Assistente vocale personale basato su intelligenza artificiale per l’apprendimento delle lingue
Assistente vocale IA per l'apprendimento delle lingue

Qual è il modo più efficace per padroneggiare una nuova lingua? Parlarla! Ma tutti sappiamo quanto possa essere intimidatorio provare nuove parole e frasi di fronte agli altri. E se avessi un amico paziente e comprensivo con cui esercitarti, libero da giudizi, libero da vergogna?
Quell’amico paziente e comprensivo che stai cercando potrebbe essere proprio un tutor virtuale di lingua alimentato da LLM! Questo potrebbe essere un modo rivoluzionario per padroneggiare una lingua, tutto dal comfort del tuo spazio.
Recentemente, sono comparsi dei grandi modelli di lingua, e stanno cambiando il modo in cui facciamo le cose. Questi potenti strumenti hanno creato chatbot in grado di rispondere come gli esseri umani, e si sono rapidamente integrati in vari aspetti della nostra vita, venendo utilizzati in centinaia di modi diversi. Un uso particolarmente interessante è nell’apprendimento delle lingue, soprattutto per quanto riguarda l’esercizio di conversazione.
Quando mi sono trasferito in Germania qualche tempo fa, ho capito quanto possa essere difficile imparare una nuova lingua e trovare opportunità per praticarla oralmente. I corsi e i gruppi di lingua possono essere costosi o difficili da inserire in un programma molto impegnato. Come persona che si confronta con queste sfide, ho avuto un’idea: perché non utilizzare dei chatbot per l’esercizio di conversazione? Tuttavia, scrivere messaggi di testo da soli non sarebbe sufficiente, poiché l’apprendimento di una lingua coinvolge molto più che scrivere. Pertanto, combinando un chatbot alimentato da intelligenza artificiale con tecnologie di trascrizione vocale e sintesi vocale, sono riuscito a creare un’esperienza di apprendimento che sembra di parlare con una persona reale.
- 10 migliori strumenti di recupero dati per Android
- Apprendimento automatico su larga scala parallelismo del modello rispetto al parallelismo dei dati
- IA e il futuro del football universitario
In questo articolo, condividerò gli strumenti che ho scelto, spiegherò il processo e presenterò il concetto di esercizio di conversazione con un chatbot basato su intelligenza artificiale attraverso comandi vocali e risposte vocali. La pipeline del progetto è composta da tre sezioni principali: trascrizione vocale, utilizzo di un modello di lingua e conversione da testo a voce. Queste verranno spiegate nei seguenti tre paragrafi.
1. Trascrizione vocale
Il riconoscimento vocale per il mio tutor di lingua funge da ponte tra l’input vocale dell’utente e la comprensione basata su testo dell’IA per generare una risposta. È un componente critico che consente un’interazione vocale, contribuendo a un’esperienza di apprendimento linguistico più coinvolgente ed efficace.
Una trascrizione accurata è cruciale per un’interazione fluida con il chatbot, soprattutto in un contesto di apprendimento delle lingue in cui la pronuncia, l’accento e la grammatica sono fattori chiave. Ci sono vari strumenti di riconoscimento vocale che possono essere utilizzati per trascrivere l’input vocale in Python, come Whisper di OpenAI e Speech-to-Text di Google Cloud.
Nella scelta di uno strumento di riconoscimento vocale per il progetto del tutor di lingua, devono essere presi in considerazione fattori come l’accuratezza, il supporto linguistico, il costo e se è necessaria una soluzione offline.
Google ha un’API Python che richiede una connessione internet e offre 60 minuti di trascrizione gratuita al mese. A differenza di Google, OpenAI ha pubblicato il proprio modello Whisper e puoi eseguirlo localmente senza dipendere dalla velocità di internet, purché tu abbia abbastanza potenza di calcolo. Ecco perché ho scelto Whisper per ridurre al minimo la latenza della trascrizione.
2. Modello di lingua
Il modello di lingua è il cuore di questo progetto. Poiché sono già molto familiare con ChatGPT e la sua API, ho deciso di utilizzarlo anche per questo progetto. Tuttavia, nel caso in cui tu abbia abbastanza potenza di calcolo, puoi anche distribuire Llama localmente, il che sarebbe gratuito. ChatGPT costa un po’ di denaro, ma è molto più conveniente in quanto hai solo bisogno di un paio di righe di codice per eseguirlo.
Per aumentare la coerenza delle risposte e averle in un template specifico, potresti anche addestrare ulteriormente i modelli di lingua (ad esempio, come addestrare ChatGPT per il tuo caso d’uso). Devi generare frasi esemplari e le relative risposte ottimali e inserirle in un addestramento di affinamento. Tuttavia, il tutor di base che voglio creare non ha bisogno di un affinamento e userò il GPT3.5-turbo generalizzato nel mio progetto.
