LangChain + Streamlit + Llama Portare l’IA conversazionale sulla tua macchina locale
LangChain + Streamlit + Llama IA conversazionale sulla tua macchina locale

Negli ultimi mesi, i Large Language Models (LLM) hanno attirato notevole attenzione, catturando l’interesse degli sviluppatori in tutto il pianeta. Questi modelli hanno creato prospettive entusiasmanti, specialmente per gli sviluppatori che lavorano su chatbot, assistenti personali e creazione di contenuti. Le possibilità che i LLM portano sul tavolo hanno suscitato un’ondata di entusiasmo nella comunità di sviluppatori | AI | NLP.
Cosa sono i LLM?
- Sbloccare l’Eccellenza Operativa attraverso il Process Mining e la Trasformazione Digitale nella Industria 4.0
- L’Incredibile Efficacia del Transfer Learning
- Come i modelli di apprendimento automatico possono amplificare le disuguaglianze nella diagnosi e nel trattamento medico
I Large Language Models (LLM) si riferiscono a modelli di apprendimento automatico capaci di produrre testo che assomiglia da vicino al linguaggio umano e di comprendere prompt in modo naturale. Questi modelli vengono addestrati utilizzando ampi set di dati che comprendono libri, articoli, siti web e altre fonti. Analizzando i modelli statistici all’interno dei dati, i LLM prevedono le parole o le frasi più probabili che dovrebbero seguire un determinato input.
Utilizzando i Large Language Models (LLM), possiamo incorporare dati specifici del dominio per affrontare le richieste in modo efficace. Questo diventa particolarmente vantaggioso quando si tratta di informazioni a cui il modello non aveva accesso durante il suo addestramento iniziale, come la documentazione interna o il repository di conoscenze di un’azienda.
L’architettura utilizzata a questo scopo è nota come Retrieval Augmentation Generation o, meno comunemente, Generative Question Answering.
Cos’è LangChain
LangChain è un framework impressionante e liberamente disponibile, meticolosamente progettato per fornire agli sviluppatori la possibilità di creare applicazioni alimentate dalla potenza dei modelli di linguaggio, in particolare dei large language models (LLM).
LangChain rivoluziona il processo di sviluppo di una vasta gamma di applicazioni, tra cui chatbot, Generative Question-Answering (GQA) e sintesi. Unendo in modo fluido componenti provenienti da moduli multipli, LangChain consente la creazione di applicazioni eccezionali basate sulla potenza dei LLM.
Per saperne di più: Documentazione ufficiale
Motivazione?
In questo articolo, illustrerò il processo di creazione del tuo assistente documentale personale, utilizzando LLaMA 7b e LangChain, una libreria open-source sviluppata appositamente per l’integrazione senza soluzione di continuità con i LLM.
Ecco una panoramica della struttura del blog, che illustra le sezioni specifiche che forniranno una dettagliata descrizione del processo:
Configurazione dell'ambiente virtuale e creazione della struttura dei fileOttenere LLM sulla tua macchina localeIntegrazione di LLM con LangChain e personalizzazione di PromptTemplateRecupero del documento e generazione della rispostaCreazione dell'applicazione utilizzando Streamlit
Sezione 1: Configurazione dell’ambiente virtuale e creazione della struttura dei file
La configurazione di un ambiente virtuale fornisce un ambiente controllato e isolato per l’esecuzione dell’applicazione, garantendo che le sue dipendenze siano separate da altri pacchetti di sistema. Questo approccio semplifica la gestione delle dipendenze e aiuta a mantenere la coerenza tra diversi ambienti.
Per configurare l’ambiente virtuale per questa applicazione, fornirò il file pip nel mio repository GitHub. Per prima cosa, creiamo la struttura dei file necessaria come mostrato nella figura. In alternativa, è possibile clonare semplicemente il repository per ottenere i file richiesti.
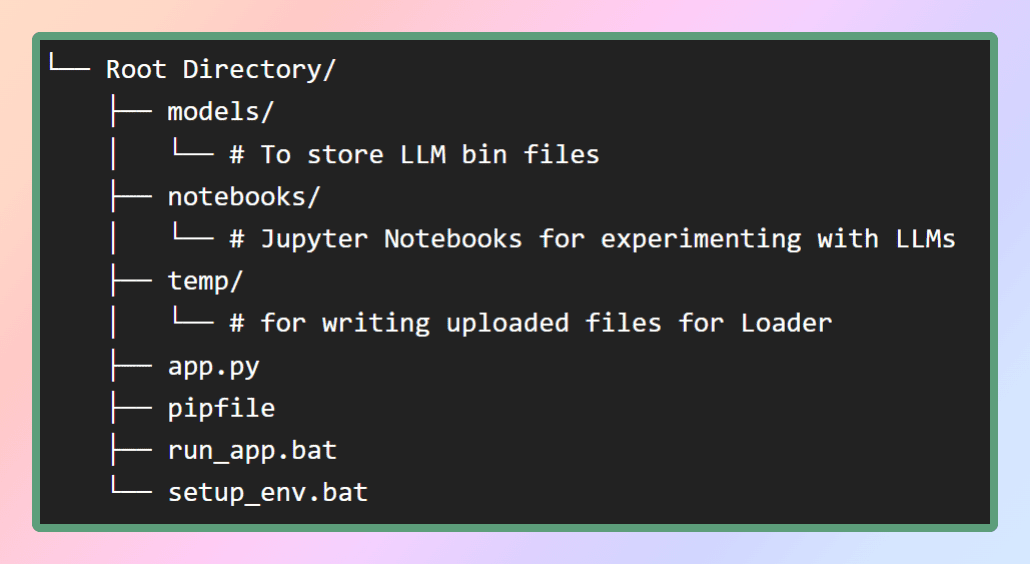
All’interno della cartella dei modelli, archivieremo i LLM che scaricheremo, mentre il file pip sarà posizionato nella directory principale.
Per creare l’ambiente virtuale e installare tutte le dipendenze al suo interno, possiamo utilizzare il comando pipenv install dalla stessa directory o eseguire semplicemente il file batch setup_env.bat. Questo installerà tutte le dipendenze dal file pipfile. In questo modo, tutte le librerie e i pacchetti necessari verranno installati nell’ambiente virtuale. Una volta che le dipendenze sono state installate con successo, possiamo procedere al passaggio successivo, che prevede il download dei modelli desiderati. Ecco il repository.
Sezione 2: Ottenere LLaMA sulla tua macchina locale
Cos’è LLaMA?
LLaMA è un nuovo grande modello di linguaggio progettato da Meta AI, che è la società madre di Facebook. Con una vasta collezione di modelli che variano da 7 miliardi a 65 miliardi di parametri, LLaMA si distingue come uno dei modelli di linguaggio più completi disponibili. Il 24 febbraio 2023, Meta ha rilasciato il modello LLaMA al pubblico, dimostrando la loro dedizione alla scienza aperta.
