Un modo semplice per migliorare i colloqui di Data Science
Migliorare i colloqui di Data Science in modo semplice
Identificazione dei primi 5% dei candidati tramite la formulazione di problemi tecnici
In questo post condivido una storia su un errore che ho commesso come inesperto responsabile delle assunzioni in Data Science e su come abbia cambiato il modo in cui conduco i colloqui tecnici. Illustrerò anche un esempio di domanda per un colloquio di Data Science e mostrerò come i candidati più qualificati affrontano il problema in modo diverso rispetto a quelli meno preparati. Sebbene mi concentri sulla Data Science, la maggior parte delle mie intuizioni e suggerimenti sono pertinenti per qualsiasi ruolo tecnico, compreso l’Ingegneria del Software, l’Ingegneria dei Dati, ecc.
Ma prima, una breve introduzione su di me.
Lavoro nell’Ingegneria del Software e nella Data Science/Machine Learning da circa nove anni. Ho lavorato in aziende di tutte le dimensioni: la più grande è Wayfair (13.000 dipendenti), la più piccola è l’attuale datore di lavoro, Fi (~100 dipendenti), dove ricopro il ruolo di VP dei Dati. Mi sto avvicinando a un punto di svolta in cui metà della mia carriera è stata trascorsa come Contributore Individuale (IC), e metà come Manager/Direttore/VP. Durante l’ultima metà, ho creato o ereditato team composti da due a 15 persone. In quel periodo, ho assunto circa 20 persone, condotto centinaia di colloqui e progettato innumerevoli percorsi di selezione.
Nel mio ruolo di responsabile delle assunzioni, ho fatto molte assunzioni di successo, ma ho anche commesso i miei errori lungo il cammino. Ad esempio, all’inizio della mia carriera come responsabile delle assunzioni, quando mi è stato affidato il compito di costruire un percorso di selezione da zero, ho commesso uno dei miei più grandi errori in termini di assunzioni. Mi ci è voluto ancora un anno o due per comprendere appieno l’errore commesso. Ma una volta che sono stato in grado di esprimerlo, ho capito che era evitabile e sono riuscito a prendere misure per assicurarmi che non si ripetesse.
- KPMG scommette oltre 2 miliardi di dollari sull’IA puntando a un fatturato di 12 miliardi di dollari
- Questo articolo sull’intelligenza artificiale valuta la capacità degli LLM di adattarsi a nuove varianti di compiti esistenti.
- Ottimizzazione delle prestazioni delle VM di Azure riducendo i costi strategie comprovate per un’efficienza ottimale
Questo post riguarda proprio quell’errore e cosa faccio per evitare di ripeterlo.
Il mio errore nelle assunzioni

Nel 2019, sono stato promosso da Senior Machine Learning Engineer a Lead Data Scientist, che era un ruolo di gestione. Il mio team stava cercando di sviluppare nuove applicazioni di modellazione che richiedevano modelli e integrazioni diverse da quelli che avevo già sviluppato. E poiché avevo da poco assunto un ruolo di gestione, non avevo la disponibilità di tempo per costruire tutta l’infrastruttura necessaria da solo. Quindi ho iniziato a cercare un Senior Data Scientist per aiutare a costruire e mantenere i nuovi modelli e le nuove integrazioni.
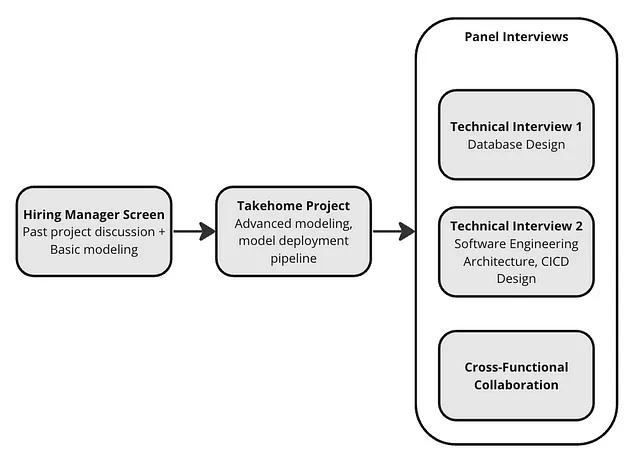
Processo di colloquio
Ho progettato un percorso di selezione che prevedeva un colloquio preliminare con il responsabile delle assunzioni, un progetto da svolgere a casa e alcuni colloqui di gruppo. Ad eccezione del colloquio interfunzionale, tutti i colloqui erano di natura tecnica e includevano sfide di machine learning, ingegneria dei dati o problemi di progettazione del software. In un paio di mesi, abbiamo trovato il candidato ideale.
