Una guida all’utilizzo delle funzioni di finestra
Guida funzioni finestra
Creare totali progressivi, medie mobili e classifiche con facilità in BigQuery.
Se hai mai cercato o inciampato su qualcosa come ‘6 abilità SQL che devi conoscere per fare colpo in un’intervista’ o forse ‘Concetti SQL che avrei voluto conoscere anni fa’. Probabilmente, le funzioni di finestra vengono menzionate meritatamente in qualche punto di quella lista.
Le funzioni di finestra sono fantastiche.
Il mio obiettivo per questo articolo è aiutarti a capire queste funzioni di finestra e come usarle. Una volta che avremo coperto il tutorial, ho preparato alcuni casi d’uso che puoi eseguire nel tuo progetto per giocarci, poiché ho utilizzato dati pubblici per questi esempi.
Affronteremo:
- Cosa è una funzione di finestra?
- La sintassi di una funzione di finestra – ovvero le parti di partizione, ordine e frame
- Uno sguardo ravvicinato su come puoi creare una media mobile di 7 giorni e come funziona
- Cosa funzioni di aggregazione e finestre hai a disposizione?
- Infine, passeremo attraverso alcuni casi d’uso per dimostrare come le funzioni di finestra possono essere applicate.
Cosa è una funzione di finestra?
Il termine ‘finestra’ può sembrare strano da usare in SQL (o nell’informatica in generale). Di solito, il nome del tipo di funzione ti dà un’idea di come possono essere utilizzate, come ad esempio:
- 5 Preoccupazioni Riguardanti la Scalabilità e l’Adozione dell’Intelligenza Artificiale
- ChatGPT è effettivamente intelligente?
- Ispezione delle previsioni di Data Science Analisi individuale + casi negativi
- Funzioni di aggregazione – prendono un insieme di cose e ti danno un risultato che le riassume tutte
- Funzioni di stringa – una cassetta degli attrezzi piena di metodi per manipolare parole e frasi
- Funzioni di matrice – lavorano con una raccolta o un gruppo di elementi tutti in una volta
E così via…
Allora, cos’è una funzione di finestra in SQL? Come una finestra nel mondo reale, ti consente di visualizzare un’area particolare mentre il resto rimane fuori dalla vista. Sei concentrato solo su ciò che viene mostrato attraverso la finestra.
Tornando al mondo dei dati, diciamo che hai una tabella contenente le vendite mensili dei negozi di liquori in IOWA.
Il set di dati utilizzato in questo esempio è accessibile pubblicamente, fornito da Google ed esiste già in BigQuery se vuoi provare questi esempi tu stesso. (link)
bigquery-public-data.iowa_liquour_sales.sales
Nell’esempio sottostante viene fornita una semplice visualizzazione delle vendite per anno e mese.
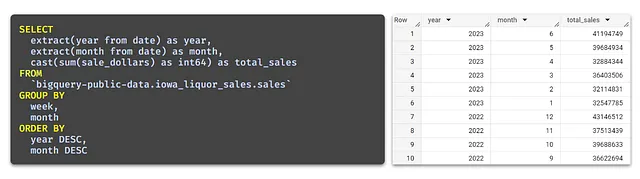
Ho salvato quanto sopra come vista per mantenere le nostre future interrogazioni il più minimali possibile per concentrarci sull’applicazione delle funzioni di finestra.
Se desideri utilizzare questa vista, puoi usare spreadsheep-20220603.Dashboard_Datasets.iowa_liqour_monthly_sales.
Cosa succede se vogliamo anche la media mensile per ogni anno come colonna separata?
Ci sono alcuni modi per ottenere questo risultato e se sei nuovo alle funzioni di finestra, potresti provare a calcolare la media come sottoquery e quindi unirti alla tabella originale, come mostrato di seguito.
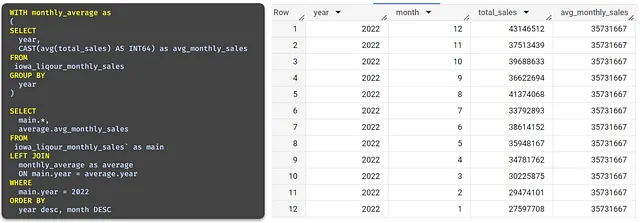
Questo funziona perfettamente, ma una funzione di finestra ti consentirà di ottenere la stessa risposta senza una sottoquery!
