Incontra Automated Reasoning And Tool-Use (ART) un framework che utilizza i modelli di linguaggio di grandi dimensioni congelati (LLMs) per produrre rapidamente fasi intermedie nei programmi di ragionamento.
ART is a framework that uses frozen large language models (LLMs) to quickly produce intermediate stages in reasoning programs.


I grandi modelli di linguaggio possono adattarsi rapidamente a nuovi compiti utilizzando l’apprendimento in contesto, ricevendo alcuni esempi di dimostrazione e istruzioni in linguaggio naturale. Ciò evita di dover ospitare il modello di linguaggio o annotare grandi quantità di dati, ma presenta importanti problemi di prestazioni con il ragionamento a più passaggi, la matematica, l’ottenimento delle informazioni più recenti e altre cose. Ricerche recenti suggeriscono di dare ai modelli di linguaggio accesso a strumenti per facilitare fasi di ragionamento più sofisticate o di sfidarli a emulare una catena di ragionamento per il ragionamento a più passaggi per alleviare questi vincoli. Tuttavia, è difficile adattare approcci consolidati per un ragionamento a catena con l’uso di strumenti per nuove attività e strumenti; ciò richiede un addestramento fine o un’ingegnerizzazione specifica per una particolare attività o strumento.
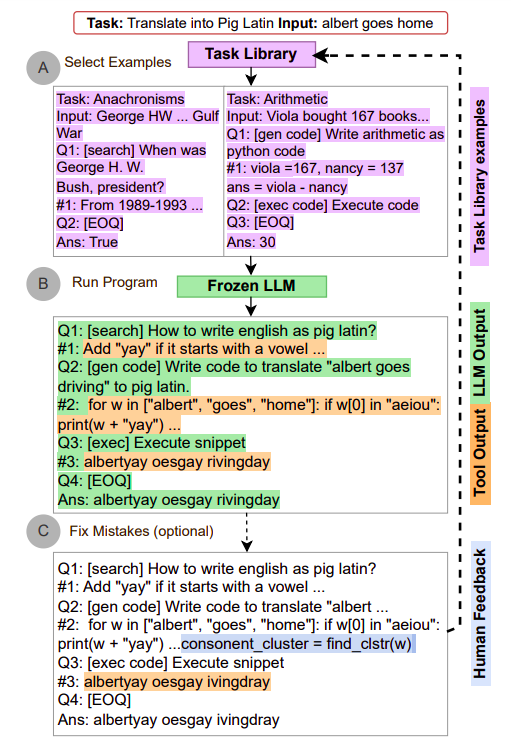
Ricercatori dell’Università di Washington, Microsoft, Meta, dell’Università della California e dell’Istituto di Ricerca Allen hanno sviluppato il framework Automated Reasoning and Tool usage (ART), che crea automaticamente decomposizioni (ragionamento a più passaggi) per esempi di nuove attività, come presentato in questo studio. ART seleziona esempi di attività simili da una libreria di attività per consentire una suddivisione e un utilizzo degli strumenti a poche dimostrazioni per ulteriori lavori. Questi esempi utilizzano un linguaggio di interrogazione flessibile ma strutturato che semplifica la lettura delle fasi intermedie, mette in pausa la creazione per utilizzare strumenti esterni e la riavvia una volta che l’output di quegli strumenti è stato incluso (Figura 1). Inoltre, il framework seleziona ed utilizza gli strumenti più adatti (come motori di ricerca ed esecuzione di codice) in ogni fase.
Il modello di linguaggio riceve esempi da ART su come suddividere istanze di diverse attività correlate e su come selezionare ed utilizzare gli strumenti dalla libreria di strumenti descritta in questi esempi. Ciò aiuta il modello a generalizzare dagli esempi per suddividere nuove attività e utilizzare gli strumenti giusti per il lavoro, senza bisogno di ulteriori dimostrazioni. Inoltre, gli utenti possono aggiornare le librerie di attività e strumenti e aggiungere nuovi esempi se necessario per correggere eventuali errori nella catena logica o aggiungere nuovi strumenti (ad esempio, per l’attività in questione).
- L’ex CEO di Google per potenziare l’esercito degli Stati Uniti con l’IA e il Metaverso
- Bloccanti pubblicitari migliori per la privacy online (2023)
- Modelli di linguaggio multimodali Il futuro dell’Intelligenza Artificiale (AI)
Viene creata una libreria di attività per 15 compiti BigBench e ART viene testato su 19 compiti di prova BigBench che non sono mai stati visti prima, 6 compiti MMLU e numerosi compiti provenienti da ricerche sull’utilizzo di strumenti correlati (SQUAD, TriviaQA, SVAMP, MAWPS). Per 32 su 34 problemi BigBench e tutti i compiti MMLU, ART riesce regolarmente a eguagliare o superare le catene di ragionamento generate al computer dalla tecnica CoT, in media, di oltre il 22%. Consentire l’uso degli strumenti aumenta le prestazioni sui compiti di prova di circa il 12,3% in media rispetto a quando non vengono utilizzati.
In media, ART supera il prompting diretto a poche dimostrazioni sia nei compiti BigBench che nei compiti MMLU di 10,8 punti percentuali. ART supera il prompting diretto a poche dimostrazioni nei compiti non visti che richiedono ragionamento matematico e algoritmico di 12,5 punti percentuali e supera i risultati noti migliori di GPT3, compresa la supervisione per la suddivisione e l’utilizzo degli strumenti, di 6,1 punti percentuali. L’aggiornamento delle librerie di attività e strumenti con nuovi esempi consente l’interazione umana e il miglioramento del processo di ragionamento, rendendo estremamente semplice migliorare le prestazioni su qualsiasi lavoro con un minimo intervento umano. Su 12 compiti di prova, ART supera i risultati noti migliori di GPT3 in media di oltre il 20% punti quando viene fornito un ulteriore feedback umano.





