Mappa-corrispondenza per la previsione della traiettoria
Mappa-corrispondenza per la previsione della traiettoria' can be condensed as 'Mappa-corrispondenza traiettoria'.
Dove stai andando? Dovresti andare in quella direzione?
Questo articolo presenta un metodo per prevedere le traiettorie dei veicoli su una rete stradale digitale utilizzando un database di viaggi passati campionati da sensori GPS rumorosi. Oltre a prevedere le direzioni future, questo metodo assegna anche una probabilità a una sequenza arbitraria di posizioni.
Centrale a questa idea è l’utilizzo di una mappa digitale su cui proiettiamo tutte le posizioni campionate aggregandole in traiettorie individuali e abbinandole alla mappa. Questo processo di abbinamento discretizza lo spazio GPS continuo in posizioni e sequenze predeterminate. Dopo aver codificato queste posizioni in token geospaziali unici, possiamo prevedere più facilmente sequenze, valutare la probabilità delle osservazioni attuali e stimare le direzioni future. Questo è il cuore di questo articolo.
I Problemi
Quali problemi sto cercando di risolvere qui? Se hai bisogno di analizzare i dati del percorso del veicolo, potresti dover rispondere a domande come quelle nel sottotitolo dell’articolo.
Dove stai andando? Dovresti andare in quella direzione?
Come valuti la probabilità che il percorso in osservazione segua direzioni frequentemente percorse? Questa è una domanda importante perché, rispondendovi, potresti programmare un sistema automatizzato per classificare i viaggi in base alla loro frequenza osservata. Una nuova traiettoria con un punteggio basso potrebbe causare preoccupazione e richiedere una segnalazione immediata.
Come prevedi quali manovre farà il veicolo successivamente? Continuerà dritto o svoltare a destra all’incrocio successivo? Dove ti aspetti di vedere il veicolo nei prossimi dieci minuti o dieci miglia? Risposte rapide a queste domande aiuteranno una soluzione software di tracciamento online a fornire risposte e informazioni ai pianificatori di consegna, agli ottimizzatori di percorso online o persino ai sistemi di ricarica opportunistica.
Soluzione
La soluzione che presento qui utilizza un database di traiettorie storiche, ciascuna costituita da una sequenza temporizzata di posizioni generate dal movimento di un veicolo specifico. Ogni record di posizione deve contenere tempo, informazioni sulla posizione, un riferimento all’identificatore del veicolo e all’identificatore della traiettoria. Un veicolo ha molte traiettorie e ogni traiettoria ha molti record di posizione. Un campione dei nostri dati di input è rappresentato nella Figura 1 di seguito.
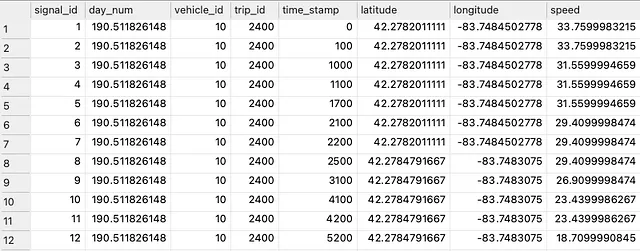
Ho tratto i dati sopra dall’Extended Vehicle Energy Dataset (EVED) [1]. Puoi creare il corrispondente database seguendo il codice in uno dei miei articoli precedenti.
Stima dei Tempi di Viaggio Utilizzando Quadkeys
Questo articolo spiega come stimare i tempi di viaggio utilizzando vettori di velocità noti indicizzati da quadkeys.
towardsdatascience.com
Il nostro primo compito è abbinare queste traiettorie a una mappa digitale di supporto. Lo scopo di questo passaggio non è solo eliminare gli errori di campionamento dei dati GPS, ma, soprattutto, coercire i dati di viaggio acquisiti in una rete stradale esistente in cui ogni nodo e tratto sono noti e fissi. Ogni traiettoria registrata viene quindi convertita da una sequenza di posizioni geospaziali in un’altra sequenza di token numerici coincidenti con i nodi esistenti della mappa digitale. Qui useremo dati e software open source, con dati cartografici provenienti da OpenStreetMap (compilati da Geofabrik), il pacchetto di abbinamento mappe Valhalla e H3 come tokenizer geospaziale.
