HashGNN Approfondimento sull’algoritmo di embedding dei nodi di Neo4j GDS
HashGNN Approfondimento su Neo4j GDS per l'embedding dei nodi
In questo articolo, esploreremo insieme a un piccolo esempio come HashGNN hashi i nodi del grafo in uno spazio di embedding.
Se preferisci guardare un video su questo argomento, puoi farlo qui.
HashGG (#GNN) è una tecnica di embedding dei nodi, che utilizza concetti delle reti neurali a passaggio di messaggi (MPNN) per catturare la prossimità di ordine superiore e le proprietà dei nodi. Ciò velocizza significativamente i calcoli rispetto alle reti neurali tradizionali utilizzando una tecnica di approssimazione chiamata MinHashing. Pertanto, si tratta di un approccio basato sull’hashing e introduce un compromesso tra efficienza e precisione. In questo articolo, capiremo cosa significa tutto ciò ed esploreremo un piccolo esempio su come funziona l’algoritmo.
Node Embeddings: I nodi con contesti simili dovrebbero essere vicini nello spazio di embedding
Molti casi d’uso di apprendimento automatico su grafi come la predizione dei collegamenti e la classificazione dei nodi richiedono il calcolo delle similarità dei nodi. In un contesto di grafo, queste similarità sono più espressive quando catturano (i) il vicinato (cioè la struttura del grafo) e (ii) le proprietà del nodo da incorporare. Gli algoritmi di embedding dei nodi proiettano i nodi in uno spazio di embedding di bassa dimensionalità, ovvero assegnano a ciascun nodo un vettore numerico. Questi vettori, gli embedding, possono essere utilizzati per ulteriori analisi predittive numeriche (ad esempio, algoritmi di apprendimento automatico). Gli algoritmi di embedding ottimizzano la metrica: i nodi con un contesto di grafo (vicinato) e/o proprietà simili dovrebbero essere mappati vicini nello spazio di embedding. Gli algoritmi di embedding dei grafi di solito utilizzano due passaggi fondamentali: (i) Definire un meccanismo per campionare il contesto dei nodi (Random walk in node2vec, matrice di transizione a k-fold in FastRP), e (ii) successivamente ridurre la dimensionalità preservando le distanze a coppie (SGD in node2vec, proiezioni casuali in FastRP).
HashGNN: Evitare l’addestramento di una rete neurale
La chiave di HashGNN è che non richiede di addestrare una rete neurale basata su una funzione di perdita, come dovremmo fare in una tradizionale rete neurale a passaggio di messaggi. Poiché gli algoritmi di embedding dei nodi ottimizzano il concetto di “nodi simili dovrebbero essere vicini nello spazio di embedding”, la valutazione della perdita coinvolge il calcolo della vera similarità di una coppia di nodi. Questo viene quindi utilizzato come feedback per l’addestramento, per valutare l’accuratezza delle previsioni e per regolare i pesi di conseguenza. Spesso, la similarità del coseno viene utilizzata come misura di similarità.
- Oltre il VIF Analisi della collinearità per la mitigazione del bias e l’accuratezza predittiva
- Tendenze evolutive nell’ingegneria delle prompt per i grandi modelli linguistici (LLM) con pratiche di AI responsabile integrate
- Sono arrivati gli strumenti di codifica dell’IA come li useranno i team di Product Engineering
HashGNN elude l’addestramento del modello e in realtà non utilizza affatto una rete neurale. Invece di addestrare matrici di pesi e definire una funzione di perdita, utilizza uno schema di hashing casuale, che hashi i vettori dei nodi alla stessa firma con la probabilità della loro similarità, il che significa che possiamo incorporare i nodi senza la necessità di confrontare direttamente i nodi tra loro (cioè non è necessario calcolare una similarità del coseno). Questa tecnica di hashing è conosciuta come MinHashing ed è stata originariamente definita per approssimare la similarità di due insiemi senza confrontarli direttamente. Poiché gli insiemi vengono codificati come vettori binari, HashGNN richiede una rappresentazione binaria dei nodi. Per comprendere come ciò possa essere utilizzato per incorporare nodi di un grafo generale, sono necessarie diverse tecniche. Diamo un’occhiata.
