Crea funzionalità di ML su larga scala con Amazon SageMaker Feature Store utilizzando dati da Amazon Redshift
Crea funzionalità di ML su larga scala con Amazon SageMaker Feature Store e dati da Amazon Redshift
Amazon Redshift è il data warehouse cloud più popolare utilizzato da decine di migliaia di clienti per analizzare exabyte di dati ogni giorno. Molti professionisti stanno estendendo questi dataset Redshift su larga scala per il machine learning (ML) utilizzando Amazon SageMaker, un servizio ML completamente gestito, con requisiti per sviluppare funzionalità offline in modo codice o in modo low-code/no-code, archiviare dati in primo piano da Amazon Redshift e fare tutto questo su larga scala in un ambiente di produzione.
In questo post, ti mostriamo tre opzioni per preparare i dati di origine Redshift su larga scala in SageMaker, inclusi il caricamento dei dati da Amazon Redshift, l’ingegneria delle funzionalità e l’ingestione delle funzionalità in Amazon SageMaker Feature Store:
- Opzione A – Utilizzare una sessione interattiva di AWS Glue su Amazon SageMaker Studio (in un ambiente di sviluppo) e un lavoro di AWS Glue (in un ambiente di produzione) con Spark
- Opzione B – Utilizzare un lavoro di elaborazione di Amazon SageMaker con una definizione di dataset Redshift o utilizzare SageMaker Feature Processing in SageMaker Feature Store, che esegue i lavori di formazione di SageMaker
- Opzione C – Utilizzare Amazon SageMaker Data Wrangler in modo low-code/no-code
Se sei un utente di AWS Glue e desideri eseguire il processo in modo interattivo, considera l’opzione A. Se conosci SageMaker e sai scrivere codice Spark, l’opzione B potrebbe essere la tua scelta. Se desideri eseguire il processo in modo low-code/no-code, puoi seguire l’opzione C.
Amazon Redshift utilizza SQL per analizzare dati strutturati e semi-strutturati su data warehouse, database operativi e data lake, utilizzando hardware progettato da AWS e ML per offrire la migliore scalabilità al miglior prezzo.
- Le onde di spin più veloci potrebbero consentire sistemi di calcolo magnetonici
- La prima telecamera AI del Regno Unito cattura 300 criminali in soli tre giorni
- Occupato? Questa è la tua guida rapida per aprire la scatola nera dei modelli di diffusione
SageMaker Studio è il primo ambiente di sviluppo integrato (IDE) per il machine learning. Fornisce un’interfaccia visiva basata sul web in cui è possibile eseguire tutte le fasi di sviluppo del ML, inclusa la preparazione dei dati e la creazione, formazione e distribuzione di modelli.
AWS Glue è un servizio di integrazione dati serverless che semplifica la scoperta, la preparazione e la combinazione dei dati per l’analisi, il ML e lo sviluppo di applicazioni. AWS Glue consente di raccogliere, trasformare, pulire e preparare dati per lo storage nei data lake e nelle pipeline dati utilizzando una varietà di funzionalità, inclusi trasformazioni integrate.
Panoramica della soluzione
Il diagramma seguente illustra l’architettura della soluzione per ciascuna opzione.

Prerequisiti
Per continuare con gli esempi in questo post, è necessario creare le risorse AWS richieste. Per fare ciò, forniamo un modello CloudFormation AWS per creare uno stack che contiene le risorse. Quando crei lo stack, AWS crea diverse risorse nel tuo account:
- Un dominio SageMaker, che include un volume Amazon Elastic File System (Amazon EFS) associato
- Un elenco di utenti autorizzati e una varietà di configurazioni di sicurezza, applicazioni, criteri e Amazon Virtual Private Cloud (Amazon VPC)
- Un cluster Redshift
- Un segreto Redshift
- Una connessione AWS Glue per Amazon Redshift
- Una funzione AWS Lambda per configurare le risorse richieste, ruoli di esecuzione e criteri
Assicurati di non avere già due domini SageMaker Studio nella regione in cui stai eseguendo il modello CloudFormation. Questo è il numero massimo consentito di domini in ogni regione supportata.
Esegui il modello CloudFormation
Completa i seguenti passaggi per eseguire il modello CloudFormation:
- Salva il modello CloudFormation sm-redshift-demo-vpc-cfn-v1.yaml in locale.
