ChatGPT con occhi e orecchie BuboGPT è un approccio di intelligenza artificiale che consente di stabilire un collegamento visivo in modelli di linguaggio multi-modalità (LLMs).
ChatGPT con occhi e orecchie BuboGPT è un approccio di intelligenza artificiale per collegare visivamente i modelli di linguaggio multi-modalità (LLMs).


I modelli di linguaggio di grandi dimensioni (LLM) sono emersi come cambiatori di gioco nel campo dell’elaborazione del linguaggio naturale. Stanno diventando una parte fondamentale della nostra vita quotidiana. L’esempio più famoso di un LLM è ChatGPT, ed è sicuro presumere che quasi tutti ne siano a conoscenza a questo punto, e la maggior parte di noi lo utilizza quotidianamente.
I LLM sono caratterizzati dalle loro enormi dimensioni e dalla capacità di apprendere da grandi quantità di dati testuali. Questo permette loro di generare testi coerenti e rilevanti dal punto di vista contestuale, simili a quelli umani. Questi modelli sono costruiti sulla base di architetture di apprendimento profondo, come GPT (Generative Pre-trained Transformer) e BERT (Bidirectional Encoder Representations from Transformers), che utilizzano meccanismi di attenzione per catturare dipendenze a lungo termine in un linguaggio.
Sfruttando il pre-addestramento su set di dati su larga scala e il fine-tuning su compiti specifici, i LLM hanno mostrato prestazioni notevoli in vari compiti legati al linguaggio, tra cui la generazione di testo, l’analisi del sentiment, la traduzione automatica e la risposta alle domande. Man mano che i LLM continuano a migliorare, essi hanno un enorme potenziale per rivoluzionare la comprensione e la generazione del linguaggio naturale, colmando il divario tra le macchine e l’elaborazione del linguaggio simile a quella umana.
- Preparazione per l’intervista Inferenza causale
- Le migliori rilevanti visione artificiale per la settimana dal 7/8 al 13/8
- Gli hacker mettono in mostra le vulnerabilità dell’IA con trucchi maliziosi al DEF CON
D’altra parte, alcune persone pensavano che i LLM non stessero utilizzando appieno il loro potenziale in quanto sono limitati solo all’input testuale. Hanno lavorato per estendere il potenziale dei LLM oltre il linguaggio. Alcuni studi hanno integrato con successo i LLM con vari segnali di input, come immagini, video, discorsi e audio, per costruire potenti chatbot multimodali.
Tuttavia, c’è ancora molta strada da fare qui poiché la maggior parte di questi modelli non comprende le relazioni tra gli oggetti visivi e le altre modalità. Sebbene i LLM migliorati visivamente possano generare descrizioni di alta qualità, lo fanno in modo opaco senza relazionarsi esplicitamente al contesto visivo.
Stabilire una corrispondenza esplicita e informativa tra il testo e le altre modalità nei LLM multimodali può migliorare l’esperienza utente e consentire un nuovo set di applicazioni per questi modelli. Incontriamo quindi BuboGPT, che affronta questa limitazione.
BuboGPT è il primo tentativo di incorporare la comprensione visiva nei LLM collegando gli oggetti visivi alle altre modalità. BuboGPT consente una comprensione e una chat multimodali congiunte per testo, visione e audio apprendendo uno spazio di rappresentazione condiviso che si allinea bene con i LLM pre-addestrati.
