Valutazione dei modelli di incremento
Evaluation of Increment Models
DATA SCIENCE CAUSALE
Come confrontare e selezionare il miglior modello di uplift
Una delle applicazioni più diffuse dell’inferenza causale nell’industria è la modellazione di uplift, ossia l’estimazione degli effetti condizionali medi del trattamento.
Quando si stima l’effetto causale di un trattamento (un farmaco, un annuncio, un prodotto, …) su un risultato di interesse (una malattia, il fatturato aziendale, la soddisfazione del cliente, …), spesso siamo interessati non solo a capire se il trattamento funziona in media, ma vorremmo sapere per quali soggetti (pazienti, utenti, clienti, …) funziona meglio o peggio.
L’estimazione degli effetti incrementali eterogenei, o uplift, è un passaggio intermedio essenziale per migliorare il targeting della politica di interesse. Ad esempio, potremmo voler avvertire determinate persone che sono più inclini a sperimentare effetti collaterali da un farmaco o mostrare un annuncio solo a un gruppo specifico di clienti.
Sebbene esistano molti metodi per modellare l’uplift, non è sempre chiaro quale utilizzare in un’applicazione specifica. In modo cruciale, a causa del problema fondamentale dell’inferenza causale, l’obiettivo di interesse, l’uplift, non viene mai osservato e quindi non possiamo convalidare i nostri stimatori come faremmo con un algoritmo di previsione di machine learning. Non possiamo creare un set di convalida e scegliere il modello con le migliori prestazioni poiché non abbiamo verità assoluta, nemmeno nel set di convalida, e nemmeno se abbiamo eseguito un esperimento casuale.
- Intelligenza Artificiale e Libero Arbitrio
- Costruire un piccolo modello di linguaggio (SLM) con l’algoritmo Jaro-Winkler per migliorare e potenziare gli errori di ortografia
- Attribuzione del modello di catena di Markov
Cosa possiamo fare allora? In questo articolo, cerco di coprire i metodi più popolari utilizzati per valutare i modelli di uplift. Se non sei familiare con i modelli di uplift, ti suggerisco di leggere prima il mio articolo introduttivo.
Comprensione dei Meta Learners
Modifica descrizione
towardsdatascience.com
Uplift ed Email Promozionali
Immagina di lavorare nel dipartimento marketing di un’azienda produttrice interessata a migliorare la nostra campagna di email marketing. Storicamente, abbiamo inviato principalmente email ai nuovi clienti. Tuttavia, ora vorremmo adottare un approccio basato sui dati e mirare ai clienti per i quali l’email ha il maggior impatto positivo sul fatturato. Questo impatto viene chiamato anche uplift o incremento.
Diamo un’occhiata ai dati che abbiamo a disposizione. Importo il processo di generazione dei dati dgp_promotional_email() da src.dgp. Importo anche alcune funzioni di tracciamento e librerie da src.utils.
from src.utils import *from src.dgp import dgp_promotional_emaildgp = dgp_promotional_email(n=500)df = dgp.generate_data()df.head()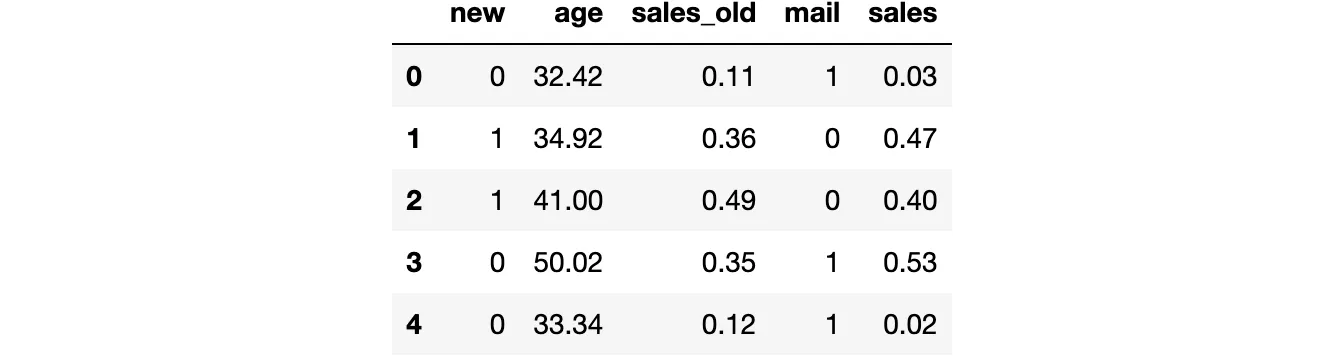
Abbiamo informazioni su 500 clienti, per i quali osserviamo se sono clienti nuovi, la loro età, le vendite generate prima della campagna di email (vendite_precedenti), se hanno ricevuto l’email e le vendite dopo la campagna di email.
Il risultato di interesse è vendite, che denotiamo con la lettera Y. Il trattamento o la politica che vorremmo migliorare è la campagna di email, che denotiamo con la lettera W. Chiamiamo tutte le altre variabili variabili confondenti o variabili di controllo e le denotiamo con X.
Y = 'vendite'W = 'email'X = ['età', 'vendite_precedenti', 'nuovi']Il Grafo Diretto Aciclico (DAG) che rappresenta le relazioni causali tra le variabili è il seguente. La relazione causale di interesse è rappresentata in verde.
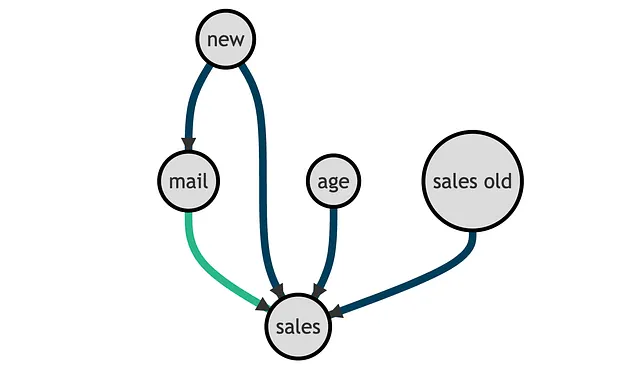
Dal DAG, vediamo che l’indicatore del cliente new è un confondente e deve essere controllato al fine di identificare l’effetto di mail su sales. invece, age e sales_old non sono essenziali per la stima ma potrebbero essere utili per l’identificazione. Per ulteriori informazioni su DAG e variabili di controllo, puoi consultare il mio articolo introduttivo.