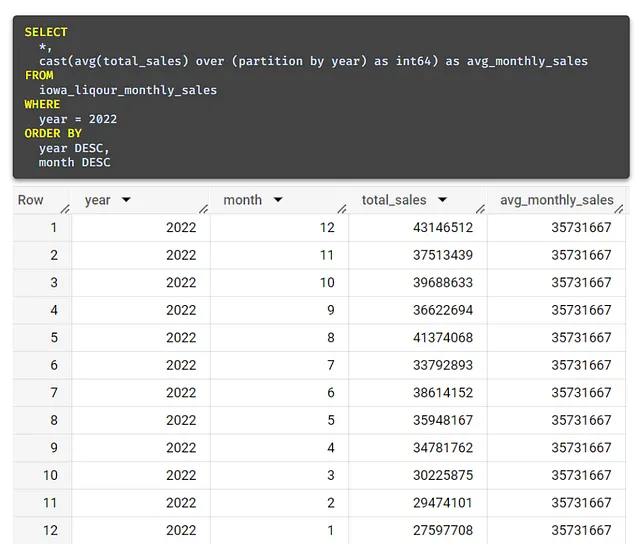
La funzione di finestra sopra ci consente di eseguire una funzione di aggregazione, in questo caso la funzione avg, su un gruppo specifico di righe definite da partition by year.
Ripensando alla metafora della finestra, la parte “partition by” è la nostra finestra in quella situazione. Certamente abbiamo l’intero dataset di fronte a noi, ma la partizione limita la nostra vista solo all’anno.
È ora di approfondire la sintassi.
Sintassi della finestra
Nell’esempio sopra, possiamo suddividere la funzione in due parti, il nome della funzione e la finestra.
In questo scenario, il nome della funzione è la nota funzione di aggregazione chiamata AVG. La parte della finestra, tuttavia, è un po’ diversa.
Dopo aver specificato la funzione, inizi la tua funzione di finestra con la parola chiave over, seguita da parentesi ().

All’interno delle parentesi, puoi specificare quale finestra vogliamo utilizzare per effettuare l’aggregazione utilizzando la parola chiave partition by, seguita da un elenco di colonne che desideri includere nella finestra. Qui, abbiamo incluso solo una colonna, year, ma in seguito inseriremo un’altra colonna nella combinazione.
Partition by è opzionale; se non includi una partition by, l’aggregazione consisterà in tutte le righe del tuo dataset. Poiché questa esiste nell’istruzione SELECT, è utile notare che la clausola WHERE verrà eseguita prima di questa funzione di finestra.
Cosa intendo con questo? Utilizzando l’esempio che ho condiviso in precedenza, ho specificato una finestra utilizzando partition by year. Tuttavia, nella mia clausola WHERE, ho un filtro impostato solo per restituire le righe in cui l’anno è uguale a 2022.
Ciò significa che il dataset ha solo un anno in vista, ovvero il 2022, quando viene eseguita la funzione di finestra. Pertanto, la mia finestra partition by year è ridondante, e utilizzando la riga qui sotto darebbe lo stesso risultato in questo scenario.

Ripetiamo la nostra query di prima e, questa volta, rimuoviamo la clausola WHERE.
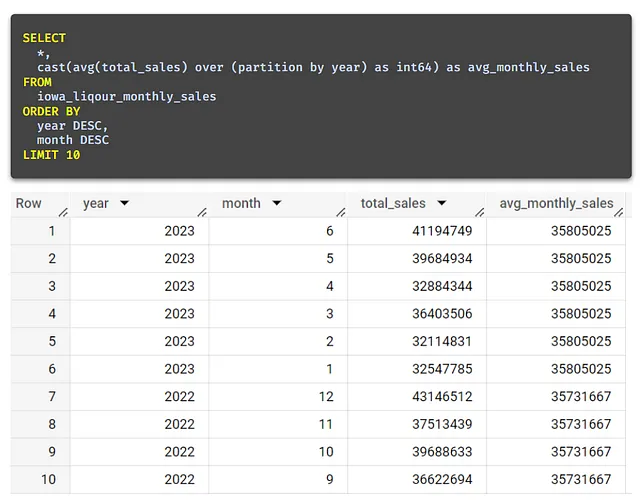
Qui possiamo vedere valori diversi per il 2023 e il 2022. Questo mostra ora la media delle vendite mensili per ciascuno degli anni offerti.
Ad esempio, nella riga 7, abbiamo il 2022 con una media mensile delle vendite di 35,7 milioni, mentre la media mensile delle vendite per il 2023 (finora) è di 35,8 milioni.
