Congelare i livelli di un modello di Deep Learning – il modo corretto
Congelare i livelli di un modello di Deep Learning - corretto modo
Esempio di ottimizzatore ADAM in PyTorch
Introduzione
È spesso utile congelare alcuni dei parametri, ad esempio quando si sta ottimizzando il modello e si desidera congelare alcuni strati a seconda dell’esempio che si sta elaborando, come illustrato
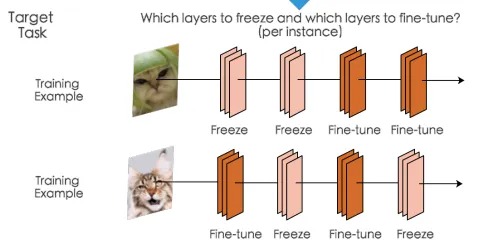
Come possiamo vedere per il primo esempio, congeliamo i primi due strati e aggiorniamo i parametri degli ultimi due, mentre per il secondo esempio congeliamo il secondo e il quarto strato e ottimizziamo gli altri. Ci saranno molti altri casi in cui questa tecnica è utile e se state leggendo questo articolo probabilmente avrete un caso per questo.
Impostazione del problema
Per semplificare un po’ le cose, supponiamo di avere un modello che accetta due tipi diversi di input: uno con 3 caratteristiche e un altro con 2 caratteristiche, e a seconda degli input che vengono passati vogliamo farli passare attraverso due diversi strati iniziali. Pertanto, vogliamo aggiornare solo i parametri relativi a quegli input particolari durante l’addestramento. Come possiamo vedere di seguito, vogliamo congelare lo strato hidden_task1 quando viene passato l’input1 e congelare lo strato hidden_task2 quando viene passato l’input2.
class Network(nn.Module): def __init__(self): super().__init__() # Trasformazione lineare degli input nascosti al layer self.hidden_task1 = nn.Linear(3, 3, bias=False) self.hidden_task2 = nn.Linear(2, 3, bias=False) self.output = nn.Linear(3, 4, bias=False) # Definizione dell'attivazione sigmoide e dell'output softmax self.sigmoid = nn.Sigmoid() self.softmax = nn.Softmax(dim=1) def forward(self, x, task='task1'): if task == 'task1': x = self.hidden_task1(x) else: x = self.hidden_task2(x) x = self.sigmoid(x) x = self.output(x) x = self.softmax(x) return x def freeze_params(self, params_str): for n, p in self.named_parameters(): if n in params_str: p.grad = None def freeze_params_grad(self, params_str): for n, p in self.named_parameters(): if n in params_str: p.requires_grad = False def unfreeze_params_grad(self, params_str): for n, p in self.named_parameters(): if n in params_str: p.requires_grad = True# Definire l'input e il target input1 = torch.randn(10, 3).to(device)input2 = torch.randn(10, 2).to(device)target1 = torch.randint(0, 4, (10, )).long().to(device) target2 = torch.randint(0, 4, (10, )).long().to(device) net = Network().to(device)# Funzione di supporto per i parametri modificati(initial, final): for n, p in initial.items(): if not torch.allclose(p, final[n]): print("Modificato : ", n)In un mondo con solo ottimizzatori SGD
Se lavorassimo solo con l’ottimizzatore SGD, il problema sarebbe risolto semplicemente utilizzando requires_grad = False che non calcolerebbe i gradienti per i parametri che specifichiamo e otterremmo così i risultati desiderati.
- ChatGPT è vecchia notizia ecco 8 strumenti di intelligenza artificiale che trasformeranno il tuo lavoro
- Come funzionano 8 modelli più piccoli in GPT4?
