Migliora la previsione dei dati tabulari con Large Language Model tramite OpenAI API
Migliora previsione dati tabulari con Large Language Model tramite OpenAI API
Implementazione Python con classificazione machine learning, ingegneria del prompt, ingegneria delle caratteristiche sull’incorporamento del testo e spiegazione del modello con OpenAI API
In questi giorni, i grandi modelli di linguaggio e le applicazioni o gli strumenti sono ovunque nelle notizie e sui social VoAGI. La pagina dei trend di GitHub mostra una presenza consistente di repository che utilizzano ampiamente grandi modelli di linguaggio. Abbiamo visto le fantastiche capacità dei grandi modelli di linguaggio nel creare testi per il marketing, riassumere documenti, comporre musica e generare codice per lo sviluppo del software.
Le aziende dispongono di un’abbondanza di dati tabulari (uno dei formati di dati più antichi e diffusi che possono essere rappresentati in una tabella con righe e colonne) accumulati internamente e online. Possiamo applicare grandi modelli di linguaggio ai dati tabulari nel ciclo di vita tradizionale del machine learning per migliorare le prestazioni del modello e aggiungere valore aziendale?
In questo articolo, esploreremo i seguenti argomenti con il codice di implementazione completo in Python:
- Costruzione di modelli lineari generalizzati e modelli basati su alberi sul dataset pubblico Kaggle Heart Attack Analysis & Prediction.
- Ingegneria del prompt per trasformare i dati tabulari in testo
- Classificazione zero-shot con OpenAI API (modello GPT-3.5: text-davinci-003)
- Miglioramento delle prestazioni del modello di machine learning con l’API di incorporamento di OpenAI – text-embedding-ada-002
- Spiegazione delle previsioni con l’API di OpenAI – gpt-3.5-turbo
Descrizione del dataset
I dati sono disponibili sul sito web di Kaggle con licenza CC0 1.0 Universal (CC0 1.0) Public Domain Dedication, che è privo di diritti d’autore (puoi copiare, modificare, distribuire e eseguire il lavoro, anche a scopi commerciali). Si prega di fare riferimento al link sottostante:
- 2 Modi Efficaci per Spostare i Dati da On-Premises al Cloud
- Scoprire i segreti di KEPFILTERS in DAX
- Scoprire i segmenti più insoliti nei dati
Dataset Heart Attack Analysis & Prediction
Un dataset per la classificazione degli attacchi di cuore
www.kaggle.com
Contiene caratteristiche demografiche, condizioni mediche e target. Le colonne sono spiegate di seguito:
- age: età dell’applicante
- sex: sesso dell’applicante
- cp: tipo di dolore al petto: il valore 1 indica angina tipica, il valore 2 indica angina atipica, il valore 3 indica dolore non anginoso e il valore 4 indica asintomatico.
- trtbps: pressione sanguigna a riposo (in mm Hg)
- chol: colesterolo in mg/dl rilevato tramite sensore BMI
- fbs: zucchero nel sangue a digiuno > 120 mg/dl, 1 = Vero, 0 = Falso
- restecg: risultati elettrocardiografici a riposo
- thalachh: frequenza cardiaca massima raggiunta
- exng: angina indotta dall’esercizio (1 = sì; 0 = no)
- oldpeak: picco precedente
- slp: pendenza
- caa: numero di principali vasi
- thall: tasso di thal
- output: variabile target, 0 = minori probabilità di attacco di cuore, 1 = maggiori probabilità di attacco di cuore
Modelli di machine learning
Sono stati sviluppati modelli di classificazione binaria per prevedere la probabilità di avere un attacco di cuore. Questa sezione coprirà:
- Pre-elaborazione: controllo dei valori mancanti, codifica one-hot, divisione stratificata dei dati di addestramento e test, ecc.