MinHashing
Per cominciare, parliamo di MinHashing. MinHashing è una tecnica di hashing sensibile alla località per approssimare la similarità di Jaccard di due insiemi. La similarità di Jaccard misura l’intersezione di due insiemi dividendo la dimensione dell’intersezione per il numero di elementi unici presenti (unione) nei due insiemi. È definita sugli insiemi, che vengono codificati come vettori binari: ogni elemento nell’universo (l’insieme di tutti gli elementi) viene assegnato un indice di riga univoco. Se un particolare insieme contiene un elemento, ciò viene rappresentato come valore 1 nella riga corrispondente del vettore dell’insieme. L’algoritmo MinHashing hashi in modo indipendente il vettore binario di ciascun insieme e utilizza K funzioni di hash per generare una firma K-dimensionale per esso. La spiegazione intuitiva di MinHashing è quella di selezionare casualmente un elemento diverso da zero K volte, scegliendo quello con il valore hash più piccolo. Questo restituirà il vettore firma per l’insieme di input. La parte interessante è che se facciamo questo per due insiemi senza confrontarli, essi hashano alla stessa firma con la probabilità della loro similarità di Jaccard (se K è sufficientemente grande). In altre parole: la probabilità converge alla similarità di Jaccard.
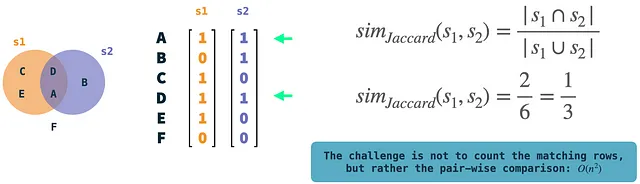
Nell’illustrazione: gli insiemi di esempio s1 e s2 sono rappresentati come vettori binari. Possiamo facilmente calcolare la similarità di Jaccard confrontando i due e contando le righe in cui entrambi i vettori hanno un 1. Queste sono operazioni piuttosto semplici, ma la complessità risiede nel confronto a coppie di vettori se ne abbiamo molti.
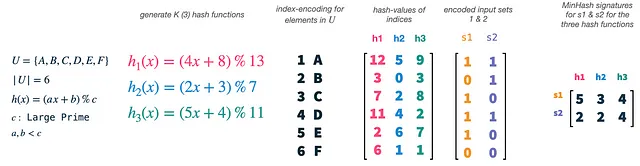
Il nostro universo U ha dimensione 6 e scegliamo K (il numero di funzioni di hash) pari a 3. Possiamo facilmente generare nuove funzioni di hash utilizzando una semplice formula e limiti per a, b e c. Quello che facciamo effettivamente è di eseguire l’hash degli indici dei nostri vettori (1-6), ognuno dei quali si riferisce a un singolo elemento nel nostro universo, con ciascuna delle nostre funzioni di hash. Questo ci darà 3 permutazioni casuali degli indici e quindi degli elementi nel nostro universo. Successivamente, possiamo prendere i nostri vettori di insieme s1 e s2 e usarli come maschere sulle nostre caratteristiche permutate. Per ogni permutazione e vettore di insieme, selezioniamo l’indice del valore di hash più piccolo, che è presente nell’insieme. Questo ci darà due vettori tridimensionali, uno per ogni insieme, chiamati firma di MinHash dell’insieme.
MinHashing seleziona semplicemente caratteristiche casuali dagli insiemi di input e abbiamo bisogno delle funzioni di hash solo come mezzo per riprodurre questa casualità in modo equo su tutti gli insiemi di input. Dobbiamo utilizzare lo stesso set di funzioni di hash su tutti i vettori, in modo che i valori di firma di due insiemi di input collidano se entrambi hanno l’elemento selezionato presente. I valori di firma collidono con la probabilità delle similarità di Jaccard degli insiemi.
