Implementa un indice di ricerca intelligente dei documenti con Amazon Textract e Amazon OpenSearch
Implement an intelligent document search index with Amazon Textract and Amazon OpenSearch
Per le aziende moderne che si occupano di enormi volumi di documenti come contratti, fatture, curriculum e report, elaborare ed estrarre in modo efficiente i dati pertinenti è fondamentale per mantenere un vantaggio competitivo. Tuttavia, i metodi tradizionali di archiviazione e ricerca dei documenti possono richiedere molto tempo e spesso comportano un grande sforzo per trovare un documento specifico, soprattutto quando includono scrittura a mano. E se ci fosse un modo per elaborare i documenti in modo intelligente e renderli ricercabili con elevata precisione?
Tutto ciò è reso possibile grazie a Amazon Textract, il servizio di elaborazione intelligente dei documenti di AWS, abbinato alle rapide capacità di ricerca di OpenSearch. In questo articolo, ti guideremo nella rapida creazione e implementazione di una soluzione di indicizzazione per la ricerca di documenti che aiuterà la tua organizzazione a sfruttare al meglio ed estrarre informazioni dai documenti.
Sia che tu sia nel reparto delle Risorse Umane alla ricerca di clausole specifiche nei contratti dei dipendenti, o un analista finanziario che si frappone a una montagna di fatture per estrarre dati di pagamento, questa soluzione è progettata per fornirti un accesso alle informazioni di cui hai bisogno con una velocità e precisione senza precedenti.
Con la soluzione proposta, i tuoi documenti vengono automaticamente acquisiti, il loro contenuto viene analizzato e successivamente indicizzato in un indice OpenSearch altamente reattivo e scalabile.
- NVIDIA si allea con i giganti indiani per far avanzare l’IA nella nazione più popolosa del mondo
- 2 Senatori propongono un quadro bipartisan per le leggi sull’intelligenza artificiale
- Prima parte del corpo di origine umana stampata in 3D nello spazio
Esamineremo come tecnologie come Amazon Textract, AWS Lambda, Amazon Simple Storage Service (Amazon S3) e Amazon OpenSearch Service possono essere integrate in un flusso di lavoro che elabora senza soluzione di continuità i documenti. Successivamente, ci immergeremo nell’indicizzazione di questi dati in OpenSearch e mostreremo le capacità di ricerca che diventano disponibili a portata di mano.
Sia che la tua organizzazione stia compiendo i primi passi nell’era della trasformazione digitale o sia un gigante consolidato alla ricerca di un’accelerazione del recupero delle informazioni, questa guida è la tua bussola per navigare nelle opportunità offerte da AWS Intelligent Document Processing e OpenSearch.
L’implementazione utilizzata in questo articolo utilizza i costrutti CDK di Amazon Textract IDP – componenti AWS Cloud Development Kit (CDK) per definire l’infrastruttura per i flussi di lavoro di Intelligent Document Processing (IDP) – che ti consentono di creare flussi di lavoro IDP personalizzabili per casi d’uso specifici. I costrutti e gli esempi di CDK di IDP sono una collezione di componenti che consentono di definire processi IDP su AWS e pubblicarli su GitHub. I principali concetti utilizzati sono i costrutti AWS Cloud Development Kit (CDK), gli stack CDK effettivi e le AWS Step Functions. Il workshop Use machine learning to automate and process documents at scale è un buon punto di partenza per saperne di più sulla personalizzazione dei flussi di lavoro e sull’utilizzo degli altri flussi di lavoro di esempio come base per i propri.
Panoramica della soluzione
In questa soluzione, ci concentriamo sull’indicizzazione dei documenti in un indice OpenSearch per una rapida ricerca e recupero delle informazioni e dei documenti. I documenti in formato PDF, TIFF, JPEG o PNG vengono inseriti in un bucket di Amazon Simple Storage Service (Amazon S3) e successivamente indicizzati in OpenSearch utilizzando questo flusso di lavoro di Step Functions.
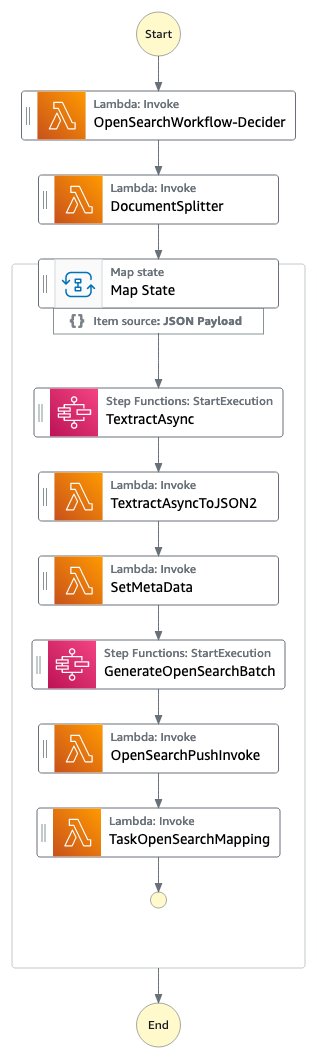
Figura 1: Il flusso di lavoro OpenSearch di Step Functions
Il Decider del flusso di lavoro OpenSearch analizza il documento e verifica che il documento sia uno dei tipi MIME supportati (PDF, TIFF, PNG o JPEG). È composto da una funzione AWS Lambda.
Il DocumentSplitter genera un massimo di 2500 pagine da documenti. Ciò significa che anche se Amazon Textract supporta documenti fino a 3000 pagine, è possibile passare documenti con molte più pagine e il processo funziona comunque correttamente, inserendo le pagine in OpenSearch e creando i numeri di pagina corretti. Il DocumentSplitter è implementato come una funzione AWS Lambda.
Lo Stato di Map elabora ogni chunk in parallelo.
Il task TextractAsync chiama Amazon Textract utilizzando l’interfaccia di programmazione asincrona (API) seguendo le best practice con le notifiche di Amazon Simple Notification Service (Amazon SNS) e l’OutputConfig per archiviare l’output JSON di Amazon Textract in un bucket Amazon S3 del cliente. È composto da due funzioni Amazon Lambda: una per inviare il documento per l’elaborazione e una che viene attivata sulla notifica di Amazon SNS.
Poiché il task TextractAsync può produrre più file di output paginati, il processo TextractAsyncToJSON2 li combina in un unico file JSON.
Il contesto di Step Functions viene arricchito con informazioni che dovrebbero essere anche ricercabili nell’indice OpenSearch nel passaggio SetMetaData. L’implementazione di esempio aggiunge ORIGIN_FILE_NAME, START_PAGE_NUMBER e ORIGIN_FILE_URI. Puoi aggiungere qualsiasi informazione per arricchire l’esperienza di ricerca, come informazioni provenienti da altri sistemi backend, ID specifici o informazioni di classificazione.
Il GenerateOpenSearchBatch prende l’output JSON generato da Amazon Textract, lo combina con le informazioni del contesto impostate da SetMetaData e prepara un file ottimizzato per l’importazione in batch in OpenSearch.
In OpenSearchPushInvoke, questo file di importazione in batch viene inviato nell’indice OpenSearch e reso disponibile per la ricerca. Questa funzione AWS Lambda è collegata alla struttura aws-lambda-opensearch della libreria AWS Solutions utilizzando le istanze di ricerca m6g.large.search, la versione OpenSearch 2.7 e la configurazione della dimensione del volume del servizio di blocco elastico Amazon (Amazon EBS) a General Purpose 2 (GP2) con 200 GB. Puoi modificare la configurazione di OpenSearch in base alle tue esigenze.
Il passaggio finale TaskOpenSearchMapping cancella il contesto, che altrimenti potrebbe superare la quota di Step Functions di Dimensioni massime di input o output per un’attività, uno stato o un’esecuzione.
Prerequisiti
Per distribuire gli esempi, è necessario un account AWS, il kit di sviluppo cloud AWS (AWS CDK), una versione corrente di Python e Docker. È necessario disporre di autorizzazioni per distribuire modelli di AWS CloudFormation, caricare nel registro dei contenitori elastici Amazon (Amazon ECR), creare ruoli di gestione dell’accesso e dell’identità di Amazon (AWS IAM), funzioni Lambda di Amazon, secchi Amazon S3, funzioni Step di Amazon, cluster OpenSearch di Amazon e un pool di utenti Amazon Cognito. Assicurati che il tuo ambiente AWS CLI sia configurato con le autorizzazioni corrispondenti.
