Oltre il VIF Analisi della collinearità per la mitigazione del bias e l’accuratezza predittiva
Collinearity analysis beyond VIF for bias mitigation and predictive accuracy
Nell’apprendimento automatico, la collinearità è un enigma complesso sia per i professionisti esperti che per i principianti. Gli algoritmi di apprendimento automatico (ML) sono ottimizzati per l’accuratezza predittiva e non per la spiegabilità dei predittori sul target. Inoltre, la maggior parte delle soluzioni per affrontare la collinearità, come il ‘Variance Inflation Score’ e l’analisi della cross-correlazione di Pearson, potrebbero portare a una massiccia perdita di informazioni nel pre-processing.
La maggior parte degli algoritmi di apprendimento automatico selezionerà la migliore combinazione possibile di caratteristiche per ottimizzare l’accuratezza predittiva. Pertanto, anche con la collinearità, a condizione che le correlazioni osservate durante l’addestramento rimangano vere nel mondo reale, la collinearità non è un problema nell’apprendimento automatico. Tuttavia, per la spiegabilità di un modello, gli effetti non controllati della collinearità sono una potenziale fonte di bias.
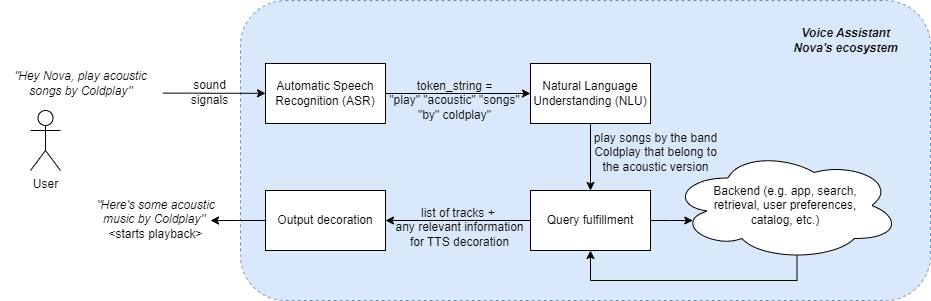
La collinearità, che si riferisce alla forte correlazione tra variabili indipendenti (IV) in un dataset, spesso presenta sfide uniche nell’interpretazione dei modelli di regressione. In particolare, interferisce nella determinazione delle vere ragioni delle relazioni nei dati, il che può portare a interpretazioni distorte e decisioni ingiuste. Ad esempio, nella figura 1, le variabili indipendenti (TAX), (B) e (RAD) sono IV collineari e anche buoni predittori della variabile dipendente (MEDV). Mentre gli algoritmi di apprendimento automatico selezioneranno la migliore combinazione di predittori, potrebbero non tener conto dell’effetto dell’aggiunta di un’altra variabile collineare (RM) a un modello con una qualsiasi di queste tre variabili.
Per incoraggiare gli apprendisti automatici a prendere sul serio l’analisi della collinearità come passaggio di pre-processing, deve esserci un modo per bilanciare il “costo inflazionistico di mantenere le variabili collineari” e il “costo predittivo di eliminarle”.
- Tendenze evolutive nell’ingegneria delle prompt per i grandi modelli linguistici (LLM) con pratiche di AI responsabile integrate
- Sono arrivati gli strumenti di codifica dell’IA come li useranno i team di Product Engineering
- Crea una soluzione di monitoraggio e reporting centralizzata per Amazon SageMaker utilizzando Amazon CloudWatch
Comprensione della Collinearità
Per dimostrare come la collinearità non controllata porti a un bias non intenzionale, utilizziamo l’esempio di “Come non raccogliere dati”: il Dataset delle Abitazioni di Boston. Questo dataset è stato successivamente smentito e ritirato dall’uso pubblico perché contiene una variabile “B” “non invertibile”. La relazione collineare tra le variabili indipendenti “B”, “RM” e “TAX” è un caso di studio perfetto su come le correlazioni spurie possano sopprimere le vere relazioni tra le IV. La trasformazione “non invertibile” su “B”, (una IV binaria che si presenta come IV continua) introduce un bias moderante che potrebbe non essere rilevato dagli algoritmi di apprendimento automatico.
