Cosa significa innatismo e ha importanza per l’intelligenza artificiale? (Parte 2)
Innatismo e importanza per l'IA (Pt. 2)

La questione dell’innatezza, nella biologia e nell’intelligenza artificiale, è fondamentale per il futuro dell’IA simile all’uomo. Questa immersione profonda in due parti sul concetto e sulla sua applicazione potrebbe aiutare a fare chiarezza.
Di Vincent J. Carchidi
(Questo è il seguito di un articolo in due parti sull’innatezza nella biologia e nell’intelligenza artificiale. La prima parte si trova qui.)
Innatezza nell’Intelligenza Artificiale
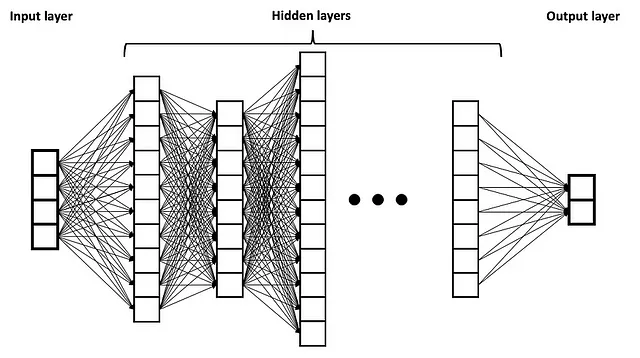
La rivoluzione dell’apprendimento profondo è stata accompagnata da un cambiamento nella relazione tra l’IA e lo studio della mente umana. Le reti neurali artificiali (ANN) sono state originariamente ispirate, in modo approssimativo, dalle interconnessioni massive dei neuroni all’interno dei cervelli dei mammiferi. Mentre l’esempio tipico usato di una ANN per un pubblico ampio è una semplice rete di alimentazione diretta, in cui c’è uno strato di input, strati nascosti nel mezzo e quindi uno strato di output attraverso il quale le informazioni fluiscono solo in una direzione, le reti neurali profonde (DNN) che possiedono molti centinaia di tali strati nascosti sono diventate più “internamente eterogenee” rispetto ai loro predecessori più superficiali (rappresentati di seguito).
- Che cos’è l’innatismo e ha qualche importanza per l’intelligenza artificiale? (Parte 1)
- Verso una AI al livello di Dio da una AI al livello di cane
- Dove avviene l’IA?
Fonte: Wikimedia Commons con licenza Creative Commons Attribution-Share Alike 4.0 International
Nel tempo, tuttavia, nel discorso popolare sull’IA si è verificato un rovesciamento dell’idea: che il cervello umano sia in realtà simile alle DNN. Il passaggio dall’ispirazione biologica per le ANN ai cervelli biologici che si trovano nella stessa lega delle DNN non è solo una stranezza linguistica, ma tradisce sia una comprensione sofisticata dell’innatezza nelle menti umane che una corretta interdisciplinarietà nello studio dell’IA. Nonostante i suoi meriti, la rivoluzione dell’apprendimento profondo ha portato con sé una tendenza a abbassare gli standard di rigore necessari per comprendere l’unica categoria di esempi di cui disponiamo di intelligenza: l’intelligenza biologica (una mancanza di cornice cognitiva recentemente lamentata da Peter Voss come un ostacolo sulla strada verso l’Intelligenza Artificiale Generale, o AGI).
Non è una sorpresa, quindi, che figure come Gary Marcus esprimano una frustrazione ripetuta nei confronti dei ricercatori di apprendimento automatico che sembrano resistere all’idea di costruire sistemi altamente strutturati, specificati con un significativo livello di conoscenza specifica del dominio. Marcus è, dopotutto, uno psicologo cognitivo di professione. E non è sorprendente che l’unico dibattito pubblico tra Gary Marcus e Yann LeCun nel 2017 si sia incentrato sulla domanda: “L’IA ha bisogno di più meccanismi innati?”
