Un’introduzione pratica agli LLM
Introduzione pratica LLM
3 livelli di utilizzo delle LLM nella pratica
Questo è il primo articolo di una serie sull’utilizzo delle Large Language Models (LLM) nella pratica. Qui fornirò una introduzione alle LLM e presenterò 3 livelli di lavoro con esse. Gli articoli futuri esploreranno gli aspetti pratici delle LLM, come utilizzare l’API pubblica di OpenAI, la libreria Python Hugging Face Transformers, come addestrare LLM e come costruire una LLM da zero.
Cos’è una LLM?
LLM è l’abbreviazione di Large Language Model, che è una recente innovazione nell’ambito dell’IA e dell’apprendimento automatico. Questo nuovo e potente tipo di IA è diventato virale nel dicembre 2022 con il rilascio di ChatGPT.
Per coloro che vivono al di fuori del mondo del buzz dell’IA e dei cicli di notizie tecnologiche, ChatGPT è un’interfaccia di chat che funziona su una LLM chiamata GPT-3 (ora aggiornata a GPT-3.5 o GPT-4 al momento della scrittura di questo articolo).
Se hai utilizzato ChatGPT, è evidente che questa non è la tua tradizionale chatbot di AOL Instant Messenger o l’assistenza clienti della tua carta di credito.
- 3 Concetti Fondamentali sulle Strutture Dati in Python
- Sfruttare il potere dei grafi di conoscenza arricchire un LLM con dati strutturati
- Valutazione dei modelli di incremento
Questa è diversa.
Cosa rende una LLM “grande”?
Quando ho sentito il termine “Large Language Model”, una delle mie prime domande è stata: in cosa differisce da un “modello di linguaggio” “regolare”?
Un modello di linguaggio è più generico di un grande modello di linguaggio. Proprio come tutti i quadrati sono rettangoli, ma non tutti i rettangoli sono quadrati. Tutte le LLM sono modelli di linguaggio, ma non tutti i modelli di linguaggio sono LLM.
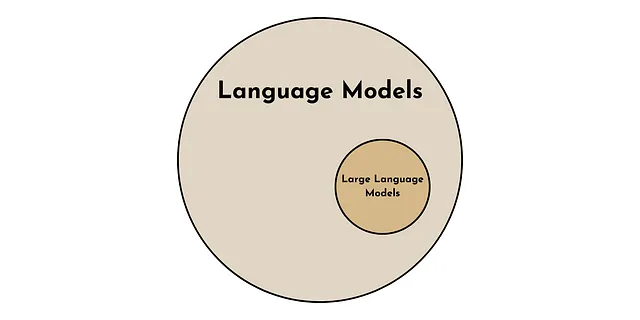
Ok, quindi le LLM sono un tipo speciale di modello di linguaggio, ma cosa le rende speciali?
Ci sono 2 proprietà chiave che distinguono le LLM dagli altri modelli di linguaggio. Una è quantitativa, l’altra è qualitativa.
- Quantitativamente, ciò che distingue una LLM è il numero di parametri utilizzati nel modello. Le attuali LLM hanno un ordine di grandezza di 10-100 miliardi di parametri [1].
- Qualitativamente, succede qualcosa di notevole quando un modello di linguaggio diventa “grande”. Mostra cosiddette proprietà emergenti, come l’apprendimento senza supervisione [1]. Queste sono proprietà che sembrano apparire improvvisamente quando un modello di linguaggio raggiunge una dimensione sufficientemente grande.
Apprendimento senza supervisione
La grande innovazione di GPT-3 (e di altre LLM) è che è in grado di effettuare apprendimento senza supervisione in una vasta gamma di contesti [2]. Ciò significa che ChatGPT può svolgere un compito anche se non è stato addestrato esplicitamente per farlo.
Anche se potrebbe sembrare niente di speciale per noi esseri umani altamente evoluti, questa capacità di apprendimento senza supervisione contrasta nettamente con il paradigma precedente dell’apprendimento automatico.
In precedenza, un modello doveva essere addestrato esplicitamente sul compito che si proponeva di svolgere per ottenere buone prestazioni. Ciò poteva richiedere da 1.000 a 1 milione di esempi di addestramento pre-etichettati.