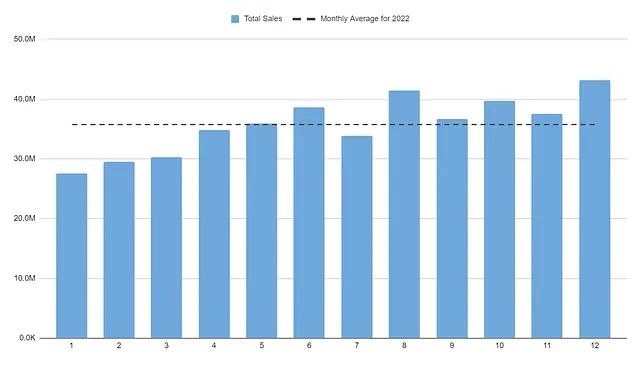
Accedere ai dati medi mensili facilita la visualizzazione e l’analisi delle tendenze delle vendite. In particolare, diventa evidente che la seconda metà dell’anno contribuisce in modo significativo alle vendite.
Abbiamo utilizzato una funzione di finestra per calcolare la media mensile delle vendite per ogni anno. Quindi, questa funzione ha applicato il risultato a tutte le righe con quel determinato anno. È come una sub-query di left-join che abbiamo visto in precedenza.
Order By
Fino ad ora ci siamo concentrati principalmente sulle funzioni di aggregazione e su come specificare la finestra. Possiamo anche determinare l’ordine in cui la finestra deve eseguire il suo compito, che è una parte fondamentale delle soluzioni di classifica o totali/medie cumulativi.
Tornando al dataset di Iowa, ampliamo la nostra vista includendo il nome del negozio e assegnando ai negozi un ranking mensile numerato in base alle loro vendite totali.
Nuova Vista
spreadsheep-20220603.Dashboard_Datasets.iowa_liqour_monthly_sales_inc_store
A differenza degli aggregati, per la funzione di ranking, che è esclusiva delle funzioni di finestra, non si specifica una colonna all’interno della funzione stessa.

Tuttavia, se provi a eseguirlo come mostrato sopra, riceverai un errore.

Il problema qui è che abbiamo detto a BigQuery che vogliamo classificare i nostri risultati, ma non abbiamo specificato come dovrebbero essere classificati, cosa che possiamo ottenere utilizzando l’istruzione ORDER BY.

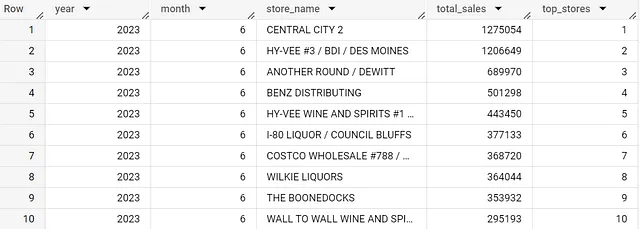
Questo ci offre una vista delle vendite mensili a livello di negozio, con un ranking per ogni negozio. Puoi quindi approfondire ulteriormente e rispondere ad altre domande, come ad esempio Quali erano i primi 3 negozi per ogni mese nel 2022?
In uno degli esempi verso la fine di questo articolo, useremo una nuova clausola chiamata QUALIFY, che ti consente di filtrare facilmente i risultati forniti dalle funzioni di finestra.
Fino ad ora, le nostre funzioni di finestra sono state applicate a tutte le righe in ogni partizione, ma cosa succede se vogliamo solo un sottoinsieme della partizione? Ad esempio, la media delle vendite giornaliere degli ultimi sette giorni? Per questo, dobbiamo specificare una cornice della finestra.
Cornice della Finestra
È ora di utilizzare un nuovo dataset, introducendo i tassisti di Chicago! Questo è un altro dataset pubblico (licenza CC0) che puoi utilizzare se vuoi fare degli esperimenti. (link)
bigquery-public-data.chicago_taxi_trips.taxi_tripsIl dataset pubblico è grande, 75GB, e consuma rapidamente la tua quota mensile gratuita di 100GB per le query. Pertanto, ho creato una nuova tabella che contiene solo i dati del 2023, in modo da poter giocare con i dati senza accumulare una fattura salata.
Ho reso questa tabella pubblica, quindi ti consiglio di provare il mio dataset per i test.
spreadsheep-case-studies-2023.chicago_taxies_2023.trip_dataComunque, torniamo all’argomento…cosa è una cornice della finestra? Questa clausola ci consente di definire quali righe o intervalli dobbiamo utilizzare all’interno della partizione. Un caso d’uso popolare per questo è quello di creare medie mobili.
SELECT date(trip_start_timestamp) as trip_start_date, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-05-01" and "2023-06-30"GROUP BY trip_start_dateORDER BY trip_start_date DESCQuesta query ci fornisce il ricavo per data tra maggio e giugno 2023.
