Come Chunkare i Dati Testuali – Un’Analisi Comparativa
Chunking Text Data - A Comparative Analysis
Esplorazione di approcci distinti al text chunking.
Introduzione
Il processo di “text chunking” nell’elaborazione del linguaggio naturale (NLP) comporta la conversione di dati di testo non strutturato in unità significative. Questo compito apparentemente semplice nasconde la complessità dei vari metodi impiegati per raggiungerlo, ognuno con i suoi punti di forza e debolezza.
A un livello più generale, questi metodi di solito rientrano in una delle due categorie. Il primo, metodi basati su regole, si basa sull’uso di separatori espliciti come la punteggiatura o i caratteri spazio, o sull’applicazione di sistemi sofisticati come le espressioni regolari, per suddividere il testo in chunk. La seconda categoria, metodi di clustering semantico, sfrutta il significato intrinseco inserito nel testo per guidare il processo di chunking. Questi possono utilizzare algoritmi di apprendimento automatico per discernere il contesto e inferire divisioni naturali all’interno del testo.
In questo articolo esploreremo e compareremo questi due approcci distinti al text chunking. Rappresenteremo i metodi basati su regole con NLTK, Spacy e Langchain, e contrasteremo tutto ciò con due diverse tecniche di clustering semantico: KMeans e una tecnica personalizzata per il clustering delle frasi adiacenti.
Lo scopo è dotare i professionisti di una chiara comprensione dei vantaggi, degli svantaggi e dei casi d’uso ideali di ciascun metodo per consentire una migliore presa di decisioni nei loro progetti di NLP.
- Mappa-corrispondenza per la previsione della traiettoria
- Quanto tempo ci vuole per imparare il Machine Learning?
- Come risolvere le date mancanti per l’analisi delle serie temporali
Nello slang brasiliano, “abacaxi”, che si traduce in “ananas”, significa “qualcosa che non produce un buon risultato, un pasticcio ingarbugliato o qualcosa di negativo”.
Casi d’uso per il text chunking
Il text chunking può essere utilizzato da diverse applicazioni:
- Summarizzazione del testo: Suddividendo grandi quantità di testo in chunk gestibili, possiamo riassumere ogni sezione singolarmente, ottenendo un riassunto complessivo più accurato.
- Analisi del sentiment: L’analisi del sentiment di chunk più brevi e coerenti spesso produce risultati più precisi rispetto all’analisi di un intero documento.
- Estrazione delle informazioni: Il chunking aiuta a individuare entità o frasi specifiche all’interno del testo, migliorando il processo di recupero delle informazioni.
- Classificazione del testo: Suddividere il testo in chunk consente ai classificatori di concentrarsi su unità più piccole e significative dal punto di vista contestuale anziché su interi documenti, il che può migliorare le prestazioni.
- Traduzione automatica: I sistemi di traduzione spesso operano su chunk di testo anziché su singole parole o interi documenti. Il chunking può aiutare a mantenere la coerenza del testo tradotto.
Comprendere questi casi d’uso può aiutare a scegliere la tecnica di chunking più adatta al tuo progetto specifico.
Confronto tra differenti metodi per il chunking semantico
In questa parte dell’articolo, compareremo i metodi popolari per il chunking semantico di testo non strutturato: il tokenizzatore di frasi NLTK, il divisore di testo Langchain, il clustering KMeans e il clustering delle frasi adiacenti in base alla similarità.
Nell’esempio seguente, valuteremo questa tecnica utilizzando un testo estratto da un PDF, elaborandolo in frasi e i loro cluster.
I dati che abbiamo utilizzato erano un PDF esportato dalla pagina Wikipedia del Brasile.
Per estrarre il testo dal PDF e suddividerlo in frasi con NLTK, utilizziamo le seguenti funzioni:
from PyPDF2 import PdfReaderimport nltknltk.download('punkt')# Estrazione del testo dal PDFdef estrai_testo_da_pdf(percorso_file): with open(percorso_file, 'rb') as file: pdf = PdfReader(file) testo = " ".join(pagina.extract_text() for pagina in pdf.pages) return testo# Estrai il testo dal PDF e suddividilo in frasitesto = estrai_testo_da_pdf(percorso_file)In questo modo, otteniamo una stringa testo di lunghezza di 210964 caratteri.