Puoi anche avviare un’istanza di AWS Cloud9 con AWS CDK, Python e Docker preinstallati per avviare la distribuzione.
Procedura guidata
Distribuzione
- Dopo aver configurato i prerequisiti, devi prima clonare il repository:
git clone https://github.com/aws-solutions-library-samples/guidance-for-low-code-intelligent-document-processing-on-aws.git- Quindi entra nella cartella del repository e installa le dipendenze:
cd guidance-for-low-code-intelligent-document-processing-on-aws/
pip install -r requirements.txt- Effettua il deploy dello stack OpenSearchWorkflow:
cdk deploy OpenSearchWorkflowIl deployment richiede circa 25 minuti con le impostazioni di configurazione predefinite degli esempi di GitHub e crea un workflow di Step Functions, che viene invocato quando un documento viene inserito in un bucket/prefix di Amazon S3 e successivamente viene elaborato fino a quando il contenuto del documento viene indicizzato in un cluster OpenSearch.
Di seguito è riportato un output di esempio che include collegamenti utili e informazioni generate dal comandocdk deploy OpenSearchWorkflow:
OpenSearchWorkflow.CognitoUserPoolLink = https://us-east-1.console.aws.amazon.com/cognito/v2/idp/user-pools/us-east-1_1234abcdef/users?region=us-east-1
OpenSearchWorkflow.DocumentQueueLink = https://us-east-1.console.aws.amazon.com/sqs/v2/home?region=us-east-1#/queues/https%3A%2F%2Fsqs.us-east-1.amazonaws.com%2F123412341234%2FOpenSearchWorkflow-ExecutionThrottleDocumentQueueABC1234-ABCDEFG1234.fifo
OpenSearchWorkflow.DocumentUploadLocation = s3://opensearchworkflow-opensearchworkflowbucketabcdef1234/uploads/
OpenSearchWorkflow.OpenSearchDashboard = https://search-idp-cdk-opensearch-abcdef1234.us-east-1.es.amazonaws.com/states/_dashboards
OpenSearchWorkflow.OpenSearchLink = https://us-east-1.console.aws.amazon.com/aos/home?region=us-east-1#/opensearch/domains/idp-cdk-opensearch
OpenSearchWorkflow.StepFunctionFlowLink = https://us-east-1.console.aws.amazon.com/states/home?region=us-east-1#/statemachines/view/arn:aws:states:us-east-1:123412341234:stateMachine:OpenSearchWorkflow12341234Questa informazione è disponibile anche nella Console di AWS CloudFormation.
Quando viene inserito un nuovo documento sotto OpenSearchWorkflow.DocumentUploadLocation, viene avviato un nuovo workflow di Step Functions per questo documento.
Per verificare lo stato di questo documento, il OpenSearchWorkflow.StepFunctionFlowLink fornisce un collegamento all’elenco delle esecuzioni di StepFunction nella Console di gestione AWS, visualizzando lo stato dell’elaborazione del documento per ogni documento caricato su Amazon S3. Il tutorial “Visualizzare e debuggare le esecuzioni nella console Step Functions” fornisce una panoramica dei componenti e delle visualizzazioni nella Console AWS.
Testing
- Primo test utilizzando un file di esempio.
aws s3 cp s3://amazon-textract-public-content/idp-cdk-samples/moby-dick-hidden-paystub-and-w2.pdf $(aws cloudformation list-exports --query 'Exports[?Name==`OpenSearchWorkflow-DocumentUploadLocation`].Value' --output text)- Dopo aver selezionato il collegamento al flusso di lavoro di StepFunction o aperto la Console di gestione AWS e recandosi alla pagina del servizio Step Functions, è possibile visualizzare le diverse invocazioni del flusso di lavoro.
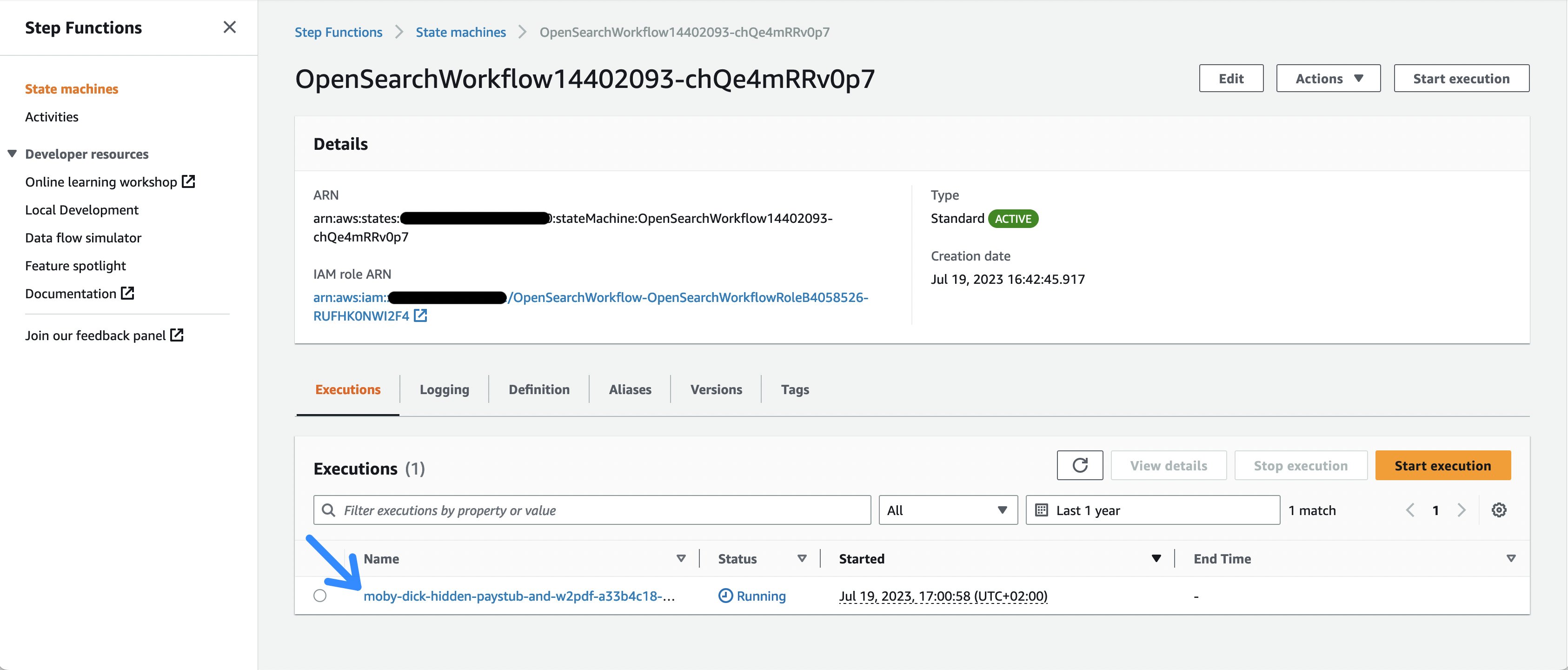
Figura 2: Elenco delle esecuzioni di Step Functions
- Dare un’occhiata all’esecuzione del documento di esempio attualmente in esecuzione, dove è possibile seguire l’esecuzione delle singole attività del flusso di lavoro.