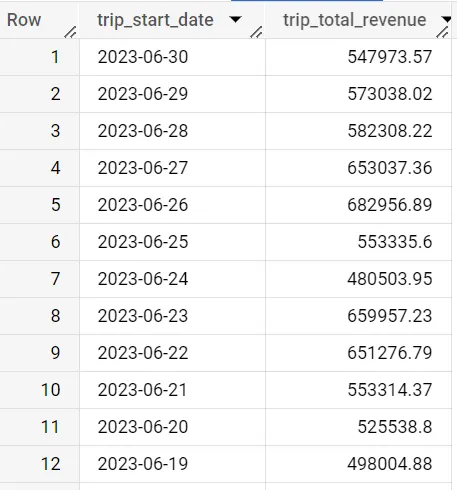
Le medie mobili sono molto comuni con i dati delle serie temporali, poiché ti permettono di confrontare facilmente le performance di un giorno specifico o di un mese rispetto a quale risultato vedi tipicamente per un determinato periodo.
Prima di tutto, creiamo una media mobile semplice e per evitare di ripetere le conversioni delle date e l’arrotondamento del ricavo, ho inserito la nostra query iniziale all’interno di un CTE.
WITH daily_data as(SELECT date(trip_start_timestamp) as trip_start_date, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-05-01" and "2023-06-30"GROUP BY trip_start_dateORDER BY trip_start_date DESC)SELECT trip_start_date, trip_total_revenue, avg(trip_total_revenue) over (order by trip_start_date asc) as moving_averageFROM daily_data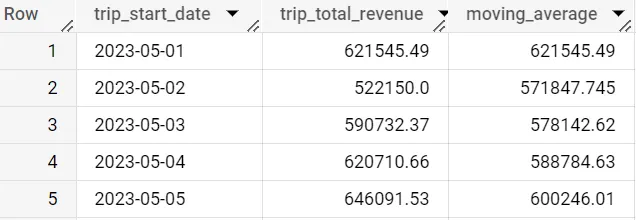
Se guardiamo le prime cinque righe, possiamo vedere che la prima media è uguale a trip_total_revenue. Questo perché è l’inizio della finestra dato che abbiamo ordinato i nostri dati per trip_start_date in ordine ascendente. Quindi non c’è ancora nulla da calcolare la media.
Tuttavia, ora abbiamo una media giornaliera tra le righe 1 e 2 per la seconda riga. Abbiamo una media giornaliera per la terza riga tra le righe 1, 2 e 3.
È un buon inizio che ci mostra che la nostra media mobile sta funzionando, ma andiamo avanti. Creiamo una media mobile che includa solo gli ultimi sette giorni di ricavi e, se la finestra non contiene sette giorni, mostrare un valore nullo.
Per specificare il range della finestra, ci sono tre parole chiave che devi ricordare:
- riga corrente
- precedente
- successivo
Poi costruisci la tua finestra iniziando con righe o intervalli (spiegherò la differenza tra i due in seguito), seguita da tra <<inizio>> e <<fine>>.
righe tra 7 precedenti e una precedenteL’esempio sopra è la finestra che ci serve per il nostro problema. Abbiamo specificato che la finestra inizia sette righe prima della riga corrente e finisce una riga prima della riga corrente.
Ecco un semplice esempio di come questa struttura di finestra funziona con una somma aggregata.
seleziona numeri, somma(numeri) over (ordine per numeri asc righe tra 7 precedenti e una precedente) come somma_mobile_sette da test_data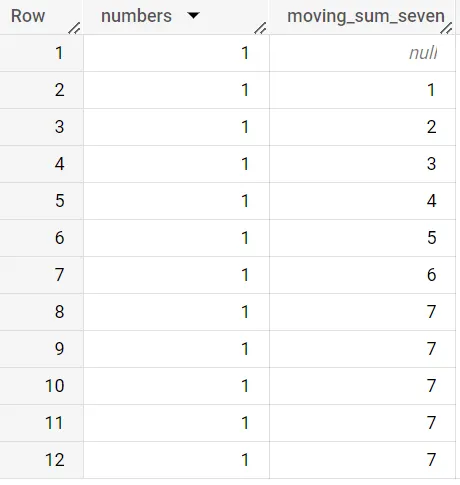
Come puoi vedere, quando raggiungiamo l’ottava riga, il valore della somma mobile raggiunge 7, dove la finestra contiene sette righe di dati. Se cambiate la finestra a 6 precedenti e righe correnti, vedrete che la finestra si è spostata per includere la riga corrente.