Ma questo era nell’era pre-grandi modelli di linguaggio (LLM). Più recentemente, nel giugno 2022, Yann LeCun e Jacob Browning, sostenendo che possiamo imparare cose nuove sull’intelligenza umana attraverso l’IA, affermano che gli LLM hanno imparato a manipolare simboli, “mostrando un certo livello di ragionamento di buon senso, componibilità, competenza multilingue, alcune capacità logiche e matematiche e addirittura capacità inquietanti di imitare i morti”. L’inghippo – “non lo fanno in modo affidabile”. LeCun ha espresso da allora il suo pessimismo sugli LLM nella ricerca dell’AGI, ma non ha, almeno chiaramente, collegato questo al pessimismo sull’apprendimento profondo stesso (qualunque confusione si abbia sulle posizioni di LeCun, a differenza di Marcus, il primo rimane in qualche modo un empirista, sebbene non un radicale).
L’inaffidabilità non è stata un ostacolo per altri, tuttavia, che si avvicinano all’idea che gli LLM possano contribuire ai dibattiti sull’innatezza negli esseri umani. Il linguista Steven Piantadosi ha scritto un articolo molto diffuso sostenendo che il successo degli LLM “minaccia praticamente ogni affermazione forte sull’innatezza del linguaggio proposta dalla linguistica generativa” (p. 1). Caratterizza gli LLM come “scienziati automatizzati o linguisti automatizzati, che lavorano anche su spazi relativamente non ristretti, cercando di trovare teorie che facciano il miglior lavoro di previsione parsimoniosa dei dati osservati” (p. 19).
Se l’argomento di Piantadosi fosse almeno parzialmente corretto – e gli LLM in qualche modo spiegassero come gli esseri umani acquisiscono le lingue naturali – avrebbe un impatto diretto sulla necessità (o mancanza di necessità in questo caso) dell’innatezza per l’intelligenza biologica e artificiale. Senza dubbio, altri hanno messo in dubbio l’argomento. Il linguista Roni Katzir, dopo aver testato personalmente GPT-4, scopre che il sistema non riesce a dimostrare di essere “idoneamente influenzato” (p. 2) verso i vincoli consolidati nell’uso del linguaggio umano, sostenendo che non modellano tanto la cognizione linguistica umana quanto il testo linguistico. Sostiene che sarebbe strano aspettarsi che gli LLM spieghino l’acquisizione del linguaggio umano data la diversa finalità alla base del loro design. I ricercatori Jon Rawski e Lucie Baumont sostengono in modo diretto che l’argomento di Piantadosi è fallace, oltre a dare priorità alla potenza di previsione rispetto alla potenza esplicativa.
Intelligenze artificiali che giocano come finestre sull’Intelligenza Artificiale Generale
In molti modi, il dibattito sull’innatismo nell’IA rispetto agli esseri umani è un’anomalia. Mentre l’apprendimento automatico ha spesso visto un’effort per minimizzare il numero di componenti innate necessarie affinché un sistema abbia successo, il dibattito assume che i successi dell’era del deep learning siano una sorta di striscia di empirismo. L’innatismo ha avuto importanza per il campo in modi rilevanti per la ricerca dell’AGI. Il problema è che quando l’innatismo è un fattore in sistemi di successo, spesso viene minimizzato o ignorato, con la rilevanza concettuale dei progressi persa persino da coloro che li promuovono di più.
Nulla è più evidente di questo che nelle intelligenze artificiali che giocano. Una delle cose più sorprendenti riguardo all’articolo di ricerca che accompagna AlphaGo Zero è stata l’insistenza degli autori sul fatto che il sistema inizia a imparare come giocare a Go da uno stato di “tabula rasa”. Naturalmente, AlphaGo Zero è notevole per aver raggiunto una performance sovrumana in Go attraverso l’apprendimento per rinforzo tramite auto-gioco, ma è stato Gary Marcus a spiegare a lungo quanto materiale incorporato – cioè innato, prima di imparare qualcosa su Go – possedesse AlphaGo Zero.
In effetti, le conoscenze di dominio utilizzate da AlphaGo Zero sono le seguenti, tratte direttamente dall’articolo di ricerca del 2017 (p. 360):
(1) Conoscenza perfetta delle regole del gioco utilizzate durante la ricerca ad albero Monte Carlo (MCTS).
(2) L’uso dello scoring di Tromp-Taylor durante le simulazioni MCTS e l’addestramento tramite auto-gioco: questa è una lista di 10 regole logiche che specificano diverse caratteristiche del gioco, tra cui la griglia 19×19, le pietre nere e bianche, ciò che conta come “pulizia” di un colore, e così via.
(3) I tratti di input che descrivono la posizione sono strutturati come un’immagine 19×19; “ovvero, l’architettura della rete neurale è abbinata alla struttura a griglia della tavola.”