- Nella console AWS CloudFormation, scegli Crea stack.
- Per Prepara modello, seleziona Il modello è pronto.
- Per Origine modello, seleziona Carica un file del modello.
- Scegli Scegli file e vai nella posizione sul tuo computer in cui è stato scaricato il modello CloudFormation e scegli il file.
- Inserisci un nome stack, ad esempio
Demo-Redshift. - Nella pagina Configura opzioni stack, lascia tutto come predefinito e scegli Avanti.
- Nella pagina Riepilogo, seleziona Riconosco che AWS CloudFormation potrebbe creare risorse IAM con nomi personalizzati e scegli Crea stack.
Dovresti vedere una nuova stack di CloudFormation con il nome Demo-Redshift in fase di creazione. Attendi che lo stato della stack sia CREATE_COMPLETE (circa 7 minuti) prima di procedere. Puoi navigare nella scheda Risorse della stack per controllare quali risorse AWS sono state create.
Avvia SageMaker Studio
Completa i seguenti passaggi per avviare il tuo dominio di SageMaker Studio:
- Nella console di SageMaker, scegli Domini nel riquadro di navigazione.
- Scegli il dominio che hai creato come parte della stack di CloudFormation (
SageMakerDemoDomain). - Scegli Avvia e Studio.
Questa pagina può impiegare da 1 a 2 minuti per caricarsi quando accedi a SageMaker Studio per la prima volta, dopodiché verrai reindirizzato alla scheda Home.
Scarica il repository GitHub
Completa i seguenti passaggi per scaricare il repository GitHub:
- Nel notebook di SageMaker, nel menu File, scegli Nuovo e Terminale.
- Nel terminale, inserisci il seguente comando:
git clone https://github.com/aws-samples/amazon-sagemaker-featurestore-redshift-integration.gitOra puoi vedere la cartella amazon-sagemaker-featurestore-redshift-integration nel riquadro di navigazione di SageMaker Studio.
Configura l’ingestione batch con il connettore Spark
Completa i seguenti passaggi per configurare l’ingestione batch:
- In SageMaker Studio, apri il notebook 1-uploadJar.ipynb in
amazon-sagemaker-featurestore-redshift-integration. - Se ti viene richiesto di scegliere un kernel, scegli Data Science come immagine e Python 3 come kernel, quindi scegli Select.
- Per i notebook successivi, scegli la stessa immagine e kernel tranne il notebook AWS Glue Interactive Sessions (4a).
- Esegui le celle premendo Shift+Invio in ognuna delle celle.
Mentre il codice viene eseguito, compare un asterisco (*) tra le parentesi quadre. Quando il codice ha finito di eseguire, l’asterisco verrà sostituito da numeri. Questa azione è valida anche per tutti gli altri notebook.
Configura lo schema e carica i dati in Amazon Redshift
Il passo successivo consiste nel configurare lo schema e caricare i dati da Amazon Simple Storage Service (Amazon S3) in Amazon Redshift. Per farlo, esegui il notebook 2-loadredshiftdata.ipynb.
Crea feature store in SageMaker Feature Store
Per creare i tuoi feature store, esegui il notebook 3-createFeatureStore.ipynb.
Esegui l’ingegneria delle feature e l’ingestione delle feature in SageMaker Feature Store
In questa sezione, presentiamo i passaggi per tutte e tre le opzioni per eseguire l’ingegneria delle feature e l’ingestione delle feature elaborate in SageMaker Feature Store.
Opzione A: Usa SageMaker Studio con una sessione interattiva AWS Glue senza server
Completa i seguenti passaggi per l’opzione A:
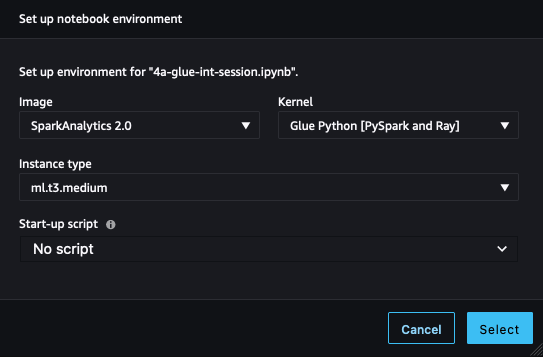
- In SageMaker Studio, apri il notebook 4a-glue-int-session.ipynb.