Corrispondenza tra Bordi e Nodi
La map-matching è più complessa di quanto possa sembrare a prima vista. Per illustrare cosa comporta questo concetto, diamo un’occhiata alla Figura 2 qui sotto.
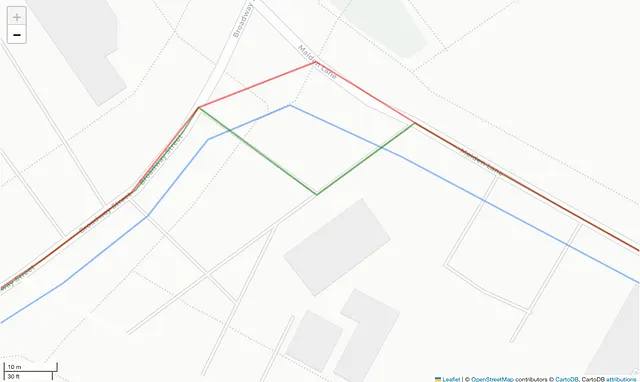
La Figura 2 sopra mostra che possiamo ottenere due traiettorie da una sequenza GPS originale. Otteniamo la prima traiettoria proiettando le posizioni GPS originali nei segmenti della rete stradale più vicina (e più probabile). Come puoi vedere, la polilinea risultante seguirà solo occasionalmente la strada perché la mappa utilizza nodi del grafo per definire le sue forme di base. Proiettando le posizioni originali sugli spigoli della mappa, otteniamo nuovi punti che appartengono alla mappa ma possono allontanarsi dalla geometria della mappa quando vengono collegati ai successivi da una linea retta.
Proiettando la traiettoria GPS sui nodi della mappa, otteniamo un percorso che si sovrappone perfettamente alla mappa, come mostrato dalla linea verde nella Figura 2. Anche se questo percorso rappresenta meglio la traiettoria iniziale, non necessariamente ha una corrispondenza di posizione uno a uno con l’originale. Fortunatamente, questo non ci preoccupa poiché mappiamo sempre ogni traiettoria ai nodi della mappa, quindi otteniamo sempre dati coerenti, con un’eccezione. Il codice di map-matching di Valhalla proietta sempre gli estremi iniziale e finale della traiettoria sugli spigoli, quindi li scartiamo sistematicamente poiché non corrispondono ai nodi della mappa.
Tokenizzazione H3
Purtroppo, Valhalla non riporta gli identificatori univoci dei nodi della rete stradale, quindi dobbiamo convertire le coordinate dei nodi in token interi unici per il calcolo successivo della frequenza della sequenza. Qui entra in gioco H3, consentendoci di codificare le coordinate dei nodi in un intero a sessantaquattro bit in modo univoco. Prendiamo la polilinea generata da Valhalla, eliminiamo i punti iniziale e finale (questi punti non sono nodi ma proiezioni sugli spigoli) e mappiamo tutte le coordinate rimanenti agli indici H3 di livello 15.
Il Grafo Duale
Utilizzando il processo descritto sopra, convertiamo ogni traiettoria storica in una sequenza di token H3. Il passo successivo consiste nel convertire ogni traiettoria in una sequenza di triplette di token. Tre valori in una sequenza rappresentano due spigoli consecutivi del grafo di previsione e vogliamo conoscere le frequenze di questi, in quanto saranno i dati principali sia per la previsione che per la valutazione della probabilità. La Figura 3 qui sotto illustra questo processo visivamente.
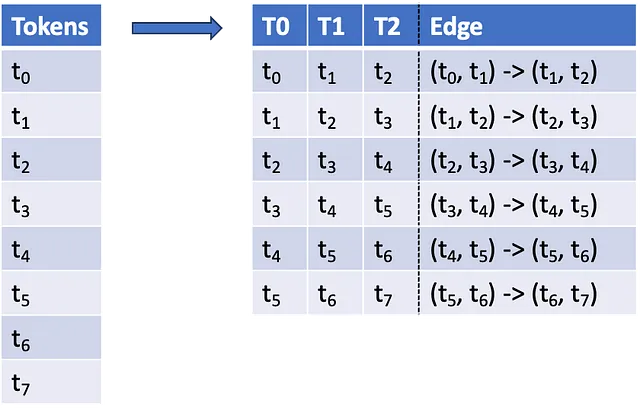
La trasformazione sopra calcola il duale del grafo stradale, invertendo i ruoli dei nodi e degli archi originali.
