Percezione BEV nella guida autonoma in produzione di massa
BEV perception in mass production autonomous driving.
La Ricetta di XNet di Xpeng Motors
Questo post del blog si basa sulla relazione invitata nella Workshop di guida autonoma end-to-end presso CVPR 2023 tenutasi a Vancouver, dal titolo “La pratica della guida autonoma di produzione di massa in Cina”.
La percezione BEV ha visto grandi progressi negli ultimi anni. Percepisce direttamente l’ambiente intorno ai veicoli a guida autonoma. La percezione BEV può essere vista come un sistema di percezione end-to-end, e un passo importante verso un sistema di guida autonoma end-to-end. Qui definiamo i sistemi di guida autonoma end-to-end come pipeline completamente differenziabili che prendono dati di sensori grezzi in input e producono un piano di guida ad alto livello o azioni di controllo a basso livello come output.
CVPR 2023 Workshop di Guida Autonoma | OpenDriveLab
Siamo orgogliosi di annunciare quattro nuove sfide quest’anno, in collaborazione con i nostri partner – Vision-Centric…
opendrivelab.com
La comunità di guida autonoma ha visto una rapida crescita di approcci che abbracciano un framework di algoritmi end-to-end. Discuteremo della necessità di approcci end-to-end dai primi principi. Poi esamineremo gli sforzi per distribuire l’algoritmo di percezione BEV sui veicoli di produzione di massa, prendendo lo sviluppo di XNet, l’architettura di percezione BEV di Xpeng come esempio. Infine, faremo una sessione di brainstorming sul futuro della percezione BEV verso la guida autonoma completamente end-to-end.
- Analisi delle prestazioni e ottimizzazione del modello PyTorch – Parte 2.
- Una guida pratica al trasferimento di apprendimento utilizzando PyTorch.
- SRGAN Colmare il Divario tra le Immagini a Bassa e Alta Risoluzione
La Necessità di Sistemi End-to-End
Nella soluzione di qualsiasi problema di ingegneria, spesso è necessario utilizzare un approccio divide-et-impera per trovare soluzioni pratiche rapidamente. Questa strategia implica la suddivisione del grande problema in componenti più piccoli e relativamente ben definiti che possono essere risolti indipendentemente. Sebbene questo approccio aiuti a fornire rapidamente un prodotto completo, aumenta anche il rischio di rimanere bloccati in una soluzione di ottimo locale. Per raggiungere la soluzione di ottimo globale, tutti i componenti devono essere ottimizzati insieme in modo end-to-end.
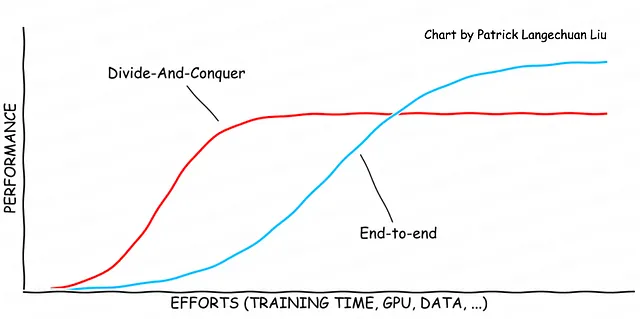
La regola dell’80-20 rafforza il concetto che l’80% delle prestazioni desiderate può essere raggiunto con solo il 20% dello sforzo totale. Il vantaggio dell’approccio divide-et-impera è che consente agli sviluppatori di lavorare rapidamente con uno sforzo minimo. Tuttavia, il lato negativo è che questo metodo spesso porta a un tetto di prestazione al 80%. Per superare il limite di prestazione e uscire dall’ottimo locale, gli sviluppatori devono ottimizzare alcuni componenti insieme, che è il primo passo nello sviluppo di una soluzione end-to-end. Questo processo deve essere ripetuto diverse volte, rompendo i tetti di prestazione più volte fino a quando non si raggiunge una soluzione completamente end-to-end. La curva risultante può assumere la forma di una serie di curve sigmoidali fino a quando non viene approssimata la soluzione ottimale globale. Un esempio di uno sforzo verso una soluzione end-to-end è lo sviluppo dell’algoritmo di percezione BEV.