DAG e Variabili di Controllo
Modifica descrizione
towardsdatascience.com
Lo scopo della modellazione del uplift è recuperare gli Effetti Individuali del Trattamento (ITE) τᵢ, cioè l’effetto incrementale su sales dell’invio della mail promozionale. Possiamo esprimere l’ITE come la differenza tra due quantità ipotetiche: l’outcome potenziale del cliente se avesse ricevuto l’email, Yᵢ⁽¹⁾, meno l’outcome potenziale del cliente se non avesse ricevuto l’email, Yᵢ⁽⁰⁾.
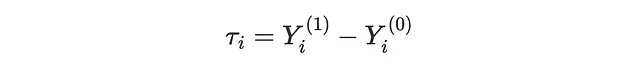
Si noti che per ogni cliente, osserviamo solo uno dei due risultati realizzati, a seconda che abbiano effettivamente ricevuto la mail o meno. Pertanto, l’ITE è intrinsecamente non osservabile. Ciò che può essere stimato invece è l’ Effetto Medio Condizionale del Trattamento (CATE), cioè l’effetto individuale atteso τᵢ, condizionato alle covariate X. Ad esempio, l’effetto medio della mail su sales per i clienti più anziani (age > 50).
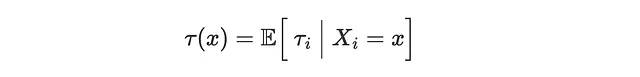
Per poter recuperare il CATE, è necessario fare tre assunzioni.
- Non confondibilità: Y⁽⁰⁾, Y⁽¹⁾ ⊥ W | X
- Sovrapposizione: 0 < e(X) < 1
- Consistenza: Y = W ⋅ Y⁽¹⁾ + (1−W) ⋅ Y⁽⁰⁾
Dove e(X) è lo score della propensione, cioè la probabilità attesa di essere trattati, condizionata alle covariate X.
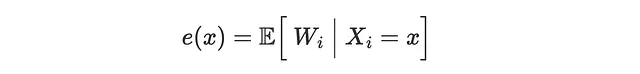
In seguito, utilizzeremo metodi di apprendimento automatico per stimare il CATE τ(x), gli score di propensione e la funzione di aspettazione condizionale (CEF) dell’outcome, μ(x)
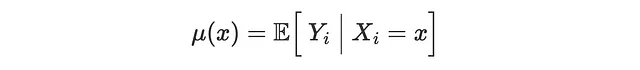
Utilizziamo algoritmi di regressione Random Forest per modellare il CATE e l’outcome CEF, mentre utilizziamo la regressione logistica per modellare il propensity score.
from sklearn.ensemble import RandomForestRegressorfrom sklearn.linear_model import LogisticRegressionCVmodel_tau = RandomForestRegressor(max_depth=2)model_y = RandomForestRegressor(max_depth=2)model_e = LogisticRegressionCV()In questo articolo, non ottimizziamo i modelli di machine learning sottostanti, tuttavia l’ottimizzazione è fortemente raccomandata per migliorare l’accuratezza dei modelli di uplift (ad esempio, con librerie di auto-ml come FLAML).
Modelli di Uplift
Esistono molti metodi per modellare l’uplift o, in altre parole, per stimare gli Effetti Medi di Trattamento Condizionale (CATE). Poiché l’obiettivo di questo articolo è confrontare i metodi per valutare i modelli di uplift, non spiegheremo i metodi in dettaglio. Per una gentile introduzione, puoi consultare il mio articolo introduttivo sui meta-learner.
I modelli che considereremo sono i seguenti:
- S-learner o single-learner, introdotto da Kunzel, Sekhon, Bickel, Yu (2017)
- T-learner o two-learner, introdotto da Kunzel, Sekhon, Bickel, Yu (2017)
- X-learner o cross-learner, introdotto da Kunzel, Sekhon, Bickel, Yu (2017)
- R-learner o Robinson-learner introdotto da Nie, Wager (2017)
- DR-learner o doubly-robust-learner, introdotto da Kennedy (2022)
Importiamo tutti i modelli dalla libreria econml di Microsoft.
from src.learners_utils import *from econml.metalearners import SLearner, TLearner, XLearnerfrom econml.dml import NonParamDMLfrom econml.dr import DRLearnerS_learner = SLearner(overall_model=model_y)T_learner = TLearner(models=clone(model_y))X_learner = XLearner(models=model_y, propensity_model=model_e, cate_models=model_tau)R_learner = NonParamDML(model_y=model_y, model_t=model_e, model_final=model_tau, discrete_treatment=True)DR_learner = DRLearner(model_regression=model_y, model_propensity=model_e, model_final=model_tau)Facciamo fit() dei modelli sui dati, specificando la variabile di outcome Y, la variabile di trattamento W e le covariate X.
names = ['SL', 'TL', 'XL', 'RL', 'DRL']learners = [S_learner, T_learner, X_learner, R_learner, DR_learner]for learner in learners: learner.fit(df[Y], df[W], X=df[X])Siamo pronti per valutare i modelli! Quale modello dovremmo scegliere?
Funzioni di Perdita Oracle
Il problema principale nell’evaluare i modelli di uplift è che, anche con un set di validazione e anche con un esperimento randomizzato o un test AB, non osserviamo la nostra metrica di interesse: gli Effetti di Trattamento Individuali. Infatti, osserviamo solo gli outcome realizzati, Yᵢ⁽⁰⁾ per i clienti non trattati e Yᵢ⁽¹⁾ per i clienti trattati. Pertanto, non possiamo calcolare l’effetto di trattamento individuale, τᵢ = Yᵢ⁽¹⁾ − Yᵢ⁽⁰⁾, nei dati di validazione per nessun cliente.