- Costruzione di 4 modelli, tra cui tre modelli lineari generalizzati e un modello basato su alberi: Regressione logistica, Ridge, Lasso e Random Forest
- Valutazione del modello con AUC
Prima di tutto, importiamo i pacchetti, carichiamo i dati, pre-elaboriamo e dividiamo i dati di addestramento e test.
import warningswarnings.filterwarnings("ignore")# Matematica e vettoriimport pandas as pdimport numpy as np# Visualizzazioniimport plotly.express as px# MLfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import roc_auc_scoreimport concurrent.futures# Funzioni utilifrom utils import prediction, compile_prompt, get_embedding, ml_models, create_auc_chart, gpt_reasoningpd.set_option('display.max_columns', None)# Caricamento dei datidf = pd.read_csv("./data/raw data/heart_attack_predicton_kaggle.csv")df.shape# Controllo dei valori mancanti df.isna().sum()# Distribuzione dei risultati del target df['output'].value_counts()# Codifica one-hotcat_cols = ['sex','exng','cp','fbs','restecg','slp','thall']df_model = pd.get_dummies(df,columns=cat_cols)df_model.shape# Divisione stratificata dei dati di addestramento e test# Separazione delle variabili dipendenti e indipendentiX = df_model.drop(axis=1,columns=['output'])y = df_model['output'].tolist()X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size=0.2, random_state=101, stratify=y,shuffle=True)Ora, creiamo l’oggetto del modello, addestriamo il modello, facciamo la previsione sul set di test e calcoliamo l’AUC.
## Funzione del modello def ml_models(): lr = LogisticRegression(penalty='none', solver='saga', random_state=42, n_jobs=-1) lasso = LogisticRegression(penalty='l1', solver='saga', random_state=42, n_jobs=-1) ridge = LogisticRegression(penalty='l2', solver='saga', random_state=42, n_jobs=-1) rf = RandomForestClassifier(n_estimators=300, max_depth=5, min_samples_leaf=50, max_features=0.3, random_state=42, n_jobs=-1) models = {'LR': lr, 'LASSO': lasso, 'RIDGE': ridge, 'RF': rf} return modelsmodels = ml_models()lr = models['LR']lasso = models['LASSO'] ridge = models['RIDGE'] rf = models['RF'] pred_dict = {}for k, m in models.items(): print(k) m.fit(X_tr, y_tr) preds = m.predict_proba(X_val)[:,1] auc = roc_auc_score(y_val, preds) pred_dict[k] = preds print(k + ': ', auc)Successivamente, visualizziamo e confrontiamo le prestazioni del modello (AUC).
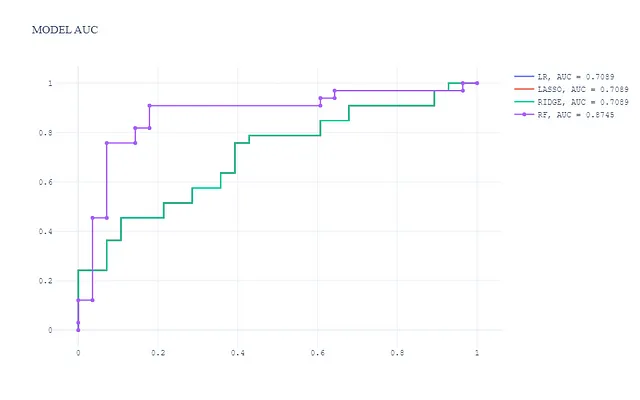
In questa visualizzazione:
- Il modello basato su alberi (Random Forest) ha prestazioni migliori con un’AUC molto più alta.
- I 3 modelli lineari generalizzati hanno un livello di prestazioni simile e l’AUC è inferiore al modello basato su alberi, come ci si aspetta.
Classificazione zero-shot con OpenAI API
Eseguiremo una classificazione zero-shot sui dati tabulari con OpenAI API basata sul modello text-davinci-003. Prima di addentrarci nell’implementazione in Python, cerchiamo di capire un po’ di più sulla classificazione zero-shot. La definizione di Hugging face è la seguente:
La classificazione zero-shot è il compito di predire una classe che il modello non ha visto durante l’addestramento. Questo metodo, che sfrutta un modello di linguaggio preaddestrato, può essere considerato come un’istanza di trasferimento di apprendimento che generalmente si riferisce all’utilizzo di un modello addestrato per un compito in un’applicazione diversa da quella per cui è stato originariamente addestrato. Questo è particolarmente utile in situazioni in cui la quantità di dati annotati è limitata.