Ecco un esempio del testo di Wikipedia:
esempio = testo[1015:3037]print(esempio)"""=======Output:=======Il Brasile è il quinto paese più grande del mondo per superficie e il settimo più popolato. La sua capitale è Brasília e la sua città più popolata è São Paulo. La federazione è composta dall'unione dei 26 stati e del Distretto Federale. È l'unico paese delle Americhe ad avere il portoghese come lingua ufficiale.[11][12] È una delle nazioni più multiculturali ed etnicamente diverse, grazie a oltre un secolo di immigrazione di massa da tutto il mondo,[13] ed è il paese a maggioranza cattolica romana più popolato. Confinato dall'Oceano Atlantico a est, il Brasile ha una costa di 7.491 chilometri (4.655 mi).[14] Confina con tutti gli altri paesi e territori dell'America del Sud tranne Ecuador e Cile e copre circa la metà della superficie terrestre del continente.[15] Il suo bacino amazzonico comprende una vasta foresta tropicale, sede di una fauna diversificata, di una varietà di sistemi ecologici e di ampie risorse naturali che abbracciano numerosi habitat protetti.[14] Questo patrimonio ambientale unico posiziona il Brasile al primo posto su 17 paesi mega-diversi ed è oggetto di un notevole interesse globale, poiché il degrado ambientale attraverso processi come la deforestazione ha impatti diretti su questioni globali come il cambiamento climatico e la perdita di biodiversità.Il territorio che sarebbe diventato noto come Brasile era abitato da numerose nazioni tribali prima dello sbarco nel 1500 dell'esploratore Pedro Álvares Cabral, che rivendicò la terra scoperta per l'Impero Portoghese. Il Brasile rimase una colonia portoghese fino al 1808, quando la capitale dell'impero fu trasferita da Lisbona a Rio de Janeiro. Nel 1815, la colonia fu elevata al rango di regno con la formazione del Regno Unito di Portogallo, Brasile e Algarve. L'indipendenza fu raggiunta nel 1822 con la creazione dell'Impero del Brasile, uno stato unitario governato da una monarchia costituzionale e un sistema parlamentare. La ratifica della prima costituzione nel 1824 portò alla formazione di un parlamento bicamerale, ora chiamato Congresso Nazionale."""NLTK Sentence Tokenizer
Il Natural Language Toolkit (NLTK) fornisce una funzione utile per dividere il testo in frasi. Questo tokenizer di frasi divide un dato blocco di testo in frasi componenti, che possono quindi essere utilizzate per ulteriori elaborazioni.
Implementazione
Ecco un esempio di utilizzo del tokenizer di frasi NLTK:
import nltknltk.download('punkt')# Divisione del testo in frasidef split_text_into_sentences(testo): frasi = nltk.sent_tokenize(testo) return frasifrasifrase = split_text_into_sentences(testo)Questo restituisce una lista di 2670 frasi estratte dal testo di input con una media di 78 caratteri per frase.
Valutazione del tokenizer di frasi NLTK
Sebbene il tokenizer di frasi NLTK sia un modo semplice ed efficiente per dividere un grande corpo di testo in singole frasi, presenta alcune limitazioni:
- Dependenza dalla lingua: Il tokenizer di frasi NLTK si basa pesantemente sulla lingua del testo. Funziona bene con l’inglese, ma potrebbe non fornire risultati accurati con altre lingue senza una configurazione aggiuntiva.
- Abbreviazioni e punteggiatura: A volte il tokenizer può interpretare erroneamente abbreviazioni o altra punteggiatura alla fine di una frase. Ciò può portare a frammenti di frasi trattati come frasi indipendenti.
- Mancanza di comprensione semantica: Come la maggior parte dei tokenizer, il tokenizer di frasi NLTK non considera la relazione semantica tra le frasi. Di conseguenza, un contesto che si estende su più frasi potrebbe essere perso nel processo di tokenizzazione.
Spacy Sentence Splitter
Spacy, un’altra potente libreria di NLP, fornisce una funzione di tokenizzazione delle frasi che si basa pesantemente su regole linguistiche. È un approccio simile a NLTK.