Considerando le notevoli capacità di LLaMA, abbiamo scelto di utilizzare questo potente modello di linguaggio per i nostri scopi. In particolare, utilizzeremo la versione più piccola di LLaMA, nota come LLaMA 7B. Anche a questa dimensione ridotta, LLaMA 7B offre significative capacità di elaborazione del linguaggio, consentendoci di raggiungere i nostri obiettivi in modo efficiente ed efficace.
Articolo di ricerca ufficiale :
LLaMA: Fondamenta di modelli di linguaggio aperti ed efficienti
Per eseguire LLM su una CPU locale, abbiamo bisogno di un modello locale in formato GGML. Ci sono diversi metodi per raggiungere questo obiettivo, ma l’approccio più semplice è scaricare direttamente il file bin dal repository dei modelli di Hugging Face. Nel nostro caso, scaricheremo il modello Llama 7B. Questi modelli sono open-source e disponibili gratuitamente per il download.
Se stai cercando di risparmiare tempo e fatica, non preoccuparti – ho tutto sotto controllo. Ecco il link diretto per scaricare i modelli ?. Basta scaricare una qualsiasi versione e quindi spostare il file nella directory dei modelli all’interno della nostra directory principale. In questo modo, avrai il modello comodamente accessibile per il tuo utilizzo.
Cos’è GGML? Perché GGML? Come GGML? LLaMA CPP
GGML è una libreria Tensor per l’apprendimento automatico, è solo una libreria C++ che consente di eseguire LLM solo sulla CPU o CPU + GPU. Definisce un formato binario per la distribuzione di grandi modelli di linguaggio (LLM). GGML fa uso di una tecnica chiamata quantizzazione che consente ai grandi modelli di linguaggio di essere eseguiti su hardware per consumatori.
Ora, cos’è la quantizzazione?
I pesi LLM sono numeri in virgola mobile (decimali). Proprio come è necessario più spazio per rappresentare un numero intero grande (ad esempio 1000) rispetto a un numero intero piccolo (ad esempio 1), è necessario più spazio per rappresentare un numero in virgola mobile ad alta precisione (ad esempio 0,0001) rispetto a un numero in virgola mobile a bassa precisione (ad esempio 0,1). Il processo di quantizzazione di un grande modello di linguaggio comporta la riduzione della precisione con cui i pesi vengono rappresentati al fine di ridurre le risorse necessarie per utilizzare il modello. GGML supporta diverse strategie di quantizzazione (ad esempio quantizzazione a 4 bit, 5 bit e 8 bit), ognuna delle quali offre trade-off diversi tra efficienza e prestazioni.
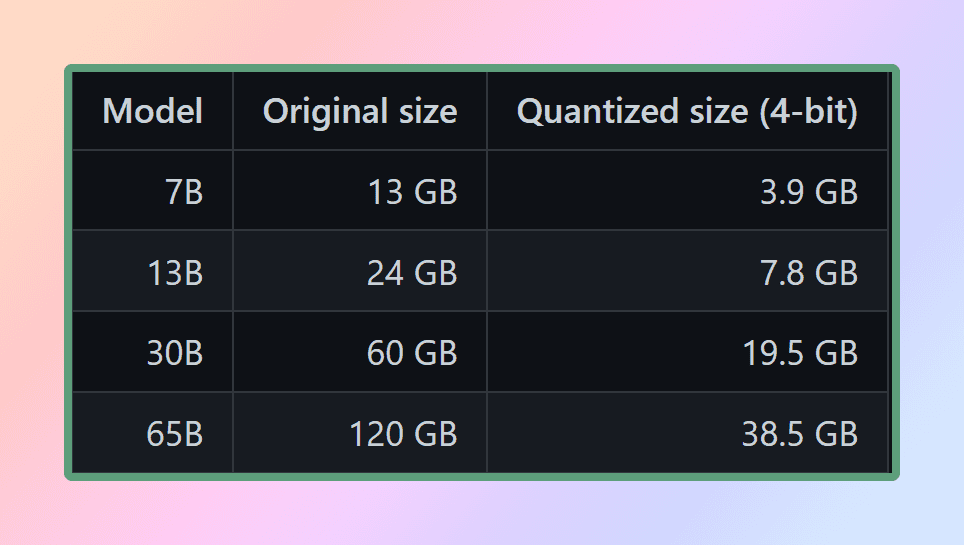
Per utilizzare efficacemente i modelli, è essenziale considerare i requisiti di memoria e disco. Poiché attualmente i modelli vengono caricati interamente in memoria, sarà necessario uno spazio su disco sufficiente per archiviarli e abbastanza RAM per caricarli durante l’esecuzione. Per il modello da 65 miliardi, anche dopo la quantizzazione, è consigliabile disporre di almeno 40 gigabyte di RAM disponibili. È importante notare che i requisiti di memoria e disco sono attualmente equivalenti.
La quantizzazione svolge un ruolo fondamentale nella gestione di queste esigenze di risorse. A meno che tu non abbia accesso a risorse computazionali eccezionali
Riducendo la precisione dei parametri del modello e ottimizzando l’utilizzo della memoria, la quantizzazione consente ai modelli di essere utilizzati su configurazioni hardware più modeste. Ciò garantisce che l’esecuzione dei modelli rimanga fattibile ed efficiente per una gamma più ampia di configurazioni.
Come lo usiamo in Python se è una libreria C++?
Ecco dove entrano in gioco i binding di Python. Il binding si riferisce al processo di creazione di un ponte o di un’interfaccia tra due linguaggi, nel nostro caso Python e C++. Utilizzeremo llama-cpp-python che è un binding di Python per llama.cpp che funge da inferenza del modello LLaMA in puro C/C++. L’obiettivo principale di llama.cpp è eseguire il modello LLaMA utilizzando la quantizzazione degli interi a 4 bit. Questa integrazione ci consente di utilizzare efficacemente il modello LLaMA, sfruttando i vantaggi dell’implementazione in C/C++ e i benefici della quantizzazione degli interi a 4 bit

Con il modello GGML preparato e tutte le nostre dipendenze al loro posto (grazie al pipfile), è ora il momento di intraprendere il nostro viaggio con LangChain. Ma prima di immergerci nel mondo emozionante di LangChain, iniziamo con il consueto rituale del “Hello World” – una tradizione che seguiamo ogni volta che esploriamo un nuovo linguaggio o framework, dopotutto, LLM è anche un modello di linguaggio.
 Immagine dell’autore: Interazione con LLM su CPU
Immagine dell’autore: Interazione con LLM su CPU
Voilà !!! Abbiamo eseguito con successo il nostro primo LLM sulla CPU, completamente offline e in modo completamente casuale (puoi giocare con l’iperparametro temperature).