Possiamo comunque fare qualcosa per valutare i nostri stimatori?
La risposta è sì, ma prima di fornire ulteriori dettagli, cerchiamo di capire cosa faremmo se potessimo osservare gli Effetti di Trattamento Individuali τᵢ.
Perdita Oracle MSE
Se potessimo osservare gli effetti di trattamento individuali (ma non possiamo, da qui l’attributo “oracle”), potremmo cercare di misurare quanto i nostri stimatori τ̂(Xᵢ) si discostano dai valori veri τᵢ. Questo è ciò che facciamo normalmente nel machine learning quando vogliamo valutare un metodo di previsione: mettiamo da parte un set di dati di validazione e confrontiamo i valori predetti con quelli veri su tali dati. Esistono molte funzioni di perdita per valutare l’accuratezza delle previsioni, quindi concentriamoci sulla più popolare: la perdita del Mean Squared Error (MSE).
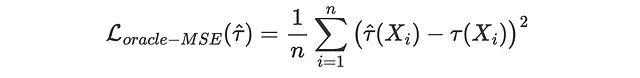
def loss_oracle_mse(data, learner): tau = learner.effect(data[X]) return np.mean((tau - data['effect_on_sales'])**2)La funzione compare_methods stampa e traccia le metriche di valutazione calcolate su un set di validazione separato.
def compare_methods(learners, names, loss, title=None, subtitle='minore è meglio'): data = dgp.generate_data(seed_data=1, seed_assignment=1, keep_po=True) results = pd.DataFrame({ 'learner': names, 'loss': [loss(data.copy(), learner) for learner in learners] }) fig, ax = plt.subplots(1, 1, figsize=(6, 4)) sns.barplot(data=results, x="learner", y='loss').set(ylabel='') plt.suptitle(title, y=1.02) plt.title(subtitle, fontsize=12, fontweight=None, y=0.94) return resultsresults = compare_methods(learners, names, loss_oracle_mse, title='Perdita Oracle MSE')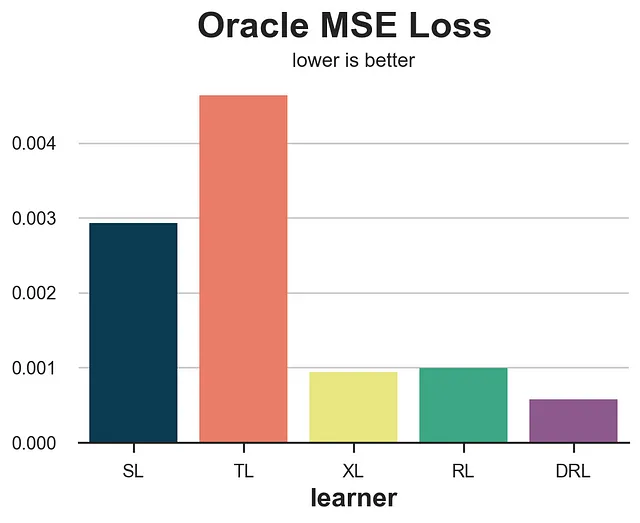
In questo caso, vediamo che il T-learner si comporta chiaramente peggio, con lo S-learner subito dopo. D’altra parte, gli X-, R- e DR-learner si comportano significativamente meglio, con il DR-learner che vince la competizione.
Tuttavia, potrebbe non essere la migliore funzione di perdita per valutare il nostro modello di incremento. Infatti, il modeling di incremento è solo un passo intermedio verso il nostro obiettivo finale: migliorare il fatturato.
Guadagno della Politica Oracle
Dato che il nostro obiettivo finale è migliorare il fatturato, potremmo valutare gli stimatori in base a quanto aumentano il fatturato, data una determinata funzione di politica. Supponiamo, ad esempio, che abbiamo un costo di 0,01$ per inviare una e-mail. Allora, la nostra politica sarebbe di trattare ogni cliente con un effetto medio condizionale predetto superiore a 0,01$.
costo = 0,01Di quanto aumenterebbe effettivamente il nostro fatturato? Definiamo con d(τ̂) la nostra funzione di politica, tale che d=1 se τ ≥ 0,1 e d=0 altrimenti. Allora la nostra funzione di guadagno (maggiore è meglio) è:
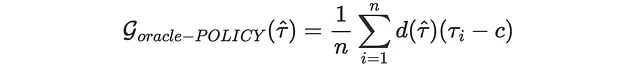
Anche questa è una funzione di perdita “oracle” che non può essere calcolata nella realtà poiché non osserviamo gli effetti del trattamento individuali.
def gain_oracle_policy(data, learner): tau_hat = learner.effect(data[X]) return np.sum((data['effect_on_sales'] - costo) * (tau_hat > costo))results = compare_methods(learners, names, gain_oracle_policy, title='Guadagno della Politica Oracle', subtitle='maggiore è meglio')
In questo caso, lo S-learner è chiaramente il peggior performer, non avendo alcun effetto sul fatturato. Il T-learner porta a modesti guadagni, mentre gli X-, R- e DR-learner portano tutti a guadagni complessivi, con lo X-learner leggermente in vantaggio.
Funzioni di Perdita Pratiche
Nella sezione precedente, abbiamo visto due esempi di funzioni di perdita che vorremmo calcolare se potessimo osservare gli Effetti del Trattamento Individuali τᵢ. Tuttavia, nella pratica, anche con un esperimento randomizzato e anche con un set di validazione, non osserviamo l’ITE, il nostro oggetto di interesse. Ora affronteremo alcune misure che cercano di valutare i modelli di incremento, dato questo vincolo pratico.