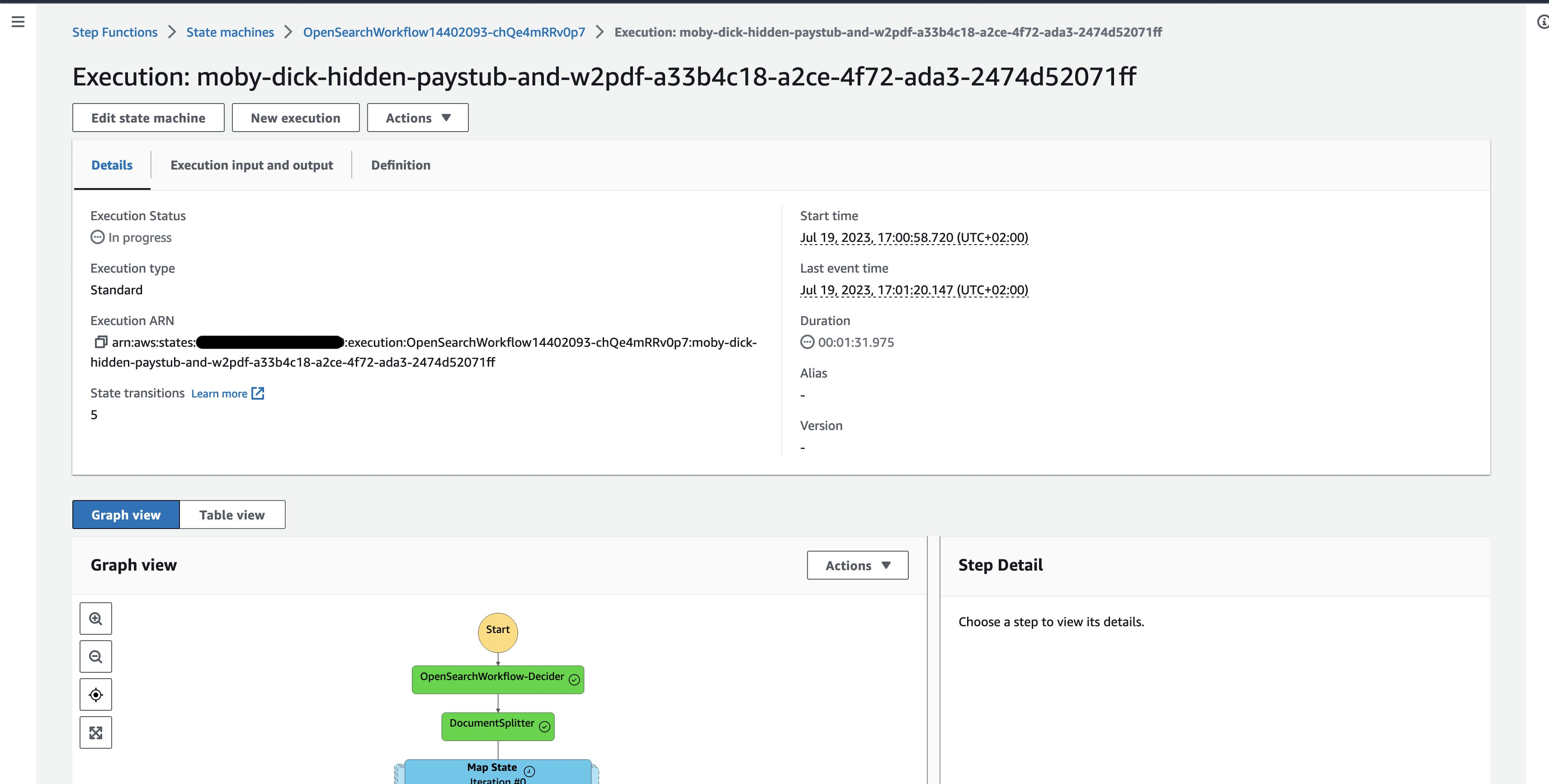
Figura 3: Esecuzione di un flusso di lavoro di Step Functions per un documento
Ricerca
Una volta che il processo è terminato, possiamo verificare che il documento sia indicizzato nell’indice di OpenSearch.
- Per farlo, prima creiamo un utente Amazon Cognito. Amazon Cognito viene utilizzato per l’autenticazione degli utenti contro l’indice di OpenSearch. Selezionare il collegamento nell’output del comando cdk deploy (o guardare l’output di AWS CloudFormation nella Console di gestione AWS) chiamato OpenSearchWorkflow.CognitoUserPoolLink.
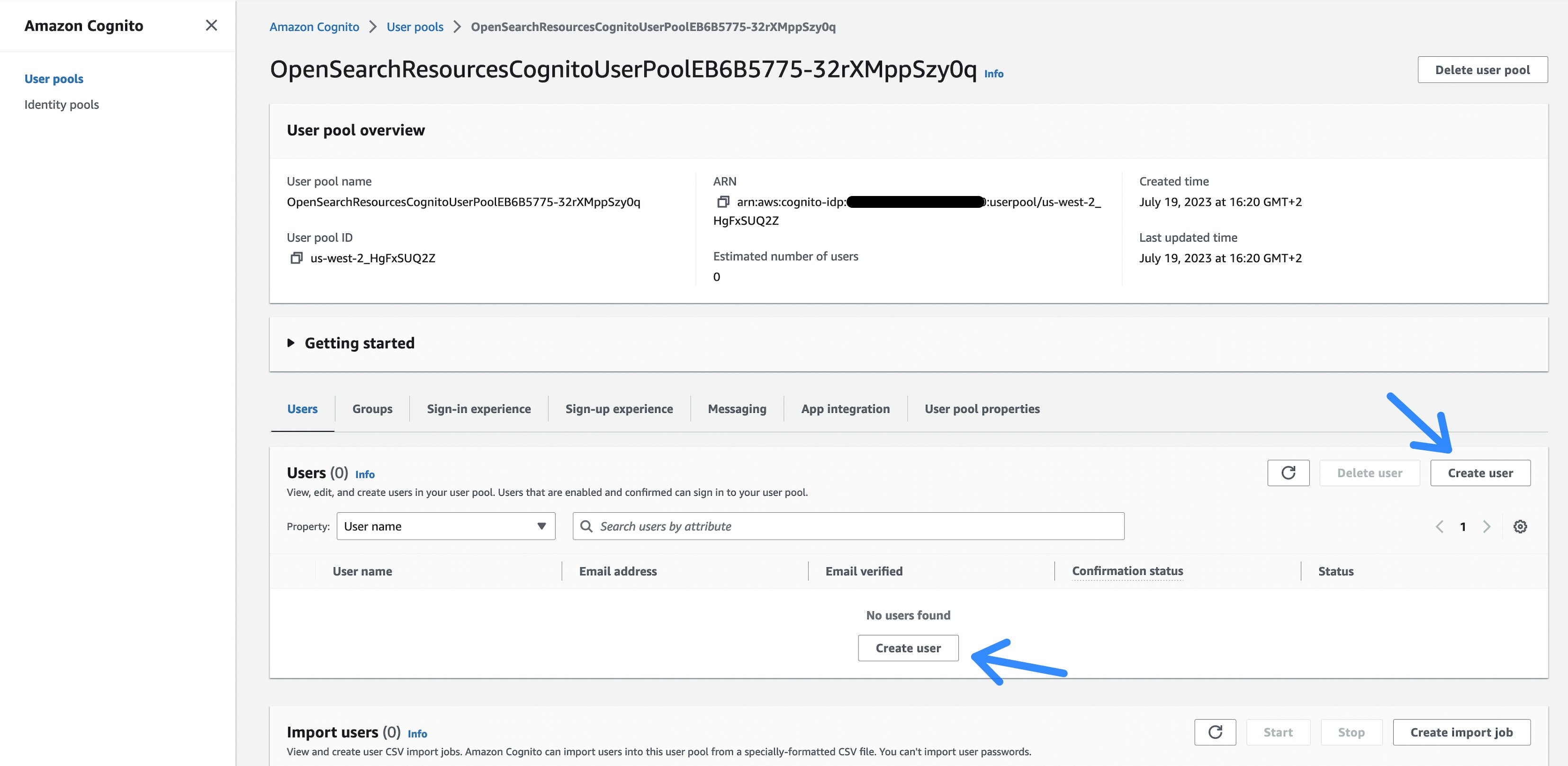
Figura 4: Pool di utenti Cognito
- Successivamente, selezionare il pulsante Crea utente, che vi indirizza a una pagina per inserire un nome utente e una password per accedere al dashboard di OpenSearch.