Ora possiamo iniziare a rispondere alle domande proposte.
Dovresti andare in quella direzione?
Abbiamo bisogno di conoscere la traiettoria del veicolo fino a un dato momento per rispondere a questa domanda. Mappiamo e tokenizziamo la traiettoria utilizzando lo stesso processo descritto sopra e quindi calcoliamo la frequenza di ogni tripletta di traiettoria utilizzando le frequenze storiche conosciute. Il risultato finale è il prodotto di tutte le frequenze individuali. Se la tripletta di input è sconosciuta, la sua frequenza sarà zero come probabilità di percorso finale.
La probabilità di una tripletta è il rapporto tra il conteggio di una specifica sequenza (A, B, C) e il conteggio di tutte le triplette (A, B, *) come rappresentato nella Figura 4 qui sotto.
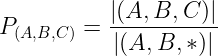
La probabilità di un percorso è semplicemente il prodotto delle triplette di traiettoria individuali, come rappresentato nella Figura 5 qui sotto.

Dove stai andando?
Utilizziamo gli stessi principi per rispondere a questa domanda, ma iniziamo solo con l’ultima tripletta conosciuta. Possiamo prevedere i k successori più probabili utilizzando questa tripletta come input enumerando tutte le triplette che hanno come primi due token gli ultimi due dell’input. La Figura 6 qui sotto illustra il processo di generazione ed elaborazione della sequenza di triplette.
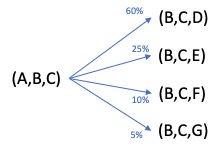
Possiamo estrarre le prime k triplette successorie e ripetere il processo per prevedere il percorso più probabile.
Implementazione
Siamo pronti per discutere i dettagli di implementazione, iniziando con la mappatura e alcuni concetti correlati. Successivamente, vedremo come utilizzare il set di strumenti Valhalla da Python, estrarre i percorsi corrispondenti e generare le sequenze di token. La fase di preelaborazione dei dati sarà completata una volta memorizzato il risultato nel database.
Infine, illustro un’interfaccia utente semplice utilizzando Streamlit che calcola la probabilità di qualsiasi traiettoria disegnata a mano e la proietta nel futuro.
Mappatura
La mappatura converte le coordinate GPS campionate dalla traiettoria di un oggetto in movimento in un grafo stradale esistente. Un grafo stradale è un modello discreto della rete stradale fisica sottostante, composto da nodi e archi di collegamento. Ogni nodo corrisponde a una nota posizione geospaziale lungo la strada, codificata come una tupla di latitudine, longitudine ed elevazione. Ogni arco diretto collega nodi adiacenti seguendo la strada sottostante e contiene molte proprietà come la direzione, la velocità massima, il tipo di strada e altro ancora. La Figura 7 qui sotto illustra il concetto con un esempio semplice.
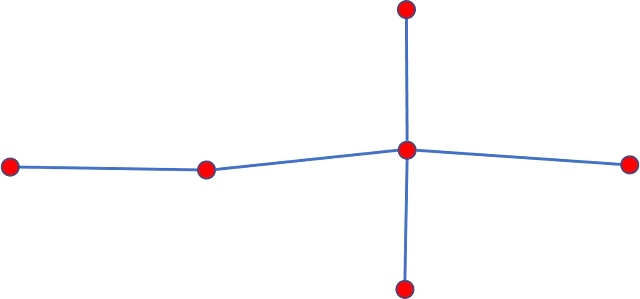
Quando ha successo, il processo di map-matching produce informazioni rilevanti e preziose sulla traiettoria campionata. Da un lato, il processo proietta i punti GPS campionati su posizioni lungo i lati del grafo stradale più probabile. Il processo di map-matching “corregge” i punti osservati posizionandoli esattamente sopra i lati inferiti del grafo stradale. Dall’altro lato, il metodo ricostruisce anche la sequenza di nodi del grafo fornendo il percorso più probabile attraverso il grafo stradale corrispondente alle posizioni GPS campionate. Si noti che, come spiegato in precedenza, queste uscite sono diverse. La prima uscita contiene coordinate lungo i lati del percorso più probabile, mentre la seconda uscita consiste nella sequenza ricostruita dei nodi del grafo. Figura 8 di seguito illustra il processo.