Perdita dell’Esito
Il primo e più semplice approccio è quello di passare a una diversa variabile di perdita. Mentre non possiamo osservare gli Effetti del Trattamento Individuali, τᵢ, possiamo comunque osservare il nostro esito Yᵢ. Questo non è esattamente il nostro oggetto di interesse, ma potremmo aspettarci che un modello di aumento delle prestazioni che funziona bene in termini di previsione di y produca anche buone stime di τ.
Una tale funzione di perdita potrebbe essere la Perdita MSE dell’Esito, che è la solita funzione di perdita MSE per i metodi di previsione.
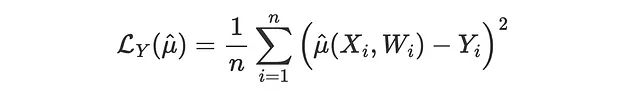
Il problema qui è che non tutti i modelli producono direttamente una stima di μ(x). Pertanto, saltiamo questo confronto e passiamo a metodi che possono valutare qualsiasi modello di aumento delle prestazioni.
Perdita della Predizione alla Predizione
Un altro approccio molto semplice potrebbe essere quello di confrontare le previsioni del modello allenato sul set di addestramento con le previsioni di un altro modello allenato sul set di convalida. Sebbene intuitivo, questo approccio potrebbe essere estremamente fuorviante.
def loss_pred(data, learner): tau = learner.effect(data[X]) learner2 = copy.deepcopy(learner).fit(data[Y], data[W], X=data[X]) tau2 = learner2.effect(data[X]) return np.mean((tau - tau2)**2)results = compare_methods(learners, names, loss_pred, 'Perdita della Predizione alla Predizione')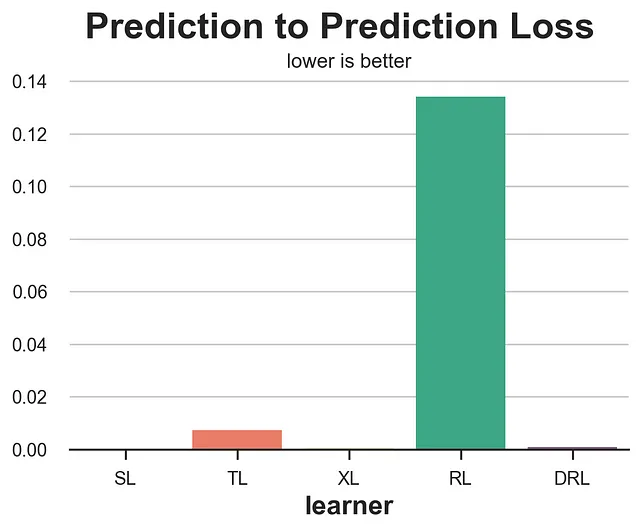
Come era prevedibile, questa metrica si comporta estremamente male e non dovresti mai usarla, poiché premia i modelli che sono coerenti, indipendentemente dalla loro qualità. Un modello che prevede sempre una costante CATE casuale per ogni osservazione otterrebbe un punteggio perfetto.
Perdita della Distribuzione
Un approccio diverso consiste nel chiedersi: quanto bene possiamo adattare la distribuzione degli esiti potenziali? Possiamo fare questo esercizio sia per gli esiti potenziali trattati che non trattati. Prendiamo l’ultimo caso. Supponiamo di prendere le vendite osservate per i clienti che non hanno ricevuto la mail e le vendite osservate meno la CATE stimata τ̂(x) per i clienti che hanno ricevuto la mail. Secondo l’assunzione di non confondibilità, queste due distribuzioni degli esiti potenziali non trattati dovrebbero essere simili, condizionate ai covariati X.
Pertanto, ci aspettiamo che la distanza tra le due distribuzioni sia vicina se abbiamo stimato correttamente gli effetti del trattamento.
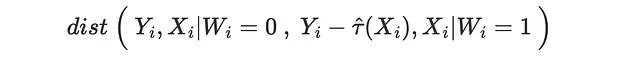
Possiamo fare lo stesso esercizio anche per gli esiti potenziali trattati.
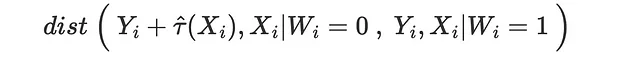
Utilizziamo la distanza di energia come metrica di distanza.
from dcor import energy_distancedef loss_dist(data, learner): tau = learner.effect(data[X]) data.loc[data.mail==1, 'sales'] -= tau[data.mail==1] return energy_distance(data.loc[data.mail==0, [Y] + X], data.loc[data.mail==1, [Y] + X], exponent=2)results = compare_methods(learners, names, loss_dist, 'Perdita della Distribuzione')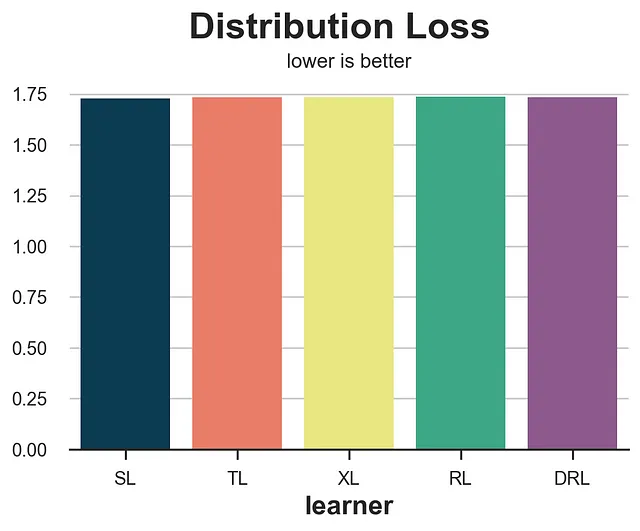
Questa misura è estremamente rumorosa e premia il S-learner seguito dal T-learner, che sono in realtà i due modelli con le peggiori performance.