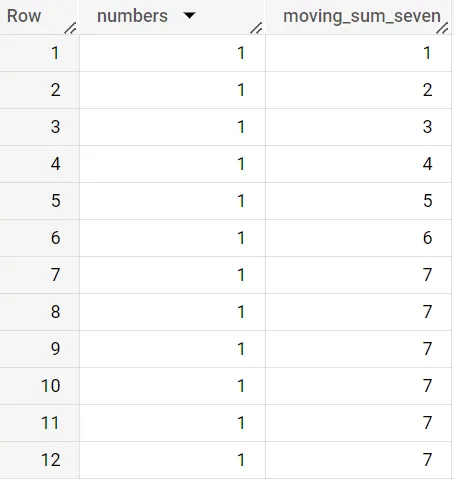
Alla fine di questa sezione, fornirò alcuni esempi di casi d’uso per evidenziare come possono essere utilizzati, ma torniamo al compito iniziale per ora!
Inseriamo ora quel range di finestra nella nostra media mobile.
con daily_data as (SELECT date(trip_start_timestamp) as trip_start_date, round(sum(trip_total),2) as trip_total_revenue FROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data` WHERE date(trip_start_timestamp) between "2023-05-01" and "2023-06-30" GROUP BY trip_start_date ORDER BY trip_start_date DESC) SELECT trip_start_date, trip_total_revenue, avg(trip_total_revenue) over (order by trip_start_date asc rows between 7 preceding and one preceding) as moving_average FROM daily_data ORDER BY trip_start_date DESCOra abbiamo una sfida finale, come facciamo a rendere il valore nullo se la finestra contiene meno di sette righe di dati? Beh, possiamo usare una dichiarazione IF per controllare.
if (COUNT(*) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 7 PRECEDING AND 1 PRECEDING) = 7, AVG(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 7 PRECEDING AND 1 PRECEDING), NULL) AS moving_averageAbbiamo introdotto una seconda funzione di finestra che conta quante righe esistono nella finestra, che, se uguale a 7, fornirà il risultato della media mobile.
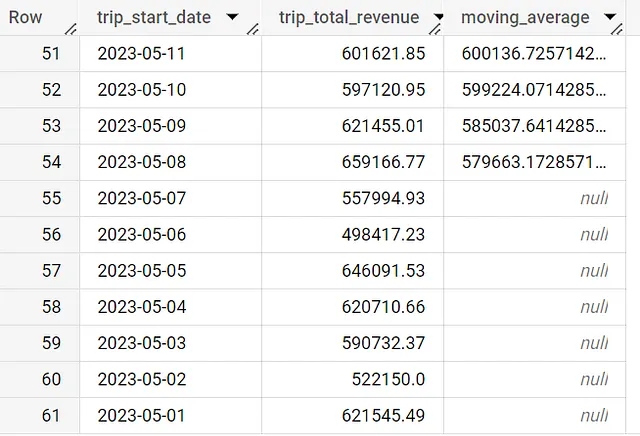
Differenza tra ROWS e RANGE
In SQL, sia le clausole ROWS che RANGE aiutano a controllare quali righe vengono utilizzate da una funzione di finestra all’interno di un gruppo.
La clausola ROWS funziona con un numero fisso di righe. Conta un numero specifico di righe prima o dopo la riga corrente, indipendentemente dai loro valori. Queste righe sono incluse nella funzione di finestra.
La clausola RANGE lavora con le righe in base ai loro valori. Considera le righe con valori all’interno di un intervallo specifico rispetto alla riga corrente. I valori effettivi determinano quali righe sono incluse nel calcolo della funzione di finestra.
Quindi, mentre la clausola ROWS si concentra sulla posizione fisica delle righe, la clausola RANGE considera il valore logico delle righe per determinare la loro inclusione nella funzione di finestra.