- Se ti viene richiesto di scegliere un kernel, scegli SparkAnalytics 2.0 come immagine e Glue Python [PySpark and Ray] come kernel, quindi scegli Select.
Il processo di preparazione dell’ambiente potrebbe richiedere del tempo per essere completato.
Opzione B: Usa un lavoro di elaborazione SageMaker con Spark
In questa opzione, utilizziamo un lavoro di elaborazione SageMaker con uno script Spark per caricare l’insieme di dati originale da Amazon Redshift, eseguire l’ingegneria delle feature e inserire i dati in SageMaker Feature Store. Per farlo, apri il notebook 4b-processing-rs-to-fs.ipynb nel tuo ambiente di SageMaker Studio.
Qui utilizziamo RedshiftDatasetDefinition per recuperare l’insieme di dati dal cluster Redshift. RedshiftDatasetDefinition è uno dei tipi di input del lavoro di elaborazione, che fornisce un’interfaccia semplice per configurare i parametri relativi alla connessione Redshift come identificatore, database, tabella, stringa di query e altro ancora. Puoi facilmente stabilire la connessione Redshift utilizzando RedshiftDatasetDefinition senza mantenere una connessione a tempo pieno. Utilizziamo anche la libreria SageMaker Feature Store Spark connector nel lavoro di elaborazione per connetterci a SageMaker Feature Store in un ambiente distribuito. Con questo connettore Spark, puoi facilmente inserire i dati nello store online e offline del gruppo di feature da un DataFrame Spark. Inoltre, questo connettore contiene la funzionalità di caricamento automatico delle definizioni delle feature per aiutare nella creazione dei gruppi di feature. In definitiva, questa soluzione ti offre un modo nativo di Spark per implementare un flusso di dati end-to-end da Amazon Redshift a SageMaker. Puoi eseguire qualsiasi ingegneria delle feature in un contesto Spark e inserire le feature finali in SageMaker Feature Store in un solo progetto Spark.
Per utilizzare il connettore Spark di SageMaker Feature Store, estendiamo un container predefinito di SageMaker Spark con sagemaker-feature-store-pyspark installato. Nello script Spark, utilizza il comando eseguibile di sistema per eseguire pip install, installare questa libreria nel tuo ambiente locale e ottenere il percorso locale del file JAR dipendenza. Nell’API del lavoro di elaborazione, fornisci questo percorso al parametro di submit_jars al nodo del cluster Spark che il lavoro di elaborazione crea.
Nello script Spark per il lavoro di elaborazione, leggiamo innanzitutto i file dell’insieme di dati originale da Amazon S3, che memorizza temporaneamente l’insieme di dati non caricato da Amazon Redshift come VoAGI. Quindi eseguiamo l’ingegneria delle feature in modo Spark e utilizziamo feature_store_pyspark per inserire i dati nello store offline delle feature.
Per il lavoro di elaborazione, forniamo un ProcessingInput con una redshift_dataset_definition. Qui costruiamo una struttura in base all’interfaccia, fornendo configurazioni relative alla connessione Redshift. Puoi utilizzare query_string per filtrare il tuo insieme di dati tramite SQL e scaricarlo in Amazon S3. Vedi il codice seguente:
rdd_input = ProcessingInput(
input_name="redshift_dataset_definition",
app_managed=True,
dataset_definition=DatasetDefinition(
local_path="/opt/ml/processing/input/rdd",
data_distribution_type="FullyReplicated",
input_mode="File",
redshift_dataset_definition=RedshiftDatasetDefinition(
cluster_id=_cluster_id,
database=_dbname,
db_user=_username,
query_string=_query_string,
cluster_role_arn=_redshift_role_arn,
output_s3_uri=_s3_rdd_output,
output_format="PARQUET"
),
),
)È necessario attendere da 6 a 7 minuti per ogni lavoro di elaborazione, inclusi gli insiemi di dati USER, PLACE e RATING.
Per ulteriori dettagli sui lavori di elaborazione di SageMaker, consulta l’elaborazione dei dati.