(4) “Le regole del Go sono invarianti rispetto a rotazione e riflessione”: questa strana formulazione significa due cose: che il dataset è stato arricchito durante l’addestramento “per includere rotazioni e riflessioni di ogni posizione” e che “rotazioni o riflessioni casuali della posizione durante MCTS” sono state campionate utilizzando un algoritmo specifico.
Come un individuo umano non può inquadrare il mondo in termini morali senza una capacità morale distintiva innata dall’inizio, AlphaGo Zero non poteva nemmeno riconoscere la tavola da Go, le pietre, i movimenti sia della tavola che delle pietre e le regole del gioco senza questo dono innato. Inoltre, come nota Marcus, l’apparato MCTS non è stato affatto appreso dai dati, ma programmato dall’inizio, con la scelta di quali arricchimenti includere “effettuata con la conoscenza umana, piuttosto che appresa” (p. 8).
Descrivere AlphaGo Zero come una lavagna vuota perché viene addestrato tramite apprendimento per rinforzo tramite auto-gioco è estremamente fuorviante e non è stato una vittoria per l’empirismo. Piuttosto, come spiega correttamente Marcus, è un “esempio…del potere di includere fin dall’inizio le cose giuste…La convoluzione è la condizione che ha reso funzionare il campo del deep learning; la ricerca ad albero è stata vitale per il gioco. AlphaZero ha combinato le due cose” (p. 8-9). Infatti, proprio come i giudizi morali umani risultano da un processo strutturato nella mente che si basa principalmente su un sistema dedicato alle intuizioni morali mentre interagisce con altri sistemi, AlphaGo Zero non poteva gestire la complessità del Go semplicemente eliminando uno dei suoi componenti innati. E, come nota Artur d’Avila Garcez e Luís C. Lamb, MCTS è un risolutore di problemi simbolici, rendendo il suo accoppiamento con la rete neurale di AlphaGo Zero un elemento di IA neuro-simbolica.
Questo aspetto combinatorio dell’endowment innato di AlphaGo Zero è ciò che lo rende così impressionante e dovremmo apprezzare la sua conoscenza incorporata prima dell’addestramento così come la meraviglia dell’addestramento stesso.
Scelte di design uniche e combinatorie che strutturano riccamente il sistema per un problema specifico sono spesso responsabili dei maggiori successi delle intelligenze artificiali che giocano, anche se le tecniche come l’apprendimento per rinforzo e l’auto-gioco sono enfatizzate nei commenti a discapito di queste scelte. Questo è evidente in modo sorprendente in “Cicero” di Meta, l’agente che gioca a Diplomacy la cui attenzione è stata rubata dal rilascio otto giorni prima di ChatGPT.
Cicero, il primo agente a raggiungere una performance di livello umano, non sovrumano, in Diplomacy, esemplifica questi elementi combinatori in due modi: in primo luogo, a un livello elevato, il sistema combina il ragionamento strategico e la comunicazione in linguaggio naturale durante il gioco. In secondo luogo, l’architettura del sistema dipende da una combinazione di ricerca e tecniche tratte da aree che includono ragionamento strategico, elaborazione del linguaggio naturale e teoria dei giochi. Il risultato, come descrivono Gary Marcus ed Ernest Davis, è “una collezione di algoritmi altamente complessi e interagenti”.
Per avere successo in Diplomacy, i giocatori devono impegnarsi in ragionamenti strategici mentre cercano di acquisire la maggioranza dei centri di rifornimento sulla mappa. Questo elemento del gioco, che incorpora la competenza tattica da una mossa all’altra al servizio di un obiettivo generale, è simile ad altri giochi come Scacchi, Go e Poker, ognuno dei quali, ormai, è stato padroneggiato in un modo o nell’altro dall’IA. Ciò che differenzia Diplomacy è che i giocatori trascorrono molto tempo negoziando tra loro in un dialogo basato su testo o verbale.
Sembra piuttosto semplice, giusto? I giocatori negoziano tra loro per ottenere risultati favorevoli, facile. Ma non lo è. Ricorda, c’è una tendenza a sottostimare la complessità sia delle situazioni in cui si trovano i nostri giudizi morali, sia dei giudizi stessi. Diplomacy può essere ingannevole in modo analogo se non guardiamo da lontano. Allineare le capacità di ragionamento strategico di un agente con la comunicazione in linguaggio naturale è estremamente complesso.