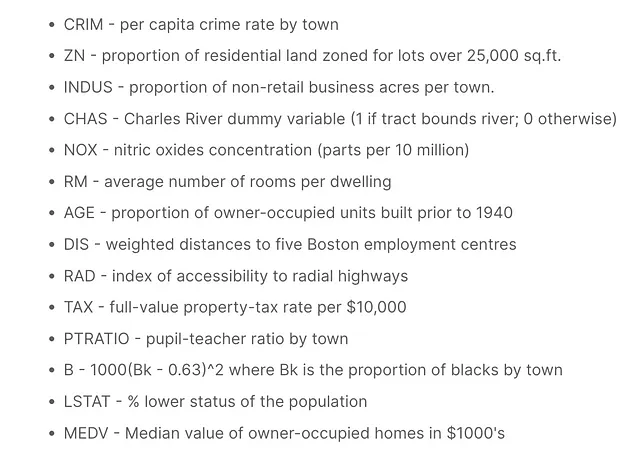
Considera le 13 variabili indipendenti (IV) nel dataset delle abitazioni di Boston, con il valore mediano delle case occupate dai proprietari (MEDV) in una città come variabile dipendente (DV). Alcune caratteristiche possono sembrare forti predittori dell’outcome, ma questa influenza risiede nel fatto che la loro varianza viene in gran parte spiegata da altri predittori.
In una relazione bivariata tra una variabile indipendente e una variabile dipendente, ci sono quattro possibilità quando viene introdotta una nuova variabile indipendente:
- Inflazione spuria: l’inclusione della terza IV incrementa significativamente l’influenza della prima IV sulla DV.
- Mascheramento o soppressione: la nuova IV nasconde o sopprime l’influenza della IV iniziale sulla variabile dipendente.
- Modera o altera: la nuova variabile cambia la direzione della relazione originale per tutte o alcune osservazioni della variabile indipendente.
- Nessun effetto: la terza IV non fornisce nuove informazioni e non ha effetto sulla IV e sulla DV.
Per i machine learner, le soluzioni preconfezionate alla collinearità spesso comportano una perdita di potenza predittiva, modelli sovradattati e bias. Pertanto, una soluzione che mitighi la perdita di informazioni è fondamentale.
Valutazione della collinearità
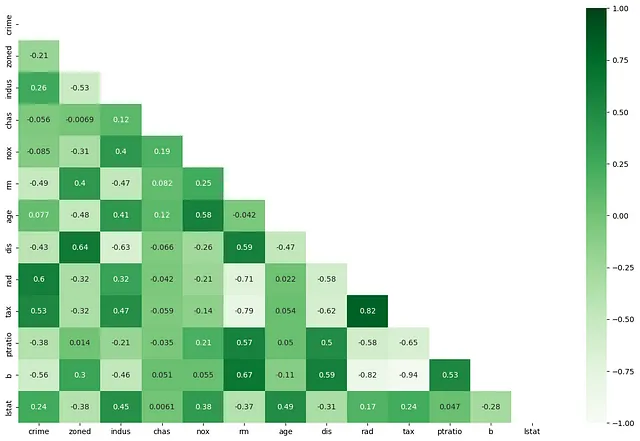
Se due o più variabili indipendenti sono altamente correlate (RAD e TAX), l’intuizione dietro la collinearità è che potenzialmente forniscono esattamente le stesse informazioni sull’influenza di un qualche concetto “latente” (grandi case suburbane/appartamenti in città) sulla variabile dipendente (valore immobile). In presenza di “Property Tax”, l’accessibilità alle autostrade radiali non fornisce nuove informazioni sul valore immobiliare (o viceversa). Quando le VI sono correlate in modo significativo in modo privo di significato, i coefficienti di un modello di regressione diventano grandi, il che a sua volta porta a inferenze sovrastimate sugli effetti di alcuni fattori su un risultato.
Attualmente ci sono due modi per affrontare la collinearità, nessuno dei quali tiene conto della variabile dipendente.