Prova questo come esempio per vederlo in azione
with sales_data as (SELECT'2023-01-01' AS DATE, 100 AS SALESUNION ALLSELECT'2023-01-02' AS DATE, 50 AS SALESUNION ALLSELECT'2023-01-03' AS DATE, 250 AS SALESUNION ALLSELECT'2023-01-03' AS DATE, 200 AS SALESUNION ALLSELECT'2023-01-04' AS DATE, 300 AS SALESUNION ALLSELECT'2023-01-05' AS DATE, 150 AS SALES)SELECT *, SUM(SALES) OVER (ORDER BY DATE ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total_rows, SUM(SALES) OVER (ORDER BY DATE RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total_rangeFROM sales_data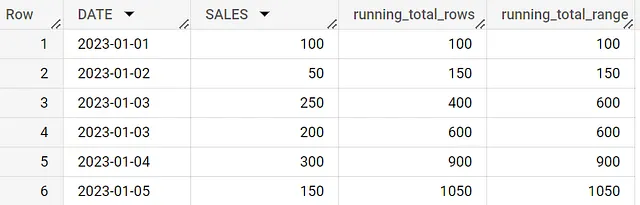
Osserva attentamente le righe 3 e 4 per confrontare le due clausole. La clausola ROWS aggiunge ogni riga al totale, anche se ci sono date di vendita duplicate. Ma con la clausola RANGE, le righe con la stessa data di vendita sono raggruppate insieme come un unico intervallo. Ad esempio, in questo caso, tutte le righe con la data 2023-01-03 saranno considerate come un unico intervallo.
Cosa sono le funzioni di finestra?
Esistono diverse funzioni che è possibile utilizzare con una funzione di finestra.
Per le funzioni di aggregazione, puoi provare:
- SUM: Calcola la somma di una colonna numerica.
- AVG: Calcola la media di una colonna numerica.
- MIN: Recupera il valore minimo da una colonna.
- MAX: Recupera il valore massimo da una colonna.
- COUNT: Conta il numero di righe in una colonna.
- COUNT DISTINCT: Conta il numero di valori distinti in una colonna.
Poi ci sono un gruppo di nuove funzioni esclusive della funzione di finestra, conosciute come funzioni analitiche:
- ROW_NUMBER: Assegna un numero univoco a ogni riga all’interno del frame di finestra.
- RANK: Assegna un rango a ogni riga in base all’ordine specificato nel frame di finestra.
- DENSE_RANK: Assegna un rango a ogni riga, senza spazi, in base all’ordine specificato nel frame di finestra.
- LAG: Recupera il valore da una riga precedente all’interno del frame di finestra.
- LEAD: Recupera il valore da una riga successiva all’interno del frame di finestra.
- FIRST_VALUE: Recupera il valore dalla prima riga all’interno del frame di finestra.
- LAST_VALUE: Recupera il valore dall’ultima riga all’interno del frame di finestra.
Le funzioni sopra sono collegate alla documentazione di BigQuery.
Esempi funzionanti
Totale giornaliero corrente
Uno dei casi d’uso più semplici delle funzioni di finestra è il totale corrente. Per il dataset dei taxi di Chicago, potremmo avere il fatturato su base mensile ma richiedere una nuova colonna che tenga traccia del nostro fatturato totale fino ad ora nell’anno.
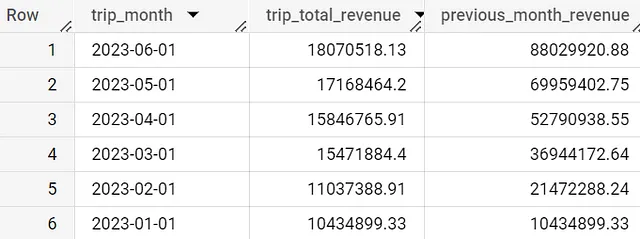
with daily_data as (SELECT date(timestamp_trunc(trip_start_timestamp,month)) as trip_month, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_monthORDER BY trip_month DESC)SELECT trip_month, trip_total_revenue, round(sum(trip_total_revenue) over (order by trip_month asc),2) AS running_total_revenue,FROM daily_dataORDER BY trip_month DESCMedia mobile a 12 settimane
Il tutorial di questo articolo evidenzia che le medie mobili sono molto comuni quando si lavora con dati di serie temporali.