Fornirò un esempio di chiamata API per facilitare una conversazione tra l’utente e ChatGPT tramite la sua API in Python, di seguito. Prima, se non ne hai già uno, dovrai aprire un account OpenAI e impostare una chiave API per interagire con ChatGPT. Le istruzioni sono fornite qui.
Una volta configurata la chiave API, puoi iniziare a generare testo utilizzando il metodo openai.ChatCompletion.create. Questo metodo richiede due parametri: il parametro modello, che specifica il particolare modello GPT a cui accedere tramite l’API, e il parametro messaggi, che include la struttura per una conversazione con ChatGPT. Il parametro messaggi è composto da due componenti chiave: ruolo e contenuto.
Ecco un frammento di codice per illustrare il processo:
# Inizializza i messaggi con il comportamento impostato.
messages = [{"role": "sistema", "content": "Inserisci qui il/i comportamento/i."}]
# Avvia un ciclo infinito per continuare la conversazione con l'utente.
while True:
content = input("Utente: ") # Ottieni l'input dall'utente per rispondere.
messages.append({"role": "utente", "content": content}) # Aggiungi l'input dell'utente ai messaggi.
# Utilizza il modello OpenAI GPT-3.5 per generare una risposta all'input dell'utente.
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
chat_response = completion.choices[0].message.content # Estrai la risposta dalla risposta dell'API.
print(f'ChatGPT: {chat_response}') # Stampa la risposta.
# Aggiungi la risposta ai messaggi con il ruolo "assistente" per registrare la cronologia della conversazione.
messages.append({"role": "assistente", "content": chat_response})- Il ruolo
sistemaè definito per determinare il comportamento di ChatGPT aggiungendo un’istruzione all’inizio della lista dei messaggi. - Durante la chat, il messaggio
utenteviene ricevuto dall’utente tramite un modello di riconoscimento vocale per ottenere una risposta da ChatGPT. - Infine, le risposte di ChatGPT vengono aggiunte alla lista dei messaggi nel ruolo di
assistenteper registrare la cronologia della conversazione.
3. Conversione da testo a voce
Nella sezione di trascrizione da testo a voce, ho spiegato come l’utente utilizza comandi vocali per simulare un’esperienza di conversazione, come se stesse parlando con una persona reale. Per migliorare ulteriormente questa sensazione e creare un’esperienza di apprendimento più dinamica e interattiva, il passo successivo prevede la conversione dell’output testuale da GPT in una voce udibile utilizzando uno strumento di sintesi vocale come gTTS. Questo non solo aiuta a creare un’esperienza più coinvolgente e facile da seguire, ma affronta anche un aspetto critico dell’apprendimento delle lingue: la sfida della comprensione attraverso l’ascolto anziché la lettura. Integrando questo componente uditivo, stiamo facilitando una pratica più completa che riflette da vicino l’uso delle lingue nel mondo reale.
Sono disponibili vari strumenti TTS, come il Text-to-Speech di Google (gTTS) e il Text to Speech di IBM Watson. In questo progetto, ho preferito gTTS perché è estremamente facile da usare, offre una qualità vocale naturale senza costi. Per utilizzare la libreria gTTS, è necessaria una connessione internet poiché la libreria richiede accesso al server di Google per convertire il testo in voce.
Spiegazione dettagliata della pipeline
Prima di immergerci nella pipeline, potresti voler dare un’occhiata al codice completo sulla mia pagina Github, poiché farò riferimento a alcune sezioni.
La figura seguente spiega il flusso di lavoro del tutor linguistico virtuale potenziato dall’IA, progettato per creare un’esperienza di apprendimento conversazionale in tempo reale basata sulla voce:
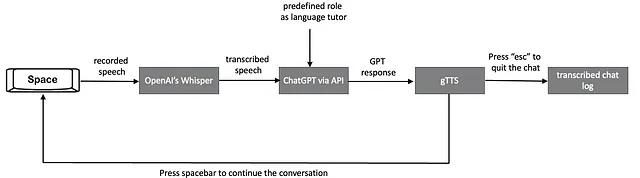
- L’utente inizia la conversazione avviando la registrazione della propria voce, salvandola temporaneamente come file .wav. Ciò viene realizzato premendo e tenendo premuto il tasto spazio e la registrazione si interrompe quando il tasto spazio viene rilasciato. Le sezioni del codice Python che abilitano questa funzionalità di premere e parlare sono spiegate di seguito.