Implementazione
L’implementazione dello splitter di frasi di Spacy è piuttosto semplice. Ecco come farlo in Python:
import spacynlp = spacy.load('en_core_web_sm')doc = nlp(testo)frasi = list(doc.sents)Questo restituisce una lista di 2336 frasi estratte dal testo di input con una media di 89 caratteri per frase.
Valutazione dello splitter di frasi di Spacy
Lo splitter di frasi di Spacy tende a creare unità di testo più piccole rispetto allo splitter di testo per caratteri di Langchain, in quanto si attiene rigorosamente ai confini delle frasi. Ciò può essere vantaggioso quando sono necessarie unità di testo più piccole per l’analisi.
Tuttavia, come NLTK, le prestazioni di Spacy dipendono dalla qualità del testo di input. Per testo scarsamente punteggiato o strutturato, i confini delle frasi identificate potrebbero non essere sempre accurati.
Ora vedremo come Langchain fornisce un framework per suddividere i dati testuali in unità e lo confrontiamo ulteriormente con NLTK e Spacy.
Langchain Character Text Splitter
Lo splitter di testo per caratteri di Langchain funziona dividendo ricorsivamente il testo in caratteri specifici. È particolarmente utile per il testo generico.
Lo splitter è definito da una lista di caratteri. Cerca di dividere il testo in base a questi caratteri fino a quando i chunk generati soddisfano il criterio di dimensione desiderato. La lista predefinita è [“\n\n”, “\n”, ” “,”“], con l’obiettivo di mantenere insieme paragrafi, frasi e parole il più possibile per mantenere la coerenza semantica.
Implementazione
Considera il seguente esempio, in cui suddividiamo il testo di esempio estratto dal nostro PDF utilizzando questo metodo.
# Inizializza lo splitter di testo con parametri personalizzaticustom_text_splitter = RecursiveCharacterTextSplitter( # Imposta la dimensione personalizzata del chunk chunk_size = 100, chunk_overlap = 20, # Utilizza la lunghezza del testo come misura di dimensione length_function = len,)# Crea i chunktesti = custom_text_splitter.create_documents([esempio])# Stampa i primi due chunkprint(f'### Chunk 1: \n\n{testi[0].page_content}\n\n=====\n')print(f'### Chunk 2: \n\n{testi[1].page_content}\n\n=====')"""=======Output:=======### Chunk 1: Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capital=====### Chunk 2: is Brasília, and its most popul ous city is São Paulo. The federation is composed of the union of====="""Infine, otteniamo 3205 blocchi di testo, rappresentati dalla lista texts. La media di caratteri per ogni blocco è di 65,8 — un po’ meno rispetto alla media di NLTK (79 caratteri).
Cambiare i Parametri e Utilizzare il Separatore ‘\n’:
Per un approccio più personalizzato con il Separatore di Langchain, possiamo modificare i parametri chunk_size e chunk_overlap secondo le nostre esigenze. Inoltre, possiamo specificare un solo carattere (o insieme di caratteri) per l’operazione di separazione, come ad esempio \n. Questo guiderà il separatore a dividere il testo in blocchi solo al cambio di riga.
Consideriamo un esempio in cui impostiamo chunk_size a 300, chunk_overlap a 30 e utilizziamo solo \n come separatore.