WLKNN (Weisfeiler-Lehman Kernel Neural Network)
HashGNN utilizza uno schema di passaggio dei messaggi come definito nelle reti neurali del kernel Weisfeiler-Lehman (WLKNN) per catturare la struttura del grafo di ordine elevato e le proprietà dei nodi. Definisce la strategia di campionamento del contesto come menzionato in precedenza per HashGNN. Il WLK viene eseguito in T iterazioni. In ogni iterazione, genera un nuovo vettore di nodo per ogni nodo combinando il vettore corrente del nodo con i vettori di tutti i vicini direttamente connessi. Pertanto, si considera come passaggio di messaggi (vettori di nodo) lungo gli archi ai nodi vicini.
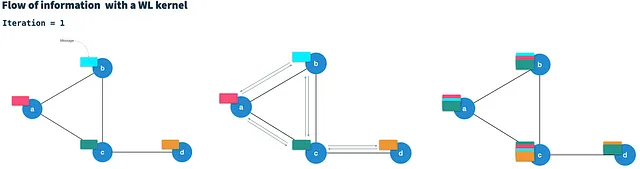
Dopo T iterazioni, ogni nodo contiene informazioni sui nodi a distanza di T hop (di ordine elevato). Il calcolo del nuovo vettore di nodo nell’iterazione t aggrega essenzialmente tutti i messaggi dei vicini (dall’iterazione t-1) in un singolo messaggio del vicino e quindi lo combina con il vettore di nodo dell’iterazione precedente. Inoltre, il WLKNN utilizza tre reti neurali (matrici di pesi e funzione di attivazione); (i) per il vettore di vicini aggregato, (ii) per il vettore di nodo e (iii) per la combinazione dei due. È una caratteristica notevole del WLK che il calcolo nell’iterazione t dipende solo dal risultato dell’iterazione t-1. Pertanto, può essere considerato una catena di Markov.
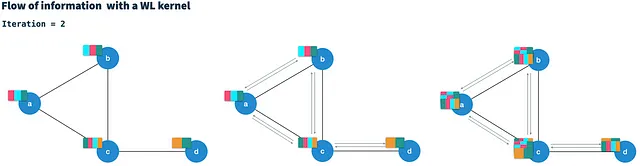
HashGNN ad esempio
Esploriamo come HashGNN combina i due approcci per incorporare in modo efficiente i vettori dei grafi in vettori di incorporamento. Come WLKNN, l’algoritmo HashGNN viene eseguito in T iterazioni, calcolando un nuovo vettore di nodi per ogni nodo mediante l’aggregazione dei vettori dei vicini e il proprio vettore di nodi dalla precedente iterazione. Tuttavia, invece di allenare tre matrici di peso, utilizza tre schemi di hash per l’hashing sensibile alla località. Ciascuno degli schemi di hash è composto da K funzioni di hash costruite casualmente per estrarre K elementi casuali da un vettore binario.
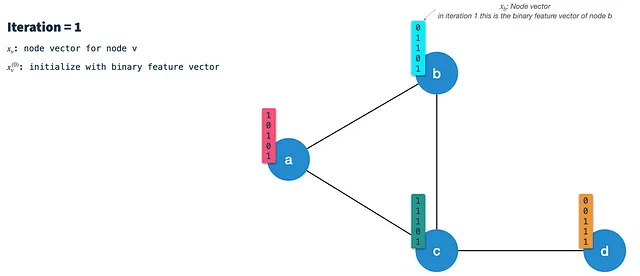
In ogni iterazione eseguiamo i seguenti passaggi:
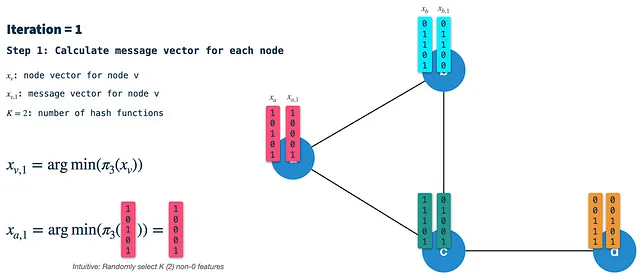
Passaggio 1: Calcola il vettore di firma del nodo: Min-hash (seleziona casualmente K elementi) il vettore del nodo dalla precedente iterazione utilizzando lo schema di hash 3. Nella prima iterazione i nodi sono inizializzati con i loro vettori di caratteristiche binarie (parleremo di come binarizzare i nodi in seguito). Il vettore di firma (o messaggio) risultante è quello che viene trasmesso lungo gli archi a tutti i vicini. Pertanto, dobbiamo farlo per tutti i nodi prima in ogni iterazione.
