Svelando il potere del Llama 2 di Meta Un salto in avanti nell’IA generativa?
Svelando il potere del Llama 2 di Meta un salto nell'IA generativa?

Introduzione
Recenti progressi nell’intelligenza artificiale (AI), in particolare nell’AI generativa, hanno catturato l’immaginazione del pubblico e dimostrato il potenziale di queste tecnologie nel guidare una nuova era di opportunità economiche e sociali. Uno di questi progressi è Meta’s Llama 2, la nuova generazione del loro modello di lingua grande open-source.
- Rivoluzionare la sintesi del testo Esplorare i trasformatori GPT-2 e XLNet
- GPT-Engineer Il tuo nuovo assistente AI per la programmazione
- Sono trapelati i dettagli di GPT-4!
Meta’s Llama 2 è addestrato su una miscela di dati disponibili pubblicamente e progettato per guidare applicazioni come ChatGPT di OpenAI, Bing Chat e altri moderni chatbot. Addestrato su una miscela di dati disponibili pubblicamente, Meta sostiene che le performance di Llama 2 siano migliorate significativamente rispetto ai modelli Llama precedenti. Il modello è disponibile per il fine-tuning su AWS, Azure e sulla piattaforma di hosting di modelli AI di Hugging Face in forma preaddestrata, rendendolo più accessibile e più facile da eseguire. Puoi anche scaricare il modello qui.
Ma cosa distingue Llama 2 dal suo predecessore e da altri modelli di lingua grandi? Approfondiamo i dettagli tecnici e le implicazioni.
Dettagli tecnici e performance
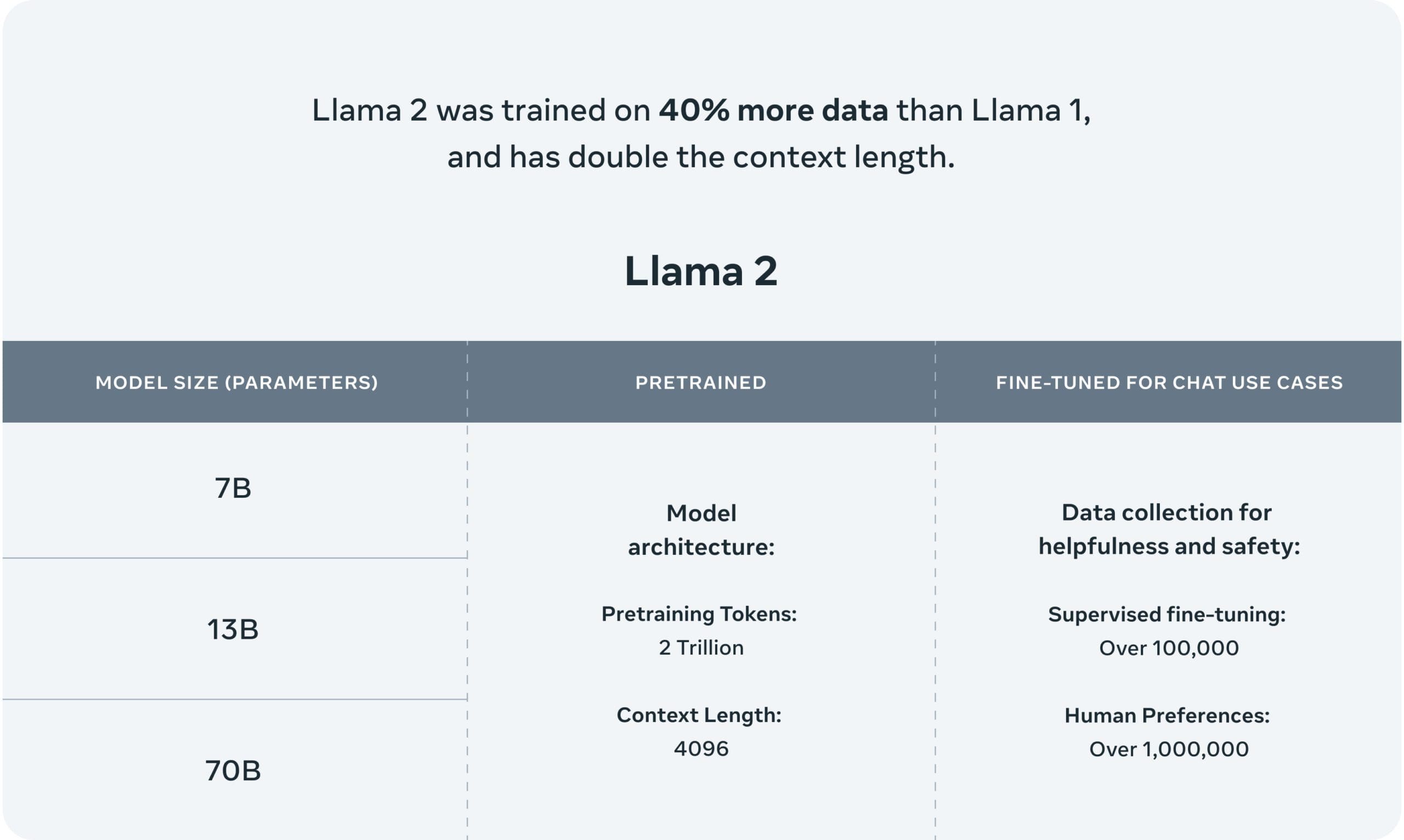
