Migliora Amazon Lex con LLMs e migliora l’esperienza delle FAQ utilizzando l’ingestione degli URL
Improve Amazon Lex with LLMs and enhance FAQ experience with URL ingestion
Nel mondo digitale di oggi, la maggior parte dei consumatori preferisce trovare risposte alle proprie domande di assistenza clienti da soli anziché perdere tempo a contattare le aziende e/o i fornitori di servizi. Questo post sul blog esplora una soluzione innovativa per creare un chatbot di domande e risposte in Amazon Lex che utilizza le FAQ esistenti dal tuo sito web. Questo strumento alimentato da intelligenza artificiale può fornire risposte rapide e accurate a domande reali, consentendo al cliente di risolvere rapidamente e facilmente problemi comuni in modo indipendente.
Ingestione di un singolo URL
Molte aziende hanno un insieme di risposte pubblicate per le FAQ per i loro clienti disponibili sul loro sito web. In questo caso, vogliamo offrire ai clienti un chatbot che possa rispondere alle loro domande dalle nostre FAQ pubblicate. Nel post del blog intitolato “Migliorare Amazon Lex con funzionalità conversazionali delle FAQ utilizzando LLMs”, abbiamo dimostrato come è possibile utilizzare una combinazione di Amazon Lex e LlamaIndex per creare un chatbot basato sulle tue fonti di conoscenza esistenti, come documenti in formato PDF o Word. Per supportare una semplice FAQ, basata su un sito web di FAQ, è necessario creare un processo di ingestione che possa eseguire lo spidering del sito web e creare incorporamenti che possono essere utilizzati da LlamaIndex per rispondere alle domande dei clienti. In questo caso, ci baseremo sul bot creato nel post del blog precedente, che effettua query su tali incorporamenti con l’input dell’utente e restituisce la risposta dalle FAQ del sito web.
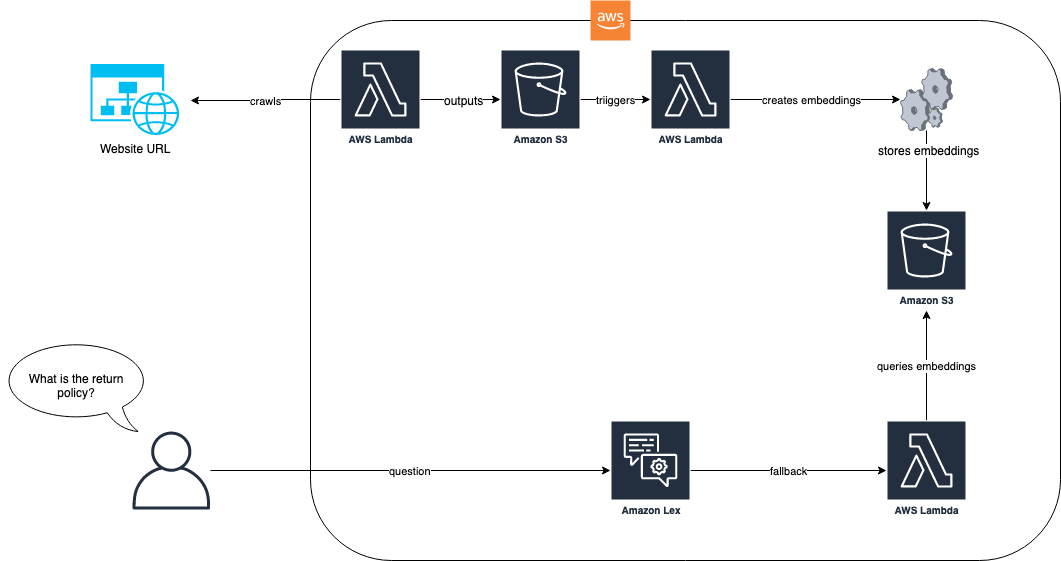
Il diagramma seguente mostra come il processo di ingestione e il bot Amazon Lex lavorano insieme per la nostra soluzione.