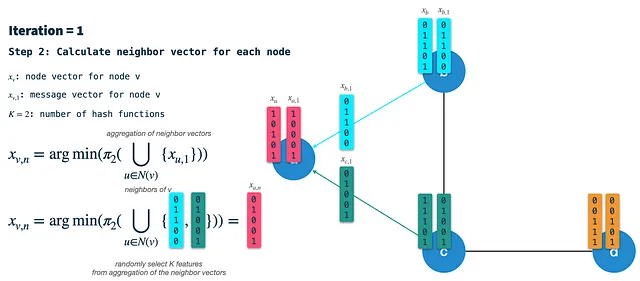
Passaggio 2: Costruisci il vettore dei vicini: In ogni nodo, riceviamo i vettori di firma da tutti i vicini direttamente connessi e li aggregiamo in un singolo vettore binario. Successivamente, utilizziamo lo schema di hash 2 per selezionare casualmente K elementi dal vettore dei vicini aggregati e chiamiamo il risultato il vettore dei vicini.
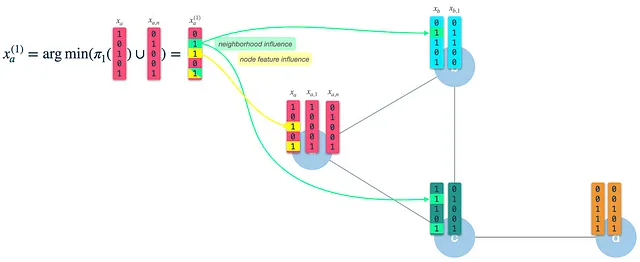
Passaggio 3: Combina il vettore del nodo e il vettore dei vicini in un nuovo vettore di nodo: Infine, utilizziamo lo schema di hash 1 per selezionare casualmente K elementi dal vettore del nodo della precedente iterazione e combiniamo il risultato con il vettore dei vicini. Il vettore risultante è il nuovo vettore di nodo che rappresenta il punto di partenza per la prossima iterazione. Nota che questo non è lo stesso del passaggio 1: Lì, applichiamo lo schema di hash 3 al vettore del nodo per costruire il vettore del messaggio/firma.
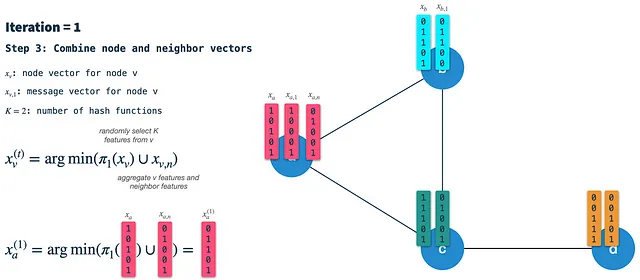
Come possiamo vedere, il vettore di nodo risultante (nuovo) ha l’influenza delle sue caratteristiche del nodo stesso (3 e 5), così come delle caratteristiche dei suoi vicini (2 e 5). Dopo l’iterazione 1, il vettore del nodo catturerà le informazioni dai vicini a distanza 1 hop. Tuttavia, poiché lo usiamo come input per l’iterazione 2, sarà già influenzato dalle caratteristiche a 2 hop di distanza.
Generalizzazioni di Neo4j GDS
HashGNN è stato implementato da Neo4j GDS (Graph Data Science Library) e aggiunge alcune generalizzazioni utili all’algoritmo.
Un importante passaggio ausiliario in GDS è la binarizzazione delle caratteristiche. MinHashing e quindi HashGNN richiedono vettori binari come input. Neo4j offre un passaggio di preparazione aggiuntivo per trasformare i vettori di nodi con valori reali in vettori di caratteristiche binarie. Utilizzano una tecnica chiamata arrotondamento dell’iperpiano. L’algoritmo funziona nel seguente modo:
Passaggio 1: Definire le caratteristiche dei nodi: Definire le proprietà dei nodi (con valori reali) da utilizzare come caratteristiche dei nodi. Questo viene fatto utilizzando il parametro featureProperties. Chiameremo questo vettore di input del nodo f.