- Modello Segment Anything Modello di base per la segmentazione delle immagini
original_param = {n : p.clone() for (n, p) in net.named_parameters()}print("Parametri originali ")pprint(original_param)print(100 * "=")# Definiamo 2 funzioni di loss (potremmo definirne solo una in realtà # in questo caso poiché sono uguali) criterion1 = nn.CrossEntropyLoss()criterion2 = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.9)# Impostare requires_grad su False per gli strati selezionatinet.freeze_params_grad(['hidden_task2.weight'])print("Parametri dopo l'aggiornamento del task 1 ")params_hid1 = {n : p.clone() for (n, p) in net.named_parameters()}pprint(params_hid1)print(100 * "=")# Output per il task 1 - vogliamo mantenere i parametri dello strato task2 congelatoutput = net(input1, task='task1')optimizer.zero_grad() # azzerare i buffer del gradienteloss1 = criterion(output, target)loss1.backward()optimizer.step()print("Stati dell'ottimizzatore 1: ")print(optimizer.state)# Impostare requires_grad nuovamente su True per gli strati selezionatinet.unfreeze_params_grad(['hidden_task2.weight'])# Output per il task 2 - vogliamo mantenere i parametri dello strato task1 congelatoutput1 = net(input2, task='task2')optimizer.zero_grad() # azzerare i buffer del gradienteloss2 = criterion1(output1, target1)loss2.backward()optimizer.step() # Eseguire l'aggiornamentoprint("Stati dell'ottimizzatore 1: ")print(optimizer.state)# Impostare requires_grad nuovamente su True per gli strati selezionatinet.unfreeze_params_grad(['hidden_task1.weight'])print("Parametri dopo l'aggiornamento del task 2 ")params_hid2 = {n : p.clone() for (n, p) in net.named_parameters()}pprint(params_hid2)changed_parameters(params_hid1, params_hid2)Nelle uscite sottostanti possiamo vedere che i parametri “Changed” dopo gli aggiornamenti delle attività 1 e 2 sono corretti e abbiamo ottenuto il risultato desiderato.
{'hidden_task1.weight': tensor([[-0.0043, 0.3097, -0.4752], [-0.4249, -0.2224, 0.1548], [-0.0114, 0.4578, -0.0512]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0214, 0.2282, 0.3464], [-0.3914, -0.2514, 0.2097], [ 0.4794, -0.1188, 0.4320], [-0.0931, 0.0611, 0.5228]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Parametri dopo hidden {'hidden_task1.weight': tensor([[ 0.0010, 0.3107, -0.4746], [-0.4289, -0.2261, 0.1547], [-0.0105, 0.4596, -0.0528]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0554, 0.2788, 0.3800], [-0.4105, -0.2702, 0.1917], [ 0.4552, -0.1496, 0.4091], [-0.0838, 0.0601, 0.5301]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Changed : hidden_task1.weightChanged : output.weightParametri dopo hidden 1 {'hidden_task1.weight': tensor([[ 0.0010, 0.3107, -0.4746], [-0.4289, -0.2261, 0.1547], [-0.0105, 0.4596, -0.0528]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1906, -0.2102], [-0.1412, -0.6783], [-0.4657, -0.2929]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0386, 0.2673, 0.3726], [-0.3818, -0.2414, 0.2232], [ 0.4402, -0.1698, 0.3898], [-0.0807, 0.0631, 0.5254]], device='cuda:0', grad_fn=<CloneBackward0>)}Changed : hidden_task2.weightChanged : output.weightComplicazioni con gli ottimizzatori adattivi
Ora proviamo a eseguire lo stesso procedimento, ma utilizzando l’ottimizzatore Adam:
optimizer = optim.Adam(net.parameters(), lr=0.9)Nella parte “Changed” vediamo ora che dopo l’aggiornamento della seconda attività, anche hidden_task1.weight è stato modificato, il che non è quello che vogliamo.
Parametri originali {'hidden_task1.weight': tensor([[-0.0043, 0.3097, -0.4752], [-0.4249, -0.2224, 0.1548], [-0.0114, 0.4578, -0.0512]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0214, 0.2282, 0.3464], [-0.3914, -0.2514, 0.2097], [ 0.4794, -0.1188, 0.4320], [-0.0931, 0.0611, 0.5228]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Parametri dopo hidden {'hidden_task1.weight': tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.9212, 1.1262, 1.2433], [-1.2879, -1.1492, -0.6922], [-0.4249, -1.0177, -0.4718], [ 0.8078, -0.8394, 1.4181]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Changed : hidden_task1.weightChanged : output.weightParametri dopo hidden 1 {'hidden_task1.weight': tensor([[ 1.4907, 1.7991, 1.0283], [-1.9122, -1.7133, -1.3428], [ 1.4837, 1.9445, -1.5453]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[-0.7146, -1.1118], [-1.0377, 0.2305], [-1.3641, -1.1889]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.9372, 1.3922, 1.5032], [-1.5886, -1.4844, -0.9789], [-0.8855, -1.5812, -1.0326], [ 1.6785, -0.2048, 2.3004]], device='cuda:0', grad_fn=<CloneBackward0>)}Changed : hidden_task1.weightChanged : hidden_task2.weightChanged : output.weightCerchiamo di capire cosa sta succedendo qui. La regola di aggiornamento per SGD è definita come:
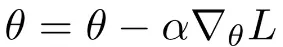
Dove alpha è il tasso di apprendimento, nabla L è il gradiente rispetto ai parametri. Come possiamo vedere, se il gradiente è zero i parametri non vengono aggiornati in quanto la regola di aggiornamento dipende solo dai gradienti. E quando impostiamo requires_grad = False i gradienti saranno zero per quei livelli e non verranno calcolati.