Differenza sopra-sotto la mediana
La perdita sopra-sotto la mediana cerca di rispondere alla domanda: il nostro modello di incremento sta rilevando qualche eterogeneità? In particolare, se prendiamo il set di validazione e dividiamo il campione in predizioni di incremento sopra la mediana e sotto la mediana τ̂(x), quale è la differenza effettiva nell’effetto medio, stimata con un estimatore di differenza tra le medie? Ci aspetteremmo che gli stimatori migliori dividano il campione in effetti alti ed effetti bassi in modo migliore.
from statsmodels.formula.api import ols def loss_ab(data, learner): tau = learner.effect(data[X]) + np.random.normal(0, 1e-8, len(data)) data['above_median'] = tau >= np.median(tau) param = ols('sales ~ mail * above_median', data=data).fit().params[-1] return paramresults = compare_methods(learners, names, loss_ab, title='Differenza sopra-sotto la mediana', subtitle='più alto è meglio')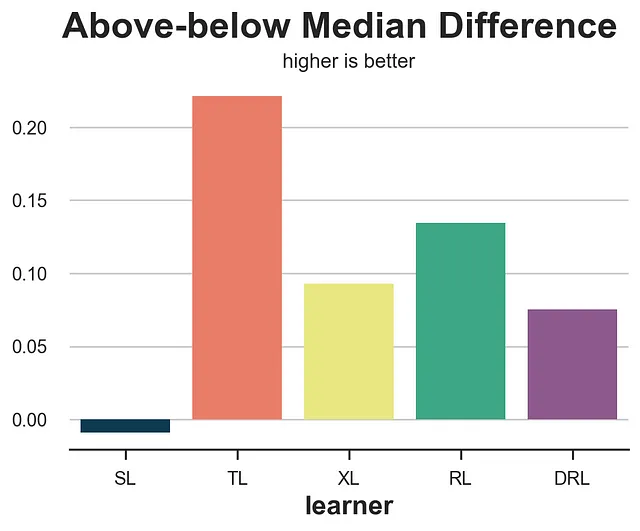
Sfortunatamente, la differenza sopra-sotto la mediana premia il T-learner, che è tra i modelli con le peggiori performance.
È importante notare che gli estimatori di differenza tra le medie nei due gruppi (sopra e sotto la mediana τ̂(x)) non sono garantiti di essere imparziali, anche se i dati provengono da un esperimento randomizzato. Infatti, abbiamo diviso i due gruppi su una variabile, τ̂(x), che è altamente endogena. Pertanto, il metodo dovrebbe essere usato con cautela.
Curva di incremento
Un’estensione del test sopra-sotto la mediana è la curva di incremento. L’idea è semplice: invece di dividere il campione in due gruppi in base alla mediana (quantile 0.5), perché non dividere i dati in più gruppi (più quantili)?
Per ogni gruppo, calcoliamo la stima di differenza tra le medie e tracciamo la sua somma cumulativa in funzione del quantile corrispondente. Il risultato è chiamato curva di incremento. L’interpretazione è semplice: più alta è la curva, meglio siamo in grado di separare le osservazioni ad alto effetto da quelle a basso effetto. Tuttavia, si applica anche la stessa avvertenza: le stime di differenza tra le medie non sono imparziali. Pertanto, dovrebbero essere usate con cautela.
def generate_uplift_curve(df): Q = 20 df_q = pd.DataFrame() data = dgp.generate_data(seed_data=1, seed_assignment=1, keep_po=True) ate = np.mean(data[Y][data[W]==1]) - np.mean(data[Y][data[W]==0]) for learner, name in zip(learners, names): data['tau_hat'] = learner.effect(data[X]) data['q'] = pd.qcut(-data.tau_hat + np.random.normal(0, 1e-8, len(data)), q=Q, labels=False) for q in range(Q): temp = data[data.q <= q] uplift = (np.mean(temp[Y][temp[W]==1]) - np.mean(temp[Y][temp[W]==0])) * q / (Q-1) df_q = pd.concat([df_q, pd.DataFrame({'q': [q], 'uplift': [uplift], 'learner': [name]})], ignore_index=True) fig, ax = plt.subplots(1, 1, figsize=(8, 5)) sns.lineplot(x=range(Q), y=ate*range(Q)/(Q-1), color='k', ls='--', lw=3) sns.lineplot(x='q', y='uplift', hue='learner', data=df_q); plt.suptitle('Curva di incremento', y=1.02, fontsize=28, fontweight='bold') plt.title('più alto è meglio', fontsize=14, fontweight=None, y=0.96)generate_uplift_curve(df)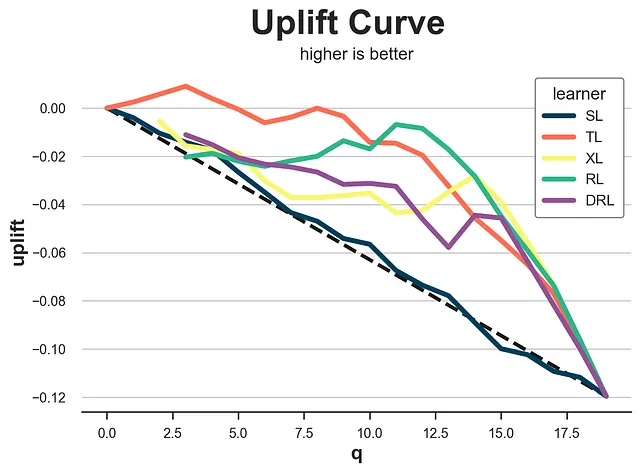
Anche se probabilmente non è il miglior metodo per valutare i modelli di incremento, la curva di incremento è molto importante per comprendere ed implementare tali modelli. Infatti, per ogni modello, ci indica quale è l’effetto medio previsto del trattamento (asse y) all’aumentare della percentuale della popolazione trattata (asse x).
Match del vicino più prossimo
Gli ultimi due metodi che abbiamo analizzato utilizzavano dati aggregati per capire se i metodi funzionano su gruppi più grandi. Il match del vicino più prossimo cerca invece di capire quanto bene un modello di incremento predice gli effetti del trattamento individuali. Tuttavia, dato che gli effetti del trattamento non sono osservabili, cerca di costruire un proxy abbinando le osservazioni trattate e di controllo sulle caratteristiche osservabili X.