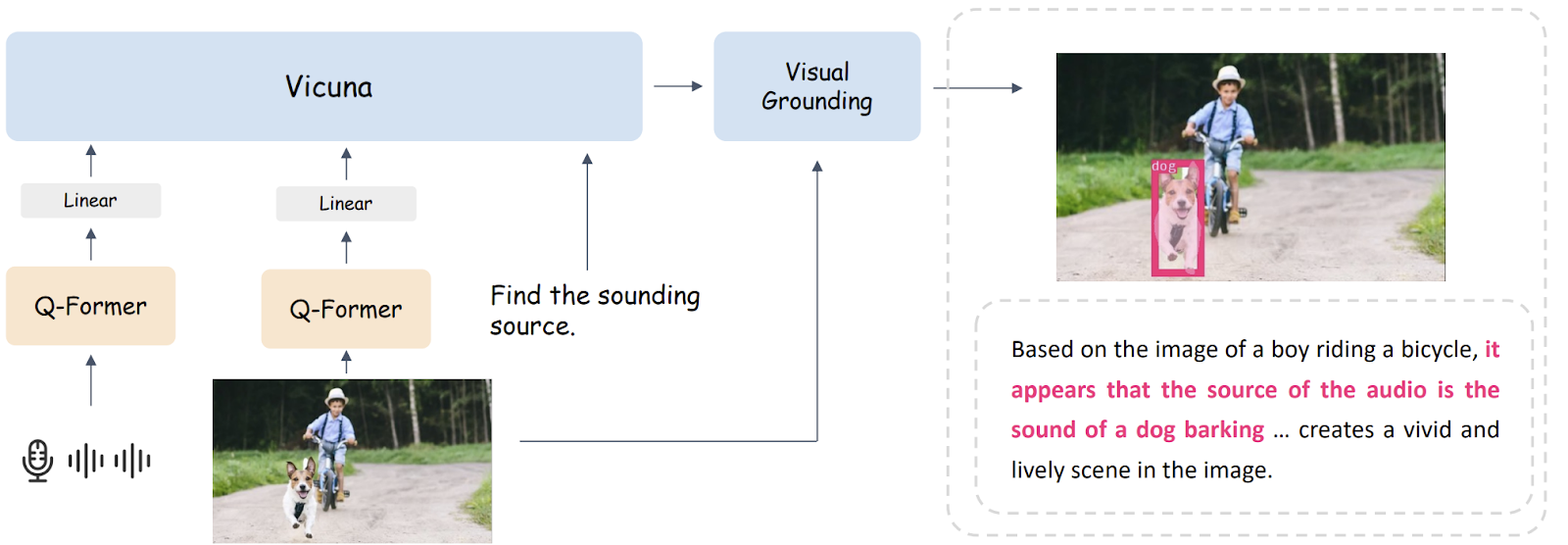
La comprensione visiva non è un compito facile da realizzare, quindi gioca un ruolo cruciale nel pipeline di BuboGPT. Per raggiungere questo obiettivo, BuboGPT costruisce una pipeline basata su un meccanismo di auto-attenzione. Questo meccanismo stabilisce relazioni dettagliate tra gli oggetti visivi e le modalità.
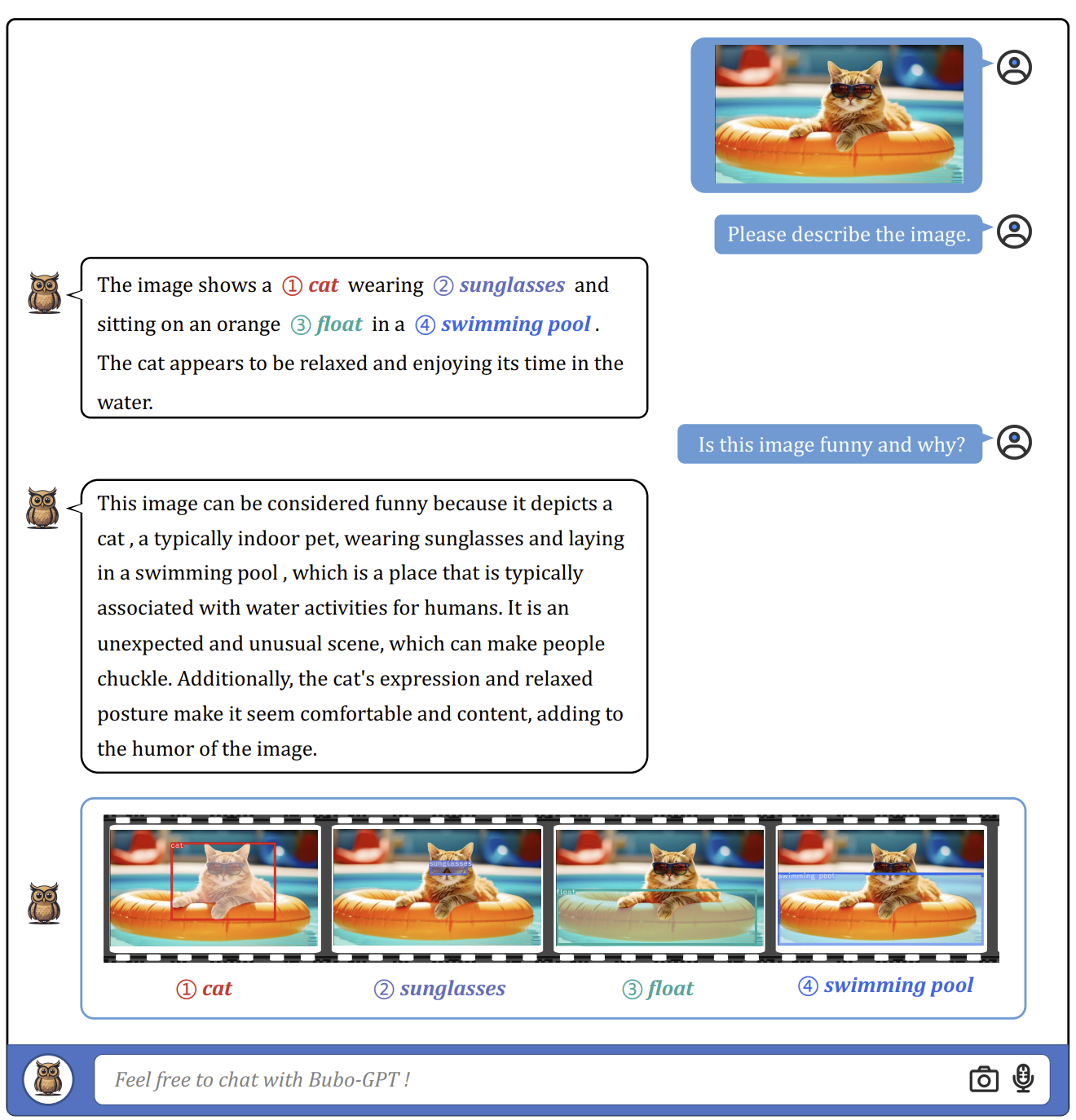
La pipeline comprende tre moduli: un modulo di tagging, un modulo di grounding e un modulo di corrispondenza delle entità. Il modulo di tagging genera etichette di testo rilevanti per l’immagine di input, il modulo di grounding localizza maschere semantiche o riquadri per ciascuna etichetta e il modulo di corrispondenza delle entità utilizza il ragionamento LLM per recuperare entità corrispondenti dalle etichette e dalle descrizioni delle immagini. Collegando gli oggetti visivi e le altre modalità attraverso il linguaggio, BuboGPT migliora la comprensione degli input multimodali.
Per consentire una comprensione multimodale di combinazioni arbitrarie di input, BuboGPT utilizza uno schema di addestramento a due fasi simile a Mini-GPT4. Nella prima fase, utilizza ImageBind come codificatore audio, BLIP-2 come codificatore visivo e Vicuna come LLM per apprendere un Q-former che allinea le caratteristiche visive o audio con il linguaggio. Nella seconda fase, esegue un accordo multimodale su un dataset di alta qualità per seguire le istruzioni.
La costruzione di questo dataset è cruciale affinché il LLM riconosca le modalità fornite e se gli input siano ben abbinati. Pertanto, BuboGPT crea un nuovo dataset di alta qualità con sottoinsiemi per l’istruzione visiva, l’istruzione audio, la localizzazione del suono con coppie immagine-audio positive e la didascalia immagine-audio con coppie negative per il ragionamento semantico. Introducendo coppie immagine-audio negative, BuboGPT apprende una migliore allineamento multimodale e mostra una maggiore capacità di comprensione congiunta.