Con questo entusiasmante traguardo raggiunto, siamo ora pronti per intraprendere il nostro obiettivo principale: rispondere alle domande di testo personalizzato utilizzando il framework LangChain.
Sezione 3: Iniziare con LLM – Integrazione di LangChain
Nella sezione precedente, abbiamo inizializzato LLM utilizzando llama cpp. Ora, sfruttiamo il framework LangChain per sviluppare applicazioni utilizzando LLM. L’interfaccia principale attraverso cui puoi interagire con loro è attraverso il testo. Come semplificazione eccessiva, molti modelli sono testo in ingresso, testo in uscita. Pertanto, molte delle interfacce in LangChain sono incentrate sul testo.
La crescita dell’ingegneria delle prompt
Nel campo in continua evoluzione della programmazione è emerso un paradigma affascinante: Prompting. Il prompting consiste nel fornire un input specifico a un modello di linguaggio per ottenere una risposta desiderata. Questo approccio innovativo ci consente di modellare l’output del modello in base all’input che forniamo.
È notevole come le sfumature nel modo in cui formuliamo un prompt possano influenzare significativamente la natura e il contenuto della risposta del modello. Il risultato può variare fondamentalmente in base alla formulazione, evidenziando l’importanza di una riflessione attenta nella formulazione dei prompt.