- Correlazione a coppie: Quante VI sono “fortemente” correlate tra loro. Un valore di soglia per il coefficiente di correlazione di caratteristiche “fortemente correlate” è soggettivo. Tuttavia, è consenso comune che la collinearità diventi un problema serio con un coefficiente di correlazione di +/- 0,7.
def dropMultiCorrelated(cormat, threshold): ##Definisci la soglia per rimuovere coppie di caratteristiche con #coefficiente di correlazione maggiore di 0,7 o -0,7 threshold = 0,7 # Seleziona la parte superiore della matrice di correlazione upper = cormat.abs().where(np.triu(np.ones(cormat.shape), k=1).astype(np.bool)) # Trova l'indice delle colonne delle caratteristiche con correlazione maggiore della soglia to_drop = [column for column in upper.columns if any(upper[column] > threshold)] for d in to_drop: print("Rimozione di {}....".format(d)) return to_drop2. Inflazione della varianza: Mentre il coefficiente di correlazione conferma un grado di cambiamento corrispondente tra due VI, ci dice poco sull’importanza della VI. Questo perché, le VI, in una relazione multivariata, non sono veramente indipendenti nel loro influsso sulla variabile dipendente (vedi Figura 1) e la vera significatività del loro influsso si manifesta nella presenza di una combinazione di altre VI.
Il punteggio di inflazione della varianza è la dimensione dell’influenza aggiunta ai coefficienti delle variabili indipendenti a causa della loro dipendenza da altre VI. Il VIF utilizza un approccio di “leave-one-out” sulle VI, trattando ogni “leave-out” come variabile dipendente e tutte le “leave-ins” come variabili indipendenti. Quindi tutte le VI diventano variabili dipendenti e ogni modello produce un valore (R2). Questo valore R2 indica la percentuale di varianza nella VI “leave-out” spiegata dalle VI “leave-in”. Il punteggio VIF viene stimato come:
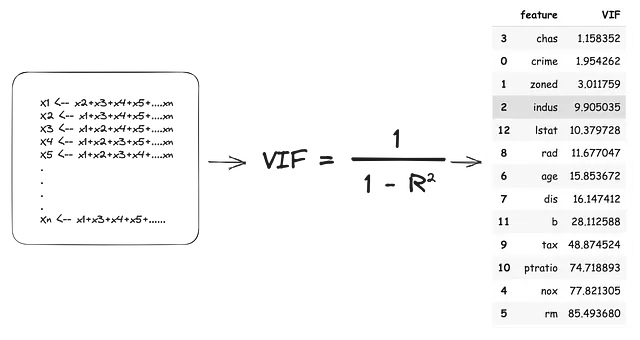
Sulla base delle stime VIF sopra, dovremmo eliminare 11 delle 13 VI per affrontare completamente la collinearità. Ciò comporterebbe non solo una perdita massiccia di informazioni, ma potrebbe potenzialmente generare modelli sovradattati che si comportano male nel mondo reale.
Nell’apprendimento automatico, i punteggi di correlazione multipla e VIF pairwise non dovrebbero essere l’unico criterio per scartare o mantenere le caratteristiche.
Alcune caratteristiche potrebbero comunque offrire un significativo valore predittivo o contribuire all’interpretazione del modello nonostante l’alta correlazione e i punteggi VIF.
Costi inflazionistici VS predittivi per la selezione delle caratteristiche collineari
Per mitigare la perdita di informazioni, possiamo confrontare due valori per misurare il costo inflazionistico del mantenimento delle caratteristiche collineari e il costo predittivo della loro eliminazione. Si noti che l’analisi VIF viene effettuata indipendentemente dalla variabile di risultato, quindi non tiene pienamente conto dell’influenza indipendente delle singole VI sulla variabile dipendente.