- Migliora Amazon Lex con funzionalità di FAQ conversazionali utilizzando LLMs
- L’ottimizzazione dei simboli migliora l’apprendimento in contesto nei modelli di linguaggio
- Llama 2 è qui – ottienilo su Hugging Face
Nel flusso di lavoro della soluzione, il sito web con le FAQ viene inglobato tramite AWS Lambda. Questa funzione Lambda esegue lo spidering del sito web e memorizza il testo risultante in un bucket di Amazon Simple Storage Service (Amazon S3). Il bucket di S3 attiva quindi una funzione Lambda che utilizza LlamaIndex per creare incorporamenti che vengono memorizzati in Amazon S3. Quando arriva una domanda da un utente finale, ad esempio “Qual è la vostra politica di reso?”, il bot Amazon Lex utilizza la sua funzione Lambda per interrogare gli incorporamenti utilizzando un approccio basato su RAG con LlamaIndex. Per ulteriori informazioni su questo approccio e sui prerequisiti, consulta il post del blog “Migliorare Amazon Lex con funzionalità conversazionali delle FAQ utilizzando LLMs”.
Dopo aver completato i prerequisiti del blog sopra menzionato, il primo passo è inglobare le FAQ in un repository di documenti che può essere vettorizzato e indicizzato da LlamaIndex. Il codice seguente mostra come fare ciò:
import logging
import sys
import requests
import html2text
from llama_index.readers.schema.base import Document
from llama_index import GPTVectorStoreIndex
from typing import List
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
class EZWebLoader:
def __init__(self, default_header: str = None):
self._html_to_text_parser = html2text()
if default_header is None:
self._default_header = {"User-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36"}
else:
self._default_header = default_header
def load_data(self, urls: List[str], headers: str = None) -> List[Document]:
if headers is None:
headers = self._default_header
documents = []
for url in urls:
response = requests.get(url, headers=headers).text
response = self._html2text.html2text(response)
documents.append(Document(response))
return documents
url = "http://www.zappos.com/general-questions"
loader = EZWebLoader()
documents = loader.load_data([url])
index = GPTVectorStoreIndex.from_documents(documents)Nell’esempio precedente, prendiamo un URL predefinito del sito web delle FAQ da Zappos e lo inglobiamo utilizzando la classe EZWebLoader. Con questa classe, abbiamo navigato fino all’URL e caricato tutte le domande presenti nella pagina in un indice. Ora possiamo fare una domanda come “Zappos ha carte regalo?” e ottenere le risposte direttamente dalle nostre FAQ sul sito web. Lo screenshot seguente mostra la console di test del bot Amazon Lex che risponde a quella domanda dalle FAQ.

Siamo stati in grado di ottenere questo perché avevamo analizzato l’URL nel primo passaggio e creato delle incorporazioni che LlamaIndex poteva utilizzare per cercare la risposta alla nostra domanda. La funzione Lambda del nostro bot mostra come viene eseguita questa ricerca ogni volta che viene restituito l’intento di fallback:
import time
import json
import os
import logging
import boto3
from llama_index import StorageContext, load_index_from_storage
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def download_docstore():
# Crea un client S3
s3 = boto3.client('s3')
# Elenca tutti gli oggetti nel bucket S3 e scarica ciascuno di essi
try:
bucket_name = 'faq-bot-storage-001'
s3_response = s3.list_objects_v2(Bucket=bucket_name)
if 'Contents' in s3_response:
for item in s3_response['Contents']:
file_name = item['Key']
logger.debug("Download in corso in /tmp/" + file_name)
s3.download_file(bucket_name, file_name, '/tmp/' + file_name)
logger.debug('Tutti i file sono stati scaricati da S3 e scritti nel filesystem locale.')
except Exception as e:
logger.error(e)
raise e
# Scarica il doc store in locale
download_docstore()
storage_context = StorageContext.from_defaults(persist_dir="/tmp/")
# Carica l'indice
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
def lambda_handler(event, context):
"""
Instrada la richiesta in arrivo in base all'intento.
Il corpo JSON della richiesta è fornito nello slot di evento.