Per fornire un’interazione senza soluzione di continuità con LLM, LangChain fornisce diverse classi e funzioni per facilitare la costruzione e il lavoro con i prompt utilizzando un modello di prompt. Si tratta di un modo riproducibile per generare un prompt. Contiene una stringa di testo il modello, che può prendere un insieme di parametri dall’utente finale e generare un prompt. Prendiamo alcuni esempi.
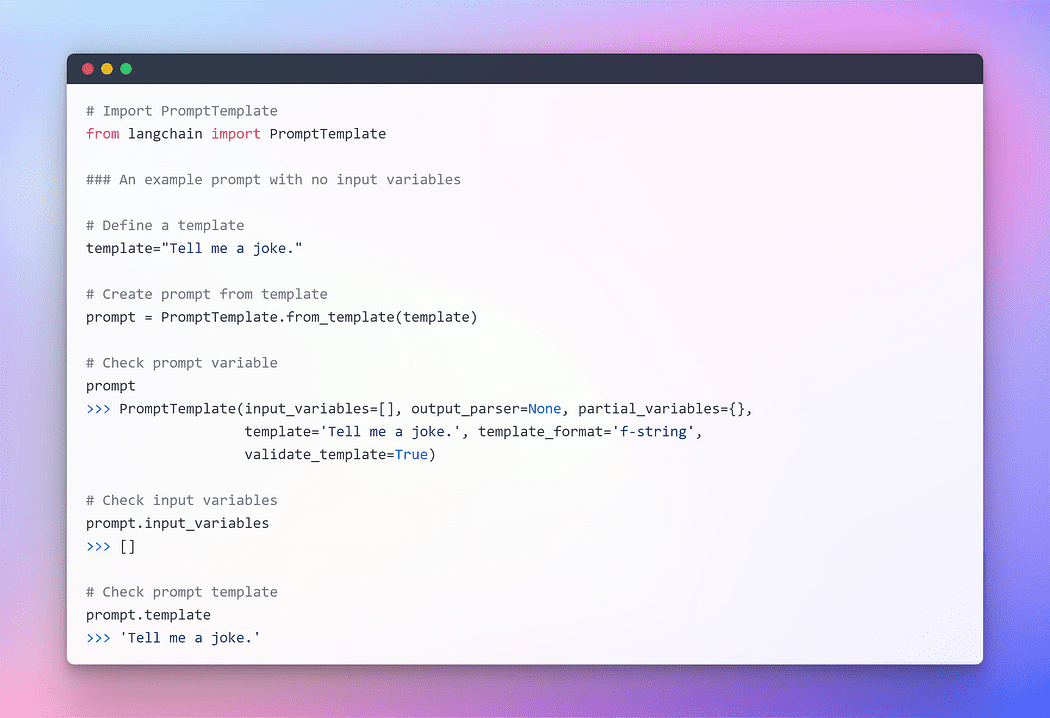 Immagine dell’autore: Prompt senza variabili di input
Immagine dell’autore: Prompt senza variabili di input
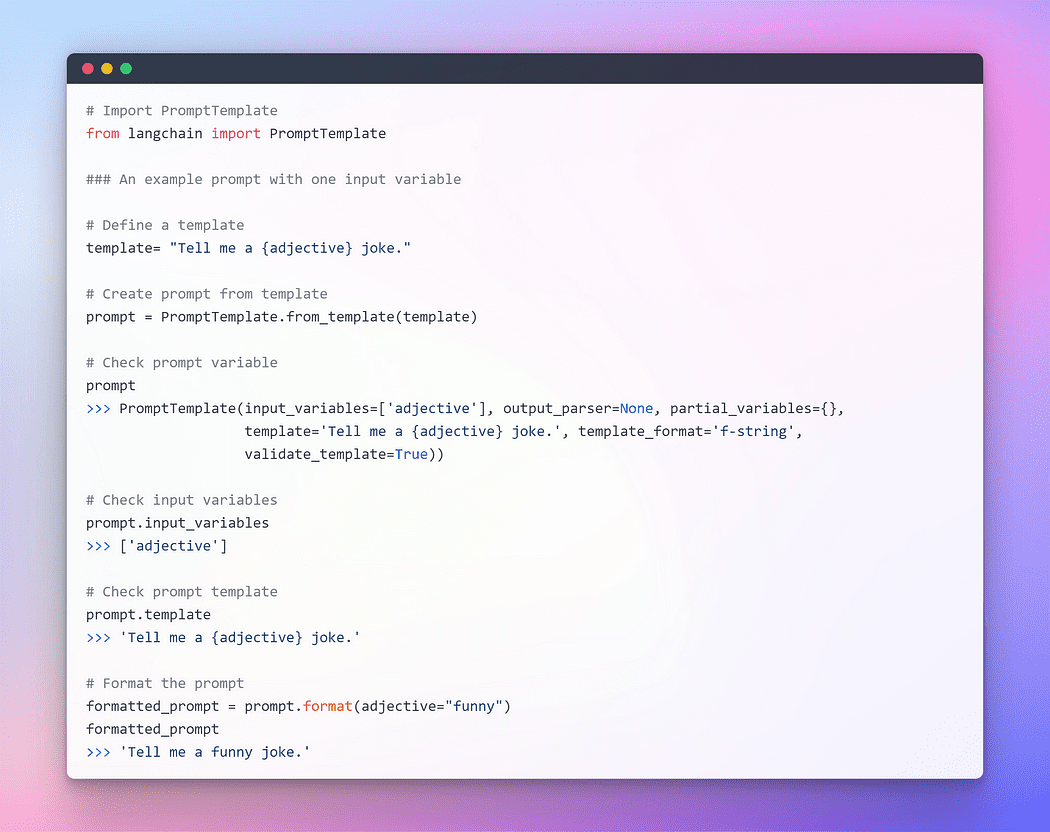 Immagine dell’autore: Prompt con una variabile di input
Immagine dell’autore: Prompt con una variabile di input
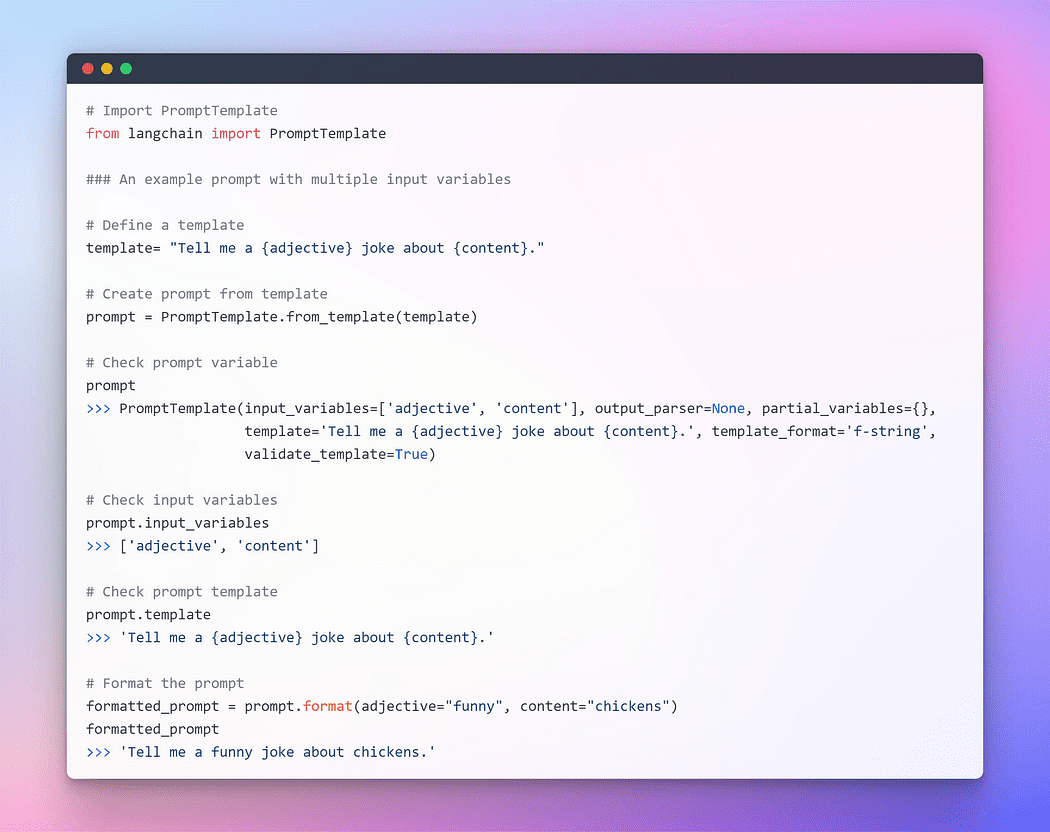 Immagine dell’autore: Prompt con più variabili di input
Immagine dell’autore: Prompt con più variabili di input
Spero che la spiegazione precedente abbia fornito una comprensione più chiara del concetto di prompting. Ora, procediamo a fornire un prompt a LLM.
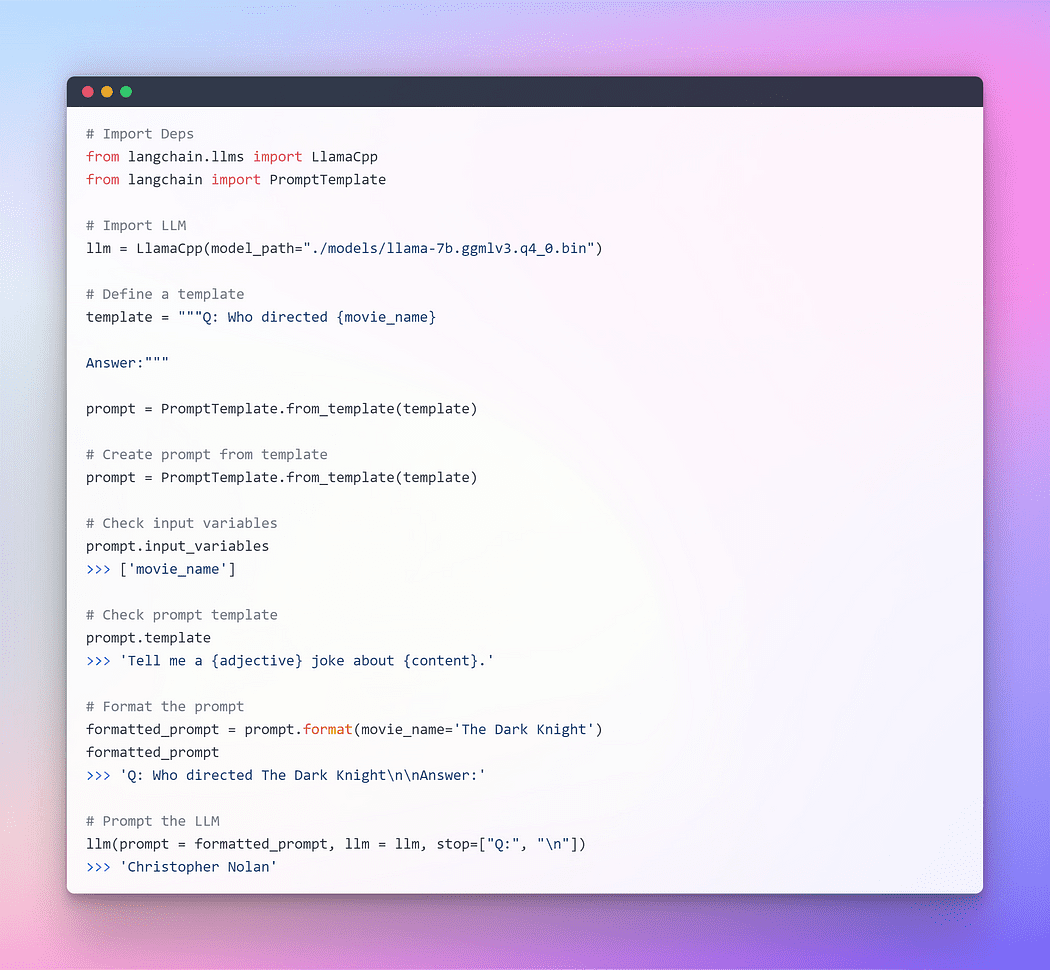 Immagine di Autore: Prompting attraverso Langchain LLM
Immagine di Autore: Prompting attraverso Langchain LLM
Questo ha funzionato perfettamente, ma non è l’utilizzo ottimale di LangChain. Finora abbiamo utilizzato componenti individuali. Abbiamo preso il modello di prompt, lo abbiamo formattato, poi abbiamo preso l’LLM e abbiamo passato quei parametri all’interno dell’LLM per generare la risposta. Utilizzare un LLM in isolamento è adatto per applicazioni semplici, ma applicazioni più complesse richiedono l’uso di LLM concatenati, sia tra loro che con altri componenti.