## Costruire modelli di regressione lineare multipla per valutare l'influenza indipendente sui risultati
fs = []
for feature in X_train.columns:
model = sm.OLS(Y_train, sm.add_constant(X_train[feature])).fit()
fs.append((feature, model.params[feature] / model.pvalues[feature]))
## Estrarre e memorizzare i valori
c1 = pd.DataFrame(coefs, columns=['Feature', 'VarianceEx']).sort_values("VarianceEx")
La prima misura è l’influenza indipendente di una variabile indipendente sulla variabile dipendente, cioè la quantità di varianza nella variabile dipendente, spiegata indipendentemente dalla variabile indipendente (R_squared). Per coerenza, stimeremo anche il punteggio VIF da questo valore di R_squared e lo chiameremo VIF(IY) – Importanza indipendente. La seconda misura è l’influenza della variabile indipendente sulla variabile dipendente in presenza di tutte le variabili indipendenti, ovvero il VIF stimato in precedenza. Chiamiamo questo VIF(IX) – Importanza collettiva.
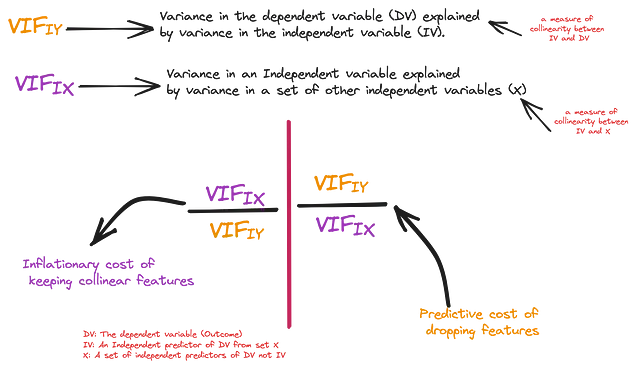
Ora possiamo stimare con fiducia la vera quantità di “sorpresa” che stai lasciando andare eliminando una caratteristica collineare. Nel grafico sottostante, l’asse X rappresenta la varianza in Y spiegata da ogni variabile indipendente (una misura di “utilità” potenziale per la previsione), mentre l’asse Y rappresenta la varianza nella variabile indipendente spiegata da altre variabili indipendenti (una misura di “bias” potenziale per il modello). La dimensione della bolla nel subplot 1 è il costo inflazionistico di mantenere queste variabili nel modello e nel subplot 2 è il costo predittivo di eliminarle.
Dato che si tratta di una fase di pre-processamento, utilizziamo “soglie” molto liberali per il fattore VIF(IX) di 20 (la linea rossa) e VIF(IY) di 1.15 (la linea blu). Le caratteristiche al di sotto della linea rossa sono quelle che sono spiegate meno dalle altre variabili indipendenti, mentre le caratteristiche dietro la linea blu non possono prevedere indipendentemente (Y).
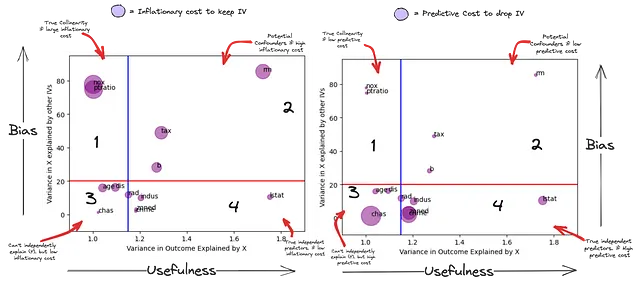
Questo grafico riassume il potere predittivo indipendente di una variabile indipendente rispetto al suo potenziale di bias.
- Quadrante 1 – Potenziali collineari veri: Queste caratteristiche (NOX, PTRATIO) sono spiegate da una combinazione lineare di altre variabili indipendenti nel modello e non possono prevedere indipendentemente la variabile dipendente (potrebbero dipendere da un altro insieme di variabili indipendenti per essere utili). Inoltre, qualsiasi potere predittivo che hanno potrebbe essere annullato da una combinazione lineare di altre variabili indipendenti (subplot 2). La loro influenza è significativamente soppressa dall’aggiunta di altre variabili indipendenti.
- Quadrante 2 – Potenziali fattori di bias: Queste sono correlate sia alla variabile dipendente che ad altre variabili indipendenti. Le caratteristiche (RM, TAX, B) sembrano essere predittive in modo indipendente di (Y), ma la loro varianza è spiegata anche da una combinazione di altre variabili indipendenti. Il loro cosiddetto potere predittivo indipendente su (Y) non può essere considerato isolatamente da altre (IVs). Possono essere predittori estremamente potenti del risultato o diventare una fonte di bias nell’interpretazione della loro importanza per il risultato.