Ad esempio, se prendiamo tutte le osservazioni trattate (i: Wᵢ=1) e troviamo il vicino più prossimo nel gruppo di controllo (NN₀(Xᵢ)), la funzione di perdita MSE corrispondente è
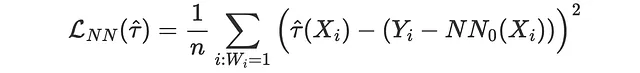
from scipy.spatial import KDTreedef loss_nn(data, learner): tau_hat = learner.effect(data[X]) nn0 = KDTree(data.loc[data[W]==0, X].values) control_index = nn0.query(data.loc[data[W]==1, X], k=1)[-1] tau_nn = data.loc[data[W]==1, Y].values - data.iloc[control_index, :][Y].values return np.mean((tau_hat[data[W]==1] - tau_nn)**2)results = compare_methods(learners, names, loss_nn, title='Perdita del vicino più prossimo')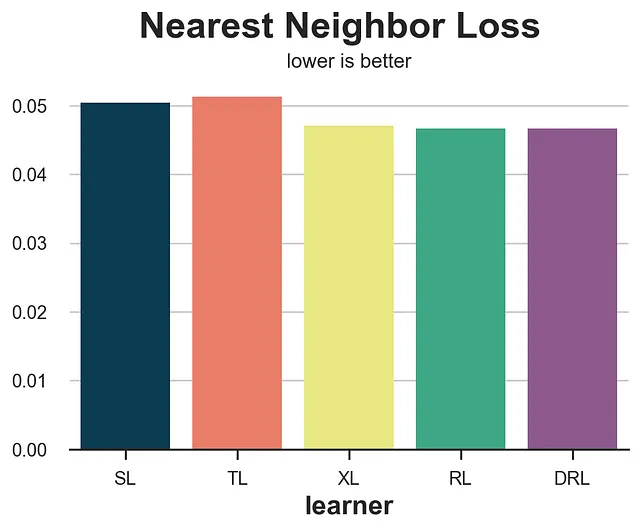
In questo caso, la perdita del vicino più prossimo funziona abbastanza bene, identificando i due metodi di peggior prestazione, S- e T-learner.
Perdita IPW
La funzione di perdita del peso della probabilità inversa (IPW) è stata proposta per la prima volta da Gutierrez, Gerardy (2017) ed è la prima delle tre metriche che vedremo che utilizzano un pseudo-outcome Y* per valutare l’estimatore. I pseudo-outcome sono variabili il cui valore atteso è l’effetto medio condizionale del trattamento, ma che sono troppo volatili per essere utilizzate direttamente come stime. Per una spiegazione più dettagliata dei pseudo-outcome, suggerisco il mio articolo sui alberi di regressione causale. Il pseudo-outcome corrispondente alla perdita IPW è
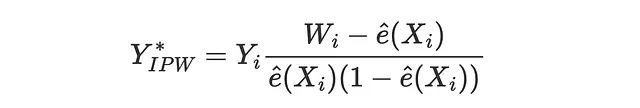
in modo che la funzione di perdita corrispondente sia
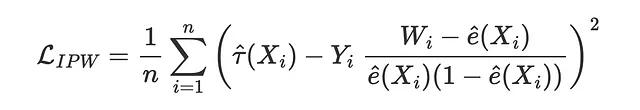
def loss_ipw(data, learner): tau_hat = learner.effect(data[X]) e_hat = clone(model_e).fit(data[X], data[W]).predict_proba(data[X])[:,1] tau_gg = data[Y] * (data[W] - e_hat) / (e_hat * (1 - e_hat)) return np.mean((tau_hat - tau_gg)**2)results = compare_methods(learners, names, loss_ipw, title='Perdita IPW')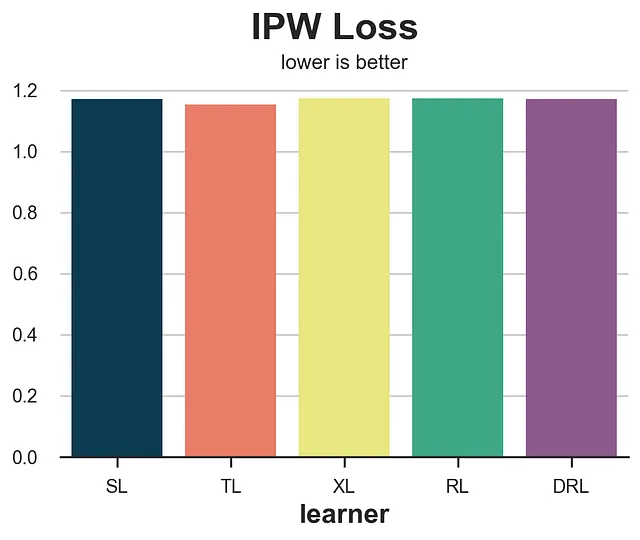
La perdita IPW è estremamente rumorosa. Una soluzione è utilizzare le sue variazioni più robuste, la perdita R o la perdita DR che presenteremo di seguito.
Perdita R
La perdita R è stata introdotta insieme al R-learner da Nie, Wager (2017), ed è essenzialmente la funzione obiettivo del R-learner. Come per la perdita IPW, l’idea è cercare di abbinare un risultato pseudo il cui valore atteso è l’Effetto Medio Condizionale del Trattamento.