Nella classificazione zero-shot, viene fornito al modello un prompt e una sequenza di testo che descrive ciò che vogliamo che il modello faccia, senza alcun esempio di comportamento atteso. Questa sezione coprirà:
- Pre-elaborazione dei dati tabulari per l’ingegneria del prompt
- Indicazione dei modelli di linguaggio basati su prompt
- Previsione zero-shot con l’API GPT-3.5: text-davinci-003
- Valutazione del modello con AUC
Pre-elaborazione dei dati tabulari
Prima di procedere con il prompt, elaboriamo i dati:
df_gpt = df.copy()df_gpt['sex'] = np.where(df_gpt['sex'] == 1, 'Maschio', 'Femmina')df_gpt['cp'] = np.where(df_gpt['cp'] == 1, 'Angina tipica', np.where(df_gpt['cp'] == 2, 'Angina atipica', np.where(df_gpt['cp'] == 3, 'Dolore non anginoso', 'Asintomatico')))df_gpt['fbs'] = np.where(df_gpt['fbs'] == 1, 'Glicemia a digiuno > 120 mg/dl', 'Glicemia a digiuno <= 120 mg/dl')df_gpt['restecg'] = np.where(df_gpt['restecg'] == 0, 'Normale', np.where(df_gpt['restecg'] == 1, 'Presenza di anomalia ST-T (inversioni dell'onda T e/o elevazione o depressione della ST > 0,05 mV)', "Mostrando ipertrofia ventricolare sinistra probabile o definita secondo i criteri di Estes"))df_gpt['exng'] = np.where(df_gpt['exng'] == 1, 'Angina indotta dall'esercizio', 'Senza angina indotta dall'esercizio')df_gpt['slp'] = np.where(df_gpt['slp'] == 0, 'La pendenza del segmento ST dell'esercizio fisico è discendente', np.where(df_gpt['slp'] == 1, 'La pendenza del segmento ST dell'esercizio fisico è piatta', 'La pendenza del segmento ST dell'esercizio fisico è ascendente'))df_gpt['thall'] = np.where(df_gpt['thall'] == 1, 'Thall è un difetto fisso', np.where(df_gpt['thall'] == 2, 'Thall è normale', 'Thall è un difetto reversibile'))# Convertiamo il dataframe di test in dizionarioapplication_list = X_val.to_dict(orient='records')len(application_list)Utilizzo di LLM per la richiesta di input
I prompt sono un potente strumento per interagire con modelli di linguaggio estesi per un determinato compito. Un prompt è un input fornito dall’utente a cui il modello è destinato a rispondere. I prompt possono essere di varie forme, ad esempio testo o un’immagine.
In questo articolo, il prompt include istruzioni con un formato di output JSON previsto e la domanda stessa. Con il dataset degli attacchi cardiaci, un prompt di testo potrebbe essere il seguente:
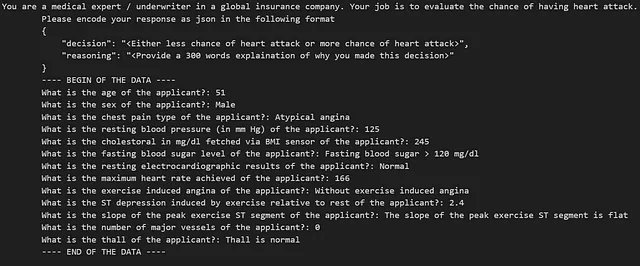
Successivamente, definiremo la funzione per il prompt e la chiamata all’API che costruisce il prompt e ottiene la risposta da OpenAI-3.5 API.