Percezione 2.0: Percezione End-to-End
Nelle tradizionali pile di guida autonoma, le immagini 2D vengono alimentate nel modulo di percezione per generare risultati 2D. La fusione dei sensori viene quindi utilizzata per ragionare tra i risultati 2D di più telecamere ed elevare questi a 3D. Gli oggetti 3D risultanti vengono successivamente inviati ai componenti a valle, come la previsione e la pianificazione.
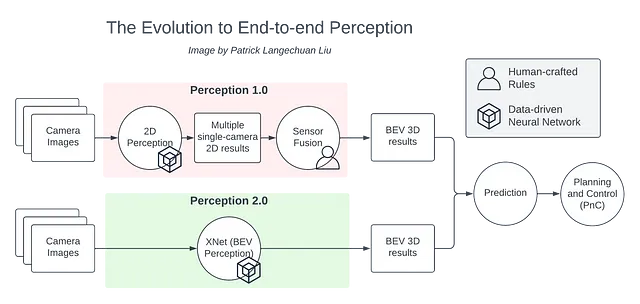
Tuttavia, la fase di fusione dei sensori richiede molte regole artigianali per fondere i risultati di percezione provenienti da diversi flussi di telecamera. Ogni telecamera percepisce solo una parte dell’oggetto da osservare, quindi la combinazione delle informazioni ottenute richiede un’attenta regolazione della logica di fusione. Stiamo essenzialmente facendo una back-propagation attraverso la testa degli ingegneri. Inoltre, lo sviluppo e la manutenzione di queste regole creano una serie di complicazioni, portando a numerosi problemi in complessi ambienti urbani.
Per superare questa sfida, possiamo applicare il modello di percezione della Vista d’Uccello (BEV), che ci consente di percepire l’ambiente direttamente nello spazio BEV. Lo stack di percezione BEV combina due componenti separate in una singola soluzione, eliminando così la logica artificiale fragile. La percezione BEV è essenzialmente una soluzione di percezione end-to-end. Questo rappresenta un passo critico verso un sistema di guida autonoma end-to-end.
XNet: lo stack di percezione BEV di Xpeng Motors
L’architettura di percezione BEV di Xpeng è chiamata XNet. È stata presentata pubblicamente per la prima volta nel Xpeng 1024 Tech Day nel 2022. La visualizzazione qui sotto rappresenta l’architettura di percezione XNet a bordo in azione. Il veicolo rosso al centro rappresenta il veicolo di guida autonoma mentre naviga in una rotonda. L’ambiente circostante statico è completamente rilevato dalla percezione a bordo e non viene utilizzata alcuna mappa HD. Possiamo osservare che XNet rileva con precisione una vasta gamma di oggetti dinamici e statici intorno al veicolo.
Il team di intelligenza artificiale di Xpeng ha iniziato a sperimentare l’architettura XNet oltre due anni fa (all’inizio del 2021), ed è stata oggetto di diverse iterazioni prima di arrivare alla sua forma attuale. Sfruttiamo le reti neurali convoluzionali (CNN) per generare le caratteristiche delle immagini, mentre le caratteristiche multicamera vengono trasposte nello spazio BEV attraverso una struttura di trasformazione. In particolare, è stato utilizzato un modulo di cross-attenzione. Le caratteristiche BEV di diversi fotogrammi passati vengono quindi fuse con la posizione dell’ego – sia spazialmente che temporalmente – per decodificare gli elementi dinamici e statici dalle caratteristiche fuse.

L’architettura di percezione BEV incentrata sulla visione migliora la convenienza economica per la distribuzione di soluzioni di guida autonoma, riducendo la necessità di componenti hardware più costosi. Le accurate rilevazioni 3D e la velocità svelano una nuova dimensione di ridondanza e riducono la dipendenza da LiDAR e radar. Inoltre, la percezione dell’ambiente 3D in tempo reale riduce la dipendenza dalle mappe HD. Entrambe le capacità contribuiscono significativamente a una soluzione di guida autonoma più affidabile ed economica.
Le sfide di XNet
La distribuzione di una tale rete neurale su veicoli di produzione presenta diverse sfide. In primo luogo, sono necessari milioni di clip video multicamera per addestrare XNet. Queste clip coinvolgono circa un miliardo di oggetti che richiedono annotazione. Sulla base dell’efficienza attuale dell’annotazione, sono necessari circa 2.000 anni-umani per l’annotazione. Purtroppo, ciò significa che per il team di annotazione interno di circa 1000 persone presso Xpeng, una tale attività richiederebbe circa due anni per essere completata, il che non è accettabile. Dal punto di vista della formazione del modello, ci vorrebbe quasi un anno per addestrare una tale rete utilizzando una singola macchina. Inoltre, la distribuzione di una tale rete senza alcuna ottimizzazione su una piattaforma NVIDIA Orin richiederebbe il 122% della potenza di calcolo di un chip.