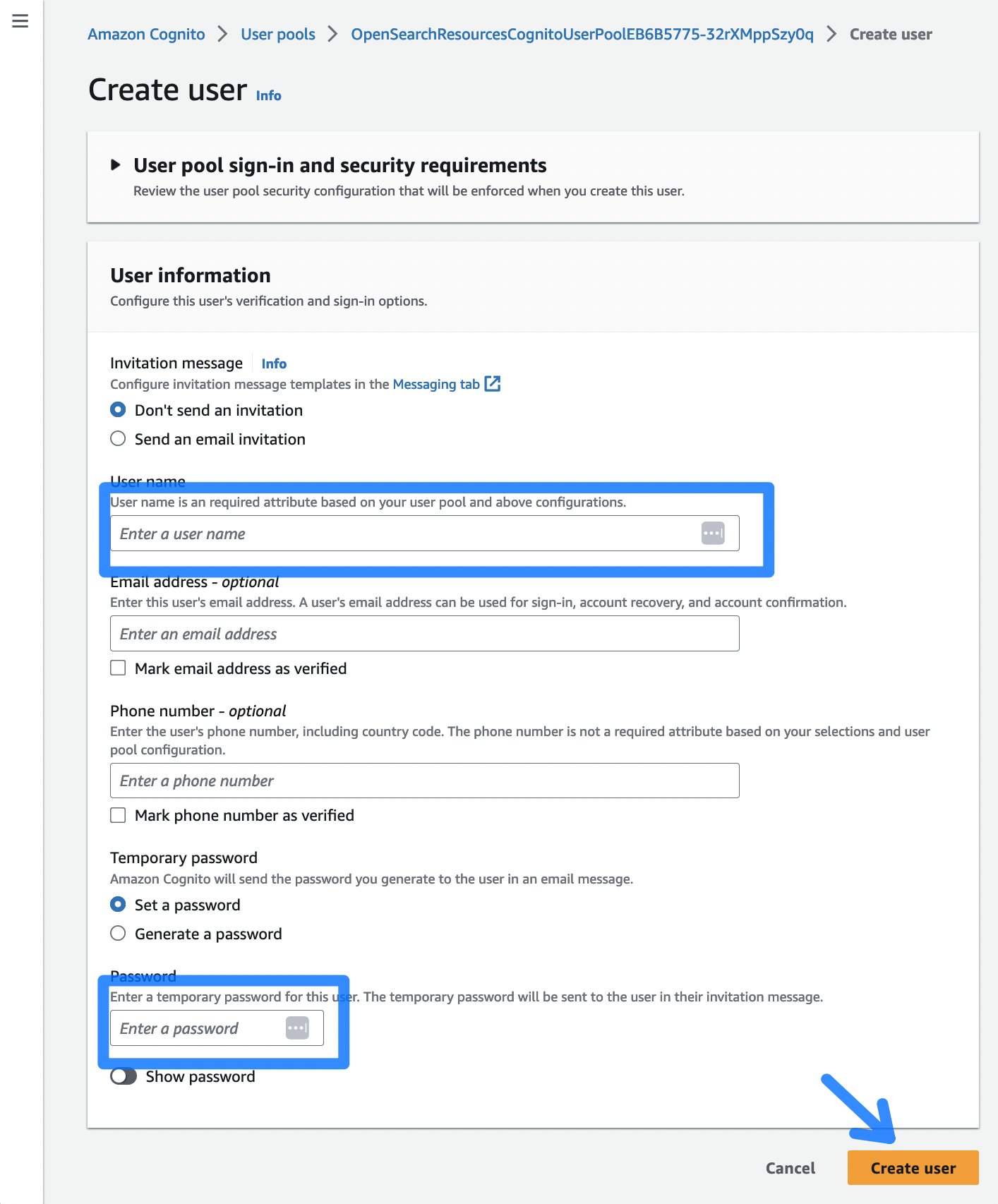
Figura 5: Dialogo di creazione utente Cognito
- Dopo aver scelto Crea utente, è possibile continuare con il dashboard di OpenSearch cliccando su OpenSearchWorkflow.OpenSearchDashboard dall’output del deployment di CDK. Effettuare l’accesso utilizzando il nome utente e la password precedentemente creati. La prima volta che si effettua l’accesso, è necessario cambiare la password.
- Dopo aver effettuato l’accesso al dashboard di OpenSearch, selezionare la sezione Gestione dello stack, seguita da Pattern di indicizzazione per creare un indice di ricerca.
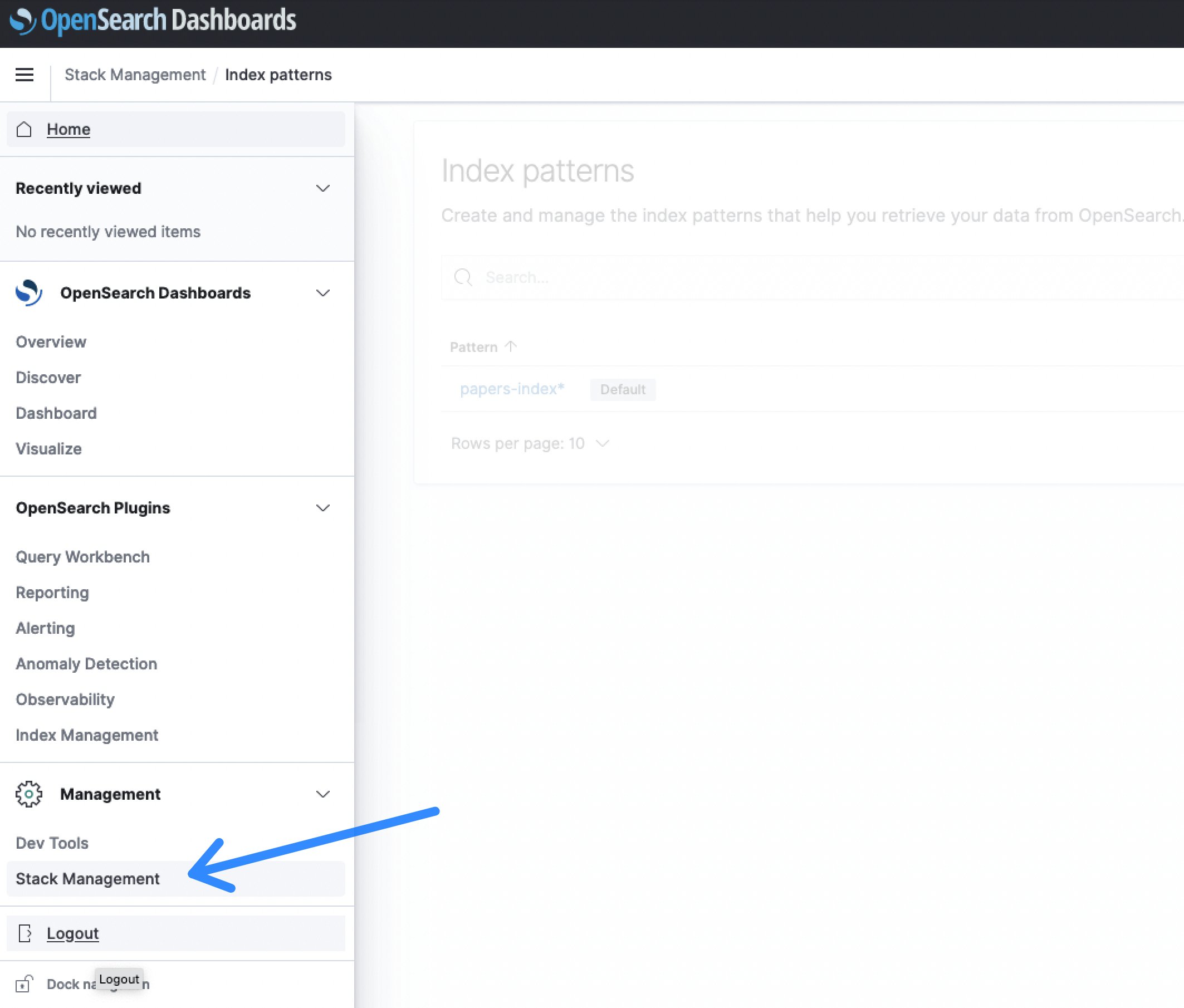
Figura 6: Gestione stack di OpenSearch Dashboards
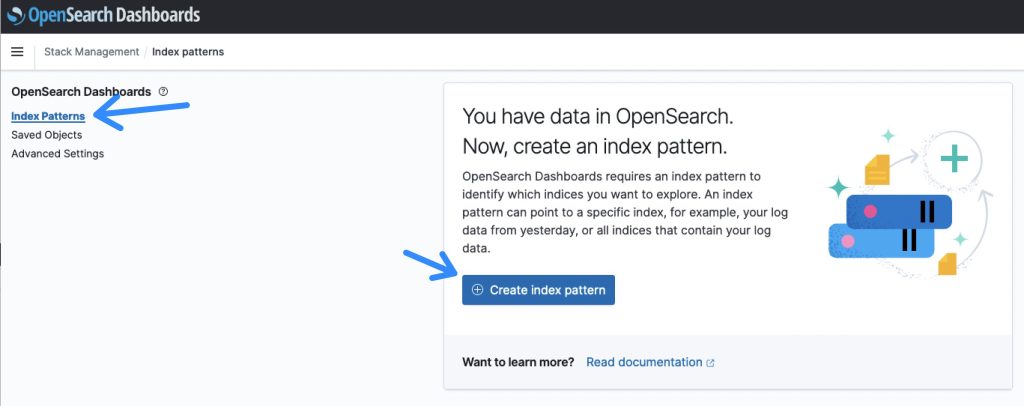
Figura 7: Panoramica dei pattern di indicizzazione di OpenSearch
- Il nome predefinito per l’indice è papers-index e un nome di pattern di indicizzazione papers-index* corrisponderà a quello.