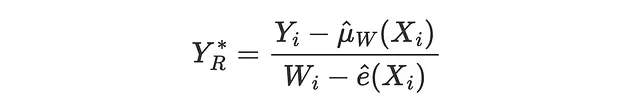
La corrispondente funzione di perdita è

def perdita_r(dati, learner): tau_hat = learner.effect(dati[X]) y_hat = clone(modello_y).fit(df[X + [W]], df[Y]).predict(dati[X + [W]]) e_hat = clone(modello_e).fit(df[X], df[W]).predict_proba(dati[X])[:,1] tau_nw = (dati[Y] - y_hat) / (dati[W] - e_hat) return np.mean((tau_hat - tau_nw)**2)confronta_metodi(learner, nomi, perdita_r, titolo='Perdita R')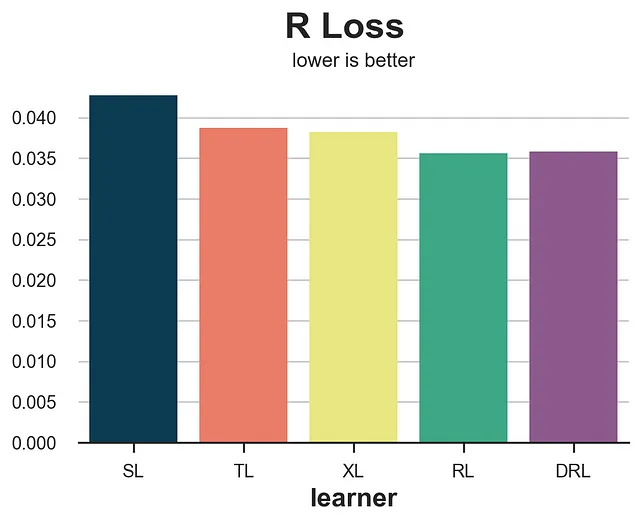
La perdita R è sensibilmente meno rumorosa della perdita IPW, e isola chiaramente il S-learner. Tuttavia, tende a favorire il suo corrispondente learner, il R-learner.
Perdita DR
La perdita DR è la funzione obiettivo del DR-learner, ed è stata introdotta per la prima volta da Saito, Yasui (2020). Come per le perdite IPW e R, l’idea è cercare di abbinare un risultato pseudo, il cui valore atteso è l’Effetto Medio Condizionale del Trattamento. Il pseudo-risultato DR è strettamente legato all’estimatore AIPW, noto anche come estimatore doppiamente robusto, da cui il nome DR.
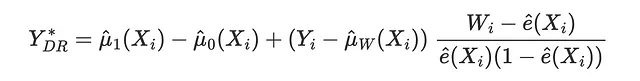
La corrispondente funzione di perdita è
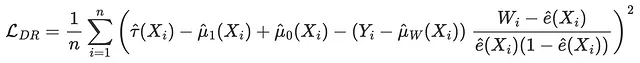
def perdita_dr(dati, learner): tau_hat = learner.effect(dati[X]) y_hat = clone(modello_y).fit(df[X + [W]], df[Y]).predict(dati[X + [W]]) mu1 = clone(modello_y).fit(df[X + [W]], df[Y]).predict(dati[X + [W]].assign(mail=1)) mu0 = clone(modello_y).fit(df[X + [W]], df[Y]).predict(dati[X + [W]].assign(mail=0)) e_hat = clone(modello_e).fit(df[X], df[W]).predict_proba(dati[X])[:,1] tau_nw = mu1 - mu0 + (dati[Y] - y_hat) * (dati[W] - e_hat) / (e_hat * (1 - e_hat)) return np.mean((tau_hat - tau_nw)**2)risultati = confronta_metodi(learner, nomi, perdita_dr, titolo='Perdita DR')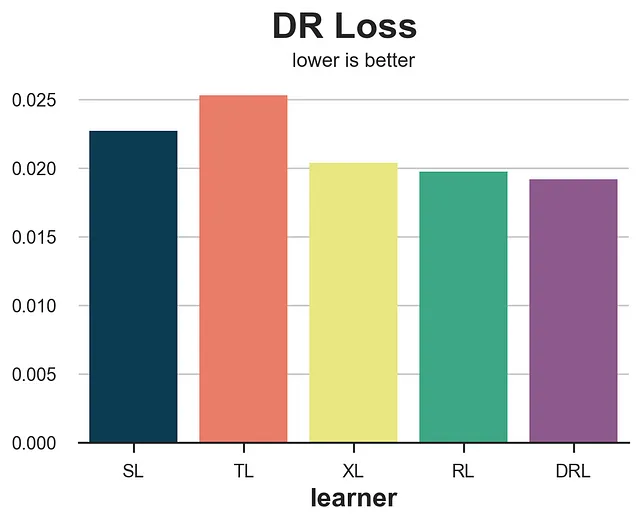
Per quanto riguarda la perdita di R, la perdita di DR tende a favorire il suo rispettivo apprendista, il DR-apprendista. Tuttavia, fornisce una classifica più accurata in termini di accuratezza degli algoritmi.
Guadagno Politica Empirica
L’ultima funzione di perdita che andremo ad analizzare è diversa da tutte le altre che abbiamo visto finora, dal momento che non si concentra su quanto bene siamo in grado di stimare gli effetti del trattamento, ma piuttosto su quanto bene si comporterebbe la corrispondente politica di trattamento ottimale. In particolare, Hitsch, Misra, Zhang (2023) propongono la seguente funzione di guadagno:
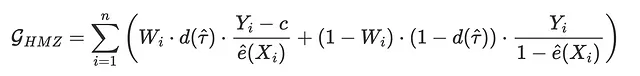
dove c è il costo del trattamento e d è la politica di trattamento ottimale data l’estimazione CATE τ̂(Xᵢ). Nel nostro caso, assumiamo un costo di trattamento individuale di c=0.01$, in modo che la politica ottimale sia quella di trattare ogni cliente con una CATE stimata maggiore di 0.01.