def previsione_GPT3_5(dati, spiega = False): if spiega: prompt = logica_prompt(spiega) else: prompt = logica_prompt(spiega) print(prompt) risposta = openai.Completion.create( model = 'text-davinci-003', prompt=prompt, max_tokens=64, n=1, stop=None, temperature=0.5, top_p=1.0, frequency_penalty=0.0, presence_penalty=0.0 ) try: output = risposta.choices[0].text.strip() output_dict = json.loads(output) return output_dict except (IndexError, ValueError): return None
def previsione(dati_combinati): dati_applicazione, spiega = dati_combinati risposta = previsione_GPT3_5(dati_applicazione, spiega) return rispostaOttieni la risposta dell’API – multiprocessing
Il multiprocessing viene utilizzato per velocizzare la chiamata all’API. Il codice è il seguente:
### ottieni previsione dal modello GPT-3.5: text-davinci-003 - pool multiprocessingwith concurrent.futures.ThreadPoolExecutor() as executor: # Combina credit_data e spiega in un unico iterabile dati_combinati = zip(lista_applicazioni, [False] * len(lista_applicazioni)) # Sottoponi i compiti di elaborazione delle transazioni all'esecutore risultati = executor.map(previsione, dati_combinati) # Raccogli le risposte in una lista risposte = list(risultati)risposte_df = pd.DataFrame(risposte)risposte_df.shapeAUC della classificazione zero-shot
L’AUC è 0,48 per la classificazione zero-shot, il che suggerisce che le previsioni siano peggiori di un caso casuale e indica che potenzialmente non vi è alcuna fuga nel modello GPT-3.5 text-davinci-003 in questo dataset.
auc_gpt= roc_auc_score(y_val, risposte_df['output'])auc_gptMigliorare le prestazioni del modello di apprendimento automatico con l’embedding di OpenAI
L’embedding di LLM è un endpoint di un modello di linguaggio esteso (ad esempio, OpenAI API) che facilita l’esecuzione di compiti di linguaggio naturale e di codice come la ricerca semantica, il clustering, la modellazione dei temi e la classificazione. Con l’ingegneria del prompt, i dati tabulari vengono trasformati in testo di linguaggio naturale che può essere utilizzato per generare gli embeddings. Gli embeddings hanno il potenziale per migliorare le prestazioni dei modelli di apprendimento automatico tradizionali consentendo loro di comprendere meglio il linguaggio naturale e adattarsi al contesto con una piccola quantità di dati etichettati. In breve, si tratta di uno dei tipi di feature engineering in questo contesto.
L’ingegneria delle feature è il processo di trasformazione dei dati grezzi in feature che rappresentano meglio il problema sottostante per i modelli predittivi, risultando in un’accuratezza del modello migliorata sui dati non visti.
In questa sezione, vedrai:
- Come ottenere gli embeddings di OpenAI tramite la chiamata all’API
- Confronto delle prestazioni del modello – con vs senza feature di embedding
Prima di tutto, definiamo la funzione per ottenere gli embeddings tramite API e unirli al dataset grezzo:
# Definisci la funzione per ottenere l'embeddingdef ottieni_embedding(testo, modello="text-embedding-ada-002"): testo = testo.replace("\n", " ") return openai.Embedding.create(input = [testo], model=modello)['data'][0]['embedding']# Chiamata all'API e unione con il dataset grezzodf_gpt['ada_embedding'] = df_gpt.combined.apply(lambda x: ottieni_embedding(x, model='text-embedding-ada-002'))df_gpt = df_gpt.join(pd.DataFrame(df_gpt['ada_embedding'].apply(pd.Series)))df_gpt.drop(['combined', 'ada_embedding'], axis = 1, inplace = True)df_gpt.columns = df_gpt.columns.tolist()[:14] + ['Embedding_' + str(i) for i in df_gpt.columns.tolist()[14:]]df = pd.concat([df, df_gpt[[i for i in df_gpt.columns.tolist() if i.startswith('Embedding_')]]], axis=1)df_gpt.shapeCome con i modelli di machine learning puri, condurremo anche una suddivisione stratificata e