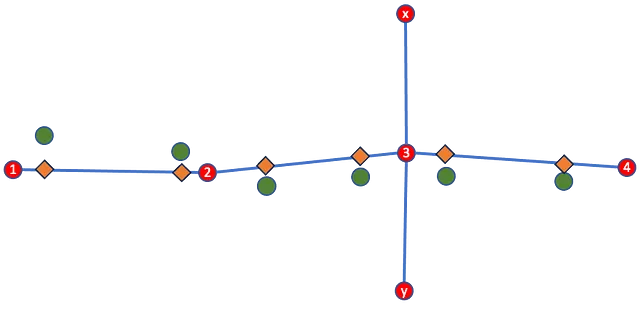
Un sottoprodotto del processo di map-matching è la standardizzazione delle posizioni di input utilizzando una rappresentazione condivisa del network stradale, specialmente quando si considera il secondo tipo di output: la sequenza più probabile di nodi. Convertendo le traiettorie GPS campionate in una serie di nodi, le rendiamo confrontabili riducendo il percorso inferito a una serie di identificatori di nodo. Possiamo pensare a queste sequenze di nodi come frasi di un linguaggio noto, dove ciascun identificatore di nodo inferito è una parola e il loro disposto trasmette informazioni comportamentali.
Questo è il quinto articolo in cui esploro l’Extended Vehicle Energy Dataset¹ (EVED) [1]. Questo dataset è un miglioramento e una revisione di lavori precedenti e fornisce le versioni map-matched delle posizioni GPS originali (i diamanti arancioni nella Figura 8 sopra).
Purtroppo, l’EVED contiene solo le posizioni GPS proiettate e manca delle sequenze ricostruite dei nodi del network stradale. Nei miei due articoli precedenti, ho affrontato il problema di ricostruire le sequenze dei segmenti stradali dalle posizioni GPS trasformate senza map-matching. Ho trovato il risultato un po’ deludente, poiché mi aspettavo una percentuale di ricostruzioni difettose inferiore al 16% osservato. Puoi seguire questa discussione dagli articoli qui di seguito.
Corrispondenza tra lati del network stradale con triangoli
I triangoli hanno potenti proprietà per le query geospaziali
towardsdatascience.com
Ulteriori informazioni sulla corrispondenza tra network stradale
Scherzi sulla corrispondenza tra network stradale
towardsdatascience.com
Ora sto esaminando lo strumento di map-matching di origine per vedere fino a che punto può correggere le ricostruzioni difettose. Quindi mettiamo alla prova Valhalla. Di seguito sono riportati i passaggi, i riferimenti e il codice che ho utilizzato per eseguire Valhalla su un container Docker.
Configurazione di Valhalla
Qui seguo attentamente le istruzioni fornite da Sandeep Pandey [2] nel suo blog.
Prima di tutto, assicurati di avere Docker installato sul tuo computer. Per installare il motore Docker, segui le istruzioni online. Se lavori su un Mac, un’ottima alternativa è Colima.
Una volta installato, devi scaricare un’immagine di Valhalla da GitHub emettendo i seguenti comandi dalla tua riga di comando, come illustrato dal codice shell in Figura 9 di seguito.
Figura 9 – Recupero dell’immagine Docker di Valhalla dalla riga di comando. (Fonte immagine: Autore)
Mentre esegui i comandi sopra, potresti dover inserire le tue credenziali GitHub. Assicurati anche di aver clonato il repository GitHub di questo articolo, poiché alcuni file e strutture di cartelle fanno riferimento ad esso.
Una volta completato, dovresti aprire una nuova finestra del terminale e impartire il seguente comando per avviare il server API Valhalla (MacOS, Linux, WSL):
Figura 10 – Il comando sopra esegue l’immagine Valhalla estratta in un container Docker. Durante l’esecuzione la prima volta, il comando scarica e prepara anche il file dati Geofabrik Michigan più recente prima di avviare. (Fonte immagine: Autore)
La riga di comando sopra specifica esplicitamente quale file OSM scaricare dal servizio Geofabrik, ovvero l’ultimo file Michigan. Questa specifica significa che quando viene eseguito per la prima volta, il server scaricherà e elaborerà il file generando un database ottimizzato. Nelle chiamate successive, il server omette questi passaggi. Quando necessario, eliminare tutto nella directory di destinazione per aggiornare i dati scaricati e avviare nuovamente Docker.