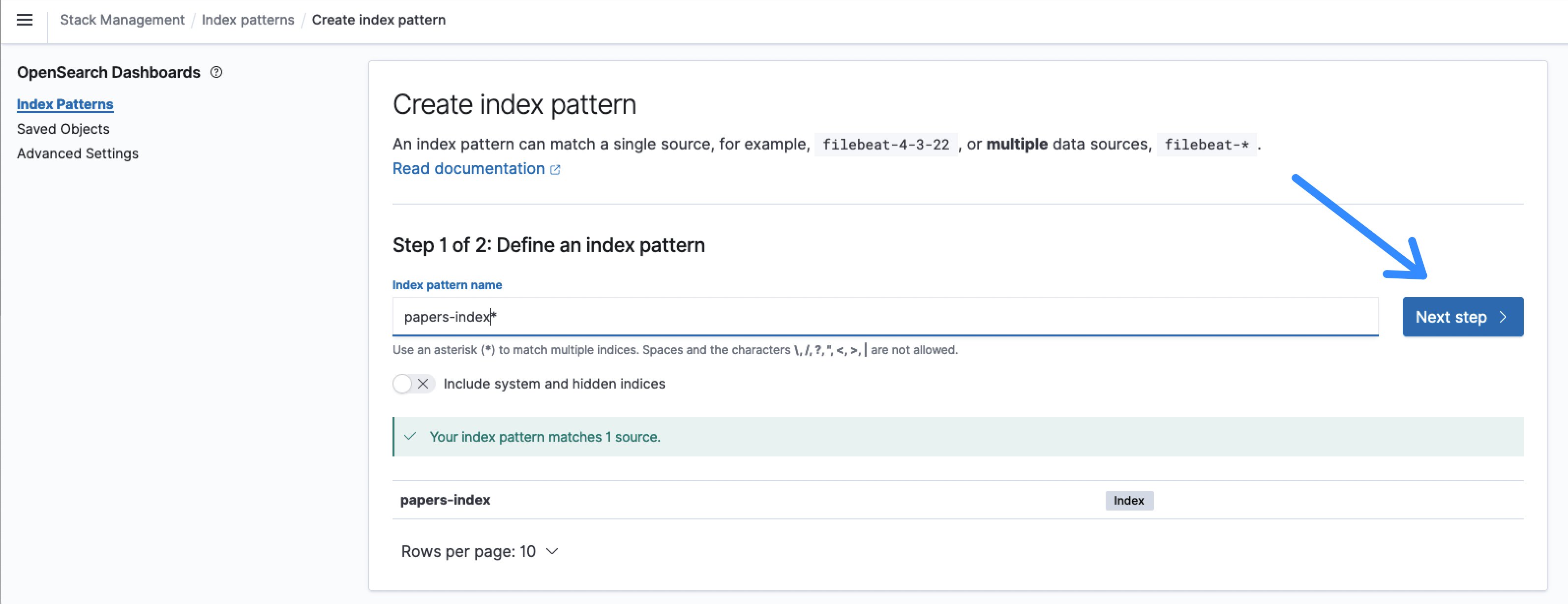
Figura 8: Definire il modello di indice OpenSearch
- Dopo aver cliccato su Passaggio successivo, selezionare timestamp come Campo temporale e Crea modello di indice.
Figura 9: Campo temporale del modello di indice OpenSearch
- Ora, dal menu, selezionare Scopri.
Figura 10: Scopri OpenSearch
Nella maggior parte dei casi, è necessario modificare l’intervallo temporale in base all’ultimo inserimento. Il valore predefinito è di 15 minuti e spesso non c’è stata attività negli ultimi 15 minuti. In questo esempio, è stato modificato in 15 giorni per visualizzare l’inserimento.
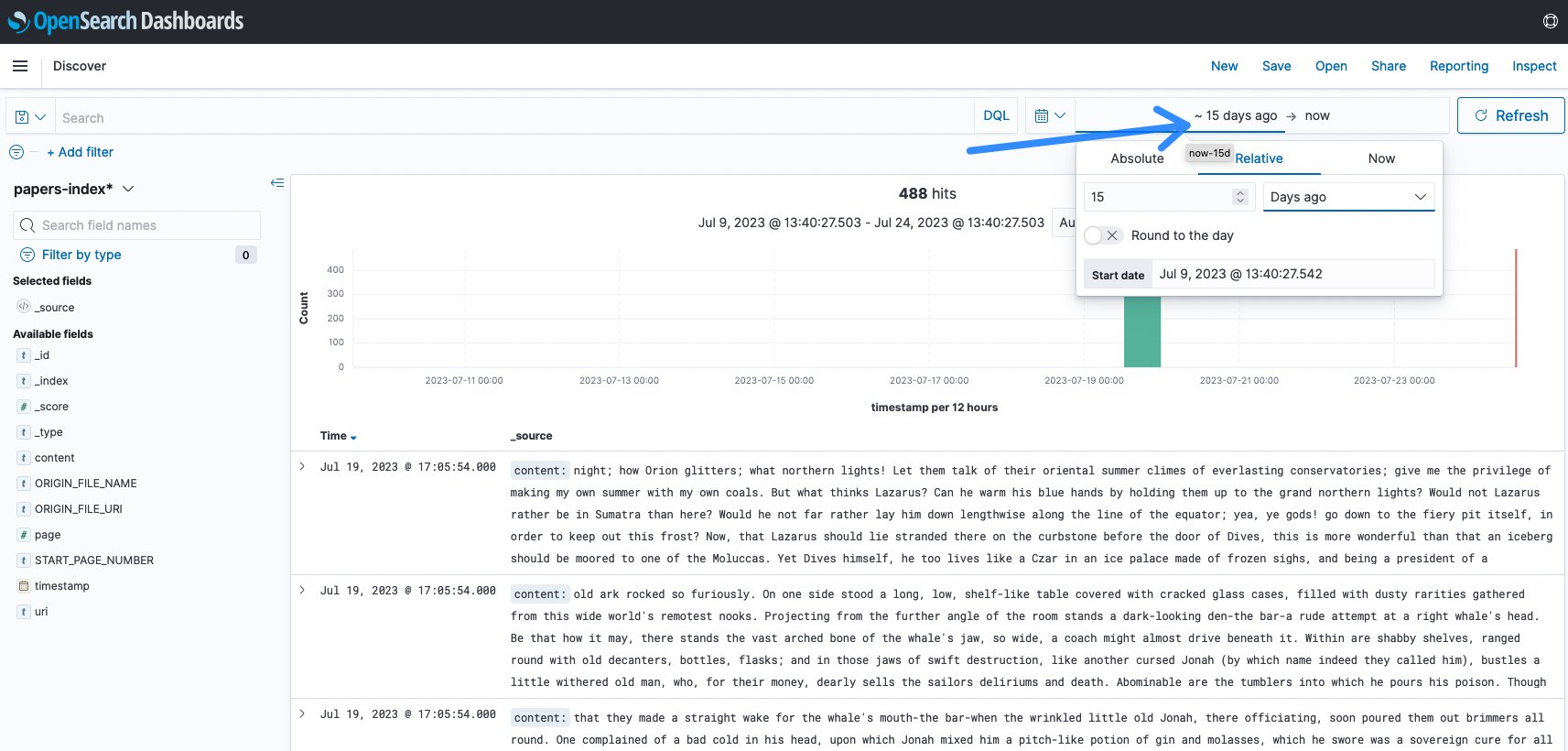
Figura 11: Modifica dell’intervallo temporale di OpenSearch
- Ora puoi iniziare la ricerca. È stato indicizzato un romanzo, puoi cercare qualsiasi termine come chiamami Ismaele e vedere i risultati.
