilmente agli embedding delle parole. Gli autori hanno selezionato queste funzioni specifiche perché danno multipli dello stesso valore dopo un certo offset, quindi possono essere rappresentate come funzioni lineari.
Conclusione
Abbiamo imparato come funzionano i transformers; successivamente, impareremo anche su altre evoluzioni oltre alle loro implementazioni.
Fino ad allora, Buona Lettura!!!!