Ora possiamo chiamare l’API Valhalla con un client specializzato.
Entra in PyValhalla
Questo progetto derivato offre semplicemente un pacchetto Python con i binding per il fantastico progetto Valhalla.
L’utilizzo del pacchetto Python PyValhalla è abbastanza semplice. Iniziamo con una procedura di installazione ordinata utilizzando il seguente comando di linea.
Figura 11 – Puoi installare PyValhalla utilizzando PIP. (Fonte immagine: Autore)
Nel tuo codice Python, devi importare i riferimenti necessari, istanziare una configurazione dai file GeoFabrik elaborati e infine creare un oggetto Actor, il tuo gateway per l’API Valhalla.
Figura 12 – Il codice sopra mostra quanto sia facile configurare PyValhalla su un’applicazione o un notebook Python. (Fonte immagine: Autore)
Prima di chiamare il servizio di map-matching di Meili, dobbiamo ottenere le posizioni GPS della traiettoria utilizzando la funzione elencata di seguito in Figura 13.
Figura 13 – La funzione sopra carica le posizioni uniche della traiettoria di un veicolo, restituendo un DataFrame Pandas con latitudine, longitudine e timestamp. (Fonte immagine: Autore)
Ora possiamo configurare il dizionario dei parametri da passare alla chiamata PyValhalla per tracciare il percorso. Consulta la documentazione di Valhalla per ulteriori dettagli su questi parametri. La funzione seguente chiama la funzionalità di map-matching in Valhalla (Meili) ed è inclusa nello script di preparazione dei dati. Illustra come determinare il percorso inferito da un DataFrame Pandas contenente le posizioni GPS osservate codificate come tuple di latitudine, longitudine e tempo.
Figura 14 – La funzione sopra accetta un oggetto Actor PyValhalla e un DataFrame Pandas contenente il percorso di origine e restituisce un polyline codificato in stringa corrispondente alla mappa. Questa stringa viene successivamente decodificata in una lista di posizioni geospaziali corrispondenti ai nodi della rete di mappe digitali, ad eccezione delle estremità, che vengono proiettate sugli edge. (Fonte immagine: Autore)
La funzione sopra restituisce il percorso corrispondente come polyline codificata in stringa. Come illustrato nel codice di preparazione dei dati di seguito, possiamo facilmente decodificare la stringa restituita utilizzando una chiamata alla libreria PyValhalla. Nota che questa funzione restituisce una polyline le cui prime e ultime posizioni sono proiettate sugli edge, non sui nodi del grafo. Vedrai che queste estremità verranno rimosse dal codice successivamente nell’articolo.
Ora passiamo alla fase di preparazione dei dati, in cui convertiamo tutte le traiettorie nel database EVED in un insieme di sequenze di edge map, da cui possiamo derivare le frequenze dei pattern.
Preparazione dei dati
La preparazione dei dati mira a convertire le traiettorie acquisite tramite GPS rumoroso in sequenze di token geospaziali corrispondenti a posizioni di mappa conosciute. Il codice principale itera attraverso le traiettorie esistenti, elaborandone una alla volta.
In questo articolo, utilizzo un database SQLite per memorizzare tutti i risultati dell’elaborazione dei dati. Iniziamo riempiendo il percorso della traiettoria corrispondente. Puoi seguire la descrizione utilizzando il codice in Figura 15 qui sotto.
Figura 15 – Il codice sopra contiene il ciclo di dati di preelaborazione. Questo ciclo itera attraverso le traiettorie conosciute, calcola i loro percorsi corrispondenti alla mappa (se presenti), tokenizza i nodi e li espande in triplette. Il codice memorizza tutti i risultati intermedi e finali nel database. (Fonte immagine: Autore)
Per ogni traiettoria, istanziamo un oggetto del tipo Actor (linea 9). Questo è un requisito non dichiarato, poiché ogni chiamata al servizio di map-matching richiede una nuova istanza. Successivamente, carichiamo i punti della traiettoria (linea 13) acquisiti dai ricevitori GPS dei veicoli con il rumore aggiunto, come indicato nell’articolo originale VED. Nella linea 14, effettuiamo la chiamata di map-matching a Valhalla, recuperiamo il percorso corrispondente codificato in stringa e lo salviamo nel database. Successivamente, decodifichiamo la stringa in una lista di coordinate geospaziali, rimuoviamo le estremità (linea 17) e le convertiamo in una lista di indici H3 calcolati al livello 15 (linea 19). Nella linea 23, salviamo gli indici H3 convertiti e le coordinate originali nel database per la mappatura inversa successiva. Infine, nelle linee 25-27, generiamo una sequenza di triplette basate sulla lista di indici H3 e le salviamo per i calcoli di inferenza successivi.