# Inizializza il separatore di testo con parametri personalizzaticustom_text_splitter = RecursiveCharacterTextSplitter( # Imposta la dimensione personalizzata dei blocchi chunk_size = 300, chunk_overlap = 30, # Utilizza la lunghezza del testo come misura di dimensione length_function = len, # Utilizza solo "\n\n" come separatore separators = ['\n'])# Crea i blocchi di testocustom_texts = custom_text_splitter.create_documents([sample])# Stampa i primi due blocchiprint(f'### Blocco 1: \n\n{custom_texts[0].page_content}\n\n=====\n')print(f'### Blocco 2: \n\n{custom_texts[1].page_content}\n\n=====')Ora, confrontiamo alcuni risultati ottenuti dai parametri standard con i parametri personalizzati:
# Stampa i blocchi campionatiprint("==== Blocchi campionati dai 'Parametri Standard': ====\n\n")for i, blocco in enumerate(texts): if i < 4: print(f"### Blocco {i+1}: \n{blocco.page_content}\n")print("==== Blocchi campionati dai 'Parametri Personalizzati': ====\n\n")for i, blocco in enumerate(custom_texts): if i < 4: print(f"### Blocco {i+1}: \n{blocco.page_content}\n")"""=======Output:=========== Blocchi campionati dai 'Parametri Standard': ====### Blocco 1: Il Brasile è il quinto paese più grande del mondo per superficie e il settimo più popoloso. La sua capitale### Blocco 2: è Brasilia e la sua città più popolosa è San Paolo. La federazione è composta dall'unione di### Blocco 3: dei 26 stati e del Distretto Federale. È l'unico paese delle Americhe ad avere il portoghese come==== Blocchi campionati dai 'Parametri Personalizzati': ====### Blocco 1: Il Brasile è il quinto paese più grande del mondo per superficie e il settimo più popoloso. La sua capitaleè Brasilia e la sua città più popolosa è San Paolo. La federazione è composta dall'unione di### Blocco 2: dei 26 stati e del Distretto Federale. È l'unico paese delle Americhe ad avere il portoghese come lingua ufficiale.[11][12] È una delle nazioni più multiculturali e etnicamente diverse, grazie a oltre un secolo di### Blocco 3: immigrazione di massa da tutto il mondo,[13] ed è il paese a maggioranza cattolica romana più popoloso. Confina con l'Oceano Atlantico a est, il Brasile ha una costa di 7.491 chilometri (4.655 mi).[14] Confina con tutti gli altri paesi e territori del Sud America, ad eccezione dell'Ecuador e del Cile, e copre approssimativamente la metà del territorio del continente.[15] Il suo bacino amazzonico comprende una vasta foresta tropicale, habitat di diverse"""Possiamo già notare che questi parametri personalizzati generano blocchi molto più grandi e quindi conservano più contenuto rispetto al set di parametri predefinito.
Valutazione del Separatore di Testo Carattere Langchain
Dopo aver diviso il testo in blocchi utilizzando parametri diversi, otteniamo due liste di blocchi: texts e custom_texts, contenenti rispettivamente 3205 e 1404 blocchi di testo. Ora, tracciamo la distribuzione delle lunghezze dei blocchi per questi due scenari per comprendere meglio l’impatto del cambiamento dei parametri.

In questo istogramma, l’asse x rappresenta le lunghezze degli chunk, mentre l’asse y rappresenta la frequenza di ogni lunghezza. Le barre blu rappresentano la distribuzione delle lunghezze degli chunk per i parametri originali, mentre le barre arancioni rappresentano la distribuzione dei parametri personalizzati. Confrontando queste due distribuzioni, possiamo vedere come i cambiamenti nei parametri abbiano influenzato le lunghezze degli chunk risultanti.
Ricorda, la distribuzione ideale dipende dai requisiti specifici del tuo compito di elaborazione del testo. Potresti voler avere chunk più piccoli e numerosi se stai affrontando un’analisi dettagliata o chunk più grandi e meno numerosi per un’analisi semantica più ampia.
Langchain Character Text Splitter vs. NLTK e Spacy
In precedenza, abbiamo generato 3205 chunk utilizzando il separatore di testo Langchain con i suoi parametri predefiniti. D’altra parte, il Tokenizzatore di Frasi NLTK ha suddiviso lo stesso testo in un totale di 2670 frasi.
Per ottenere una comprensione più intuitiva della differenza tra questi metodi, possiamo visualizzare la distribuzione delle lunghezze degli chunk. Il grafico seguente mostra le densità delle lunghezze degli chunk per ciascun metodo, consentendoci di vedere come le lunghezze sono distribuite e dove si trovano la maggior parte delle lunghezze.

Dalla Figura 1, possiamo vedere che il separatore di Langchain produce una densità di lunghezze di cluster molto più concisa e tende ad avere più cluster più lunghi, mentre NLTK e Spacy sembrano produrre risultati molto simili in termini di lunghezza del cluster, preferendo frasi più piccole ma con molti outliers con lunghezze che possono arrivare fino a 1400 caratteri – e una tendenza alla diminuzione della lunghezza.