- Quadrante 3 – Dipendenti: Anche se non sono predittivi in modo indipendente di (Y), c’è un costo predittivo elevato nell’eliminare alcuni di essi. Questo perché hanno informazioni uniche che non sono spiegate da altre variabili indipendenti. L’utilità di queste informazioni “uniche” per la previsione di (Y) può essere considerata solo in combinazione con altre variabili indipendenti.
- Quadrante 4 – Veri predittori indipendenti: Queste variabili sono predittive indipendentemente di (Y). Queste variabili hanno anche informazioni uniche che non sono spiegate da altre variabili indipendenti (più rispetto al Quadrante 3). L’utilità di queste informazioni “uniche” per la previsione di (Y) è indipendente dalle altre variabili indipendenti. Tuttavia, una combinazione lineare di altre variabili indipendenti potrebbe avere un potere predittivo maggiore rispetto alla loro previsione indipendente.
O = Y_train# Per stimare l'effetto dell'aggiunta/rimozione di una caratteristica C sulla relazione tra una caratteristica indipendente I e un risultato O
conf = []
for I in X_train.columns:
# costruire un modello di base per l'effetto di I su O
model = sm.OLS(O, sm.add_constant(X_train[I])).fit()
IO_coef, IO_sig = model.params[I], model.pvalues[I]
## Accedere all'effetto di
for C in X_train.columns:
if C != I:
# costruire un modello ausiliario aggiungendo C alla relazione tra I e O
model2 = sm.OLS(O, sm.add_constant(X_train[[I, C]])).fit()
ico_preds = model2.predict()
ICO_coef, ICO_sig = model2.params[I], model2.pvalues[I]
# costruire un modello di base per l'effetto di C su O
model3 = sm.OLS(O, sm.add_constant(X_train[C])).fit()
CO_coef, CO_sig = model3.params[C], model3.pvalues[C]
corr_IC, _ = pearsonr(X_train[I], X_train[C]) # CORR L'indipendente rispetto al controllo
corr_IO, _ = pearsonr(X_train[I], O) #CORR L'indipendente rispetto al risultato
corr_CO, _ = pearsonr(X_train[C], O) #CORR Il controllo rispetto al risultato
conf.append({"I_C":f"{I}_{C}",
"IO_coef":IO_coef, "IO_sig":IO_sig,
"CO_coef":CO_coef, "CO_sig":CO_sig,
"ICO_sig":ICO_sig, "ICO_coef": ICO_coef,
"corr_IC":corr_IC,
"corr_IO":corr_IO,
"corr_CO":corr_CO})
cc = pd.DataFrame(conf)
corr_ic = (cc['corr_IC'] > 0.5) | (cc['corr_IC'] 0.5) | (cc['corr_CO'] 0.5) | (cc['corr_IO'] < -0.5) # C è correlato con O
## C e O sono correlati in modo significativo
co_sig = (cc['CO_sig'] < 0.01) # C è predittivo in modo indipendente di O
io_sig = (cc['IO_sig'] < 0.01)
cc[corr_ic & corr_io & corr_co & co_sig & io_sig]
Le variabili B, TAX e RM predicono significativamente l’una l’altra e predicono anche indipendentemente l’outcome. Questo potrebbe essere la combinazione lineare di IVs che predice al meglio il DV (MEDV). In alternativa, la rilevanza predittiva di due di queste IV potrebbe essere inflazionata o soppressa a causa della presenza della terza IV. Per investigare questo, ogni variabile dovrebbe essere rimossa sequenzialmente da un modello di base che comprende tutte le variabili indipendenti.