Andiamo attraverso ciascuno di questi passaggi e li spieghiamo in dettaglio.
Caricamento della traiettoria
Abbiamo visto come caricare ogni traiettoria dal database (vedi Figura 13). Una traiettoria è una sequenza ordinata nel tempo di posizioni GPS campionate codificate come coppia di latitudine e longitudine. Nota che non stiamo usando le versioni corrispondenti di queste posizioni come fornite dai dati EVED. Qui, usiamo le coordinate rumorose e originali come esistevano nel database VED iniziale.
Corrispondenza con la mappa
Il codice che chiama il servizio di corrispondenza con la mappa è già presentato nella Figura 14 sopra. Il problema centrale è la configurazione; oltre a ciò, è una chiamata abbastanza diretta. Anche il salvataggio della stringa codificata risultante nel database è semplice.
Figura 16 — Il codice sopra salva la stringa polilinea codificata nel nuovo database. (Fonte immagine: Autore)
Nella riga 17 del ciclo principale (Figura 15), decodifichiamo la stringa di geometria in una lista di tuple di latitudine e longitudine. Nota che qui eliminiamo le posizioni iniziali e finali, poiché non sono proiettate su nodi. Successivamente, convertiamo questa lista nella sua lista di token H3 corrispondente nella riga 19. Usiamo il livello di dettaglio massimo per cercare di evitare sovrapposizioni e garantire una relazione uno a uno tra i token H3 e i nodi del grafo della mappa. Inseriamo i token nel database nelle due righe seguenti. Prima, salviamo l’intera lista di token associandola alla traiettoria.
Figura 17 — La funzione sopra inserisce la lista di token H3 della traiettoria nel database. (Fonte immagine: Autore)
Successivamente, inseriamo la mappatura delle coordinate del nodo ai token H3 per consentire il disegno delle polylinee da un dato elenco di token. Questa funzionalità sarà utile in seguito quando inferiremo le direzioni future del viaggio.
Figura 18 — Inseriamo una mappatura tra i token H3 e le coordinate del nodo per consentire la ricostruzione di una traiettoria dai token inferiti. (Fonte immagine: Autore)
Ora possiamo generare e salvare le triple di token corrispondenti. La funzione seguente utilizza la nuova lista generata di token H3 e la espande in un’altra lista di triple, come dettagliato nella Figura 3 sopra. Il codice di espansione è rappresentato nella Figura 19 qui sotto.
Figura 19 — Il codice sopra converte una lista di token H3 in una lista delle triple corrispondenti. (Fonte immagine: Autore)
Dopo l’espansione delle triple, possiamo finalmente salvare il prodotto finale nel database, come mostrato dal codice nella Figura 20 qui sotto. Attraverso interrogazioni intelligenti di questa tabella, inferiremo le probabilità di viaggio attuali e le traiettorie future più probabili.
Figura 20 — La funzione sopra salva le triple H3 nel database. Questo è l’ultimo passaggio della fase di preparazione dei dati. Ora possiamo passare ad esplorare le informazioni raccolte. (Fonte immagine: Autore)
Abbiamo ora completato un ciclo del ciclo di preparazione dei dati. Una volta completato il ciclo esterno, abbiamo un nuovo database con tutte le traiettorie convertite in sequenze di token che possiamo esplorare a piacere.
Puoi trovare l’intero codice di preparazione dei dati nel repository GitHub.
Probabilità e previsioni
Ora ci rivolgiamo al problema di stimare le probabilità di viaggio esistenti e prevedere le direzioni future. Iniziamo definendo cosa intendo per “probabilità di viaggio esistenti”.