L’architettura di Cicero può essere divisa tra un motore di pianificazione e un agente di dialogo. Il motore di pianificazione è responsabile del ragionamento strategico, mentre l’agente di dialogo gestisce la comunicazione in linguaggio naturale. In modo cruciale, queste due divisioni sono mediate da un meccanismo molto specifico (un “modello di azione condizionato dal dialogo”), e l’agente di dialogo è controllato dal motore di pianificazione. Questa struttura di alto livello garantisce che il motore di pianificazione possa generare intenzioni che vengono poi utilizzate per costruire gli obiettivi dell’agente. Queste informazioni vengono quindi fornite all’agente di dialogo in modo che la generazione di messaggi tra Cicero e gli altri giocatori rimanga allineata con gli obiettivi strategici dell’agente. Sebbene Cicero talvolta si contraddica, i suoi progettisti affermano che nessun essere umano ha identificato l’agente come un’intelligenza artificiale durante il gioco anonimo a più livelli, evidenziando il successo umano del sistema.
La struttura a livello inferiore ha una sua particolarità. Si potrebbe sospettare che, dato il successo di AlphaGo Zero attraverso l’autogioco, anche un agente di Diplomacy dovrebbe essere addestrato con questa tecnica. Ma, le ricerche precedenti a Cicero hanno rilevato che addestrare un agente di Diplomacy senza dati umani ha portato a un gioco relativamente povero contro gli esseri umani.
Neppure l’algoritmo di ricerca ad albero Monte Carlo è particolarmente utile qui. Mentre MCTS era stato testato in Diplomacy prima di Cicero (a mia conoscenza, principalmente nell’aspetto strategico del gioco, non tanto nell’aspetto della negoziazione), le differenze tra Go e Diplomacy lo rendono meno efficace. Go è un gioco asincrono in cui i giocatori fanno le loro mosse uno alla volta, trasmettendo così tutte le informazioni rilevanti sulla scacchiera al momento in cui il giocatore successivo si muove. Diplomacy è simultaneo: i giocatori negoziano, quindi inseriscono le loro azioni in modo privato, che vengono rivelate a tutti contemporaneamente. MCTS non può gestire bene questa struttura.
Ecco cosa ha fatto invece il team di Meta AI: basandosi sulla ricerca precedente sugli AI che giocano a Diplomacy, hanno costruito un algoritmo chiamato “piKL” (pronunciabile in modo accettabile come “pickle”). piKL è progettato per “interpolare” tra le due esigenze di cercare nuove strategie e imitare gli esseri umani. Questo algoritmo è fondamentale per il motore di pianificazione. Rifacendosi alla ricerca svolta per l’agente di poker Libratus, Meta AI afferma che “piKL tratta ogni mossa in Diplomacy come un proprio sottogioco…”
Inoltre, un modello generativo di linguaggio ampio sottostà all’agente di dialogo. Questo modello è stato perfezionato sul dialogo di giochi esistenti. Ma, i modelli linguistici sono svincolati dal contesto del mondo di Diplomacy e generano quindi output non coerenti con gli obiettivi strategici dell’agente (oltre ad essere facilmente manipolabili dagli esseri umani). Per aggirare questo problema, alcuni messaggi umani su cui è stato addestrato sono stati contrassegnati con azioni proposte, che rappresentano le intenzioni dei giocatori. Il modello linguistico è stato condizionato su queste intenzioni.
Possiamo cominciare a vedere come tutto questo si incastra. Durante il gioco, il motore di pianificazione seleziona le intenzioni rilevanti per controllare il modello linguistico. Questo controllo si basa su azioni veritiere per il sistema e azioni reciprocamente vantaggiose per il destinatario della comunicazione (il sistema modella le azioni per ogni giocatore).
Implicazioni
Cicero è un capolavoro di ingegneria. È anche uno degli esempi più sorprendenti di un sistema di intelligenza artificiale che compie un’impresa distintivamente umana con un ricco endowment altamente strutturato codificato con una certa conoscenza di dominio. Questi componenti interni si interfacciano in modo relativamente produttivo nell’allineamento del ragionamento strategico e della comunicazione in linguaggio naturale. Marcus e Davis sono stati tra i pochi che hanno subito riconosciuto l’importanza di questo sistema al di là del gioco di Diplomacy: “Se Cicero è un punto di riferimento, l’apprendimento automatico potrebbe alla fine dimostrarsi ancora più prezioso se incorporato in sistemi altamente strutturati, con una buona dose di macchine innatamente neurosimboliche”.