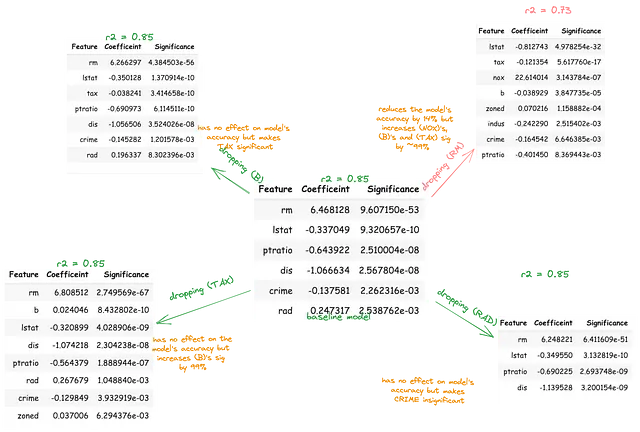
In seguito, il corrispondente cambiamento nella significatività delle variabili rimanenti sull’outcome dovrebbe essere quantificato in percentuale. Questa procedura aiuterà a evidenziare le IV spiegate da altre IV, che fingono di essere importanti.
Sopra la linea rossa, rimozione del bias collineare
Ci sono tre effetti principali (di interesse) che le variabili collineari sopra la linea rossa possono avere sulla relazione tra altre IV e la variabile dipendente. Possono agire come mediatore (sopprimere), confonditore (esagerare) o moderatore (modificare).
I concetti di moderatori, mediatori e confonditori non sono realmente discussi nell’apprendimento automatico. Questi concetti sono spesso lasciati agli “scienziati sociali”, dopotutto, sono loro che devono “interpretare” i loro coefficienti. Tuttavia, questi concetti spiegano come la collinearità possa introdurre un bias nei modelli di apprendimento automatico.
Si noti che questi effetti non possono essere stabiliti veramente senza un’analisi causale più approfondita, ma per una fase di pre-elaborazione di rimozione del bias, possiamo utilizzare definizioni semplici di questi concetti per filtrare queste relazioni.
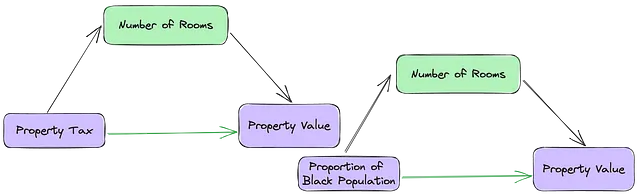
Un mediatore spiega “come” le IV e il DV sono correlati, cioè il processo attraverso il quale sono correlati. Un mediatore deve soddisfare tre criteri:
a) Essere significativamente predittivo della prima IV, b) essere significativamente predittivo del DV e c) essere significativamente predittivo del DV in presenza della prima IV.
Agisce come “mediatore” perché la sua inclusione non cambia la direzione della relazione tra la prima IV e il DV. Se un mediatore viene rimosso da un modello, la forza della relazione tra la prima IV e il DV dovrebbe diventare più forte perché il mediatore stava veramente considerando parte di quell’effetto.
## finding mediatorscc = pd.DataFrame(conf)co_sig = (cc['CO_sig'] < 0.01) # La C è predittiva in modo indipendente di Yio_sig = (cc['IO_sig'] < 0.01) # La I è predittiva in modo indipendente di Yicoi_sig = (cc['ICO_I_sig'] < 0.01) # La I e la C sono predittive di Yicoc_sig = (cc['ICO_C_sig'] < 0.05) # La C è predittiva in modo indipendente di Y in presenza di Iicoci_sig = (cc['IO_sig'] > cc['ICO_I_sig']) # La relazione diretta tra I e O dovrebbe essere più forte senza CAd esempio, nella relazione tra (RM), (TAX) e (MEDV), il numero di stanze potenzialmente spiega come l’imposta sulla proprietà è correlata al suo valore immobiliare.
I confonditori sono sfuggenti in quanto è difficile definirli in termini di correlazioni e significatività. Una variabile confondente è una variabile esterna che è correlata sia alla variabile dipendente che alle variabili indipendenti, potenzialmente distorcendo la relazione percepita tra di esse. A differenza dei mediatori, la relazione tra la prima IV e il DV non ha significato. Non c’è nemmeno garanzia che rimuovendo il confonditore la relazione tra la prima IV e il DV si indebolisca o si rafforzi.