Probabilità di viaggio
Iniziamo con un percorso arbitrario proiettato sui nodi della rete stradale tramite corrispondenza con la mappa. Pertanto, abbiamo una sequenza di nodi dalla mappa e vogliamo valutare quanto probabile sia quella sequenza, utilizzando come riferimento di frequenza il database di viaggi noti. Utilizziamo la formula nella Figura 5 sopra. In poche parole, calcoliamo il prodotto delle probabilità di tutte le triplette di token individuali.
Per illustrare questa funzionalità, ho implementato un’applicazione Streamlit semplice che consente all’utente di disegnare un viaggio arbitrario nell’area di Ann Arbor coperta e calcolare immediatamente la sua probabilità.
Una volta che l’utente disegna punti sulla mappa che rappresentano il viaggio o i campioni GPS ipotetici, il codice li corrisponde con la mappa per recuperare i token H3 sottostanti. Da quel momento in poi, è semplicemente questione di calcolare le frequenze delle triplette individuali e moltiplicarle per calcolare la probabilità totale. La funzione nella Figura 21 qui sotto calcola la probabilità di un viaggio arbitrario.
Figura 21 — La funzione sopra calcola una probabilità di percorso arbitraria dal database di frequenza delle triplette. (Fonte immagine: Autore)
Il codice riceve il supporto da un’altra funzione che recupera i successori di ogni coppia di token H3 esistenti. La funzione elencata di seguito in Figura 22 interroga il database di frequenza e restituisce un oggetto Counter di Python con i conteggi di tutti i successori della coppia di token di input. Quando la query non trova successori, la funzione restituisce la costante None. Nota come la funzione utilizzi una cache per migliorare le prestazioni di accesso al database (codice non elencato qui).
Figura 22 — La funzione sopra interroga il database di frequenza per i successori noti di ogni coppia di token H3 e restituisce un oggetto Counter con i conteggi di tutti i successori. (Fonte immagine: Autore)
Ho progettato entrambe le funzioni in modo tale che la probabilità calcolata sia zero quando non esistono successori noti per un nodo dato.
Vediamo come possiamo prevedere il percorso futuro più probabile di una traiettoria.
Previsione delle direzioni
Abbiamo bisogno solo degli ultimi due token di una traiettoria in esecuzione per prevedere le direzioni future più probabili. L’idea consiste nell’espandere tutti i successori di quella coppia di token e selezionare quelli più frequenti. Il codice di seguito mostra la funzione come punto di ingresso al servizio di previsione delle direzioni.
Figura 23 — La funzione sopra popola un oggetto FeatureGroup di Folium con i percorsi previsti della traiettoria fornita dall’utente. (Fonte immagine: Autore)
La funzione precedente inizia recuperando la traiettoria disegnata dall’utente come lista di token H3 corrispondenti alla mappa estraibile l’ultima coppia. Chiamiamo questa coppia di token il seed e la espanderemo ulteriormente nel codice. Alla riga 9, chiamiamo la funzione di espansione del seed che restituisce una lista di polilinee corrispondenti ai criteri di espansione di input: il massimo branching per iterazione e il numero totale di iterazioni.
Vediamo come funziona la funzione di espansione del seed seguendo il codice elencato di seguito in Figura 24.
Figura 24 — La funzione di espansione del seed utilizza la classe PredictedPath per gestire ogni iterazione. Si prega di consultare di seguito per ulteriori dettagli su questa classe. (Fonte immagine: Autore)
Chiamando una funzione di espansione del percorso che genera i migliori percorsi successori, la funzione di espansione del seed espande iterativamente i percorsi, a partire da quello iniziale. L’espansione del percorso opera scegliendo un percorso e generando le espansioni più probabili, come mostrato di seguito in Figura 25.
Figura 25 — La funzione di espansione del percorso sopra itera i successori più frequenti per il percorso corrente. Crea un nuovo percorso per ciascuno dei successori più frequenti utilizzando una funzione specializzata (vedere di seguito). (Fonte immagine: Autore)
Il codice genera nuovi percorsi aggiungendo i nodi successori al percorso sorgente, come mostrato in Figura 26 di seguito.
Figura 26 — Per generare un percorso “figlio”, è sufficiente aggiungere il nodo successore a un percorso esistente, come mostrato di seguito. Nota che il codice crea una copia del percorso originale prima di aggiungere il nuovo nodo. (Fonte immagine: Autore)
Il codice implementa percorsi previsti utilizzando una classe specializzata, come mostrato in Figura 27.