"""
# Per impostazione predefinita, considera la richiesta dell'utente come proveniente dal fuso orario America/New_York.
os.environ['TZ'] = 'America/New_York'
time.tzset()
logger.debug("===== INIZIO ADATTAMENTO LEX ====")
logger.debug(event)
slots = {}
if "currentIntent" in event and "slots" in event["currentIntent"]:
slots = event["currentIntent"]["slots"]
intent = event["sessionState"]["intent"]
dialogaction = {"type": "Delegate"}
message = []
if str.lower(intent["name"]) == "fallbackintent":
# Esegui la query dall'input fornito dall'utente
response = str.strip(query_engine.query(event["inputTranscript"]).response)
dialogaction["type"] = "Close"
message.append({'content': f'{response}', 'contentType': 'PlainText'})
final_response = {
"sessionState": {
"dialogAction": dialogaction,
"intent": intent
},
"messages": message
}
logger.debug(json.dumps(final_response, indent=1))
logger.debug("===== FINE ADATTAMENTO LEX ====")
return final_responseQuesta soluzione funziona bene quando una singola pagina web contiene tutte le risposte. Tuttavia, la maggior parte dei siti FAQ non è costruita su una singola pagina. Ad esempio, nel nostro esempio di Zappos, se facciamo la domanda “Avete una politica di corrispondenza dei prezzi?”, otteniamo una risposta non soddisfacente, come mostrato nella seguente schermata.
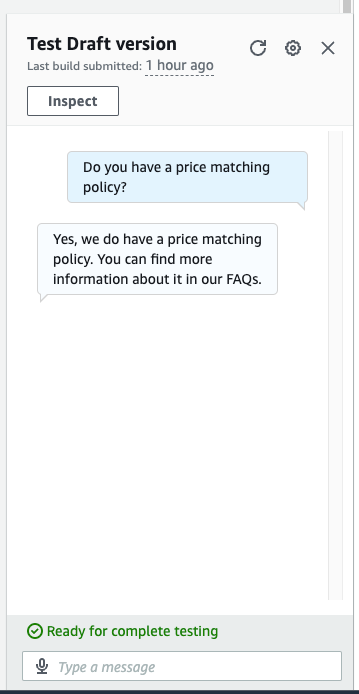
Nell’interazione precedente, la risposta sulla politica di corrispondenza dei prezzi non è utile per l’utente. Questa risposta è breve perché il FAQ citato è un collegamento a una pagina specifica sulla politica di corrispondenza dei prezzi e la nostra analisi web riguardava solo la singola pagina. Per ottenere risposte migliori, sarà necessario analizzare anche questi collegamenti. La sezione successiva mostra come ottenere risposte a domande che richiedono due o più livelli di profondità delle pagine.
Analisi a N livelli
Quando analizziamo una pagina web per conoscere le FAQ, le informazioni che vogliamo possono essere contenute in pagine collegate. Ad esempio, nel nostro esempio di Zappos, se facciamo la domanda “Avete una politica di corrispondenza dei prezzi?”, la risposta è “Sì, visita il link per saperne di più.” Se qualcuno chiede “Qual è la vostra politica di corrispondenza dei prezzi?”, vogliamo dare una risposta completa con la politica. Per ottenere questo, dobbiamo analizzare i collegamenti per ottenere le informazioni effettive per l’utente finale. Durante il processo di acquisizione, possiamo utilizzare il nostro caricatore web per trovare i collegamenti di ancoraggio ad altre pagine HTML e quindi analizzarli. La seguente modifica al nostro crawler web ci consente di trovare i collegamenti nelle pagine che analizziamo. Include anche una logica aggiuntiva per evitare l’analisi circolare e consentire un filtro con un prefisso.
import logging
import requests
import html2text
from llama_index.readers.schema.base import Document
from typing import List
import re
def find_http_urls_in_parentheses(s: str, prefix: str = None):
pattern = r'\((https?://[^)]+)\)'
urls = re.findall(pattern, s)
matched = []
if prefix is not None:
for url in urls:
if str(url).startswith(prefix):
matched.append(url)
else:
matched = urls
return list(set(matched)) # rimuovi i duplicati convertendo in set, quindi converti di nuovo in list
class EZWebLoader:
def __init__(self, default_header: str = None):
self._html_to_text_parser = html2text
if default_header is None:
self._default_header = {"User-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36"}
else:
self._default_header = default_header
def load_data(self,
urls: List[str],
num_levels: int = 0,
level_prefix: str = None,
headers: str = None) -> List[Document]:
logging.info(f"Numero di URL: {len(urls)}.")