Tuttavia, molti nell’intelligenza artificiale ritengono che questo sia fuorviante: sì, l’intelligenza biologica può avere tutte le caratteristiche innate possibili, ma i sistemi di intelligenza artificiale potrebbero non averne bisogno. Esistono, secondo l’idea, altri modi per esprimere comportamenti intelligenti rispetto a quelli degli esseri umani. Basta guardare ad AlphaGo Zero: questo sistema, i cui componenti interni sono relativamente più semplici del cervello umano, gioca a Go meglio di qualsiasi essere umano al mondo. Perché concentrarsi sulla costruzione di cose più innate in un tale sistema quando fa già così bene il suo lavoro? E perché non cercare di ridurre al minimo il numero di componenti operative in Cicero mentre ci siamo?
Questo ipotetico interlocutore non vede l’intera situazione ma si concentra solo sui dettagli. Come spiega Marcus nel suo articolo del 2018: “mentre un essere umano può imparare molti giochi senza possedere particolari caratteristiche innate per un gioco specifico, ogni implementazione di [AlphaGo Zero] è dotata innatamente di caratteristiche specifiche del gioco che vincolano il sistema ad una particolare realizzazione di un particolare gioco, focalizzandosi su un particolare problema. Gli esseri umani sono molto più flessibili nel modo in cui affrontano i problemi” (p. 9).
Il passaggio da un’intelligenza “limitata” a un’intelligenza “generale” è direttamente collegato al problema dell’innatismo. E l’intelligenza biologica dimostra il motivo: sebbene sia vero che nessun individuo umano può giocare a Go al livello di AlphaGo Zero (ammesso che non si replichi nulla come KataGo vs. Kellin Pelrine con AlphaGo Zero), il sistema non potrebbe raggiungere questo punto senza una struttura innata altamente specifica, allo stesso modo in cui il giudizio morale umano assume un carattere molto specifico a causa della nostra struttura innata.
Le intuizioni provenienti dalla biologia nell’ambito dell’IA vanno oltre. Gli AI che giocano a giochi sono spesso notevoli perché consentono ai ricercatori di testare tecniche in ambienti in cui ci sono obiettivi ben definiti (cioè condizioni chiare per la vittoria) insieme a vincoli stabili (cioè regole del gioco, tavolo su cui si gioca, numero di giocatori, e così via). Questi giochi sono sfruttamenti isolati delle capacità cognitive umane, compresa la competenza tattica, il ragionamento strategico, la comunicazione in linguaggio naturale, l’inganno, la cooperazione e la collaborazione, l’onestà e la disonestà, e altri ancora.
Il problema è che AlphaGo Zero, Cicero e altre AI che giocano a giochi non stanno facendo ciò che facciamo quando giochiamo a Go, Diplomacy o a qualsiasi altro gioco di strategia. Come sottolinea l’interlocutore, trovano modi diversi per avere successo: AlphaGo Zero può giocare contro se stesso milioni di volte con un algoritmo di ricerca accuratamente migliorato appositamente progettato per Go; Cicero può negoziare senza la sensazione di essere tradito, guidando le sue azioni con una conoscenza “metagioco” sostanziale. Ma AlphaGo Zero non può formulare strategie al di fuori di Go, né riconoscere una scacchiera di Go che non soddisfa le dimensioni esatte per cui è stato programmatamente istruito a riconoscere; Cicero non può negoziare al di fuori di Diplomacy perché non sa come leggere intenzioni quanto ottimizza gli accordi che ciascuno troverebbe accettabili.
E qui sta il problema: quando gli esseri umani formulano strategie in Go, possono utilizzare questa capacità in qualsiasi altro gioco o contesto; quando gli esseri umani leggono le intenzioni in Diplomacy, possono utilizzare la stessa capacità cognitiva in qualsiasi situazione al di fuori del gioco, con flessibilità e robustezza, che sia nella diplomazia faccia a faccia o in una conversazione informale.