Figura 27 — La classe sopra implementa un percorso previsto con supporto per l’ordinamento delle probabilità, la creazione da una coppia di token seed e la generazione delle polyline della mappa. (Fonte immagine: Autore)
L’applicazione
Ora possiamo vedere l’applicazione Streamlit risultante in Figura 28 di seguito.
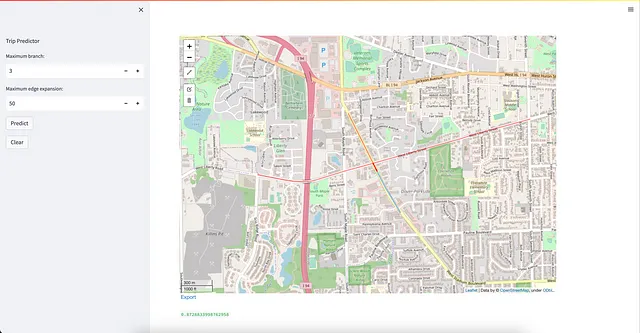
Conclusion
In questo articolo, ho presentato un metodo per prevedere la traiettoria futura di un veicolo quando guida attraverso una rete stradale digitalmente mappata. Utilizzando un database di traiettorie storiche, questo metodo assegna una probabilità a qualsiasi viaggio e prevede anche le direzioni più probabili per il futuro prossimo. Di conseguenza, questo metodo può rilevare traiettorie improbabili o addirittura nuove mai viste prima.
Iniziamo con un ampio database di traiettorie dei veicoli dell’area di interesse. Ogni percorso è una sequenza cronologica di coordinate geospaziali (latitudine e longitudine) e altre proprietà rilevanti come la velocità. Di solito raccogliamo queste traiettorie dai ricevitori GPS a bordo e le compiliamo centralmente in un database.
Le campionature GPS sono rumorose a causa di errori inevitabili che si verificano durante la misurazione del segnale. Ostacoli naturali e artificiali, come i canyon urbani, possono ridurre significativamente l’accuratezza di ricezione del segnale e aumentare gli errori di geolocalizzazione. Fortunatamente, ci sono soluzioni praticabili che risolvono questo problema mediante l’associazione probabilistica delle campionature GPS a una mappa digitale. Ecco di cosa si tratta la corrispondenza della mappa.
Corrispondendo le campionature GPS rumorose a una mappa digitale conosciuta, non solo correggiamo il problema di accuratezza proiettando ogni istanza sul segmento stradale più probabile della mappa, ma otteniamo anche una sequenza discreta di posizioni definite dalla mappa esistente che il veicolo molto probabilmente ha attraversato. Questo ultimo risultato è fondamentale per la nostra previsione della traiettoria perché converte essenzialmente un insieme di coordinate GPS rumorose in una collezione pulita e ben nota di punti nella mappa digitale. Questi marcatori digitali sono fissi e non cambiano mai e proiettando la sequenza di campioni GPS su di essi, otteniamo una serie di token ben noti che possiamo utilizzare successivamente per la previsione.
Calcoliamo tutte le probabilità utilizzando le frequenze della sequenza di token conosciuti per le traiettorie arbitrarie e la loro evoluzione futura. Il risultato sono un paio di script Python, uno per la preparazione dei dati e un altro per l’input dei dati e la visualizzazione utilizzando la piattaforma Streamlit.
Note
- Gli autori del paper originale hanno concesso in licenza il dataset con licenza Apache 2.0 (vedi i repository GitHub VED e EVED). Notare che ciò si applica anche al lavoro derivato.
Riferimenti
[1] Zhang, S., Fatih, D., Abdulqadir, F., Schwarz, T., & Ma, X. (2022). Extended vehicle energy dataset (eVED): an enhanced large-scale dataset for deep learning on vehicle trip energy consumption. arXiv. https://doi.org/10.48550/arXiv.2203.08630
[2] Efficient and fast map matching with Valhalla — Sandeep Pandey (ikespand.github.io)
[3] Map Matching done right using Valhalla’s Meili | by Serge Zotov | Towards Data Science
João Paulo Figueira è un Data Scientist presso tb.lx di Daimler Truck a Lisbona, Portogallo.