I termini Wᵢ⋅d(τ̂) e (1-Wᵢ)⋅(1-d(τ̂)) implicano che utilizziamo per il calcolo solo gli individui per i quali il trattamento effettivo W corrisponde a quello ottimale, d.
def guadagno_politica(data, apprendista): tau_hat = apprendista.effect(data[X]) e_hat = clone(model_e).fit(data[X], data[W]).predict_proba(data[X])[:,1] d = tau_hat > costo return np.sum((d * data[W] * (data[Y] - costo)/ e_hat + (1-d) * (1-data[W]) * data[Y] / (1-e_hat)))risultati = confronta_metodi(apprendisti, nomi, guadagno_politica, titolo='Guadagno Politica Empirica', sottotitolo='più alto è meglio')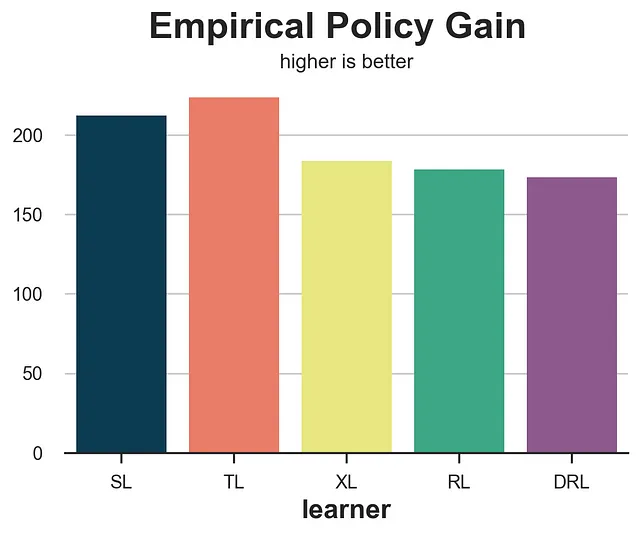
Il guadagno politica empirica si comporta molto bene, isolando i due metodi con le prestazioni peggiori, gli apprendisti S e T.
Meta Studi
In questo articolo, abbiamo presentato una vasta varietà di metodi per valutare i modelli di incremento, anche noti come stimatori dell’effetto medio condizionato del trattamento. Abbiamo anche testato nel nostro dataset simulato, che è un esempio molto speciale e limitato. Come si comportano queste metriche in generale?
Schuler, Baiocchi, Tibshirani, Shah (2018) confronta la perdita S, la perdita T, la perdita R, su dati simulati, per gli stimatori corrispondenti. Trovano che la perdita R “è la metrica del set di validazione che, quando ottimizzata, porta più costantemente alla selezione di un modello ad alte prestazioni”. Gli autori individuano anche il cosiddetto bias di congenialità: metriche come la perdita R o DR tendono ad essere parziali nei confronti dell’apprendista corrispondente.
Curth, van der Schaar (2023) studia una vasta gamma di apprendisti da un punto di vista teorico. Trovano che “non esiste un criterio di selezione esistente che sia globalmente migliore in tutte le condizioni sperimentali che consideriamo”.
Mahajan, Mitliagkas, Neal, Syrgkanis (2023) è lo studio più esaustivo in termini di portata. Gli autori confrontano molte metriche su 144 dataset e 415 stimatori. Trovano che “nessuna metrica domina significativamente le altre” ma “le metriche che utilizzano elementi DR sembrano sempre essere tra i vincitori candidati”.
Conclusione
In questo articolo, abbiamo esplorato diversi metodi per valutare i modelli di incremento. La sfida principale è l’inesplicabilità della variabile di interesse, gli effetti del trattamento individuale. Pertanto, i diversi metodi cercano di valutare i modelli di incremento utilizzando altre variabili, utilizzando outcome proxy o approssimando l’effetto delle politiche ottimali implicite.
È difficile raccomandare l’utilizzo di un singolo metodo poiché non c’è consenso su quale sia il migliore, né dal punto di vista teorico né da quello empirico. Le funzioni di perdita che utilizzano elementi R e DR tendono a ottenere risultati più consistenti, ma sono anche inclini verso i modelli corrispondenti. Comprendere come funzionano queste metriche può tuttavia aiutare a comprendere i loro pregiudizi e limitazioni al fine di prendere le decisioni più appropriate a seconda dello scenario specifico.
Riferimenti
- Curth, van der Schaar (2023), “In Search of Insights, Not Magic Bullets: Towards Demystification of the Model Selection Dilemma in Heterogeneous Treatment Effect Estimation”
- Gutierrez, Gerardy (2017), “Causal Inference and Uplift Modeling: A review of the literature”
- Hitsch, Misra, Zhang (2023), “Heterogeneous Treatment Effects and Optimal Targeting Policy Evaluation”
- Kennedy (2022), “Towards optimal doubly robust estimation of heterogeneous causal effects”
- Kunzel, Sekhon, Bickel, Yu (2017), “Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning”
- Mahajan, Mitliagkas, Neal, Syrgkanis (2023), “Empirical Analysis of Model Selection for Heterogeneous Causal Effect Estimation”
- Nie, Wager (2017), “Quasi-Oracle Estimation of Heterogeneous Treatment Effects”
- Saito, Yasui (2020), “Counterfactual Cross-Validation: Stable Model Selection Procedure for Causal Inference Models”
- Schuler, Baiocchi, Tibshirani, Shah (2018), “A comparison of methods for model selection when estimating individual treatment effects”
Articoli correlati
- Comprensione dei Meta-learner
- Comprensione dell’estimatore robusto al doppio AIPW
- Comprensione degli alberi causali
- Dagli alberi causali alle foreste
Codice
Puoi trovare il Jupyter Notebook originale qui:
Blog-Posts/notebooks/evaluate_uplift.ipynb at main · matteocourthoud/Blog-Posts
Codice e notebook per i miei post sul blog di VoAGI. Contribuisci allo sviluppo di matteocourthoud/Blog-Posts creando un…
github.com
Grazie per aver letto!
Lo apprezzo davvero! 🤗 Se ti è piaciuto il post e vuoi vedere altro, considera di seguirmi. Pubblico una volta alla settimana su argomenti legati all’inferenza causale e all’analisi dei dati. Cerco di mantenere i miei post semplici ma precisi, fornendo sempre codice, esempi e simulazioni.
Inoltre, una piccola disclaimer: scrivo per imparare, quindi gli errori sono la norma, anche se faccio del mio meglio. Per favore, quando li individui, fammelo sapere. Apprezzo anche suggerimenti su nuovi argomenti!