Passaggio 2: Costruire classificatori binari casuali: Definire un iperpiano per ogni dimensione target. Il numero di dimensioni risultanti è controllato dal parametro dimensions. Un iperpiano è un piano ad alta dimensionalità e, finché risiede nell’origine, può essere descritto unicamente dal suo vettore normale n. Il vettore n è ortogonale alla superficie del piano e quindi ne descrive l’orientamento. Nel nostro caso, il vettore n deve avere la stessa dimensionalità dei vettori di input del nodo (dim(f) = dim(n)). Per costruire un iperpiano, basta estrarre dim(f) volte da una distribuzione gaussiana.
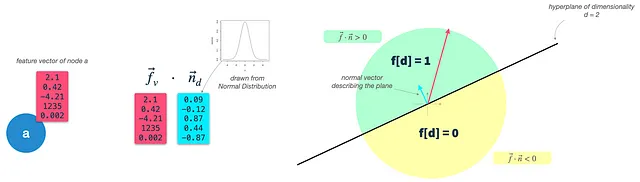
Passaggio 3: Classificare i vettori dei nodi: Calcolare il prodotto scalare del vettore di input del nodo e di ciascun vettore dell’iperpiano, che restituisce l’angolo tra l’iperpiano e il vettore di input. Utilizzando un parametro threshold, possiamo decidere se il vettore di input è sopra (1) o sotto (0) l’iperpiano e assegnare il valore corrispondente al vettore di caratteristiche binarie risultante. Questo è esattamente ciò che accade anche in una classificazione binaria, con l’unica differenza che non ottimizziamo iterativamente il nostro iperpiano, ma utilizziamo invece classificatori gaussiani casuali.
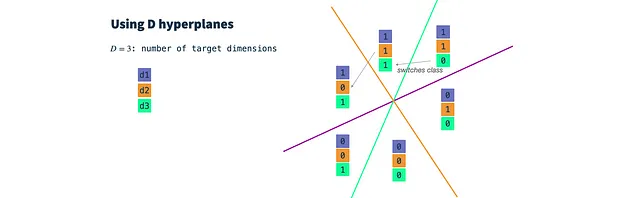
In sostanza, estraiamo un classificatore gaussiano casuale per ciascuna dimensione target e impostiamo un parametro di soglia. Quindi, classifichiamo i nostri vettori di input per ciascuna dimensione target e otteniamo un vettore binario di d dimensioni che utilizziamo come input per HashGNN.
Conclusioni
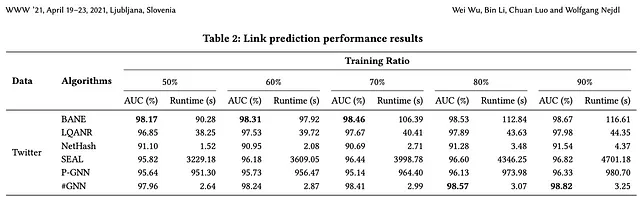
HashGNN utilizza l’hashing sensibile alla località per incorporare i vettori dei nodi in uno spazio di incorporamento. Utilizzando questa tecnica, evita l’addestramento iterativo computazionalmente intensivo di una rete neurale (o di altre ottimizzazioni), così come i confronti diretti tra nodi. Gli autori dell’articolo riportano un tempo di esecuzione 2-4 ordini di grandezza più veloce rispetto agli algoritmi basati sull’apprendimento come SEAL e P-GNN, pur producendo una precisione altamente comparabile (in alcuni casi anche migliore).
HashGNN è implementato nella libreria di Neo4j GDS (Graph Data Science) e può quindi essere utilizzato direttamente sul tuo grafo Neo4j. Nel prossimo post, approfondirò i dettagli pratici su come usarlo e cosa tenere a mente.
Grazie per essere passato e ci vediamo alla prossima. 🚀
Riferimenti
- Articolo originale: Graph Neural Networks accelerati da Hashing per la previsione dei collegamenti
- Documentazione di Neo4j GDS: HashGNN