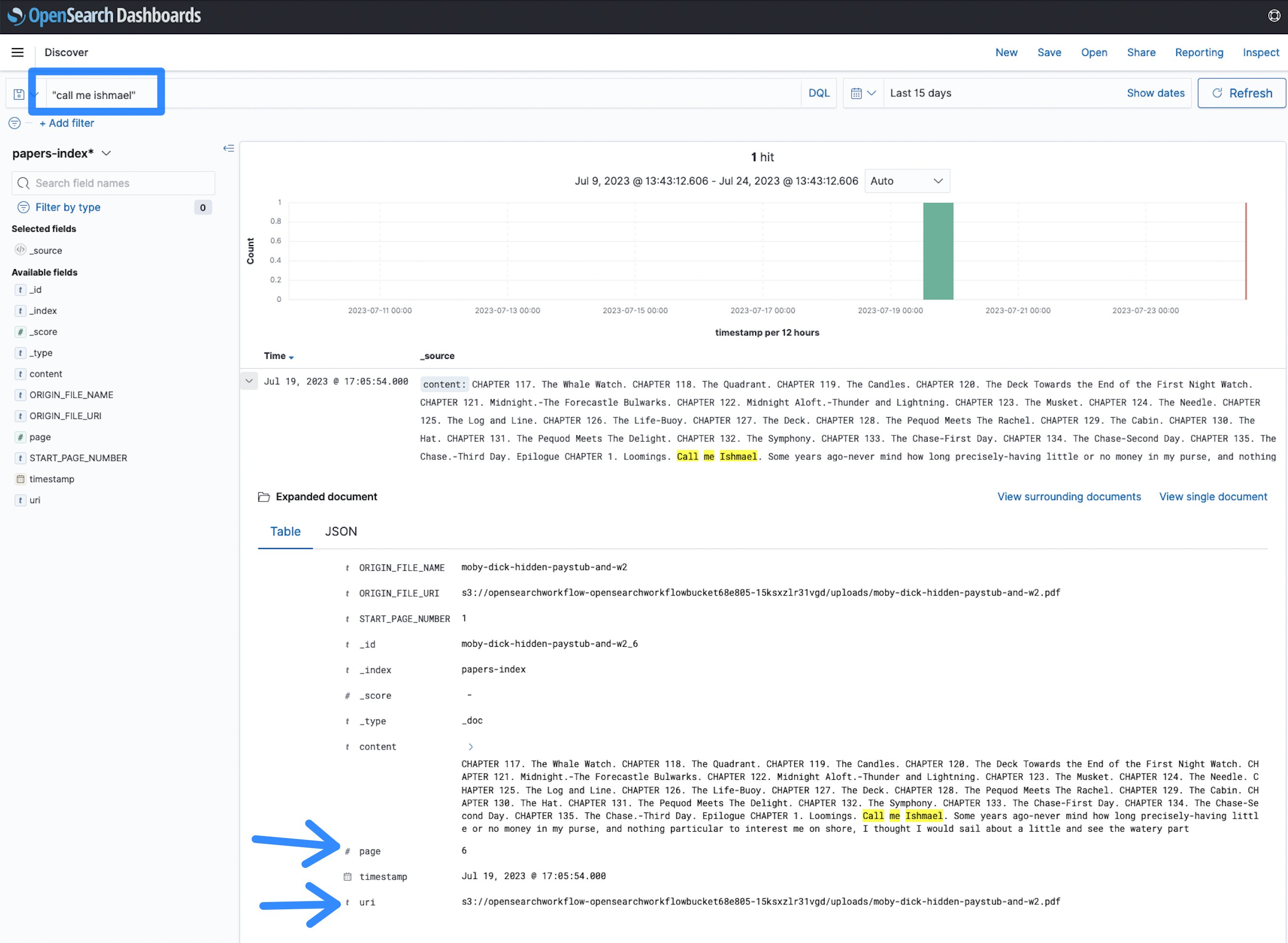
Figura 12: Termine di ricerca di OpenSearch
In questo caso, il termine chiamami Ismaele compare nella pagina 6 del documento all’URI (Uniform Resource Identifier) specificato, che indica la posizione di file su Amazon S3. Ciò consente di identificare più rapidamente i documenti e trovare informazioni in un ampio corpus di documenti in formato PDF, TIFF o immagine, rispetto all’analisi manuale.
Esecuzione su larga scala
Al fine di stimare la scala e la durata di un processo di indicizzazione, l’implementazione è stata testata con 93.997 documenti e un totale di 1.583.197 pagine (in media 16,84 pagine/documento e il file più grande con 3755 pagine), che sono stati tutti indicizzati in OpenSearch. L’elaborazione di tutti i file e la loro indicizzazione in OpenSearch hanno richiesto 5,5 ore nella regione US East (N. Virginia – us-east-1) utilizzando le quote predefinite del servizio Amazon Textract. Il grafico qui sotto mostra un test iniziale alle 18:00 seguito dall’elaborazione principale alle 21:00 e tutto completato entro le 2:30.
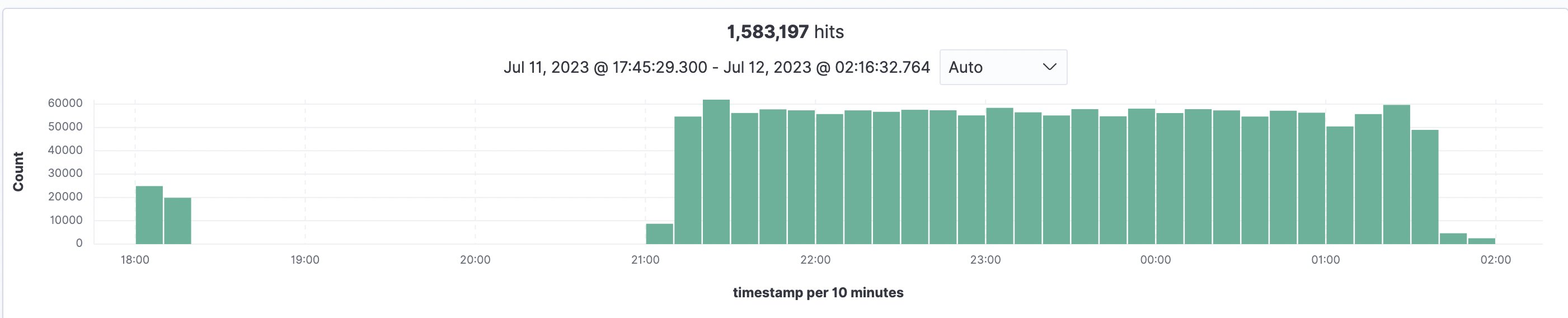
Figura 13: Panoramica dell’indicizzazione di OpenSearch
Per l’elaborazione, il parametro tcdk.SFExecutionsStartThrottle è stato impostato su un executions_concurrency_threshold = 550, il che significa che i flussi di lavoro di elaborazione dei documenti in contemporanea sono limitati a 550 e le richieste in eccesso vengono accodate in una coda Amazon SQS Fist-In-First-Out (FIFO), che viene successivamente svuotata quando i flussi di lavoro correnti terminano. La soglia di 550 si basa sulla quota del servizio Textract di 600 nella regione us-east-1. Pertanto, la profondità della coda e l’età del messaggio più vecchio sono metriche da monitorare.