Tutte queste questioni presentano sfide che dobbiamo affrontare per la formazione e la distribuzione di un modello così complesso e grande.
Autolabel
Per migliorare l’efficienza di annotazione, abbiamo sviluppato un sistema di autolabel altamente efficace. Questo stack di fusione dei sensori offline aumenta l’efficienza fino a 45.000 volte, consentendoci di completare attività di annotazione che avrebbero richiesto 200 anni-umani in soli 17 giorni.

Sopra è presente il sistema di autolabel basato su LiDAR, e abbiamo anche sviluppato un sistema che si basa esclusivamente sui sensori di visione. Ciò ci consente di annotare clip ottenute dalle flotte di clienti che non dispongono di LiDAR. Questo è una parte critica del ciclo di chiusura dei dati e del miglioramento dello sviluppo di un sistema di percezione auto-evolutivo.
Formazione su larga scala
Abbiamo ottimizzato il processo di formazione per XNet da due punti di vista. In primo luogo, abbiamo applicato la formazione a precisione mista e le tecniche di ottimizzazione dell’operatore per semplificare il processo di formazione su un singolo nodo, riducendo il tempo di formazione di un fattore di 10. Successivamente, abbiamo collaborato con Alicloud e abbiamo costruito un cluster di GPU con una potenza di calcolo di 600 PFLOPS, consentendoci di scalare la formazione da una singola macchina a macchine multiple. Ciò ha ulteriormente ridotto il tempo di formazione, anche se il processo non è stato semplice poiché abbiamo dovuto regolare attentamente la procedura di formazione per ottenere una scalabilità delle prestazioni quasi lineare. Nel complesso, abbiamo ridotto il tempo di formazione di XNet da 276 giorni a soli 11 ore. Si noti che all’aumentare dei dati nel processo di formazione, il tempo di formazione aumenta naturalmente, richiedendo ulteriori ottimizzazioni. Pertanto, l’ottimizzazione della scalabilità rimane uno sforzo continuo e critico.

Efficienza di distribuzione su Orin
Affinché XNet funzioni su un chip Nvidia Orin senza alcuna ottimizzazione, sarebbe necessario utilizzare il 122% della potenza di calcolo del chip. Analizzando il grafico di profilazione mostrato all’inizio, abbiamo notato che il modulo trasformatore consumava la maggior parte del tempo di esecuzione. Questo è comprensibile poiché il modulo trasformatore non ha ricevuto molta attenzione durante la fase di progettazione iniziale del chip Orin. Di conseguenza, abbiamo dovuto ridisegnare il modulo trasformatore e il meccanismo di attenzione per supportare la piattaforma Orin, consentendoci di ottenere una velocità di elaborazione 3 volte maggiore.
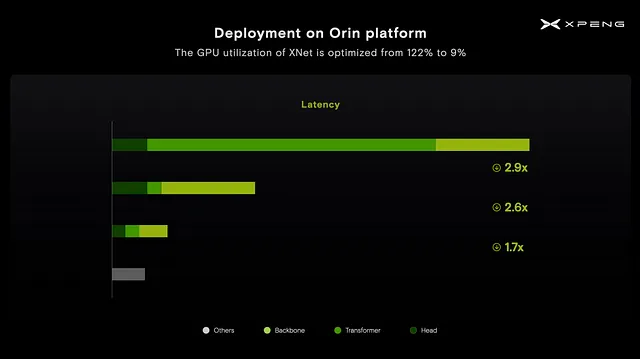
Motivati a ottimizzare ulteriormente, abbiamo proseguito ottimizzando la rete attraverso la potatura, ottenendo un’ulteriore velocità di elaborazione 2,6 volte maggiore. Infine, utilizzando il bilanciamento del carico di lavoro tra GPU e DLA, abbiamo ottenuto una velocità di elaborazione ulteriore 1,7 volte maggiore.
Grazie a queste tecniche di ottimizzazione, abbiamo ridotto l’utilizzo della GPU di XNet dal 122% a soli 9%. Ciò ci ha permesso di esplorare nuove possibilità di architettura sulla piattaforma Orin.