Per le soluzioni native di SageMaker per l’elaborazione delle feature da Amazon Redshift, è possibile utilizzare anche l’elaborazione delle feature in SageMaker Feature Store, che è per l’infrastruttura sottostante, inclusa la fornitura degli ambienti di calcolo e la creazione e la gestione delle pipeline di SageMaker per caricare e inserire i dati. Puoi concentrarti solo sulle definizioni del tuo processore delle feature che includono le funzioni di trasformazione, la fonte di Amazon Redshift e il sink di SageMaker Feature Store. La pianificazione, la gestione dei lavori e altre attività in produzione sono gestite da SageMaker. Le pipeline del processore delle feature sono pipeline di SageMaker, quindi sono disponibili i meccanismi standard di monitoraggio e le integrazioni.
Opzione C: Usa SageMaker Data Wrangler
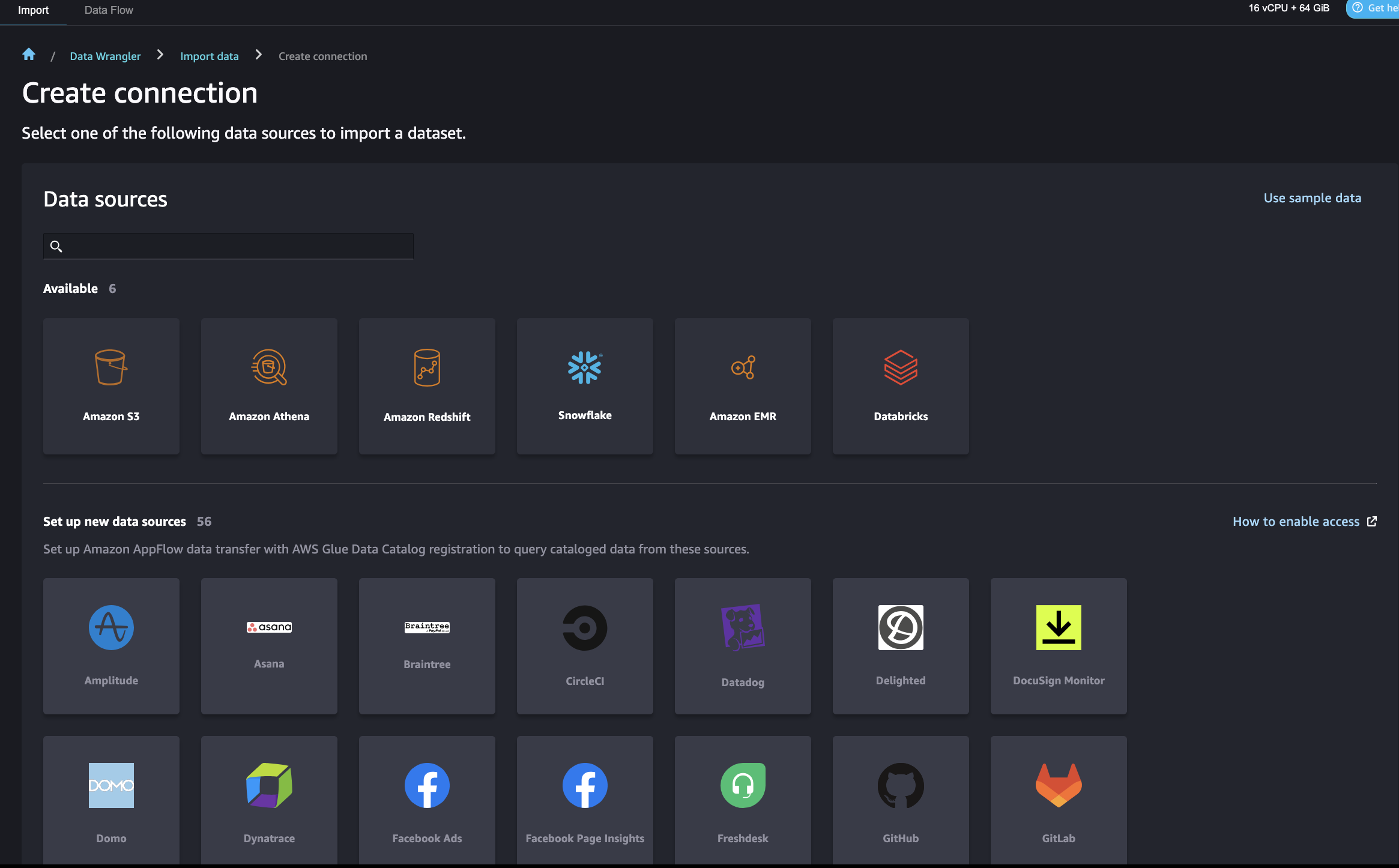
SageMaker Data Wrangler ti consente di importare dati da varie origini dati, inclusa Amazon Redshift, per una modalità di preparazione, trasformazione e creazione di feature a basso codice/no-code. Dopo aver completato la preparazione dei dati, puoi utilizzare SageMaker Data Wrangler per esportare le feature in SageMaker Feature Store.