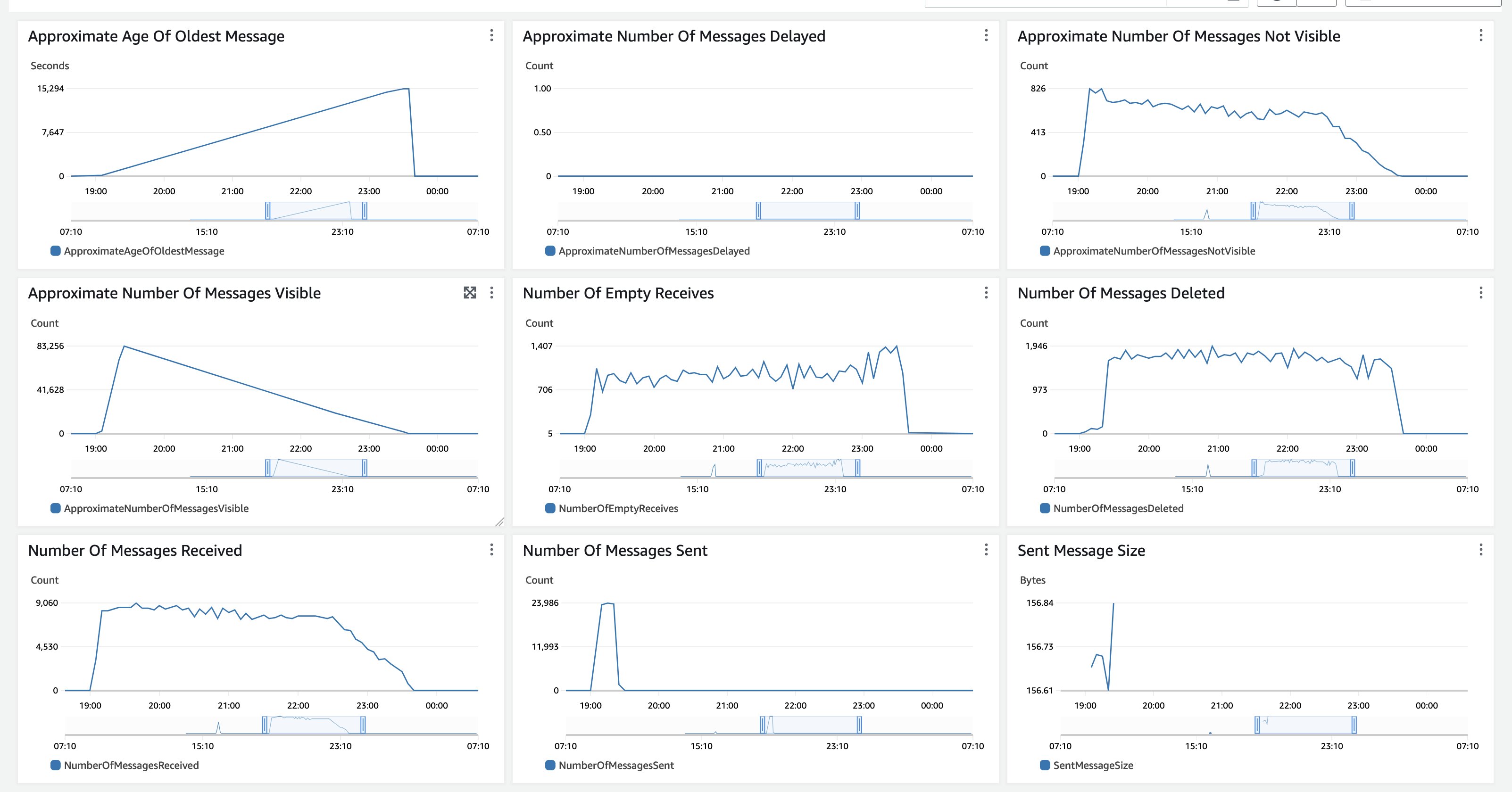
Figura 14: Monitoraggio di Amazon SQS
In questo test, tutti i documenti sono stati caricati su Amazon S3 contemporaneamente, quindi il Numero approssimativo di messaggi visibili ha un aumento repentino e quindi una diminuzione lenta poiché non vengono inseriti nuovi documenti. L’Età approssimativa del messaggio più vecchio aumenta fino a quando tutti i messaggi vengono elaborati. Il periodo di conservazione dei messaggi di Amazon SQS è impostato su 14 giorni. Per l’elaborazione di backlog molto lungo che potrebbe superare i 14 giorni, inizia l’elaborazione con un subset più piccolo di documenti rappresentativi e monitora la durata dell’esecuzione per stimare quanti documenti puoi elaborare prima di superare i 14 giorni. Le metriche di CloudWatch di Amazon SQS sono simili anche per un caso d’uso di elaborazione di un ampio backlog di documenti, che viene inserito contemporaneamente e quindi elaborato completamente. Se il tuo caso d’uso prevede un flusso costante di documenti, entrambe le metriche, il Numero approssimativo di messaggi visibili e l’Età approssimativa del messaggio più vecchio, saranno più lineari. Puoi anche utilizzare il parametro di soglia per combinare un carico costante con l’elaborazione del backlog e allocare capacità in base alle tue esigenze di elaborazione.
Un’altra metrica da monitorare è la salute del cluster OpenSearch, che è necessario configurare secondo le migliori pratiche operative per il servizio Amazon OpenSearch. La distribuzione predefinita utilizza istanze di ricerca m6g.large.search.
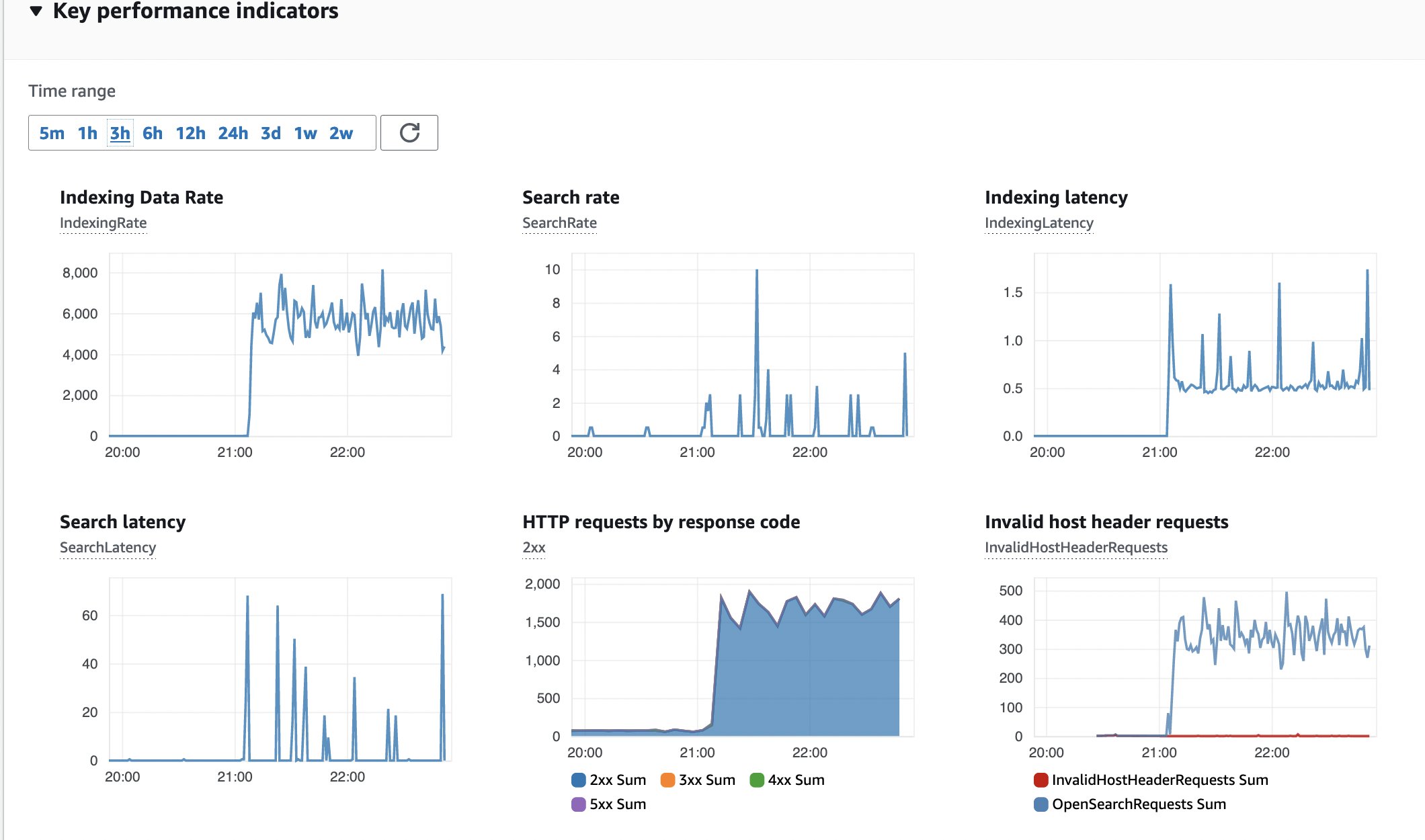
Figura 15: Monitoraggio di OpenSearch
Ecco uno snapshot degli indicatori chiave di performance (KPI) per il cluster OpenSearch. Nessun errore, tasso di indicizzazione costante e latenza.
Le esecuzioni del workflow delle Step Functions mostrano lo stato di elaborazione di ogni singolo documento. Se vedi esecuzioni nello stato Failed, seleziona i dettagli. Una buona metrica da monitorare è la dashboard automatica di AWS CloudWatch per le Step Functions, che espone alcune delle metriche di CloudWatch delle Step Functions.
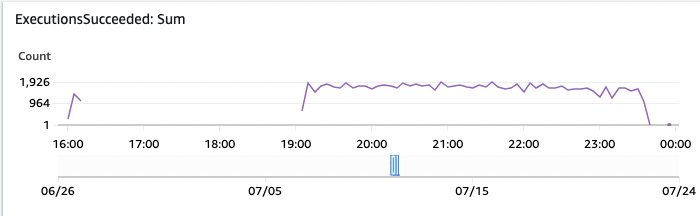
Figura 16: Monitoraggio delle esecuzioni delle Step Functions riuscite
In questo grafico della dashboard di AWS CloudWatch, puoi vedere le esecuzioni riuscite delle Step Functions nel tempo.