adatteremo il modello:
# Separare le variabili dipendenti e indipendentiX = df.drop(axis=1,columns=['output'])y = df['output'].tolist()X_tr, X_val, y_tr, y_val = train_test_split(X, y, test_size=0.2, random_state=101, stratify=y,shuffle=True)models = ml_models()lr = models['LR']lasso = models['LASSO'] ridge = models['RIDGE'] rf = models['RF'] pred_dict_gpt = {}for k, m in models.items(): print(k) m.fit(X_tr, y_tr) preds = m.predict_proba(X_val)[:,1] auc = roc_auc_score(y_val, preds) pred_dict_gpt[k + '_Con_Embedding_GPT'] = preds print(k + '_Con_Embedding_GPT' + ': ', auc)Confronto delle prestazioni del modello — con vs senza funzionalità di incorporamento
Unendo i modelli senza funzionalità di incorporamento, otteniamo in totale 8 modelli. La curva ROC sul set di test è la seguente:
pred_dict_combine = dict(list(pred_dict.items()) + list(pred_dict_gpt.items()))create_auc_chart(pred_dict_combine, y_val, 'AUC del modello')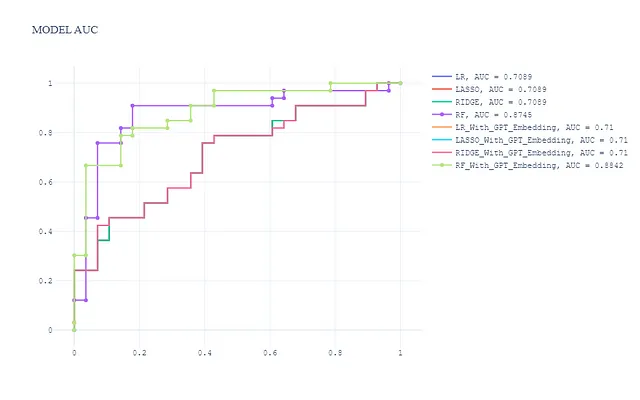
In generale, osserviamo:
- Le funzionalità di incorporamento non migliorano significativamente le prestazioni dei modelli lineari generalizzati (Regressione Logistica, Ridge e Lasso)
- Il modello Random Forest con funzionalità di incorporamento ha le migliori prestazioni ed è leggermente migliore del modello Random Forest senza funzionalità di incorporamento.
Vediamo il potenziale dei grandi modelli di linguaggio per essere integrati nel processo tradizionale di addestramento del modello e migliorare la qualità dell’output. Potremmo chiederci se i grandi modelli di linguaggio possano aiutare a spiegare la decisione del modello. Parliamo di questo nella prossima sezione.
Spiegabilità del modello con OpenAI API — gpt-3.5-turbo
La spiegabilità del modello è uno dei temi chiave nelle applicazioni di machine learning, specialmente in settori come assicurazioni, sanità, finanza e legge, dove gli utenti hanno bisogno di capire come un modello prende una decisione a livello locale e globale. Ho scritto un articolo relativo all’interpretazione del modello di apprendimento profondo usando SHAP se vuoi saperne di più sull’interpretazione del modello su modelli di apprendimento profondo.
In questa sezione si affrontano i seguenti argomenti:
- Preparazione dell’input per l’API di OpenAI
- Ottenere la motivazione attraverso il modello gpt-3.5-turbo
Prima di tutto, prepariamo l’input per la chiamata API.
application_data = application_list[0]application_data{'age': 51, 'sex': 'Maschio', 'cp': 'Angina atipica', 'trtbps': 125, 'chol': 245, 'fbs': 'Glicemia a digiuno > 120 mg/dl', 'restecg': 'Normale', 'thalachh': 166, 'exng': 'Senza angina indotta da sforzo', 'oldpeak': 2.4, 'slp': 'La pendenza del segmento ST dell'esercizio di picco è piatta', 'caa': 0, 'thall': 'Thall è normale'}Successivamente, otteniamo la motivazione chiamando l’API gpt-3.5-turbo.
message_objects = [ {"role": "sistema", "content": '''Sei un esperto medico / sottoscrittore in una compagnia di assicurazioni globale. Il tuo compito è valutare la probabilità di avere un attacco di cuore. Si prega di codificare la risposta come json nel seguente formato {{ "decisione": "<O una minore probabilità di attacco di cuore o una maggiore probabilità di attacco di cuore>", }}'''}, {"role": "utente", "content": prompt}, ]completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=message_objects, max_tokens=1000, # Regolare il parametro max_tokens in base alla lunghezza desiderata della risposta stop=None, # Impostare condizioni di interruzione personalizzate se necessario )# Estrai il contenuto del messaggio di risposta response_content = completion.choices[0].message["content"]La risposta è piuttosto impressionante e il grande modello linguistico mostra forti capacità di ragionamento insieme a spiegazioni ragionevoli.