Esistono alcune impostazioni di Identity and Access Management (IAM) di AWS che consentono a SageMaker Data Wrangler di connettersi a Amazon Redshift. Prima, crea un ruolo IAM (ad esempio, redshift-s3-dw-connect) che includa una policy di accesso ad Amazon S3. Per questo post, abbiamo allegato la policy AmazonS3FullAccess al ruolo IAM. Se hai restrizioni nell’accesso a un bucket S3 specificato, puoi definirlo nella policy di accesso ad Amazon S3. Abbiamo allegato il ruolo IAM al cluster Redshift che abbiamo creato in precedenza. Successivamente, crea una policy per consentire a SageMaker di accedere ad Amazon Redshift ottenendo le credenziali del cluster e allega la policy al ruolo IAM di SageMaker. La policy è simile al codice seguente:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "redshift:getclustercredentials",
"Effect": "Allow",
"Resource": [
"*"
]
}
]
}Dopo questa configurazione, SageMaker Data Wrangler ti permette di interrogare Amazon Redshift e di salvare i risultati in un bucket S3. Per le istruzioni per connetterti a un cluster Redshift e interrogare ed importare dati da Amazon Redshift a SageMaker Data Wrangler, consulta Importa dati da Amazon Redshift.
SageMaker Data Wrangler offre una selezione di oltre 300 trasformazioni di dati predefinite per casi d’uso comuni, come l’eliminazione di righe duplicate, l’imputazione di dati mancanti, la codifica one-hot e la gestione dei dati di serie temporali. Puoi anche aggiungere trasformazioni personalizzate in pandas o PySpark. Nel nostro esempio, abbiamo applicato alcune trasformazioni come la rimozione di colonne, l’applicazione di vincoli sui tipi di dati e la codifica ordinale dei dati.
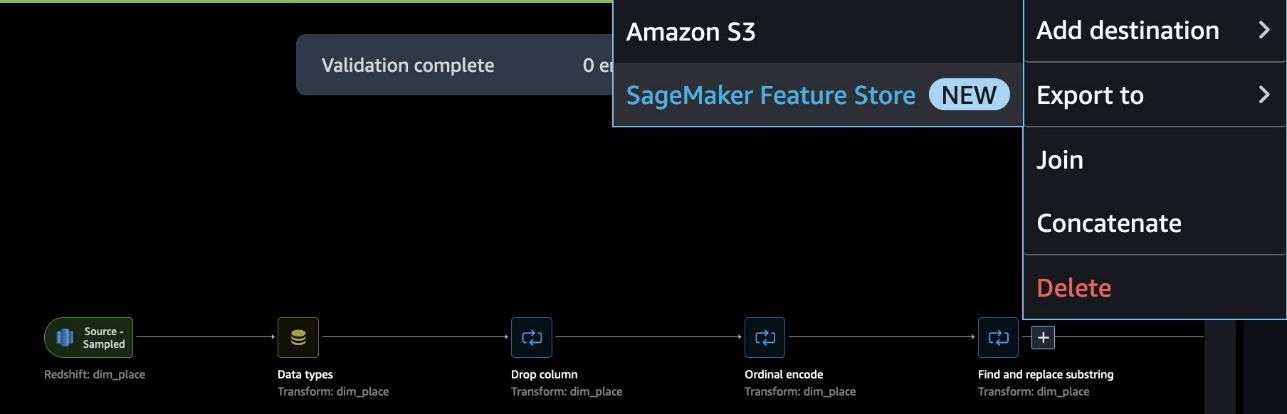
Quando il flusso di dati è completo, puoi esportarlo in SageMaker Feature Store. A questo punto, devi creare un gruppo di feature: assegna un nome al gruppo di feature, seleziona sia lo storage online che offline, fornisci il nome di un bucket S3 da utilizzare per lo storage offline e fornisce un ruolo con accesso a SageMaker Feature Store. Infine, puoi creare un job, che crea un job di elaborazione SageMaker che esegue il flusso di SageMaker Data Wrangler per acquisire le feature dalla fonte dati Redshift nel tuo gruppo di feature.