LangChain fornisce l’interfaccia Chain per tali applicazioni concatenate. Definiamo una Chain in modo molto generico come una sequenza di chiamate a componenti, che possono includere altre chains. Le chains ci consentono di combinare più componenti insieme per creare un’applicazione singola e coerente. Ad esempio, possiamo creare una chain che prende l’input dell’utente, lo formatta con un modello di prompt e poi passa la risposta formattata a un LLM. Possiamo costruire chains più complesse combinando più chains insieme o combinando chains con altri componenti.
Per capirne una, creiamo una chain molto semplice che prenderà l’input dell’utente, formatterà il prompt con esso e poi lo invierà all’LLM utilizzando i componenti individuali sopra creati.
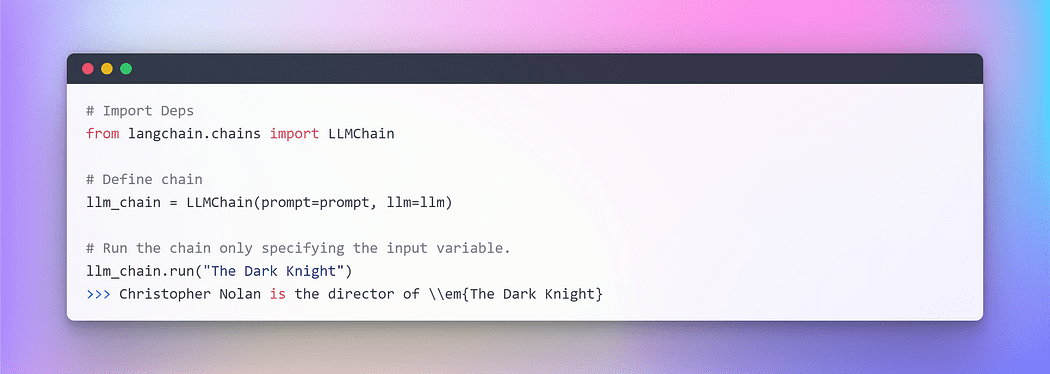 Immagine di Autore: Concatenazione in LangChain
Immagine di Autore: Concatenazione in LangChain
Quando si gestiscono più variabili, hai l’opzione di inserirle collettivamente utilizzando un dizionario. Questa conclude questa sezione. Ora, immergiamoci nella parte principale in cui incorporeremo il testo esterno come un recuperatore per scopi di domanda e risposta.
Sezione 4: Generazione di Embedding e Vectorstore per la Domanda e Risposta
In numerose applicazioni LLM, c’è la necessità di dati specifici dell’utente che non sono inclusi nell’insieme di addestramento del modello. LangChain ti fornisce i componenti essenziali per caricare, trasformare, archiviare e interrogare i tuoi dati.
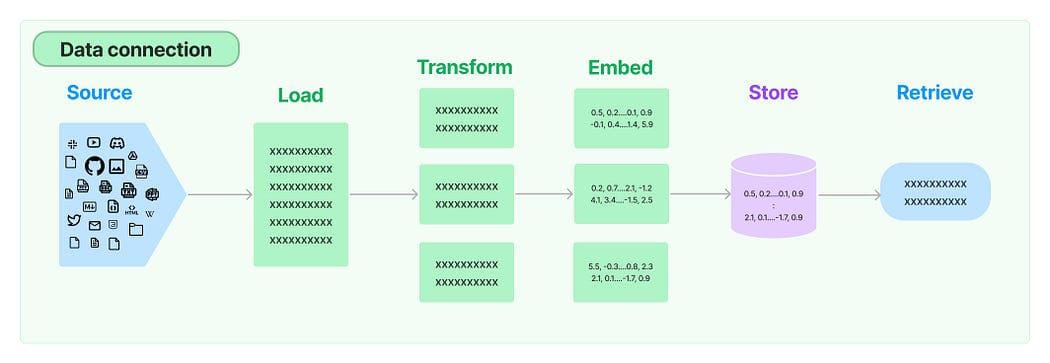 Connessione Dati in LangChain: Sorgente
Connessione Dati in LangChain: Sorgente
Le cinque fasi sono:
- Caricatore Documenti: Viene utilizzato per caricare i dati come documenti.
- Trasformatore Documenti: Divide il documento in frammenti più piccoli.
- Embedding: Trasforma i frammenti in rappresentazioni vettoriali, chiamate embedding.
- Archivi Vettoriali: Viene utilizzato per archiviare i vettori dei frammenti sopra in un database vettoriale.
- Recuperatori: Viene utilizzato per recuperare un insieme di vettori che sono più simili a una query in forma di un vettore che è incorporato nello stesso spazio latente.
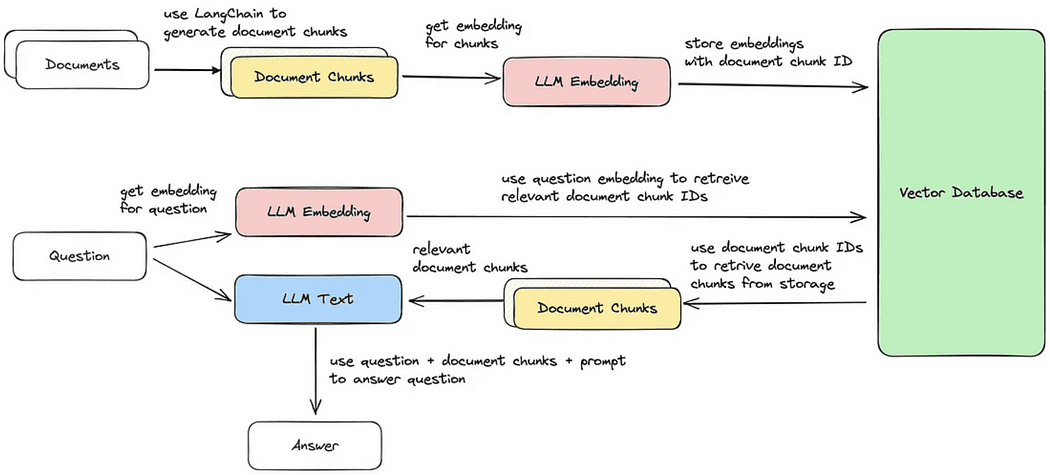 Ciclo di Recupero Documenti / Domanda e Risposta
Ciclo di Recupero Documenti / Domanda e Risposta
Ora, passeremo attraverso ciascuno dei cinque passaggi per eseguire un recupero di frammenti di documenti che sono più simili alla query. Successivamente, possiamo generare una risposta basata sul frammento vettoriale recuperato, come illustrato nell’immagine fornita.