Le prime settimane del nuovo assunto sono andate bene. E una volta che si sono messi al passo con la tecnologia utilizzata, i colleghi e il processo di lavoro, ho loro assegnato un progetto più ampio.
Emergono i sintomi
Dopo un paio di settimane sul progetto assegnato, ho notato che le loro attività richiedevano più tempo del previsto. Quindi ho dedicato loro del tempo extra ogni settimana per assicurarmi che le cose rimanessero in linea. Ma purtroppo, le cose non sono migliorate. Ogni volta che ci incontravamo per discutere dei progressi e dei prossimi passi, sembrava che non ci fossero progressi. Invece, emergevano ostacoli tecnici che, dal loro punto di vista, dovevano essere risolti per poter procedere. Ricordo di essermi sentito frustrato perché avevo difficoltà a capire come tutti gli ostacoli tecnici che sollevavano fossero così rilevanti, poiché sembravano venir fuori dal nulla.
Ricordo di essere stato due mesi nel progetto che avevamo previsto di completare in due settimane, eppure ancora non avevamo una soluzione funzionante. Peggio ancora, non avevamo nemmeno una tempistica chiara per il completamento.
Il problema sottostante
Ora che ho gestito e assunto persone per diversi anni, e ho visto sia successi che fallimenti con nuove assunzioni, sono in grado di spiegare esattamente qual era il problema sottostante e dove ho sbagliato.
Il problema sottostante era che mancavano di un insieme di competenze fondamentali per avere successo nel loro ruolo. Superficialmente, potrebbe sembrare che mancassero di abilità tecniche, dal momento che frequentemente emergevano ostacoli tecnici che non potevano risolvere rapidamente. Ma non era così. In realtà, le loro abilità tecniche erano eccezionali.
Invece, mancavano della capacità di comprendere la connessione tra l’applicazione tecnica e la necessità aziendale, il che impediva loro di sapere quando e come effettuare compromessi. Questo si manifestava come ostacoli tecnici insormontabili, ognuno dei quali avrebbe potuto essere evitato semplificando l’affermazione del problema.
Ad esempio, una delle sfide con cui si scontravano continuamente era legata alla dimensione del set di dati con cui stavano lavorando. Ma ogni volta che citavano questo come un problema, suggerivo di ridurre il set di dati solo alle tre o quattro caratteristiche di nostro interesse e filtrare solo i record che probabilmente erano rilevanti. In questo modo avremmo ridotto l’intero set di dati originale a meno dello 0,5% delle sue dimensioni, evitando qualsiasi problema legato al volume e ottenendo l’80% del valore aggiunto dell’intero set di dati. Ma ogni volta che facevo questa proposta, era chiaro che non ci avevano pensato, nonostante avessi sollevato la questione più volte.
Formulazione del problema tecnico
Per riassumere, il neo-assunto aveva difficoltà a mantenere una forte comprensione sia del contesto aziendale che del contesto tecnico contemporaneamente, quindi i compiti tecnici che si proponevano di risolvere erano spesso più complicati di quanto dovessero essere. In altre parole, avevano problemi con la formulazione del problema tecnico, che è la capacità di trasformare un obiettivo aziendale in un obiettivo tecnico e la capacità di comprendere come un insieme di requisiti rappresentino un obiettivo aziendale sottostante.
Per coloro che non sono familiari con la formulazione del problema tecnico o con il flusso di lavoro tipico di un team di Data Science, di solito i requisiti vengono forniti o dal Product Manager (PM) o dal responsabile/leader tecnico. Ma anche nei casi in cui i requisiti vengono forniti ai membri del team, non sono mai completamente esaustivi. Pertanto, è essenziale che i membri del team siano in grado di comprendere l’obiettivo che ha portato a quei requisiti. Se non riescono a farlo da soli, dovranno essere monitorati attentamente dal loro responsabile o dal PM. Questo limita la scalabilità del team e in genere causa attriti tra il membro del team e il suo responsabile/PM.