Ci sono due varianti di Llama 2: Llama 2 e Llama-2-Chat. Llama-2-Chat è stato fine-tunato per conversazioni a due vie. Entrambe le versioni sono ulteriormente suddivise in modelli di varia complessità: modelli da 7 miliardi di parametri, da 13 miliardi di parametri e da 70 miliardi di parametri. I modelli sono stati addestrati su due trilioni di token, che è il 40% in più del primo modello Llama, inclusi oltre 1 milione di annotazioni umane.
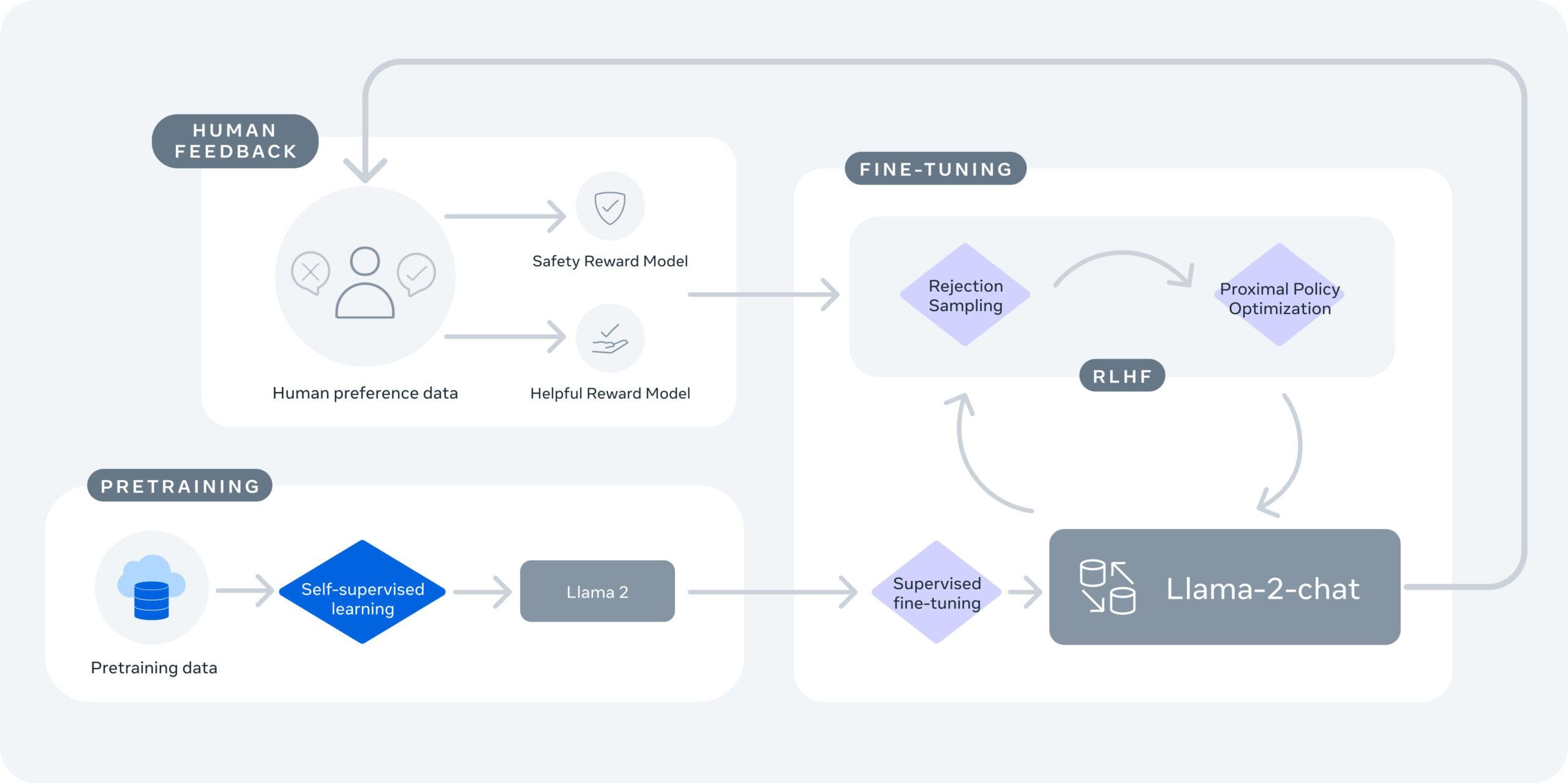
Llama 2 ha una lunghezza di contesto di 4096 e utilizza il reinforcement learning dai feedback umani specificamente per la sicurezza e la utilità nel caso dell’addestramento di Llama-Chat-2. Llama 2 supera altri LLM, come Falcon e MPT, nelle aree del ragionamento, della codifica, della competenza e dei test di conoscenza, secondo Meta.
Inoltre, Llama 2 è ottimizzato per essere eseguito in locale su Windows e su smartphone e PC con la tecnologia on-device di Qualcomm Snapdragon, il che significa che possiamo aspettarci app alimentate dall’IA che funzionano senza dipendere dai servizi cloud a partire dal 2024.
“Queste nuove esperienze di IA on-device, alimentate da Snapdragon, possono funzionare in aree senza connettività o anche in modalità aereo.”
—Qualcomm (fonte: CNET)
Open-Source e sicurezza
Uno degli aspetti chiave di Llama 2 è la sua natura open-source. Meta crede che rendendo i modelli di IA disponibili apertamente, possano beneficiare tutti. Questo sviluppo permette sia al mondo degli affari che alla ricerca di accedere a strumenti che sarebbero diventati proibitivi da costruire e scalare da soli, aprendo una miriade di opportunità per la ricerca, l’esperimento e lo sviluppo.