with daily_data as (SELECT date(timestamp_trunc(trip_start_timestamp,week(monday))) as trip_week, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_weekORDER BY trip_week DESC)SELECT trip_week, trip_total_revenue, if ( COUNT(*) OVER (ORDER BY trip_week ASC ROWS BETWEEN 12 PRECEDING AND 1 PRECEDING) = 12, AVG(trip_total_revenue) OVER (ORDER BY trip_week ASC ROWS BETWEEN 12 PRECEDING AND 1 PRECEDING), NULL ) AS moving_averageFROM daily_dataORDER BY trip_week DESC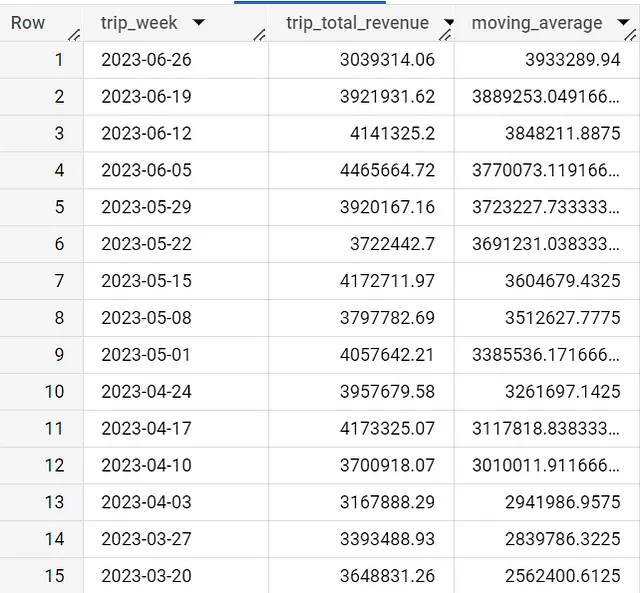
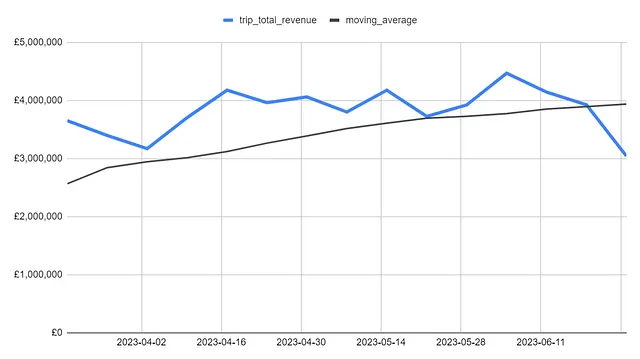
Il grafico del fatturato insieme alla media mobile indica una tendenza positiva, poiché la media mobile è continuamente salita ogni settimana da aprile. Senza la media mobile, i nostri occhi potrebbero essere attirati dalle settimane con prestazioni inferiori anziché dalla visione d’insieme.
Calcolo di uno z-score per il rilevamento delle anomalie
Calcolo dello z-score = (x – media) / deviazione standard
Lo z-score è un modo per misurare quanto insolito o tipico è un numero rispetto a un gruppo di altri numeri. Ti dice quanto un numero specifico si discosta dalla media del gruppo in termini di deviazioni standard.
if ( COUNT(*) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) = 30, round ( ( trip_total_revenue - AVG(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) ) / stddev(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) ,1), NULL ) AS z_score_30_dayIn questo esempio, abbiamo preso il valore effettivo di trip_total_revenue e sottratto il fatturato medio giornaliero che abbiamo osservato negli ultimi 30 giorni.
Abbiamo quindi diviso quel numero per la deviazione standard di quei 30 giorni. Questo ci dice quanto vicino sia un determinato giorno di fatturato alla media o quante deviazioni standard quel valore è rispetto alla media.
Questo è un indicatore utile da tracciare su un grafico, come mostrato di seguito, in quanto fornisce contesto ai tuoi dati. Anche se abbiamo solo gli ultimi 30 giorni in vista, lo z-score viene confrontato senza sforzo con i 30 giorni precedenti e possiamo vedere aree in cui picchi e cali sembrano insignificanti fino a quando lo z-score evidenzia quanto diverso sia stato quel giorno rispetto alla norma.
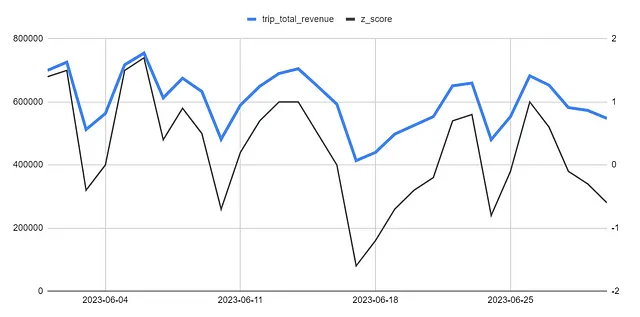
Con questo tipo di rapporti, dovresti impostare un valore che suggerisca la presenza di un evento anomalo. Non direi che ci sono date anomale nel grafico sopra, ma un valore tipico è 3 (cioè tre deviazioni standard). Tuttavia, ciò dipende interamente dalla volatilità dei tuoi dati.
Query completa
with daily_data as (SELECT (trip_start_timestamp) as trip_start_date, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_start_dateORDER BY trip_start_date DESC)SELECT trip_start_date, trip_total_revenue, if ( COUNT(*) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) = 30, round ( ( trip_total_revenue - AVG(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) ) / stddev(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) ,1), NULL ) AS z_score_30_dayFROM daily_dataORDER BY trip_start_date DESCClassifica mensile dei migliori performer
Nel dataset dei taxi di Chicago, ci sono numerose compagnie di taxi e potremmo chiederci quali sono state le prime 3 compagnie più performanti ogni mese.