Riflettendo su questa situazione, è chiaro dove ho sbagliato: non ho costruito un colloquio che valutasse la formulazione del problema tecnico, e questa competenza era un requisito per il loro successo nel ruolo. Una volta realizzato questo, ho iniziato a sperimentare modi per integrare questa competenza nel mio processo di colloquio. Fortunatamente, la cosa più efficace che ho trovato richiedeva solo un piccolo aggiustamento.
Aggiustare i colloqui
Ecco cosa faccio in modo diverso.
Per almeno un colloquio tecnico, inserisco il compito tecnico in uno scenario aziendale reale in cui è necessario comprendere appieno il contesto aggiunto per risolvere adeguatamente il problema.
Oltre a valutare le abilità tecniche, questo colloquio modificato valuta anche la capacità del candidato di dedurre dai requisiti quale sia l’intenzione effettiva del progetto e quindi assicurarsi che questa intenzione venga raggiunta quando si progetta la soluzione tecnica.
Successivamente, illustrerò un esempio di colloquio che non valuta la formulazione del problema tecnico e discuterò cosa rappresenta una soluzione valida. Poi mostrerò lo stesso colloquio ma con l’aggiustamento della formulazione del problema tecnico e mostrerò come modifica ciò che viene considerato una soluzione valida.
Puoi trovare il set di dati originale che utilizzo per questo colloquio qui. Puoi anche trovare il prompt del colloquio configurato come un notebook Kaggle qui.
Esempio 1: Colloquio di modellazione Data Science SENZA valutazione della formulazione del problema tecnico
Ecco il prompt dell’intervista senza alcuna valutazione di problemi tecnici.
################################################ Intervista SENZA valutazione di problemi tecnici ## come parte della valutazione. ################################################# Ti abbiamo fornito un dataset# che consiste di informazioni sulla salute dei pazienti# legate all'arresto cardiaco (infarti).# Ogni record rappresenta un paziente che# ha visitato il Pronto Soccorso (PS) perché# stava avendo dolori al petto. Ogni colonna# corrisponde ad una misurazione che è stata# presa al momento del loro arrivo al PS, compreso# il tipo di dolore al petto che stavano# sperimentando. Il dataset contiene anche una# colonna binaria che indica se il paziente ha# avuto o meno un infarto# entro 48 ore dalla loro visita al PS.import pandas as pddf = pd.read_csv(f"{filepath}/heart.csv")display(df.head(5)# Il tuo compito è costruire un modello che# preveda se un candidato avrà o meno un# infarto basandosi sui dati di input forniti.def predict_heart_attack(row): """ Accetta una riga del dataset sugli infarti. Restituisce 0 o 1 come previsione. """ # TODO pass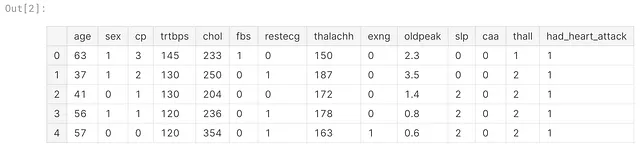
Usavo condurre questa intervista in un contesto dal vivo, dove era comodo avere un dataset piccolo e pulito con cui lavorare. Il dataset è piccolo (303 righe e 13 input) e relativamente pulito, quindi i candidati con qualsiasi esperienza di ML possono costruire un classificatore senza troppa difficoltà.
Valutazione
I candidati più deboli sono facili da identificare poiché di solito faticano a costruire anche un modello di base nel tempo assegnato, figuriamoci uno buono. Il compito più sfumato come intervistatore è identificare i candidati “buoni” rispetto ai candidati “eccellenti”. Oltre a dimostrare la capacità di costruire un classificatore funzionante in un breve lasso di tempo, i candidati più forti si differenziano tipicamente per (1) adottare un approccio iterativo: ottengono rapidamente qualcosa che funziona e poi lo migliorano e (2) prendere decisioni deliberate. Ad esempio, quando chiedo loro perché hanno scelto una misura di prestazione specifica per valutare la performance del loro modello, hanno una risposta specifica. I candidati più deboli o meno esperti daranno risposte, ma senza una vera giustificazione.