Tuttavia, prima di procedere ulteriormente, dovremo preparare un testo per eseguire i compiti sopra menzionati. A scopo di questo test fittizio, ho copiato un testo da Wikipedia riguardante alcuni popolari supereroi DC. Ecco il testo:
 Immagine di Autore: Testo Grezzo per il Test
Immagine di Autore: Testo Grezzo per il Test
Caricamento e Trasformazione dei Documenti
Per iniziare, creiamo un oggetto documento. In questo esempio, utilizzeremo il caricatore di testo. Tuttavia, LangChain offre supporto per documenti multipli, quindi a seconda del tuo documento specifico, puoi utilizzare diversi caricatori. Successivamente, utilizzeremo il metodo load per recuperare i dati e caricarli come documenti da una fonte preconfigurata.
Una volta caricato il documento, possiamo procedere con il processo di trasformazione suddividendolo in pezzi più piccoli. Per fare ciò, utilizzeremo il TextSplitter. Di default, lo splitter separa il documento al separatore ‘\n\n’. Tuttavia, se si imposta il separatore su null e si definisce una dimensione specifica per i pezzi, ogni pezzo avrà quella lunghezza specificata. Di conseguenza, la lunghezza della lista risultante sarà uguale alla lunghezza del documento diviso per la dimensione dei pezzi. In sintesi, assomiglierà a qualcosa del genere: lunghezza della lista = lunghezza del documento / dimensione dei pezzi. Mettiamoci all’opera.
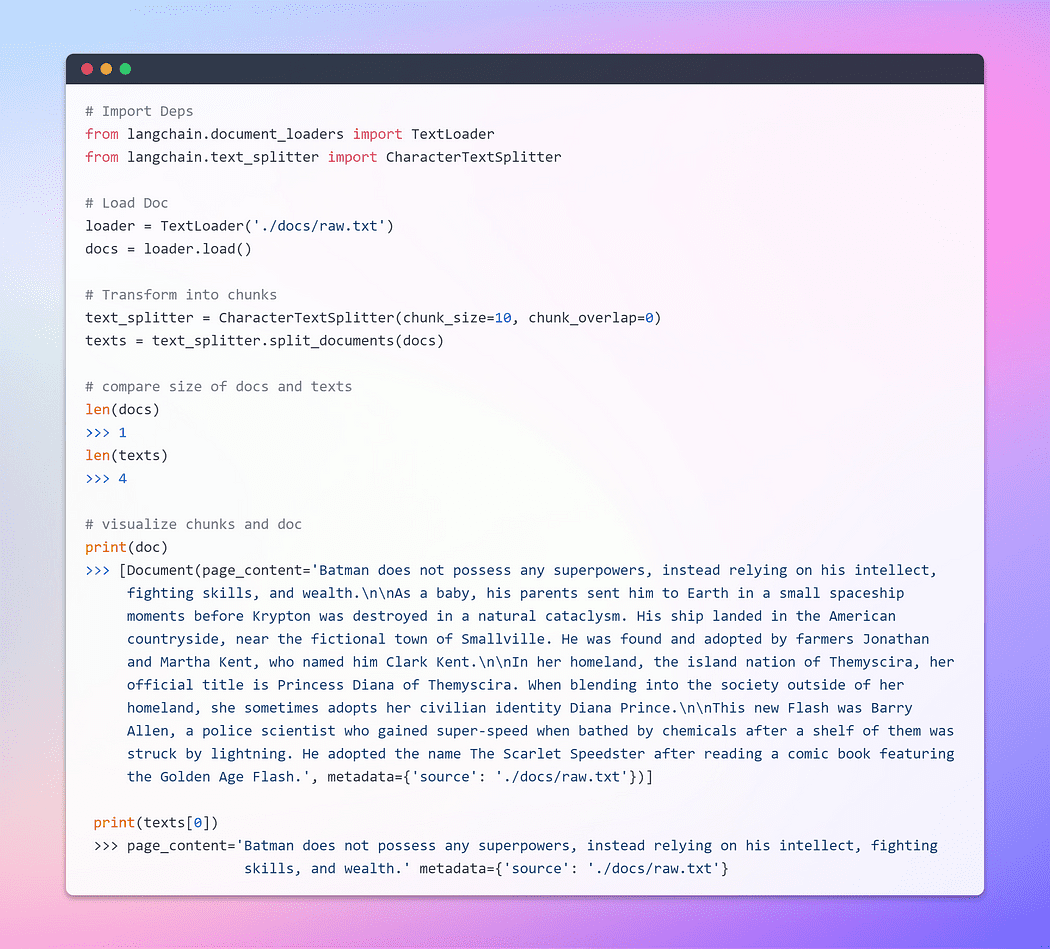 Immagine dell’autore: Caricamento e Trasformazione del Documento
Immagine dell’autore: Caricamento e Trasformazione del Documento
Parte del viaggio sono le Embeddings !!!
Questo è il passaggio più importante. Le Embeddings generano una rappresentazione vettoriale di un contenuto testuale. Ciò ha una rilevanza pratica poiché ci consente di concettualizzare il testo all’interno di uno spazio vettoriale.
L’embedding di una parola è semplicemente una rappresentazione vettoriale di una parola, con il vettore che contiene numeri reali. Poiché le lingue di solito contengono almeno decine di migliaia di parole, i semplici vettori binari delle parole possono diventare impraticabili a causa di un elevato numero di dimensioni. Le embedding delle parole risolvono questo problema fornendo rappresentazioni dense delle parole in uno spazio vettoriale a bassa dimensione.
Quando parliamo di recupero, ci riferiamo al recupero di un insieme di vettori che sono più simili possibile a una query in forma di un vettore che è incorporato nello stesso spazio latente.
La classe base Embeddings in LangChain espone due metodi: uno per l’embedding dei documenti e uno per l’embedding di una query. Il primo prende in input più testi, mentre il secondo prende un singolo testo.