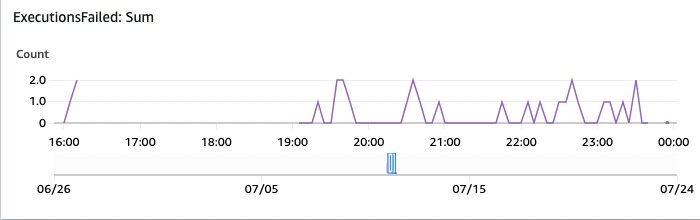
Figura 17: Monitoraggio delle esecuzioni fallite di OpenSearch
E questo mostra le esecuzioni fallite. Vale la pena indagare su queste esecuzioni attraverso la panoramica delle Step Functions nella console di AWS.
La seguente schermata mostra un esempio di un’elaborazione fallita a causa del file di origine di dimensione 0, il che ha senso perché il file non ha contenuto e non può essere elaborato. È importante filtrare i processi falliti e visualizzare i fallimenti, in modo che tu possa tornare al documento di origine e validare la causa principale.
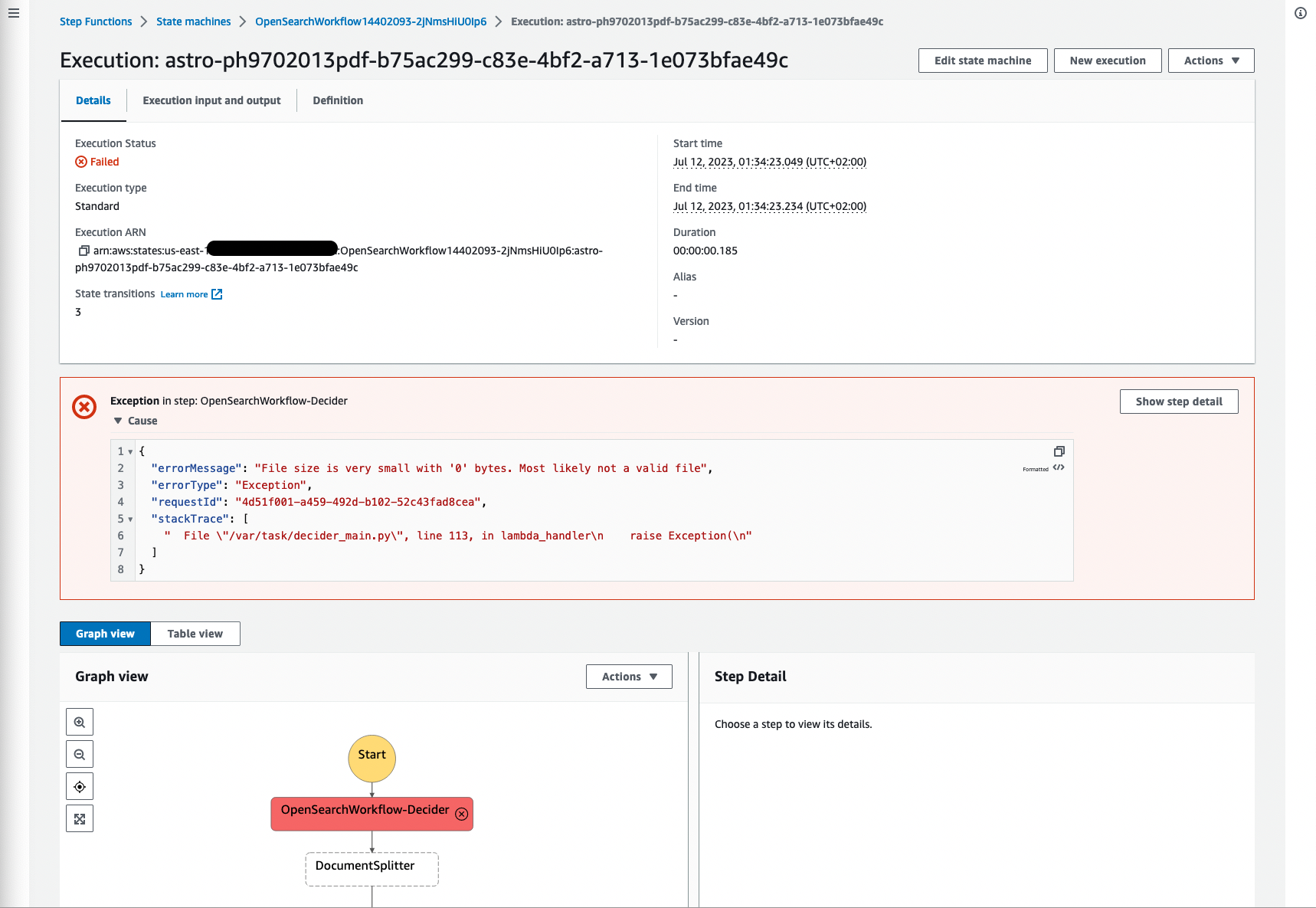
Figura 18: Workflow delle Step Functions fallito
Altre fallimenti potrebbero includere documenti che non sono di tipo mime: application/pdf, image/png, image/jpeg o image/tiff perché altri tipi di documento non sono supportati da Amazon Textract.
Costo
Il costo totale dell’ingestione di 1.583.278 pagine è stato suddiviso tra i servizi AWS utilizzati per l’implementazione. La seguente lista fornisce numeri approssimativi, perché il costo effettivo e la durata dell’elaborazione possono variare in base alla dimensione dei documenti, al numero di pagine per documento, alla densità delle informazioni nei documenti e alla regione AWS. Amazon DynamoDB ha consumato $0.55, Amazon S3 $3.33, OpenSearch Service $14.71, Step Functions $17.92, AWS Lambda $28.95 e Amazon Textract $1.849.97. Inoltre, tieni presente che il cluster Amazon OpenSearch Service distribuito viene fatturato per l’ora e accumulerà costi più elevati se viene eseguito per un periodo di tempo prolungato.
Modifiche
Molto probabilmente, vorrai modificare l’implementazione e personalizzarla per il tuo caso d’uso e i tuoi documenti. Il workshop “Utilizza il machine learning per automatizzare e elaborare documenti su larga scala” presenta una buona panoramica su come manipolare i flussi di lavoro effettivi, cambiare il flusso e aggiungere nuovi componenti. Per aggiungere campi personalizzati all’indice di OpenSearch, guarda il task SetMetaData nel flusso di lavoro utilizzando la funzione AWS Lambda set-manifest-meta-data-opensearch per aggiungere meta-dati al contesto, che verranno aggiunti come campo all’indice di OpenSearch. Qualsiasi informazione sui meta-dati diventerà parte dell’indice.
Pulizia
Elimina le risorse di esempio se non ne hai più bisogno, per evitare costi futuri utilizzando il seguente comando:
cdk destroy OpenSearchWorkflownello stesso ambiente del comando cdk deploy. Attenzione, questo rimuove tutto, incluso il cluster OpenSearch e tutti i documenti e il bucket Amazon S3. Se desideri mantenere tali informazioni, esegui il backup del tuo bucket Amazon S3 e crea uno snapshot dell’indice dal tuo cluster OpenSearch. Se hai elaborato molti file, potresti dover svuotare prima il bucket Amazon S3 utilizzando la console di gestione di AWS (ad esempio, dopo aver eseguito un backup o sincronizzato i file in un bucket diverso se desideri conservare le informazioni), perché la funzione di pulizia potrebbe richiedere troppo tempo e quindi distruggere lo stack di AWS CloudFormation.
Conclusion
In questo post, ti abbiamo mostrato come implementare una soluzione full stack per l’ingestione di un grande numero di documenti in un indice OpenSearch, pronti per essere utilizzati per casi d’uso di ricerca. Sono stati discusse anche le singole componenti dell’implementazione, insieme a considerazioni sulla scalabilità, costi e opzioni di modifica. Tutto il codice è accessibile come OpenSource su GitHub come campioni di IDP CDK e come costrutti IDP CDK per creare le tue soluzioni da zero. Come prossimo passo, puoi iniziare a modificare il flusso di lavoro, aggiungere informazioni ai documenti nell’indice di ricerca ed esplorare il workshop di IDP. Per favore, lascia un commento qui sotto sulla tua esperienza e idee per espandere la soluzione attuale.