Per ottenere ciò, possiamo utilizzare la funzione analitica rank, partizionata per trip_month e ordinata per trip_total_revenue in ordine decrescente.
rank() over (partition by trip_month order by trip_total_revenue desc) AS rankingTuttavia, questo fornirà comunque risultati per tutte le compagnie nel dataset per ogni mese anziché solo le prime 3. Pertanto, possiamo utilizzare la clausola QUALIFY, che funziona in modo simile alla clausola WHERE, per consentirti di filtrare i tuoi dati.
La clausola qualify può essere utilizzata solo con le funzioni di finestra e può fare riferimento alle funzioni di finestra create nella tua dichiarazione select. Maggiori dettagli qui.
I risultati seguenti indicano chiaramente che tre grandi compagnie dominano il settore dei taxi.
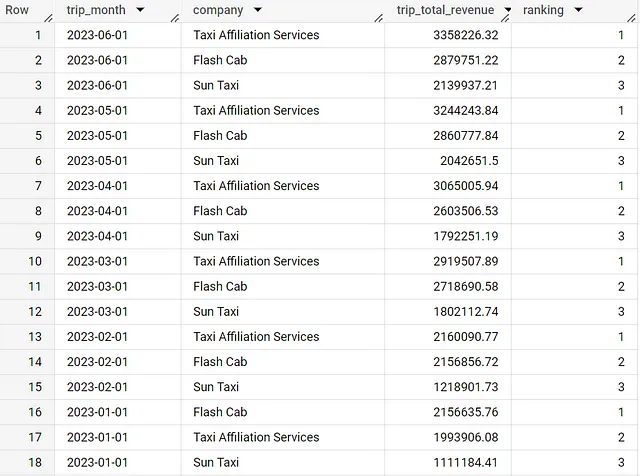
with daily_data as (SELECT date(timestamp_trunc(trip_start_timestamp,month)) as trip_month, company, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_month, companyORDER BY trip_month DESC)SELECT trip_month, company, trip_total_revenue, rank() over (partition by trip_month order by trip_total_revenue desc) AS rankingFROM daily_dataQUALIFY ranking <= 3ORDER BY trip_month DESCConfronti Mensili/Trimestrali
La segnalazione mensile e trimestrale è essenziale per monitorare gli KPI e per aiutare a valutare la direzione in cui si sta dirigendo l’azienda. Tuttavia, creare un report in BigQuery, che fornisce i cambiamenti mese per mese, può rivelarsi complicato una volta che si conosce la procedura.
Una volta che hai i dati al livello desiderato, come mensile nel mio esempio qui sotto, puoi utilizzare le funzioni LAG o LEAD per restituire il fatturato del mese precedente, consentendoti di calcolare la differenza percentuale.
Puoi utilizzare LAG o LEAD; entrambi ottengono lo stesso risultato a seconda di come ordini i dati. Poiché stiamo prelevando il fatturato del mese precedente, ha senso utilizzare lag qui.
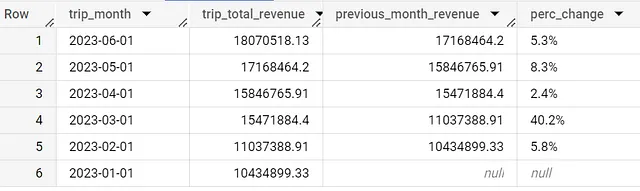
con daily_data as (SELECT date(timestamp_trunc(trip_start_timestamp,month)) as trip_month, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_monthORDER BY trip_month DESC)SELECT trip_month, trip_total_revenue, lead(trip_total_revenue) over (order by trip_total_revenue asc) AS previous_month_revenue, round ( ( ( trip_total_revenue - lag(trip_total_revenue) over (order by trip_total_revenue asc) ) / lag(trip_total_revenue) over (order by trip_total_revenue asc) ) * 100 , 1) || "%" AS perc_changeFROM daily_dataORDER BY trip_month DESCQuesto conclude l’articolo. Se hai domande o sfide, non esitare a commentare e risponderò il prima possibile.
Scrivo frequentemente articoli su BigQuery e Looker Studio. Se sei interessato, considera di seguirmi qui su VoAGI per ulteriori contenuti!
Tutte le immagini, salvo diversa indicazione, sono dell’autore.
Rimani elegante, amici! Tom