Esempio 2: Intervista di modellazione di Data Science CON valutazione di problemi tecnici
Ecco la stessa domanda di intervista, ma con uno scenario aziendale incorporato, quindi include la valutazione di problemi tecnici come parte di ciò che viene valutato.
################################################ Intervista CON valutazione di problemi tecnici come ## parte della valutazione. ################################################# Un Pronto Soccorso (PS) sta ricevendo un# numero schiacciante di pazienti che hanno# dolori al petto, che sono un sintomo di un# infarto. I pazienti che mostrano altri# sintomi di infarto dovrebbero essere# prioritizzati (accelerati) al momento di# entrare nella sala d'attesa del PS per# mitigare gli effetti dell'infarto o# evitarlo del tutto.## In media, il PS è in grado di accelerare# il 20% dei pazienti che stanno# sperimentando dolori al petto, consentendo loro# di saltare la coda dei pazienti. Attualmente,# la politica del PS è quella di# accelerare pazienti che stanno# sperimentando dolore al petto di Tipo 2 (angina# atipica). Questo corrisponde a un valore di# `df['cp'] == 1` nel dataset. Il personale del PS# ritiene che la loro politica attuale sia# subottimale e sta richiedendo che tu# effettui un'analisi su questi dati dei pazienti# per sviluppare una politica che# prioritizzi meglio i pazienti ad alto rischio.# # Ti abbiamo fornito un dataset# che consiste di informazioni sulla salute dei pazienti# legate agli infarti. Ogni record# rappresenta un paziente che ha visitato il PS# perché stava avendo dolori al petto.# Ogni colonna corrisponde ad una misurazione che# è stata presa al momento del loro arrivo al PS,# compreso il tipo di dolore al petto che stavano# sperimentando. Il dataset contiene anche una# colonna binaria che indica se il paziente ha# avuto o meno un infarto# entro 48 ore dalla loro visita al PS.import pandas as pddf = pd.read_csv(f"{filepath}/heart.csv")display(df.head(5)# Il tuo compito è utilizzare il dataset per costruire# una politica di accelerazione che sia migliore rispetto# alla politica attuale del PS.def fast_track(row): """ Accetta una riga del dataset sugli infarti. Restituisce 0 o 1 come decisione per l'accelerazione. """ # TODO passSi noti che gli aspetti tecnici del problema rimangono invariati: viene utilizzato lo stesso dataset e la firma della soluzione è la stessa. Tuttavia, ora sono presenti informazioni aggiuntive che modificano il profilo di una soluzione ideale.
Nuova formulazione del problema
Il contesto aziendale aggiunto introduce due nuove informazioni che il candidato deve comprendere prima di iniziare la soluzione. La prima è che esiste un vincolo secondo il quale solo il 20% dei pazienti può essere accelerato. Ciò corrisponde a 60,6 pazienti, o 61 se arrotondiamo per eccesso:
.20 * len(df) # Restituisce 60.6Quindi, il numero massimo di pazienti che possiamo “salvare” accelerandoli è 61, poiché il pronto soccorso non può accelerarne più di quello.
La seconda nuova informazione fornita dal contesto del pronto soccorso è che esiste una strategia di base che deve essere superata affinché la nuova politica venga considerata. Tale strategia di base prevede di prevedere correttamente 41 attacchi cardiaci:
# La strategia di base del pronto soccorso è di accelerare# ogni paziente con dolore al petto di tipo 2,# che corrisponde a# `df['cp'] == 1`. Quindi la strategia di base del pronto soccorso# consiste nel restituire 1 quando# df['cp'] == 1, e 0 altrimenti.( df.groupby(['cp'])[['had_heart_attack']] .agg(['mean', 'count']))
.82 * 50 # restituisce 41Combinando il vincolo aggiunto (61 accelerazioni totali) con l’obiettivo di superare la strategia di base (41 previsioni corrette), possiamo formulare il nuovo obiettivo come: trovare un classificatore che abbia una recall@k (con k=61) maggiore di 41.
Candidati deboli
I candidati che hanno difficoltà nella formulazione tecnica del problema trascurano queste due informazioni e passano immediatamente alla modalità di soluzione. Questo porta tipicamente a una delle due soluzioni subottimali: una con alta precisione, ma con una recall uguale o inferiore a 41, o una con alta recall ma con una precisione così scarsa che i primi 61 pazienti accelerati non produrranno più di 41 attacchi cardiaci. Come intervistatore, darò suggerimenti per indirizzare il candidato se vedo che sta andando nella direzione sbagliata. Alcuni candidati colgono i miei suggerimenti e correggono il tiro correttamente, mentre altri continuano a lottare per identificare il problema giusto da risolvere.