Ecco un flusso di dati end-to-end nello scenario di feature engineering del PLACE.
Usa SageMaker Feature Store per l’addestramento e la previsione dei modelli
Per utilizzare SageMaker Feature Store per l’addestramento e la previsione dei modelli, apri il notebook 5-classification-using-feature-groups.ipynb.
Dopo che i dati Redshift sono stati trasformati in feature e acquisiti in SageMaker Feature Store, le feature sono disponibili per la ricerca e la scoperta tra i team di data scientist responsabili di molti modelli ML indipendenti e casi d’uso. Questi team possono utilizzare le feature per la modellazione senza dover ricostruire o eseguire nuovamente i flussi di feature engineering. I gruppi di feature sono gestiti e scalati in modo indipendente e possono essere riutilizzati e uniti insieme indipendentemente dalla fonte dati upstream.
Il passo successivo è creare modelli di ML utilizzando le feature selezionate da uno o più gruppi di feature. Decidi quali gruppi di feature utilizzare per i tuoi modelli. Ci sono due opzioni per creare un dataset di ML dai gruppi di feature, entrambe utilizzando il SageMaker Python SDK:
- Usa l’API DatasetBuilder di SageMaker Feature Store – L’API DatasetBuilder di SageMaker Feature Store consente ai data scientist di creare dataset di ML da uno o più gruppi di feature nello storage offline. Puoi utilizzare l’API per creare un dataset da un singolo o più gruppi di feature e salvarlo come file CSV o come DataFrame di pandas. Ecco un esempio di codice:
from sagemaker.feature_store.dataset_builder import DatasetBuilder
fact_rating_dataset = DatasetBuilder(
sagemaker_session = sagemaker_session,
base = fact_rating_feature_group,
output_path = f"s3://{s3_bucket_name}/{prefix}",
record_identifier_feature_name = 'ratingid',
event_time_identifier_feature_name = 'timestamp',
).to_dataframe()[0]- Esegui query SQL utilizzando la funzione athena_query nell’API FeatureGroup – Un’altra opzione è utilizzare il catalogo dei dati AWS Glue predefinito per l’API FeatureGroup. L’API FeatureGroup include una funzione
Athena_queryche crea un’istanza di AthenaQuery per eseguire query SQL definite dall’utente. Quindi esegui la query Athena e organizza il risultato della query in un DataFrame di pandas. Questa opzione ti consente di specificare query SQL più complesse per estrarre informazioni da un gruppo di feature. Ecco un esempio di codice:
dim_user_query = dim_user_feature_group.athena_query()
dim_user_table = dim_user_query.table_name
dim_user_query_string = (
'SELECT * FROM "'
+ dim_user_table
+ '"'
)
dim_user_query.run(
query_string = dim_user_query_string,
output_location = f"s3://{s3_bucket_name}/{prefix}",
)
dim_user_query.wait()
dim_user_dataset = dim_user_query.as_dataframe()Successivamente, possiamo unire i dati interrogati da diversi gruppi di funzionalità nel nostro dataset finale per l’addestramento e il testing del modello. In questo post, utilizziamo la trasformazione batch per l’inferenza del modello. La trasformazione batch consente di ottenere l’inferenza del modello su un insieme di dati bulk in Amazon S3, e il risultato dell’inferenza viene anch’esso archiviato in Amazon S3. Per ulteriori dettagli sull’addestramento e l’inferenza del modello, fare riferimento al notebook 5-classification-using-feature-groups.ipynb.
Esegui una query di join sui risultati di previsione in Amazon Redshift
Infine, interrogiamo il risultato dell’inferenza e lo uniamo ai profili utente originali in Amazon Redshift. Per fare ciò, utilizziamo Amazon Redshift Spectrum per unire i risultati di previsione batch in Amazon S3 con i dati originali di Redshift. Per ulteriori dettagli, fare riferimento al notebook run 6-read-results-in-redshift.ipynb.