Il numero di stanze in una casa può mediare o confondere la relazione tra la proporzione di popolazione nera e il valore immobiliare. Beh, secondo questo articolo, dipende dalla relazione tra (B) e (RM). Se la relazione tra (RM <-> MEDV) e (RM <-> B) è nella stessa direzione, rimuovere (RM) dovrebbe indebolire l’effetto di (B) su (MEDV). Tuttavia, se la relazione tra (RM <-> MEDV) e (RM <-> B) è nella direzione opposta, rimuovere (RM) dovrebbe rafforzare (B).
(RM <—> MEDV) e (RM <-> B) sono nella stessa direzione (sottoplot 3 della figura 1), tuttavia, rimuovendo (RM) rafforza l’effetto di (B).
Ma guarda la figura qui sotto, dove c’è un buon confine decisionale per un terzo IV nella relazione tra il primo IV e DV. Questo indica un tipo di relazione diverso tra (RM) e (TAX) basato sul valore di (B).
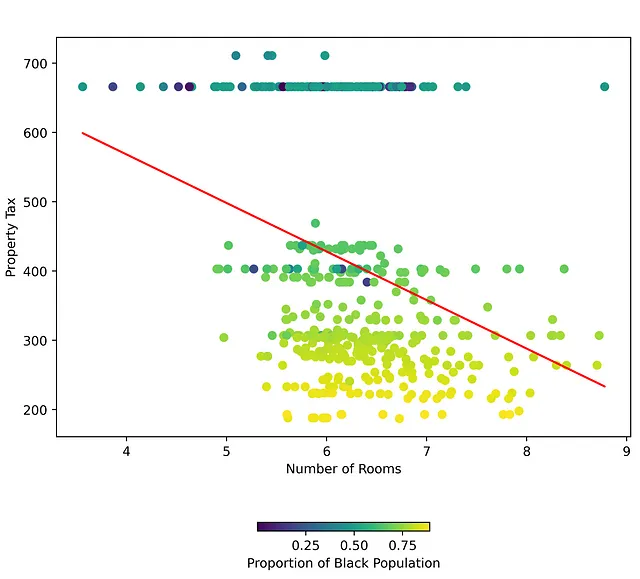
Con moderatori, la relazione tra il primo IV e la variabile dipendente è diversa in base al valore del moderatore. Quale tassa di proprietà puoi aspettarti di pagare per una casa che costa $100,00? Beh, dipende dalla proporzione di popolazione nera nella città e dal numero di stanze in quella casa. Infatti, ci sono una serie di città le cui tasse di proprietà rimangono costanti, indipendentemente dal numero di stanze, a condizione che (B) rimanga al di sotto di una certa soglia.
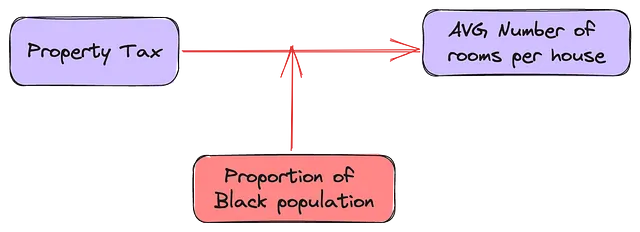
I moderatori sono di solito caratteristiche categoriche o gruppi nei dati. Le tradizionali fasi di pre-elaborazione per i gruppi creano variabili dummy per ogni etichetta di gruppo. Questo potenzialmente affronta qualsiasi effetto moderatore di quel gruppo sulla variabile dipendente. Tuttavia, le variabili classificate o le variabili continue con bassa varianza (B) possono anche essere moderatori.
Conclusioni
In conclusione, sebbene la collinearità sia un problema complesso nella modellazione di regressione, la sua valutazione e gestione attenta possono migliorare la potenza predittiva e l’affidabilità dei modelli di apprendimento automatico. La capacità di tenere conto della perdita di informazione fornisce un quadro efficace per la selezione delle caratteristiche, consentendo di bilanciare la spiegabilità e l’accuratezza predittiva.