if headers is None:
headers = self._default_header
documents = []
visited = {}
for url in urls:
q = [url]
depth = num_levels
for page in q:
if page not in visited: # evita i cicli controllando se abbiamo già analizzato un collegamento
logging.info(f"Analisi di {page}")
visited[page] = True # aggiungi voce a visitati per evitare di analizzare nuovamente le pagine
response = requests.get(page, headers=headers).text
response = self._html_to_text_parser.html2text(response) # riduci l'HTML a testo
documents.append(Document(response))
if depth > 0:
# analizza le pagine collegate
ingest_urls = find_http_urls_in_parentheses(response, level_prefix)
logging.info(f"Trovate {len(ingest_urls)} pagine da analizzare.")
q.extend(ingest_urls)
depth -= 1 # riduci il contatore di profondità per andare solo num_levels in profondità nella nostra analisi
else:
logging.info(f"Salto di {page} perché è già stato analizzato")
logging.info(f"Numero di documenti: {len(documents)}.")
return documents
url = "http://www.zappos.com/general-questions"
loader = EZWebLoader()
# analizza il sito con profondità 1 e prefisso "/c/" per la root del servizio clienti
documents = loader.load_data([url]
num_levels=1, level_prefix="https://www.zappos.com/c/")
index = GPTVectorStoreIndex.from_documents(documents)Nel codice precedente, introduciamo la possibilità di eseguire il crawling di N livelli di profondità e forniamo un prefisso che ci permette di limitare il crawling solo a elementi che iniziano con un certo pattern di URL. Nel nostro esempio di Zappos, le pagine del servizio clienti sono tutte radicate in zappos.com/c, quindi includiamo questo come prefisso per limitare i nostri crawl a un sottoinsieme più piccolo e pertinente. Il codice mostra come possiamo inglobare fino a due livelli di profondità. La logica Lambda del nostro bot rimane la stessa perché niente è cambiato tranne che il crawler ingloba più documenti.
Ora abbiamo tutti i documenti indicizzati e possiamo fare una domanda più dettagliata. Nella seguente schermata, il nostro bot fornisce la risposta corretta alla domanda “Avete una politica di corrispondenza dei prezzi?”

Ora abbiamo una risposta completa alla nostra domanda sulla corrispondenza dei prezzi. Invece di ricevere semplicemente la risposta “Sì, consulta la nostra politica”, ci vengono forniti i dettagli dal crawl di secondo livello.
Pulizia
Per evitare future spese, procedi con l’eliminazione di tutte le risorse che sono state distribuite come parte di questo esercizio. Abbiamo fornito uno script per spegnere l’endpoint di Sagemaker in modo corretto. I dettagli sull’utilizzo sono nel file README. Inoltre, per rimuovere tutte le altre risorse, puoi eseguire il comando cdk destroy nella stessa directory dei comandi cdk per deprovisionare tutte le risorse dello stack.
Conclusione
La possibilità di inglobare un insieme di domande frequenti in un chatbot consente ai tuoi clienti di trovare le risposte alle loro domande mediante query di linguaggio naturale semplici. Combinando il supporto integrato di Amazon Lex per la gestione delle situazioni di fallback con una soluzione RAG come un LlamaIndex, possiamo fornire un percorso rapido affinché i nostri clienti ottengano risposte soddisfacenti, curate e approvate alle domande frequenti. Applicando il crawling a N livelli nella nostra soluzione, possiamo permettere risposte che potrebbero coprire più link di FAQ e fornire risposte più approfondite alle domande dei nostri clienti. Seguendo questi passaggi, puoi incorporare senza problemi potenti capacità di domande e risposte basate su LLM e un’ingestione efficiente di URL nel tuo chatbot Amazon Lex. Ciò comporta interazioni più accurate, complete e consapevoli del contesto con gli utenti.