Clustering KMeans
Il Clustering di Frasi è una tecnica che prevede la suddivisione delle frasi in gruppi in base alla loro somiglianza semantica. Utilizzando incorporamenti di frasi e un algoritmo di clustering come K-means, possiamo implementare il Clustering di Frasi.
Implementazione
Ecco un semplice esempio di codice utilizzando la libreria Python sentence-transformers per generare incorporamenti di frasi e scikit-learn per il clustering K-means:
from sentence_transformers import SentenceTransformerfrom sklearn.cluster import KMeans# Carica il modello Sentence Transformermodel = SentenceTransformer('all-MiniLM-L6-v2')# Definisci una lista di frasi (i tuoi dati di testo)sentences = ["Questa è una frase di esempio.", "Un'altra frase va qui.", "..."]# Genera incorporamenti per le frasiembeddings = model.encode(sentences)# Scegli un numero appropriato di cluster (qui scegliamo 5 come esempio)num_clusters = 3# Esegui il clustering K-meanskmeans = KMeans(n_clusters=num_clusters)clusters = kmeans.fit_predict(embeddings)Puoi vedere qui che i passaggi per il clustering di una lista di frasi sono:
- Carica un modello Sentence Transformer. In questo caso, stiamo usando
all-MiniLM-L6-v2da sentence-transformers/all-MiniLM-L6-v2 in HuggingFace. - Definisci le tue frasi e genera i loro incorporamenti con il metodo
encode()del modello. - Quindi definisci la tua tecnica di clustering e il numero di cluster (qui stiamo usando KMeans con 3 cluster) e infine adattalo al dataset.
Valutazione del Clustering KMeans
E infine tracciamo una WordCloud per ogni cluster.
from wordcloud import WordCloudimport matplotlib.pyplot as pltfrom nltk.corpus import stopwordsfrom nltk.tokenize import word_tokenizeimport stringnltk.download('stopwords')# Definisci una lista di stop wordstop_words = set(stopwords.words('italian'))# Definisci una funzione per pulire le frasidef clean_sentence(sentence): # Tokenizza la frase tokens = word_tokenize(sentence) # Converti in minuscolo tokens = [w.lower() for w in tokens] # Rimuovi la punteggiatura table = str.maketrans('', '', string.punctuation) stripped = [w.translate(table) for w in tokens] # Rimuovi i token non alfabetici words = [word for word in stripped if word.isalpha()] # Filtra le stop word words = [w for w in words if not w in stop_words] return words# Calcola e stampa le Word Cloud per ogni clusterfor i in range(num_clusters): cluster_sentences = [sentences[j] for j in range(len(sentences)) if clusters[j] == i] cleaned_sentences = [' '.join(clean_sentence(s)) for s in cluster_sentences] text = ' '.join(cleaned_sentences) wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(text) plt.figure() plt.imshow(wordcloud, interpolation="bilinear") plt.axis("off") plt.title(f"Cluster {i}") plt.show()Di seguito abbiamo i grafici WordCloud per i cluster generati:

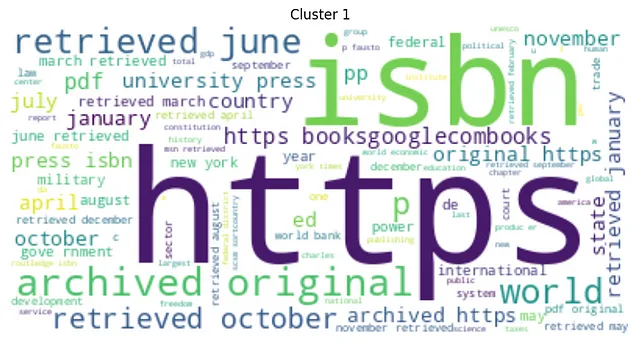

Nella nostra analisi del word cloud per il clustering KMeans, è evidente che ogni cluster si differenzia in modo distintivo in base alla semantica delle sue parole più frequenti. Ciò dimostra una forte differenziazione semantica tra i cluster. Inoltre, si osserva una notevole variazione nelle dimensioni dei cluster, indicando una disparità significativa nel numero di sequenze che compongono ciascun cluster.