Meta sottolinea anche la sicurezza e la trasparenza. Llama 2 è stato “red-teamed” e quindi è stato testato per la sicurezza generando prompt avversari per il fine-tuning del modello, sia internamente che esternamente. Meta divulga come i modelli vengono valutati e modificati, promuovendo la trasparenza nel processo di sviluppo.
Conclusione
Llama 2 fa del suo meglio per continuare la prospettiva di Meta nel campo dell’IA generativa. Le sue performance migliorate, la sua natura open-source e l’impegno per la sicurezza e la trasparenza rendono Llama 2 un modello promettente per una vasta gamma di applicazioni. Man mano che sempre più sviluppatori e ricercatori ottengono accesso, possiamo aspettarci un’impennata di soluzioni innovative alimentate dall’IA.
Mentre andiamo avanti, sarà cruciale continuare ad affrontare le sfide e i pregiudizi intrinseci ai modelli di IA. Tuttavia, l’impegno di Meta per la sicurezza e la trasparenza stabilisce un precedente positivo per il settore. Con il rilascio di Llama 2, ora abbiamo a disposizione un altro strumento nel nostro arsenale di IA generativa, e uno che fa dell’accesso aperto un impegno continuo.
Matthew Mayo (@mattmayo13) è un Data Scientist e l’Editor-in-Chief di VoAGI, la risorsa online di riferimento per Data Science e Machine Learning. I suoi interessi sono nell’elaborazione del linguaggio naturale, nel design e nell’ottimizzazione degli algoritmi, nell’apprendimento non supervisionato, nelle reti neurali e nelle approcci automatizzati all’apprendimento automatico. Matthew ha una laurea magistrale in informatica e un diploma di laurea in data mining. Puoi contattarlo all’indirizzo editor1 at VoAGI[dot]com.