Cosa succede con gli ottimizzatori adattivi come ADAM o altri, in cui la regola di aggiornamento non dipende solo dai gradienti? Vediamo ADAM:
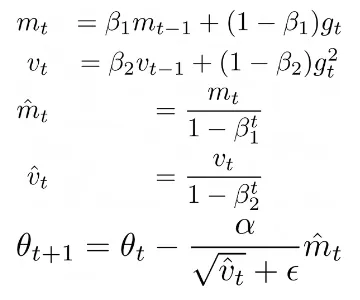
Dove Beta1, Beta2 sono alcuni iperparametri, alpha è il tasso di apprendimento, mt è il primo momento e vt è il secondo momento dei gradienti gt. Questa regola di aggiornamento consente di calcolare tassi di apprendimento adattivi per ciascun parametro. In particolare, anche se il gradiente corrente gt viene impostato a zero tramite requires_grad = False, i parametri vengono comunque aggiornati dall’ottimizzatore utilizzando i valori mt e vt memorizzati. Infatti, se stampiamo optimizer.state possiamo vedere che l’ottimizzatore memorizza il numero di passaggi (cioè il numero di aggiornamenti dei gradienti) che ogni parametro ha effettuato, exp_avg, che è il primo momento, e exp_avg_sq, il secondo momento:
# optimizer step 1defaultdict(<class 'dict'>, {Parameter containing:tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[-5.9304e-04, -1.0966e-04, -5.9985e-05], [ 4.4068e-04, 4.1636e-04, 1.7705e-05], [-1.0544e-04, -2.0357e-04, 1.7783e-04]], device='cuda:0'), 'exp_avg_sq': tensor([[3.5170e-08, 1.2025e-09, 3.5982e-10], [1.9420e-08, 1.7336e-08, 3.1345e-11], [1.1118e-09, 4.1440e-09, 3.1623e-09]], device='cuda:0')}, Parameter containing:tensor([[ 0.9212, 1.1262, 1.2433], [-1.2879, -1.1492, -0.6922], [-0.4249, -1.0177, -0.4718], [ 0.8078, -0.8394, 1.4181]], device='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[-0.0038, -0.0056, -0.0037], [ 0.0021, 0.0021, 0.0020], [ 0.0027, 0.0034, 0.0025], [-0.0010, 0.0001, -0.0008]], device='cuda:0'), 'exp_avg_sq': tensor([[1.4261e-06, 3.1517e-06, 1.3953e-06], [4.4782e-07, 4.3352e-07, 3.9994e-07], [7.2213e-07, 1.1702e-06, 6.4754e-07], [1.0547e-07, 1.2353e-09, 6.5470e-08]], device='cuda:0')}})# optimizer step 2tensor([[ 1.4907, 1.7991, 1.0283], [-1.9122, -1.7133, -1.3428], [ 1.4837, 1.9445, -1.5453]], device='cuda:0', requires_grad=True): {'step': tensor(2.), 'exp_avg': tensor([[-5.3374e-04, -9.8693e-05, -5.3987e-05], [ 3.9661e-04, 3.7472e-04, 1.5934e-05], [-9.4899e-05, -1.8321e-04, 1.6005e-04]], device='cuda:0'), 'exp_avg_sq': tensor([[3.5135e-08, 1.2013e-09, 3.5946e-10], [1.9400e-08, 1.7318e-08, 3.1314e-11], [1.1107e-09, 4.1398e-09, 3.1592e-09]], device='cuda:0')}, Parameter containing:tensor([[ 0.9372, 1.3922, 1.5032], [-1.5886, -1.4844, -0.9789], [-0.8855, -1.5812, -1.0326], [ 1.6785, -0.2048, 2.3004]], device='cuda:0', requires_grad=True): {'step': tensor(2.), 'exp_avg': tensor([[-0.0002, -0.0025, -0.0017], [ 0.0011, 0.0011, 0.0010], [ 0.0019, 0.0029, 0.0021], [-0.0028, -0.0015, -0.0014]], device='cuda:0'), 'exp_avg_sq': tensor([[2.4608e-06, 3.7819e-06, 1.6833e-06], [5.1839e-07, 4.8712e-07, 4.7173e-07], [7.4856e-07, 1.1713e-06, 6.4888e-07], [4.4950e-07, 2.6660e-07, 1.1588e-07]], device='cuda:0')}, Parameter containing:tensor([[-0.7146, -1.1118], [-1.0377, 0.2305], [-1.3641, -1.1889]], device='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[ 0.0009, 0.0011], [ 0.0045, -0.0002], [ 0.0003, 0.0012]], device='cuda:0'), 'exp_avg_sq': tensor([[8.7413e-08, 1.3188e-07], [1.9946e-06, 4.3840e-09], [8.1403e-09, 1.3691e-07]], device='cuda:0')}})Possiamo vedere che nel primo aggiornamento optimizer.step() otteniamo solo due parametri negli stati dell’ottimizzatore – hidden_task1 e output. Nel secondo passaggio dell’ottimizzatore, abbiamo tutti i parametri ma notiamo che hidden_task1 viene aggiornato due volte, il che non dovrebbe accadere.
Quindi come fare con loro? La soluzione è in realtà molto semplice – invece di utilizzare requires_grad semplicemente impostiamo grad = None per i parametri. Il codice diventa quindi:
original_param = {n : p.clone() for (n, p) in net.named_parameters()}print("Parametri originali ")pprint(original_param)print(100 * "=")# definiamo 2 funzioni di perdita (potremmo definirne solo una in realtà # in questo caso poiché sono uguali) criterion1 = nn.CrossEntropyLoss()criterion2 = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.9)print("Parametri dopo l'aggiornamento del task 1 ")params_hid1 = {n : p.clone() for (n, p) in net.named_parameters()}pprint(params_hid1)print(100 * "=")# output per il task 1 - vogliamo mantenere i parametri del livello frozen del task2output = net(input1, task='task1')optimizer.zero_grad() # azzeriamo i buffer del gradienteloss1 = criterion1(output, target1)loss1.backward()# Congeliamo i parametri qui!net.freeze_params(['hidden_task2.weight'])optimizer.step()# output per il task 2 - vogliamo mantenere i parametri del livello frozen del task1output = net(input2, task='task2')optimizer.zero_grad() # azzeriamo i buffer del gradienteloss2 = criterion2(output, target2)loss2.backward()# Congeliamo i parametri qui!net.freeze_params_grad(['hidden_task1.weight'])optimizer.step() # Esegui l'aggiornamentoprint("Parametri dopo l'aggiornamento del task 2 ")params_hid2 = {n : p.clone() for (n, p) in net.named_parameters()}pprint(params_hid2)changed_parameters(params_hid1, params_hid2)Notare che dobbiamo impostare
grad = Nonedopoloss.backward()poiché dobbiamo calcolare prima i gradienti per tutti i parametri, ma prima dioptimizer.step().
Se eseguiamo il codice ora con l’ottimizzatore ADAM, i risultati sono quelli attesi
Parametri originali {'hidden_task1.weight': tensor([[-0.0043, 0.3097, -0.4752], [-0.4249, -0.2224, 0.1548], [-0.0114, 0.4578, -0.0512]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.0214, 0.2282, 0.3464], [-0.3914, -0.2514, 0.2097], [ 0.4794, -0.1188, 0.4320], [-0.0931, 0.0611, 0.5228]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Parametri dopo l'aggiornamento del task 1 {'hidden_task1.weight': tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[ 0.1871, -0.2137], [-0.1390, -0.6755], [-0.4683, -0.2915]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.9212, 1.1262, 1.2433], [-1.2879, -1.1492, -0.6922], [-0.4249, -1.0177, -0.4718], [ 0.8078, -0.8394, 1.4181]], device='cuda:0', grad_fn=<CloneBackward0>)}====================================================================================================Cambiato : hidden_task1.weightCambiato : output.weightParametri dopo l'aggiornamento del task 2 {'hidden_task1.weight': tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', grad_fn=<CloneBackward0>), 'hidden_task2.weight': tensor([[-0.7146, -1.1118], [-1.0377, 0.2305], [-1.3641, -1.1889]], device='cuda:0', grad_fn=<CloneBackward0>), 'output.weight': tensor([[ 0.9372, 1.3922, 1.5032], [-1.5886, -1.4844, -0.9789], [-0.8855, -1.5812, -1.0326], [ 1.6785, -0.2048, 2.3004]], device='cuda:0', grad_fn=<CloneBackward0>)}Cambiato : hidden_task2.weightCambiato : output.weightAnche lo stato optimizer.state è ora diverso – nel secondo passaggio dell’ottimizzatore hidden_task1 non viene aggiornato e il suo valore step è 1.