Limitazioni del Clustering KMeans
Il clustering delle frasi, sebbene utile, ha alcune limitazioni degne di nota. Le principali limitazioni includono:
- Perdita dell’Ordine delle Frasi: Il clustering delle frasi non mantiene la sequenza originale delle frasi, il che potrebbe distorcere il flusso naturale della narrazione. ** Questo è molto importante**
- Efficienza Computazionale: KMeans può richiedere molto tempo e risorse computazionali, specialmente con corpora di testo di grandi dimensioni o quando si lavora con un numero maggiore di cluster. Questo può essere un importante svantaggio per le applicazioni in tempo reale o per la gestione di big data.
Clustering delle Frasi Adiacenti
Per superare alcune delle limitazioni del clustering KMeans, in particolare la perdita dell’ordine delle frasi, un approccio alternativo potrebbe essere il clustering delle frasi adiacenti in base alla loro similarità semantica. La premessa fondamentale di questo approccio è che due frasi che appaiono consecutivamente in un testo sono più probabilmente correlate semanticamente rispetto a due frasi che sono più distanti.
Implementazione
Ecco un’implementazione estesa di questa euristica utilizzando le frasi di Spacy come input:
import numpy as npimport spacy# Carica il modello Spacynlp = spacy.load('en_core_web_sm')def process(text): doc = nlp(text) sents = list(doc.sents) vecs = np.stack([sent.vector / sent.vector_norm for sent in sents]) return sents, vecsdef cluster_text(sents, vecs, threshold): clusters = [[0]] for i in range(1, len(sents)): if np.dot(vecs[i], vecs[i-1]) < threshold: clusters.append([]) clusters[-1].append(i) return clustersdef clean_text(text): # Aggiungi qui il tuo processo di pulizia del testo return text# Inizializza la lista delle lunghezze dei cluster e la lista dei testi finaliclus_lens = []testi_finali = []# Processa il testothreshold = 0.3sents, vecs = process(testo)# Clustra le frasiclusters = cluster_text(sents, vecs, threshold)for cluster in clusters: cluster_txt = clean_text(' '.join([sents[i].text for i in cluster])) cluster_len = len(cluster_txt) # Controlla se il cluster è troppo corto if cluster_len < 60: continue # Controlla se il cluster è troppo lungo elif cluster_len > 3000: threshold = 0.6 sents_div, vecs_div = process(cluster_txt) reclusters = cluster_text(sents_div, vecs_div, threshold) for subcluster in reclusters: div_txt = clean_text(' '.join([sents_div[i].text for i in subcluster])) div_len = len(div_txt) if div_len < 60 or div_len > 3000: continue clusters_lens.append(div_len) final_texts.append(div_txt) else: clusters_lens.append(cluster_len) final_texts.append(cluster_txt)Cose chiave da questo codice:
- Elaborazione del testo: Ogni frammento di testo viene passato alla funzione
process. Questa funzione utilizza la libreria SpaCy per creare rappresentazioni semantiche di ogni frase nel frammento di testo. - Creazione di cluster: La funzione
cluster_textforma cluster di frasi basandosi sulla similarità coseno delle loro rappresentazioni. Se la similarità coseno è inferiore a una soglia specificata, inizia un nuovo cluster. - Controllo della lunghezza: Il codice verifica quindi la lunghezza di ogni cluster. Se un cluster è troppo corto (meno di 60 caratteri) o troppo lungo (più di 3000 caratteri), la soglia viene regolata e il processo viene ripetuto per quel cluster specifico fino a ottenere una lunghezza accettabile.