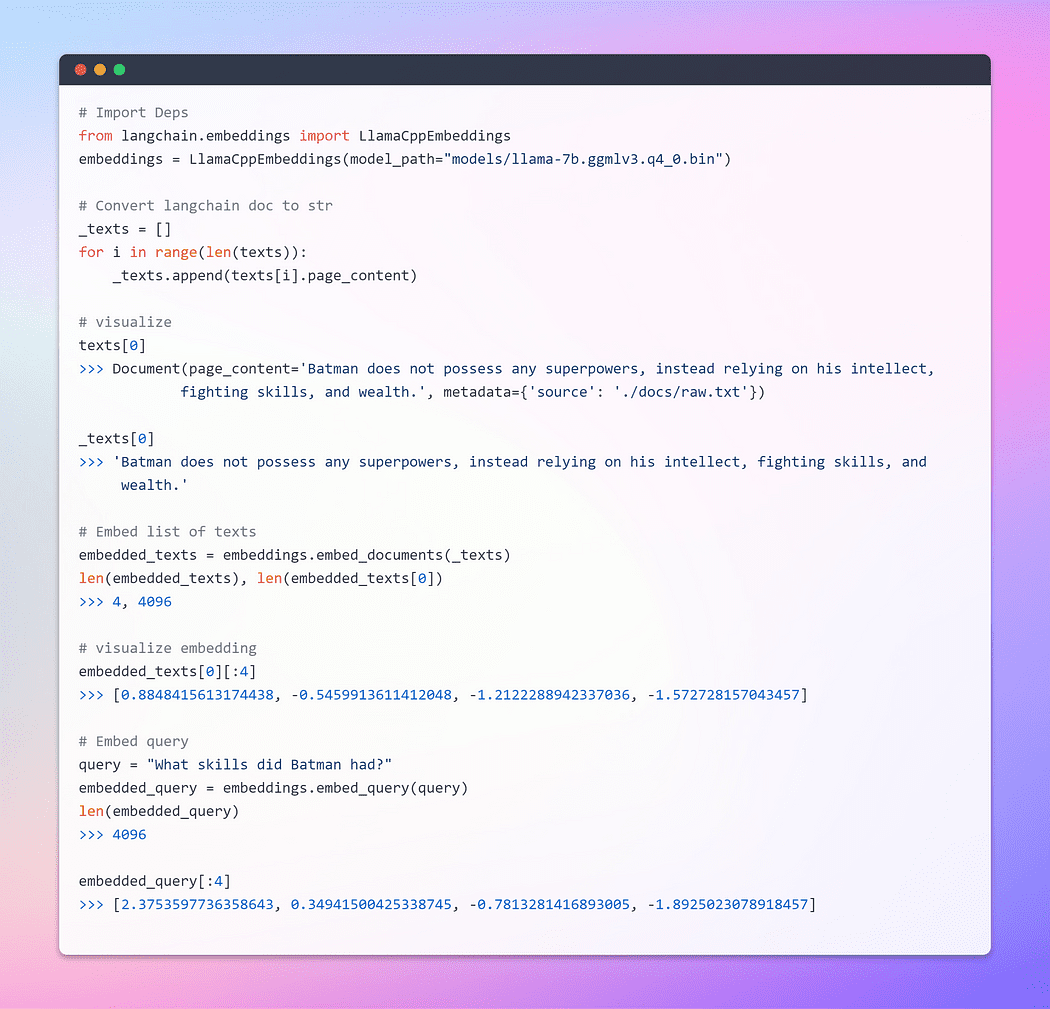 Immagine dell’autore: Embeddings
Immagine dell’autore: Embeddings
Per una comprensione completa delle embeddings, consiglio vivamente di approfondire i fondamenti poiché costituiscono il nucleo di come le reti neurali gestiscono i dati testuali. Ho trattato ampiamente questo argomento in uno dei miei blog utilizzando TensorFlow. Ecco il link.
Word Embeddings — Rappresentazione del Testo per le Reti Neurali
Creazione del Vector Store e Recupero dei Documenti
Un vector store gestisce efficientemente la memorizzazione dei dati incorporati e facilita le operazioni di ricerca di vettori per conto tuo. L’embedding e la memorizzazione dei vettori di embedding risultanti è un metodo diffuso per la memorizzazione e la ricerca di dati non strutturati. Durante la query, anche la query non strutturata viene incorporata e vengono recuperati i vettori di embedding che mostrano la maggiore similarità con la query incorporata. Questo approccio consente un recupero efficace delle informazioni rilevanti dal vector store.
Qui, utilizzeremo Chroma, un database di embedding e un vector store appositamente creato per semplificare lo sviluppo di applicazioni di intelligenza artificiale che incorporano embeddings. Offre una suite completa di strumenti e funzionalità integrate per facilitare la configurazione iniziale, tutto ciò può essere comodamente installato sulla tua macchina locale eseguendo un semplice comando pip install chromadb.
 Immagine dell’autore: Creazione del Vector Store
Immagine dell’autore: Creazione del Vector Store
Fino ad ora, abbiamo assistito alla notevole capacità delle embeddings e dei vector store nel recuperare pezzi rilevanti da collezioni di documenti estesi. Ora è arrivato il momento di presentare questo pezzo recuperato come contesto insieme alla nostra query, al LLM. Con un colpo di bacchetta magica, supplicheremo il LLM di generare una risposta basata sulle informazioni che gli abbiamo fornito. La parte importante è la struttura della richiesta.
Tuttavia, è cruciale sottolineare l’importanza di una richiesta ben strutturata. Formulando una richiesta ben strutturata, possiamo mitigare il potenziale per il LLM di impegnarsi in allucinazioni – in cui potrebbe inventare fatti di fronte all’incertezza.
Senza prolungare ulteriormente l’attesa, procediamo ora alla fase finale e scopriamo se il nostro LLM è in grado di generare una risposta convincente. È arrivato il momento di assistere al culmine dei nostri sforzi e svelare l’esito. Andiamo ?