Ad esempio, se volessi che un computer effettuasse la traduzione di testi, l’analisi del sentiment e l’identificazione di errori grammaticali, ognuna di queste attività richiederebbe un modello specializzato addestrato su un ampio set di esempi etichettati. Ora, però, LLM può fare tutte queste cose senza addestramento esplicito.
Come funzionano le LLM?
Il compito principale utilizzato per addestrare la maggior parte degli LLM di ultima generazione è la previsione delle parole. In altre parole, dato una sequenza di parole, qual è la distribuzione di probabilità della prossima parola?
Ad esempio, dato la sequenza “Ascolta il tuo ____,” le parole più probabili potrebbero essere: cuore, intestino, corpo, genitori, nonna, ecc. Questo potrebbe apparire come la distribuzione di probabilità mostrata di seguito.
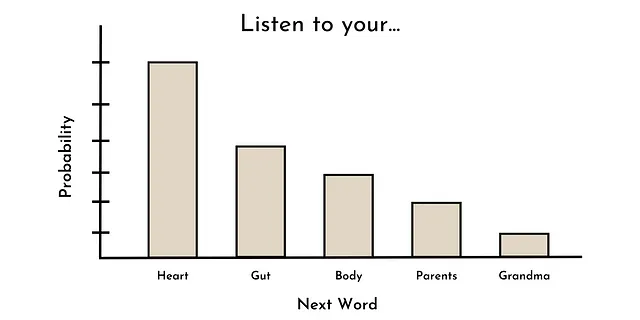
È interessante notare che questo è lo stesso modo in cui molti modelli di linguaggio (non di grandi dimensioni) sono stati addestrati in passato (ad esempio GPT-1) [3]. Tuttavia, per qualche motivo, quando i modelli di linguaggio superano una certa dimensione (ad esempio ~10B di parametri), queste abilità (emergenti), come l’apprendimento zero-shot, possono iniziare a manifestarsi [1].
Anche se non esiste una risposta chiara su perché questo accada (solo speculazioni per ora), è chiaro che gli LLM sono una tecnologia potente con innumerevoli casi d’uso potenziali.
3 Livelli di Utilizzo degli LLM
Ora passiamo a come utilizzare questa potente tecnologia nella pratica. Sebbene ci siano innumerevoli casi d’uso potenziali per gli LLM, qui li categorizzo in 3 livelli in base alla conoscenza tecnica richiesta e alle risorse computazionali necessarie. Iniziamo con il più accessibile.
Livello 1: Progettazione di Prompt
Il primo livello di utilizzo degli LLM nella pratica è la progettazione di prompt, che definisco come qualsiasi utilizzo di un LLM così com’è, ovvero senza modificare i parametri del modello. Anche se molte persone tecnicamente inclini sembrano disprezzare l’idea della progettazione di prompt, questa è il modo più accessibile per utilizzare gli LLM nella pratica (sia tecnicamente che economicamente).
Ci sono 2 modi principali per creare i prompt: il Modo Semplice e il Modo Meno Semplice.
Modo Semplice: ChatGPT (o un altro UI LLM conveniente) — Il vantaggio chiave di questo metodo è la comodità. Strumenti come ChatGPT forniscono un modo intuitivo, gratuito e senza codice per utilizzare un LLM (non può essere più semplice di così).
Tuttavia, la comodità spesso ha un costo. In questo caso, ci sono 2 svantaggi principali in questo approccio. Il primo è la mancanza di funzionalità. Ad esempio, ChatGPT non consente agli utenti di personalizzare facilmente i parametri di input del modello (ad esempio temperatura o lunghezza massima della risposta), che sono valori che modulano le uscite degli LLM. Il secondo, le interazioni con l’interfaccia utente di ChatGPT non possono essere facilmente automatizzate e quindi applicate a casi d’uso su larga scala.
Anche se questi svantaggi potrebbero essere eliminatori per alcuni casi d’uso, entrambi possono essere ridotti se portiamo la progettazione di prompt un passo avanti.
Modo Meno Semplice: Interagire direttamente con un LLM — Possiamo superare alcuni dei svantaggi di ChatGPT interagendo direttamente con un LLM tramite interfacce programmatiche. Questo potrebbe essere tramite API pubbliche (ad esempio l’API di OpenAI) o eseguendo un LLM localmente (utilizzando librerie come Transformers).