Diamo un’occhiata ad alcuni dei frammenti di output di questo approccio e confrontiamoli con Langchain Splitter:
==== Frammenti di esempio da 'Langchain Splitter con parametri personalizzati': ====### Frammento 1: Il Brasile è il quinto paese più grande del mondo per superficie e il settimo più popoloso. La sua capitale è Brasilia e la sua città più popolosa è San Paolo. La federazione è composta dall'unione dei 26### Frammento 2: stati e dal Distretto Federale. È l'unico paese delle Americhe ad avere il portoghese come lingua ufficiale.[11][12] È una delle nazioni più multiculturali e etnicamente diverse, a causa di oltre un secolo di==== Frammenti di esempio da 'Clustering di frasi adiacenti': ====### Frammento 1: Il Brasile è il quinto paese più grande del mondo per superficie e il settimo più popoloso. La sua capitale è Brasilia e la sua città più popolosa è San Paolo.### Frammento 2: La federazione è composta dall'unione dei 26 stati e dal Distretto Federale. È l'unico paese delle Americhe ad avere il portoghese come lingua ufficiale.[11][12]Ottimo, ora confrontiamo la distribuzione delle lunghezze dei frammenti di final_texts (dall’approccio di clustering delle sequenze adiacenti) con le distribuzioni di Langchain Character Text Splitter e NLTK Sentence Tokenizer. Per fare ciò, dobbiamo prima calcolare le lunghezze dei frammenti in final_texts:
final_texts_lengths = [len(chunk) for chunk in final_texts]Ora possiamo tracciare le distribuzioni dei tre metodi:
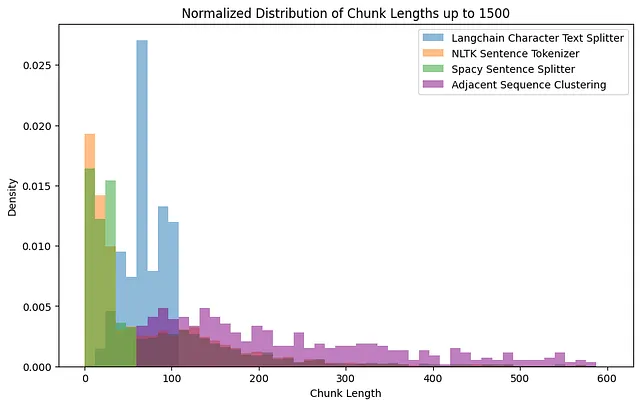
Dalla Figura 6, possiamo dedurre che il Langchain splitter, utilizzando la sua dimensione predefinita dei frammenti, crea una distribuzione uniforme, implicando lunghezze dei frammenti consistenti.
Il Spacy Sentence Splitter e il NLTK Sentence Tokenizer, d’altra parte, sembrano preferire frasi più corte, anche se con molti valori anomali più grandi, indicando la loro dipendenza da segnali linguistici per determinare le divisioni e potenzialmente produrre frammenti di dimensioni irregolari.
Infine, l’approccio di Clustering delle sequenze adiacenti personalizzato, che raggruppa basandosi sulla similarità semantica, mostra una distribuzione più varia. Questo potrebbe indicare un approccio più sensibile al contesto, mantenendo la coerenza del contenuto all’interno dei frammenti consentendo al contempo una maggiore flessibilità nelle dimensioni.
Valutazione dell’approccio di Clustering delle Sequenze adiacenti
L’approccio di Clustering delle sequenze adiacenti porta benefici unici:
- Coerenza contestuale: Genera frammenti tematicamente coerenti considerando coerenza semantica e contestuale.
- Flessibilità: Bilancia la preservazione del contesto e l’efficienza computazionale, fornendo dimensioni di frammenti regolabili.
- Regolazione della soglia: Consente agli utenti di adattare il processo di suddivisione in base alle proprie esigenze, regolando la soglia di similarità.
- Preservazione della sequenza: Conserva l’ordine originale delle frasi nel testo, fondamentale per modelli di linguaggio sequenziali e compiti in cui l’ordine del testo è importante.
Confronto dei metodi di suddivisione del testo: Sommario delle Insight
Langchain Character Text Splitter
Questo metodo fornisce lunghezze di chunk coerenti, garantendo una distribuzione uniforme. Ciò potrebbe essere vantaggioso quando è necessaria una dimensione standard per l’elaborazione o l’analisi successiva. L’approccio è meno sensibile alla struttura linguistica specifica del testo, focalizzandosi maggiormente sulla produzione di chunk di una lunghezza di caratteri predefinita.
NLTK Sentence Tokenizer e Spacy Sentence Splitter
Questi approcci mostrano una preferenza per frasi più brevi ma includono molti valori anomali più grandi. Se da un lato ciò può portare a chunk linguisticamente coerenti, dall’altro può comportare un’alta variabilità nelle dimensioni dei chunk.