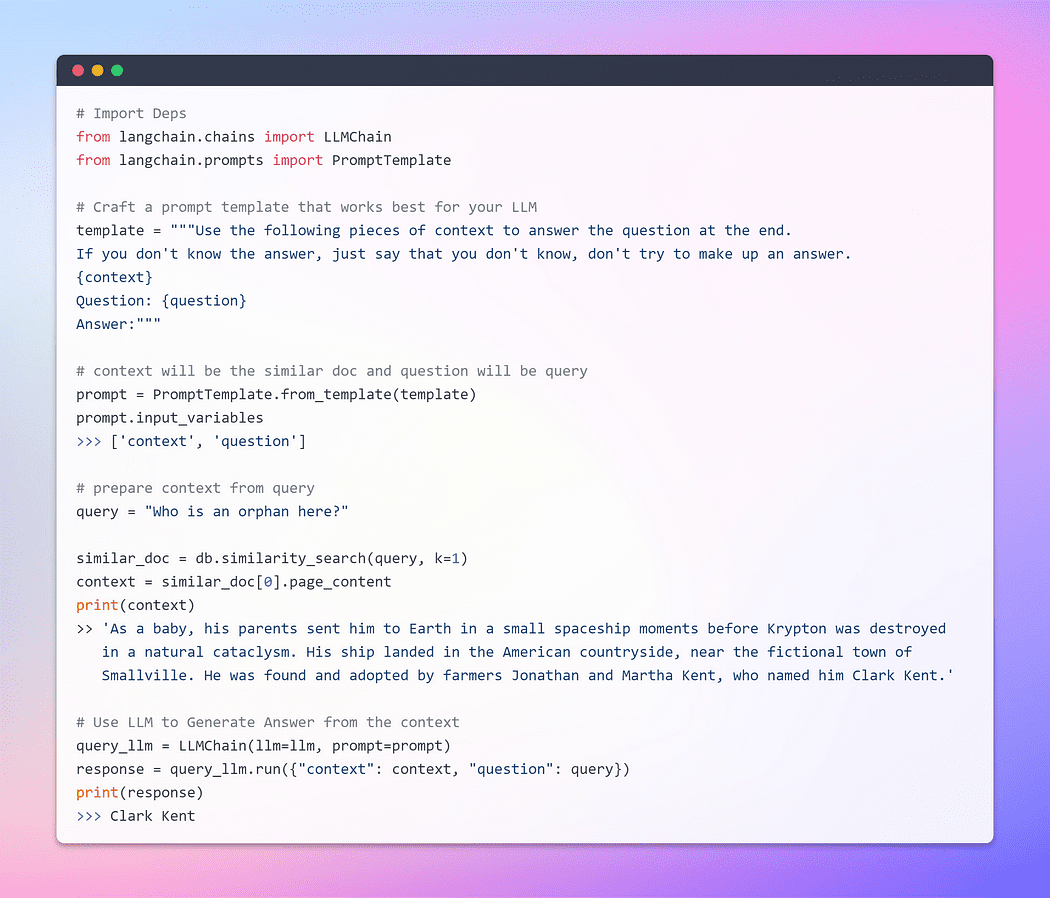 Immagine dell’autore: Domande e Risposte con il Documento
Immagine dell’autore: Domande e Risposte con il Documento
Questo è il momento che stavamo aspettando! Ce l’abbiamo fatta! Abbiamo appena costruito il nostro bot di risposta alle domande utilizzando LLM in esecuzione in locale.
Sezione 5: Collega tutto usando Streamlit
Questa sezione è del tutto opzionale, poiché non serve come guida esaustiva a Streamlit. Non approfondirò questo argomento; invece, presenterò un’applicazione di base che consente agli utenti di caricare qualsiasi documento di testo. Avranno quindi la possibilità di fare domande tramite input di testo. Sullo sfondo, la funzionalità rimarrà coerente con quanto abbiamo visto nella sezione precedente.
Tuttavia, c’è un’eccezione per quanto riguarda il caricamento dei file in Streamlit. Per evitare potenziali errori di memoria, considerando in particolare la natura intensiva di memoria degli LLM, leggerò semplicemente il documento e lo scriverò nella cartella temporanea all’interno della nostra struttura di file, chiamandolo raw.txt. In questo modo, indipendentemente dal nome originale del documento, Textloader lo elaborerà senza problemi in futuro.
Attualmente, l’app è progettata per i file di testo, ma è possibile adattarla anche per i file PDF, CSV o altri formati. Il concetto di base rimane lo stesso poiché gli LLM sono principalmente progettati per l’input e l’output di testo. Inoltre, è possibile sperimentare con diversi LLM supportati dalle librerie Llama C++.
Senza addentrarci ulteriormente nei dettagli intricati, presento il codice dell’app. Sentiti libero di personalizzarlo per adattarlo al tuo caso d’uso specifico.
Ecco come apparirà l’app di Streamlit.
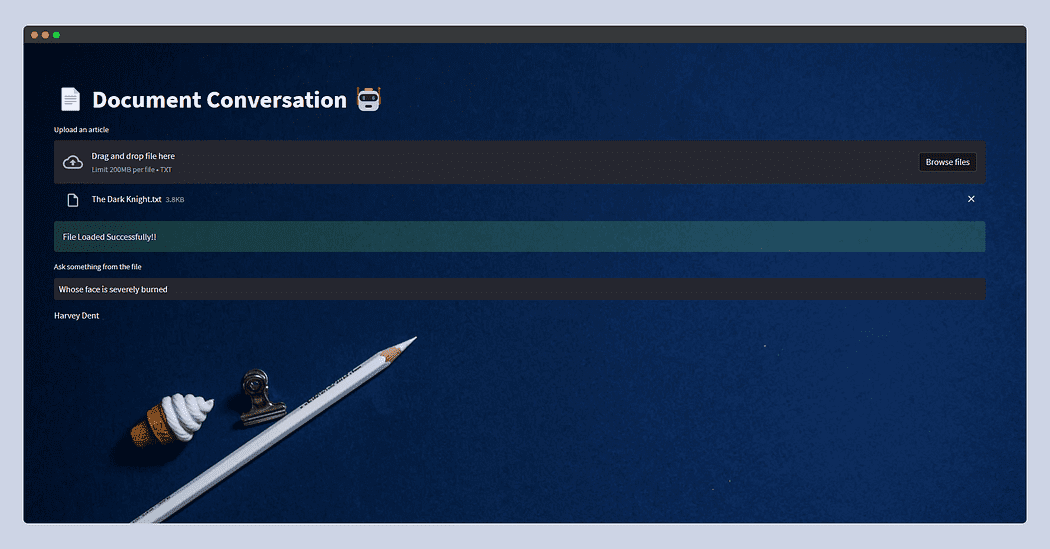
Questa volta ho alimentato il trama di The Dark Knight copiata da Wiki e ho semplicemente chiesto Di chi il volto è gravemente bruciato? e LLM ha risposto – Harvey Dent.
Bene, bene, bene! Con questo, si conclude questo blog.
Spero che tu abbia apprezzato questo articolo! e che lo abbia trovato informativo e coinvolgente. Puoi seguirmi, Afaque Umer, per altri articoli simili.
Cercherò di affrontare altri concetti di Machine Learning / Data Science e cercherò di spiegare termini e concetti che sembrano complessi in modo più semplice.
Afaque Umer è un appassionato Ingegnere di Machine Learning. Ama affrontare nuove sfide utilizzando le ultime tecnologie per trovare soluzioni efficienti. Spingiamo insieme i confini dell’IA!
Originale. Ripubblicato con permesso.