Candidati forti
I candidati che sono bravi nella formulazione tecnica del problema affrontano il problema in modo diverso. Invece di passare immediatamente alla modalità di soluzione, dedicano del tempo a leggere attentamente l’istruzione, spesso più volte, per assicurarsi di comprendere il contesto.
Successivamente, fanno qualcosa che è fortemente correlato al successo, e a cui presto molta attenzione:
I migliori candidati scrivono il loro approccio prima di iniziare e poi mi chiedono (l’intervistatore) se sembra ragionevole.
Quando osservo questo, è musica per le mie orecchie. Perché? Perché è esattamente ciò che voglio che facciano se dovessero entrare a far parte del mio team. Voglio qualcuno che sia in grado di esporre il suo piano in anticipo prima di immergersi in esso, e che abbia anche la consapevolezza di consultarmi prima di iniziare. Anche se ciò richiede più tempo all’inizio, riduce la necessità di tornare indietro e cambiare approcci a metà dell’intervista, assicurando che il tempo rimanente sia ben utilizzato.
I candidati che sono in grado di esporre correttamente il problema sono tipicamente in grado di risolvere anche la sfida. Questo non dovrebbe sorprendere, poiché non è molto difficile superare la strategia di base. Ad esempio, anche la seguente soluzione semplice basata su regole supera la strategia di base:
def fast_track(row): """ Una soluzione molto semplice che supera comunque la strategia di base. """ # "cp" è la colonna per il dolore al petto. if row['cp'] == 2 and row['sex'] == 0: return 1 elif row['cp'] == 1 and row['sex'] == 0: return 1 else: return 0# Verifica delle prestazionidf['pred'] = df.apply( lambda row: fast_track(row), axis=1)top_k_preds = df.sort_values('pred').tail(61)recall_at_k = len( top_k_preds .query('had_heart_attack == 1') .query(pred == 1))print(f"Recall@61 = {recall_at_k}")# Restituisce Recall@61 = 50Ma i punti bonus vengono sicuramente dati se il candidato riesce a esporre chiaramente il problema e a risolverlo al massimo (recupero perfetto a k=61).
Benefici dell’intervista per la definizione del problema tecnico
Il principale vantaggio dell’intervista per la definizione del problema tecnico è che le persone che superano e vengono quindi assunte sono in grado di operare con maggiore indipendenza. Poiché sono in grado di interiorizzare gli obiettivi che devono migliorare, possono ridurre la quantità di lavoro aggiuntivo necessario da parte del loro manager e dei Product Owner. Questo è fondamentale per amplificare l’impatto di un team tecnico, specialmente in organizzazioni più piccole dove c’è poco supporto da parte dei PM e i manager sono anche responsabili di progetti specifici, limitando la loro capacità di supervisionare molti progetti contemporaneamente.
Siamo riusciti a mantenere molto piccolo e agile il team dei Dati presso Fi, ad esempio, soprattutto grazie al fatto che abbiamo assunto solo persone con una forte capacità di definire il problema tecnico. Attualmente siamo un team di soli quattro individui (presto saranno cinque), eppure copriamo tutte le esigenze relative ai dati per un’azienda di oltre 100 persone e gestiamo tutti i processi ETL, la progettazione e la manutenzione del Data Warehouse, i report di Tableau, le analisi approfondite e delle cause radici, l’apprendimento automatico e la modellazione predittiva, e più recentemente la ricerca e sviluppo per lo sviluppo di nuove funzionalità. E i domini che copriamo riguardano letteralmente ogni aspetto del business: Finanza, Marketing, Esperienza del Cliente, Ingegneria, Hardware, Firmware, Operazioni e Prodotto. Il motivo per cui siamo in grado di assumerci così tanto lavoro e coprire così tanti domini è che tutti nel team sono capaci di prendere un problema poco definito e mapparlo in una dichiarazione di problema tecnico.
Prossimamente
Restate sintonizzati per un futuro articolo in cui parlerò di come migliorare la vostra capacità di definire problemi tecnici e di come migliorare la capacità del vostro team se siete un manager.