Questi metodi possono fornire buoni risultati che possono essere utilizzati come input per compiti successivi.
Clustering delle sequenze adiacenti
Questo metodo genera una distribuzione più varia, indicativa del suo approccio sensibile al contesto. Clustering basato sulla similarità semantica, garantisce che il contenuto all’interno di ogni chunk sia coerente consentendo allo stesso tempo una flessibilità nella dimensione dei chunk. Questo metodo può essere vantaggioso quando è importante preservare la continuità semantica dei dati testuali.
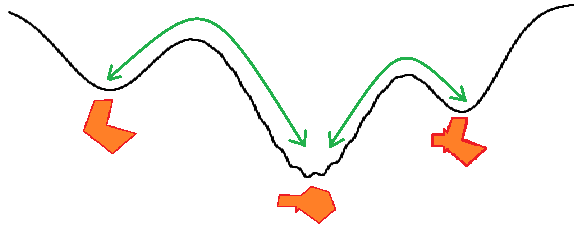
Per una rappresentazione più visuale e astratta (o sciocca), diamo un’occhiata alla Figura 7 qui sotto e cerchiamo di capire quale tipo di “taglio” di ananas rappresenterebbe meglio gli approcci discussi:
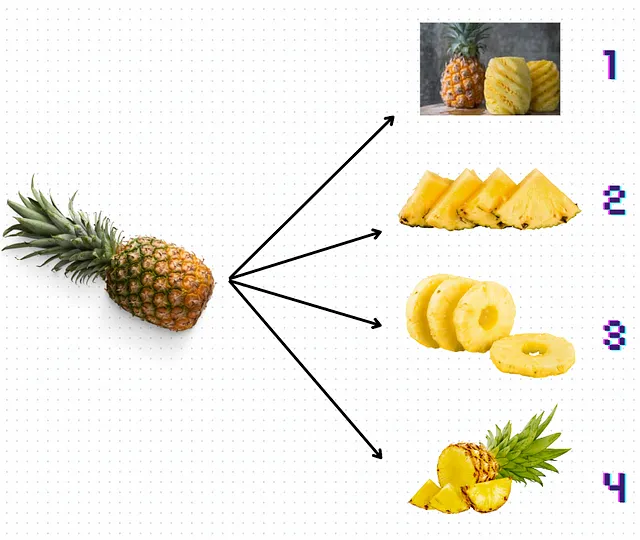
Elenchiamoli in ordine:
- Il taglio numero 1 rappresenterebbe un approccio basato su regole, in cui è possibile “sfilare” il testo “spazzatura” desiderato in base a filtri o espressioni regolari. Molto lavoro da fare per l’intero ananas, poiché conserva anche molti valori anomali con una dimensione di contesto molto più grande.
- Langchain sarebbe simile al taglio numero 2. Pezzi molto simili in termini di dimensione ma non contengono l’intero contesto desiderato (è un triangolo, quindi potrebbe essere anche un melone).
- Il taglio numero 3 è sicuramente KMeans. Potresti anche raggruppare solo ciò che ha senso per te, la parte più succosa, ma non otterrai il suo nucleo. Senza di esso, i chunk perdono tutta la struttura e il significato. Penso che ci voglia molto lavoro per farlo… soprattutto per ananas più grandi.
- Infine, il taglio numero 4 illustra il metodo di Clustering delle Frasi Adiacenti. La dimensione dei chunk può variare, ma spesso mantengono informazioni di contesto, simili a pezzi irregolari di ananas che indicano comunque la struttura generale del frutto.
TL;DR: In questo articolo, abbiamo confrontato tre metodi di chunking del testo e i loro vantaggi unici. Langchain offre dimensioni di chunk coerenti, ma la struttura linguistica passa in secondo piano. NLTK e Spacy forniscono chunk linguisticamente coerenti, ma la dimensione varia considerevolmente. Il Clustering delle Sequenze Adiacenti si basa sulla similarità semantica, fornendo coerenza del contenuto con dimensioni di chunk flessibili. Alla fine, la scelta ottimale dipende dalle tue esigenze specifiche, tra cui coerenza linguistica, uniformità delle dimensioni dei chunk e potenza di calcolo disponibile.
Grazie per aver letto!
- Seguimi su Linkedin!