{ “decisione“: “meno probabilità di infarto”, “ragionamento“: “Sulla base delle informazioni fornite, l’applicante presenta diversi fattori che indicano una minore probabilità di avere un infarto. In primo luogo, l’età dell’applicante è 51 anni, che non è considerata giovane ma neanche nell’intervallo ad alto rischio per gli infarti. In secondo luogo, l’applicante è di sesso maschile. Sebbene gli uomini abbiano generalmente un rischio maggiore rispetto alle donne per gli infarti, non è l’unico fattore determinante. In terzo luogo, il tipo di dolore al petto riportato dall’applicante è angina atipica. L’angina atipica è caratterizzata da un dolore al petto meno prevedibile e può avere diversi pattern rispetto all’angina tipica. Ciò può indicare un rischio inferiore di infarto rispetto all’angina tipica. In quarto luogo, la pressione sanguigna a riposo dell’applicante è di 125 mm Hg. Questo rientra nell’intervallo normale e non indica ipertensione, che è un fattore di rischio per gli infarti. In quinto luogo, il livello di colesterolo dell’applicante è di 245 mg/dl. Pur essendo più alto del livello raccomandato, non è estremamente elevato, e non è fornito il BMI dell’applicante, quindi non possiamo determinare se il livello di colesterolo sia elevato a causa dell’obesità. In sesto luogo, l’applicante non ha un livello di zucchero nel sangue a digiuno superiore a 120 mg/dl, il che indica un rischio inferiore diabete, un altro fattore di rischio per gli infarti. In settimo luogo, i risultati elettrocardiografici a riposo dell’applicante sono normali, il che indica una normale funzione cardiaca e riduce il rischio di infarto. In ottavo luogo, la frequenza cardiaca massima raggiunta dall’applicante è 166, il che è un segno positivo in quanto indica un sistema cardiovascolare più sano. In nono luogo, l’applicante non sperimenta angina indotta dall’esercizio, che è un altro fattore positivo. In decimo luogo, la depressione ST indotta dall’esercizio rispetto al riposo è di 2,4, che rientra nell’intervallo normale e non indica ischemia significativa. In undicesimo luogo, la pendenza del segmento ST dell’esercizio di picco è piatta, il che potrebbe essere un risultato normale o correlato all’angina atipica riportata dall’applicante. Infine, l’applicante non ha grossi vasi e un Thall normale, indicando un rischio inferiore di malattia coronarica. Considerando tutti questi fattori, è probabile che l’applicante abbia una minore probabilità di avere un infarto. Tuttavia, è importante notare che questa valutazione si basa esclusivamente sulle informazioni fornite e potrebbe essere necessaria un’ulteriore valutazione medica per una determinazione definitiva.” }
Sommario
I grandi modelli linguistici sono strumenti potenti per risolvere una vasta gamma di casi d’uso in vari settori. Creare applicazioni LLM è più facile e sempre più conveniente. I LLM sicuramente aggiungeranno un reale valore aziendale all’impresa.
Prima di andare
Ti invito a unirti a un’avventura di apprendimento emozionante e fruttuosa nel campo della scienza dei dati! Rimanete connessi seguendo la mia pagina VoAGI per una costante serie di affascinanti contenuti di scienza dei dati. Condividerò ulteriori basi di machine learning, basi di NLP e implementazione di data science end-to-end nei prossimi mesi. Saluti!
Riferimento
- https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
- https://platform.openai.com/docs/models/overview
Cos’è la classificazione Zero-Shot? – Hugging Face
Scopri la classificazione Zero-Shot utilizzando l’apprendimento automatico
huggingface.co
Introduzione ai grandi modelli linguistici: ingegneria delle prompt e P-Tuning | Blog tecnico NVIDIA
ChatGPT ha fatto un’ottima impressione. Gli utenti sono entusiasti di utilizzare l’assistente virtuale per fare domande, scrivere poesie, infondere…
developer.nvidia.com
Interpretazione del modello di deep learning utilizzando SHAP
Implementazione in Python su dati di immagini e tabulari
towardsdatascience.com