Il punto centrale è il seguente:
I modi “diversi” con cui le AI riescono a avere successo nei giochi in modi superiori agli esseri umani, rimanendo contemporaneamente confinate a questi domini, sono dovuti al potere della loro struttura innata. Sarà necessaria una nuova forma di struttura innata che si mescoli agli elementi di successo dell’apprendimento approfondito per compiere il salto da un’intelligenza limitata a un’intelligenza generale.
Conclusioni
L’idea di innatismo, secondo la mia esperienza, disturba le persone. Ma ciò che è interessante non è che le persone si sentano disturbate dall’idea che braccia, gambe, sistema circolatorio o midollo spinale umani siano innati; non lo sono. Piuttosto, le persone tendono a sentirsi disturbate dall’idea che le facoltà superiori della mente siano innate, come valori morali, lingue, senso musicale e simili.
Questo doppio standard è stato identificato come un potenziale ostacolo nelle scienze cognitive e neuroscienze, un pregiudizio implicito di qualche tipo, che ho sostenuto essere probabilmente responsabile di parte della resistenza all’innatismo nell’IA. La “fissazione” per l’apprendimento end-to-end di cui Rodney Brooks ha twittato potrebbe essere, in parte, il risultato di questo strano doppio standard che si è semplicemente inserito nell’IA, anziché essere unico nel campo.
Tuttavia, identificare solamente alza le carte in gioco nell’illustrare perché separazioni ordinate tra ingegneria e scienza nello sforzo di costruire un’intelligenza artificiale simile all’essere umano, o l’IA generale stessa, non saranno sufficienti per andare avanti. La mentalità che dice: “Vediamo solo cosa funziona e cosa non funziona” ha enormi vantaggi creativi, ma l’IA simile all’essere umano è una montagna troppo alta per essere scalata solo con questo. L’IA simile all’essere umano è, come illustrato, probabilmente una serie di problemi di ricerca ben strutturati che non possono permettersi di dare per scontate assunzioni implicite sulla biologia e sulle capacità cognitive negli esseri umani o negli animali.
Riferimenti:
[1] B. Alloui-Cros, Mastering Both the Pen and the Sword? Cicero in the Game of Diplomacy (2023), Substack
[2] A. Bakhtin, et al., No-Press Diplomacy from Scratch (2021), ArXiv
[3] N. Brown e T. Sandholm, Superintelligenza artificiale per il poker Heads-Up No-Limit (2017), Science
[4] V.J. Carchidi, I sottomarini nuotano? (2022), AI & Society
[5] N. Chomsky, Naturalismo e dualismo nello studio del linguaggio e della mente (1994), International Journal of Philosophical Studies
[6] D. Silver, et al., Dominare il gioco del Go senza conoscenza umana (2017), Nature
[7] G. Dupre, Cosa può contribuire l’apprendimento profondo alla linguistica teorica? (2021), Minds and Machines
[8] A. Garcez e L. Lamb, AI neurosimbolica: la terza ondata (2023), Artificial Intelligence Review
[9] M. Holmes, Diplomazia faccia a faccia (2018), Cambridge University Press
[10] A.P. Jacob, et al., Modellazione di un gioco forte e simile a quello umano con una ricerca regolarizzata da KL (2021), ArXiv
[11] R. Katzir, Perché i grandi modelli linguistici sono scarsi come teorie della cognizione linguistica umana. Una risposta a Piantadosi (2023), LingBuzz
[12] G. Marcus e E. Davis, Cosa significa la vittoria di Cicero di Meta AI per l’IA? (2022), Communications of the ACM
[13] G. Marcus, Innatismo, AlphaZero e intelligenza artificiale, ArXiv
[14] Meta Fundamental AI Research Diplomacy Team (FAIR), et al., Gioco di livello umano nel gioco della diplomazia combinando modelli linguistici con ragionamento strategico (2022), Science
[15] S. Piantadosi, I moderni modelli linguistici confutano l’approccio di Chomsky al linguaggio (2023), LingBuzz
[16] J. Rawski e L. Baumont, I moderni modelli linguistici non confutano nulla (2023), LingBuzz
[17] A. Theodoridis e G. Chalkiadakis, Ricerca dell’albero Monte Carlo per il gioco della diplomazia (2020), 11a Conferenza Ellenica sull’Intelligenza Artificiale
[18] S. Ullman, Utilizzare la neuroscienza per sviluppare l’intelligenza artificiale (2019), Science