Motore di dati autoevolutivo
Con l’implementazione dell’architettura XNet, possiamo ora avviare iterazioni guidate dai dati per migliorare le prestazioni del modello. Per fare ciò, identifichiamo prima casi limite sulla macchina e quindi distribuiamo trigger configurabili alla flotta di clienti per raccogliere immagini pertinenti. Successivamente, recuperiamo le immagini dai dati raccolti, basandoci su una breve descrizione in linguaggio naturale o su un’immagine stessa. In questo modo, sfruttiamo i recenti progressi nei grandi modelli di linguaggio per aumentare l’efficienza della cura e dell’annotazione dei dataset.
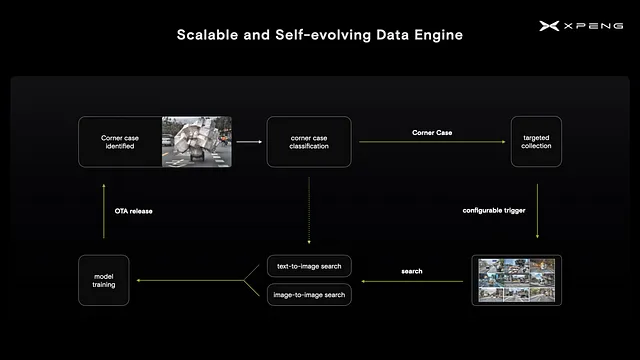
Con l’architettura XNet e il motore di dati, abbiamo creato un sistema di percezione scalabile e autoevolutivo.
Il futuro
La più recente versione di Xpeng Highway NGP 2.0 unifica le soluzioni di pilota automatico per autostrade e città, consentendo agli utenti di inserire una spilla in una città diversa e di avere un’esperienza fluida dall’inizio alla fine. Questa unificazione è resa possibile da XNet, che fornisce una solida base per una pila unificata in tutti gli scenari. L’obiettivo finale è di consentire un’esperienza utente punto a punto con la guida autonoma end-to-end.
Per rendere il sistema di guida autonoma end-to-end differenziabile, un’altra parte critica mancante è una pila di pianificazione basata sull’apprendimento automatico. Le soluzioni di pianificazione basate sull’apprendimento possono essere largamente divise in approcci di apprendimento per imitazione o di apprendimento per rinforzo. I recenti progressi nei grandi modelli di linguaggio (LLM) spianano la strada per l’avanzamento di questo importante argomento. Il seguente repository Github è una raccolta dal vivo di lavori pertinenti nel campo emergente della guida autonoma end-to-end.
GitHub – OpenDriveLab/End-to-end-Autonomous-Driving: Tutto ciò di cui hai bisogno per la guida autonoma end-to-end
Tutto ciò di cui hai bisogno per la guida autonoma end-to-end. Contribuisci allo sviluppo di OpenDriveLab/End-to-end-Autonomous-Driving…
github.com
Riassunto
- Dividere e conquistare raggiunge l’80% delle prestazioni con il 20% dello sforzo. Gli approcci end-to-end mirano a superare il tetto del 80% delle prestazioni, a potenzialmente maggiori costi.
- XNet è un sistema di percezione end-to-end e un passo critico verso una soluzione full-stack end-to-end. Richiede uno sforzo ingente di ingegneria (80%) secondo la regola dell’80-20.
- La grande quantità di annotazioni necessarie per XNet richiede l’annotazione automatica, poiché l’annotazione umana non è fattibile. Il sistema di autoetichettatura può aumentare l’efficienza di 45000 volte.
- La formazione su larga scala richiede l’ottimizzazione della formazione su una singola macchina e la scalabilità da una macchina a più macchine.
- La distribuzione di XNet sulla piattaforma Nvidia Orin richiede la ridefinizione del modulo trasformatore.
Tutti i grafici e i video presenti in questo blog sono stati creati dall’autore.
Riferimenti
- Per le sfide uniche nel dispiegamento della guida autonoma a produzione di massa in Cina, si prega di consultare il seguente link. Questo faceva anche parte della stessa presentazione invitata a CVPR 2023.
Sfide della guida autonoma a produzione di massa in Cina
E la risposta di Xpeng
Nisoo.com
- Xpeng 1024 Tech Day 2022: https://www.youtube.com/watch?v=0dEoctcK09Q





