Machine Learning a Effetti Misti per Variabili Categoriche ad Alta Cardinalità – Parte II Libreria GPBoost
Machine Learning Effetti Misti per Variabili Categoriche ad Alta Cardinalità - Parte II GPBoost
Una dimostrazione di GPBoost in Python & R utilizzando dati reali
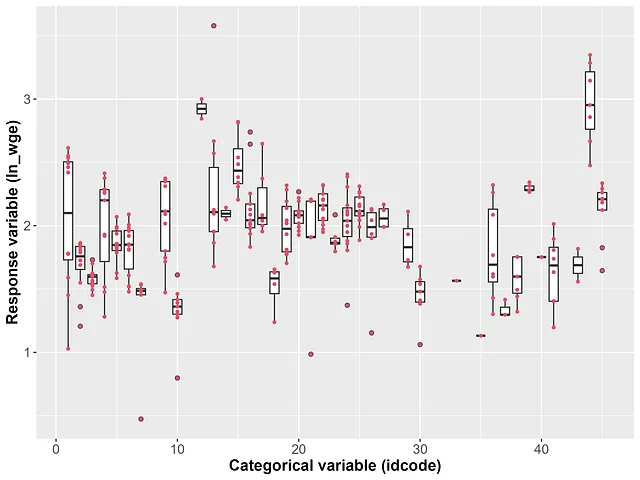
Le variabili categoriche ad alta cardinalità sono variabili per le quali il numero di livelli diversi è grande rispetto alla dimensione del campione di un dataset. Nella Parte I di questa serie, abbiamo effettuato un confronto empirico tra diversi metodi di apprendimento automatico e abbiamo scoperto che gli effetti casuali sono uno strumento efficace per gestire le variabili categoriche ad alta cardinalità con l’algoritmo GPBoost [Sigrist, 2022, 2023] che presenta la maggiore precisione di previsione. In questo articolo, mostriamo come l’algoritmo GPBoost, che combina il tree-boosting con gli effetti casuali, può essere applicato con le librerie Python e R del pacchetto GPBoost. In questa demo viene utilizzata la versione 1.2.1 di GPBoost.
Indice
∘ 1 Introduzione∘ 2 Dati: descrizione, caricamento e suddivisione dei campioni∘ 3 Allenamento di un modello GPBoost∘ 4 Scelta dei parametri di sintonizzazione∘ 5 Previsione∘ 6 Interpretazione∘ 7 Ulteriori opzioni di modellazione · · 7.1 Interazione tra variabili categoriche e altre variabili predittive · · 7.2 Modelli di effetti misti lineari (generalizzati)∘ 8 Conclusioni e riferimenti
1 Introduzione
L’applicazione di un modello GPBoost comporta i seguenti passaggi principali:
- Definire un
GPModelin cui si specificano i seguenti elementi: — Un modello di effetti casuali: effetti casuali raggruppati tramitegroup_datae/o processi gaussiani tramitegp_coords— Lalikelihood(= distribuzione della variabile di risposta condizionata agli effetti fissi e casuali) - Creare un
Datasetcontenente la variabile di risposta (label) e le variabili predittive ad effetti fissi (data) - Scegliere i parametri di sintonizzazione, ad esempio utilizzando la funzione
gpb.grid.search.tune.parameters - Allenare il modello
- Eseguire previsioni e/o interpretare il modello allenato
Nel seguito, affrontiamo questi punti passo dopo passo.