tensor([[ 0.8957, 1.2069, 0.4291], [-1.3211, -1.1204, -0.7465], [ 0.8887, 1.3537, -0.9508]], device='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[-5.9304e-04, -1.0966e-04, -5.9985e-05], [ 4.4068e-04, 4.1636e-04, 1.7705e-05], [-1.0544e-04, -2.0357e-04, 1.7783e-04]], device='cuda:0'), 'exp_avg_sq': tensor([[3.5170e-08, 1.2025e-09, 3.5982e-10], [1.9420e-08, 1.7336e-08, 3.1345e-11], [1.1118e-09, 4.1440e-09, 3.1623e-09]], device='cuda:0')}, Parameter containing:tensor([[ 0.9372, 1.3922, 1.5032], [-1.5886, -1.4844, -0.9789], [-0.8855, -1.5812, -1.0326], [ 1.6785, -0.2048, 2.3004]], device='cuda:0', requires_grad=True): {'step': tensor(2.), 'exp_avg': tensor([[-0.0002, -0.0025, -0.0017], [ 0.0011, 0.0011, 0.0010], [ 0.0019, 0.0029, 0.0021], [-0.0028, -0.0015, -0.0014]], device='cuda:0'), 'exp_avg_sq': tensor([[2.4608e-06, 3.7819e-06, 1.6833e-06], [5.1839e-07, 4.8712e-07, 4.7173e-07], [7.4856e-07, 1.1713e-06, 6.4888e-07], [4.4950e-07, 2.6660e-07, 1.1588e-07]], device='cuda:0')}, Parameter containing:tensor([[-0.7146, -1.1118], [-1.0377, 0.2305], [-1.3641, -1.1889]], device='cuda:0', requires_grad=True): {'step': tensor(1.), 'exp_avg': tensor([[ 0.0009, 0.0011], [ 0.0045, -0.0002], [ 0.0003, 0.0012]], device='cuda:0'), 'exp_avg_sq': tensor([[8.7413e-08, 1.3188e-07], [1.9946e-06, 4.3840e-09], [8.1403e-09, 1.3691e-07]], device='cuda:0')}})Distributed Data Parallel
Come nota aggiuntiva, nel caso in cui desideriamo il supporto di DistributedDataParallel in PyTorch per lavorare con più GPU, è necessario modificare leggermente l’implementazione descritta sopra come segue:
È un po’ più complicato e se conosci un modo più pulito per scriverlo, condividilo nei commenti!
Feedback
Apprezzerei qualsiasi feedback riguardo a quanto sopra – se sai se potrebbero esserci eventuali problemi nel farlo in questo modo e se ci sono altri modi per ottenere lo stesso risultato.
Conclusioni
In questo articolo abbiamo descritto come congelare dei livelli durante l’addestramento quando è necessario congelare e scongelare alcuni livelli. Se ciò che desideri è congelare completamente alcuni dei livelli durante tutto l’addestramento, puoi utilizzare entrambe le soluzioni descritte in questo articolo, poiché non importa nel tuo caso se stai utilizzando SGD o un ottimizzatore adattivo. Tuttavia, come abbiamo visto, il problema si presenta quando è necessario congelare e scongelare i livelli durante l’addestramento e il diverso comportamento che osserviamo quando si utilizzano ottimizzatori il cui regola di aggiornamento dipende solo dal gradiente e quelli il cui regola di aggiornamento dipende da altre variabili come il momentum. Puoi trovare anche il codice completo qui.