Sebbene questo modo di creare prompt sia meno comodo (poiché richiede conoscenze di programmazione e possibili costi delle API), offre un modo personalizzabile, flessibile e scalabile per utilizzare gli LLM nella pratica. Gli articoli futuri di questa serie discuteranno sia modi a pagamento che gratuiti per realizzare questo tipo di progettazione di prompt.
Anche se la progettazione di prompt (come definita qui) può gestire la maggior parte delle possibili applicazioni degli LLM, affidarsi a un modello generico così com’è può comportare prestazioni subottimali per casi d’uso specifici. Per queste situazioni, possiamo passare al livello successivo di utilizzo degli LLM.
Livello 2: Ottimizzazione del Modello
Il secondo livello di utilizzo di un LLM è l’ottimizzazione del modello, che definisco come la modifica di un LLM esistente per un particolare caso d’uso, cambiando almeno 1 parametro (interno) del modello, ovvero i pesi e i bias. In questa categoria, includerò anche il transfer learning, ovvero l’utilizzo di una parte di un LLM esistente per sviluppare un altro modello.
Il fine-tuning consiste tipicamente in 2 passaggi. Passaggio 1: Ottenere un LLM pre-addestrato. Passaggio 2: Aggiornare i parametri del modello per un compito specifico dati (tipicamente migliaia di) esempi etichettati di alta qualità.
I parametri del modello sono ciò che definisce la rappresentazione interna del testo di input del LLM. Così, regolando questi parametri per un compito particolare, le rappresentazioni interne diventano ottimizzate per il compito di fine-tuning (o almeno questa è l’idea).
Questa è un’approccio potente allo sviluppo del modello perché un numero relativamente piccolo di esempi e risorse computazionali possono produrre prestazioni eccezionali del modello.
Il lato negativo, tuttavia, è che richiede significativamente più competenze tecniche e risorse computazionali rispetto all’ingegneria dell’input. In un futuro articolo, cercherò di mitigare questo lato negativo esaminando le tecniche di fine-tuning e condividendo esempi di codice Python.
Sebbene l’ingegneria dell’input e il fine-tuning del modello possano gestire probabilmente il 99% delle applicazioni LLM, ci sono casi in cui è necessario andare ancora oltre.
Livello 3: Crea il tuo LLM
Il terzo e ultimo modo per utilizzare un LLM nella pratica è creare il proprio. In termini di parametri del modello, qui si creano tutti i parametri del modello da zero.
Un LLM è principalmente un prodotto dei suoi dati di addestramento. Pertanto, per alcune applicazioni, potrebbe essere necessario curare corpora di testo personalizzati e di alta qualità per l’addestramento del modello, ad esempio un corpus di ricerca medica per lo sviluppo di un’applicazione clinica.
Il più grande vantaggio di questo approccio è che è possibile personalizzare completamente il LLM per il proprio caso d’uso specifico. Questa è la massima flessibilità. Tuttavia, come spesso accade, la flessibilità ha un costo in termini di comodità.
Poiché la chiave delle prestazioni del LLM è la scala, la creazione di un LLM da zero richiede enormi risorse computazionali e competenze tecniche. In altre parole, questo non sarà un progetto da svolgere da soli in un fine settimana, ma piuttosto un lavoro di squadra che richiede mesi, se non anni, con un budget di 7-8F.
Tuttavia, in un futuro articolo di questa serie, esploreremo le tecniche popolari per lo sviluppo di LLM da zero.
Conclusioni
Nonostante l’esagerazione sui LLM in questi giorni, sono un’innovazione potente nel campo dell’IA. Qui ho fornito un’introduzione su cosa sono i LLM e come possono essere utilizzati nella pratica. Il prossimo articolo di questa serie offrirà una guida per principianti all’API Python di OpenAI per avviare il tuo prossimo caso d’uso LLM.
Risorse
Contatti: Il mio sito web | Prenota una chiamata | Chiedimi qualcosa
Social: YouTube 🎥 | LinkedIn | Twitter
Supporto: Diventa un membro ⭐️ | Offrimi un caffè ☕️
The Data Entrepreneurs
Una comunità per imprenditori nello spazio dei dati. 👉 Unisciti a Discord!
VoAGI.com
[1] Survey di Large Language Models. arXiv:2303.18223 [cs.CL]
[2] GPT-3 Paper. arXiv:2005.14165 [cs.CL]
[3] Radford, A., & Narasimhan, K. (2018). Miglioramento della comprensione del linguaggio tramite Pre-Training Generativo. (GPT-1 Paper)