Pulizia
In questa sezione, forniamo i passaggi per pulire le risorse create come parte di questo post al fine di evitare addebiti continui.
Arresta le applicazioni SageMaker
Seguire i seguenti passaggi per arrestare le risorse:
- In SageMaker Studio, nel menu File, scegliere Arresta.
- Nella finestra di conferma dell’arresto, scegliere Arresta tutto per procedere.
- Dopo aver ricevuto il messaggio “Server stopped”, è possibile chiudere questa scheda.
Elimina le applicazioni
Seguire i seguenti passaggi per eliminare le applicazioni:
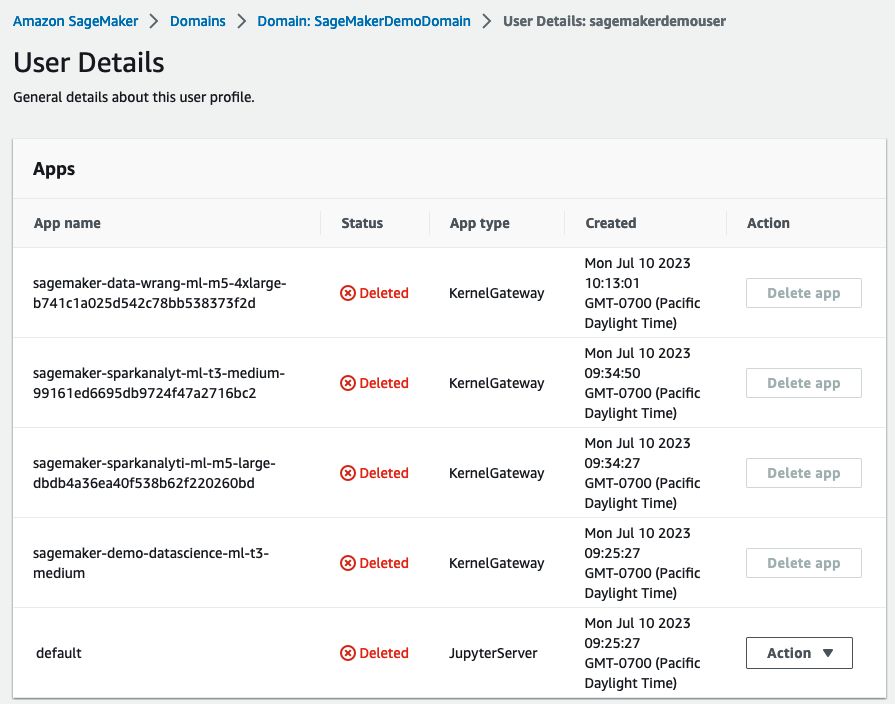
- Nella console di SageMaker, nel riquadro di navigazione, scegliere Domini.
- Nella pagina Domini, scegliere
SageMakerDemoDomain. - Nella pagina dei dettagli del dominio, sotto Profili utente, scegliere l’utente
sagemakerdemouser. - Nella sezione App, nella colonna Azione, scegliere Elimina app per eventuali app attive.
- Assicurarsi che la colonna Stato indichi Eliminato per tutte le app.
Elimina il volume di archiviazione EFS associato al tuo dominio SageMaker
Trovare il volume EFS nella console di SageMaker ed eliminarlo. Per istruzioni, fare riferimento a Gestisci il volume di archiviazione Amazon EFS in SageMaker Studio.
Elimina i bucket S3 predefiniti per SageMaker
Elimina i bucket S3 predefiniti (sagemaker-<region-code>-<acct-id>) per SageMaker se non si sta utilizzando SageMaker in quella regione.
Elimina lo stack di CloudFormation
Elimina lo stack di CloudFormation nel tuo account AWS per pulire tutte le risorse correlate.
Conclusioni
In questo post, abbiamo dimostrato un flusso di dati e ML end-to-end da un data warehouse Redshift a SageMaker. È possibile utilizzare facilmente l’integrazione nativa di AWS di motori appositamente progettati per attraversare senza soluzione di continuità il percorso dei dati. Consultare il blog AWS per ulteriori pratiche sulla creazione di funzionalità di ML da un data warehouse moderno.