Le seguenti variabili globali vengono utilizzate per gestire lo stato del processo di registrazione:
recording = False # Indica se il sistema sta registrando audio
done_recording = False # Indica che l'utente ha completato la registrazione di un comando vocale
stop_recording = False # Indica che l'utente vuole uscire dalla conversazioneLa funzione listen_for_keys serve a controllare la pressione e il rilascio dei tasti. Imposta le variabili globali in base allo stato del tasto spazio e del tasto Esc.
def listen_for_keys():
# Funzione per ascoltare le pressioni dei tasti per controllare la registrazione
global recording, done_recording, stop_recording
while True:
if keyboard.is_pressed('space'): # Avvia la registrazione alla pressione del tasto spazio
stop_recording = False
recording = True
done_recording = False
elif keyboard.is_pressed('esc'): # Interrompi la registrazione alla pressione di 'esc'
stop_recording = True
break
elif recording: # Interrompi la registrazione al rilascio del tasto spazio
recording = False
done_recording = True
break
time.sleep(0.01)La funzione callback viene utilizzata per gestire i dati audio durante la registrazione. Controlla il flag recording per determinare se registrare i dati audio in arrivo.
def callback(indata, frames, time, status): # Funzione chiamata per ogni blocco audio durante la registrazione. if recording: if status: print(status, file=sys.stderr) q.put(indata.copy())La funzione press2record è la funzione principale responsabile della registrazione vocale quando l’utente preme e tiene premuto il tasto spazio.
Inizializza le variabili globali per gestire lo stato di registrazione e determina il tasso di campionamento e crea un file temporaneo per memorizzare l’audio registrato.
La funzione apre quindi un oggetto SoundFile per scrivere i dati audio e un oggetto InputStream per catturare l’audio dal microfono, utilizzando la funzione callback precedentemente menzionata. Viene avviato un thread per ascoltare i tasti premuti, in particolare il tasto spazio per la registrazione e il tasto ‘esc’ per interrompere. All’interno di un ciclo, la funzione controlla il flag di registrazione e scrive i dati audio nel file se la registrazione è attiva. Se la registrazione viene interrotta, la funzione restituisce -1; in caso contrario, restituisce il nome del file audio registrato.
def press2record(filename, subtype, channels, samplerate): # Funzione per gestire la registrazione quando viene premuto un tasto global recording, done_recording, stop_recording stop_recording = False recording = False done_recording = False try: # Determina il tasso di campionamento se non fornito if samplerate is None: device_info = sd.query_devices(None, 'input') samplerate = int(device_info['default_samplerate']) print(int(device_info['default_samplerate'])) # Crea un nome file temporaneo se non fornito if filename is None: filename = tempfile.mktemp(prefix='captured_audio', suffix='.wav', dir='') # Apre il file audio per la scrittura with sf.SoundFile(filename, mode='x', samplerate=samplerate, channels=channels, subtype=subtype) as file: with sd.InputStream(samplerate=samplerate, device=None, channels=channels, callback=callback, blocksize=4096) as stream: print('Premi Spazio per avviare la registrazione, rilascia per interrompere o premi Esc per uscire') listener_thread = threading.Thread(target=listen_for_keys) # Avvia il listener su un thread separato listener_thread.start() # Scrive l'audio registrato nel file while not done_recording and not stop_recording: while recording and not q.empty(): file.write(q.get()) # Restituisce -1 se la registrazione viene interrotta if stop_recording: return -1 except KeyboardInterrupt: print('Interrotto dall\'utente') return filenameInfine, la funzione get_voice_command chiama press2record per registrare il comando vocale dell’utente.
def get_voice_command(): # ... saved_file = press2record(filename="input_to_gpt.wav", subtype = args.subtype, channels = args.channels, samplerate = args.samplerate) # ...- Dopo aver catturato e salvato il comando vocale in un file temporaneo .wav, passiamo alla fase di trascrizione. In questa fase, l’audio registrato viene convertito in testo utilizzando Whisper. Lo script corrispondente per eseguire semplicemente il compito di trascrizione per un file .wav è il seguente:
def get_voice_command(): # ... result = audio_model.transcribe(saved_file, fp16=torch.cuda.is_available()) # ...Questo metodo richiede due parametri: il percorso del file audio registrato, saved_file, e un flag opzionale per utilizzare la precisione FP16 se CUDA è disponibile per migliorare le prestazioni su hardware compatibile. Restituisce semplicemente il testo trascritto.
- Successivamente, il testo trascritto viene inviato a ChatGPT per generare una risposta appropriata nella funzione
interact_with_tutor(). Il segmento di codice corrispondente è il seguente:
def interact_with_tutor(): # Definisci il ruolo del sistema per impostare il comportamento dell'assistente chat messages = [ {"role": "system", "content" : "Tu sei Anna, la mia compagna di studio tedesca. Chatterai con me. Le tue risposte saranno brevi. Il mio livello è B1, adatta la complessità delle tue frasi al mio livello. Cerca sempre di farmi parlare facendomi domande e approfondisci sempre la chat."} ] while True: # Ottieni il comando vocale dell'utente command = get_voice_command() if command == -1: # Salva i log della chat ed esci se la registrazione viene interrotta save_response_to_pkl(messages) return "La chat è stata interrotta." # Aggiungi il comando dell'utente alla cronologia dei messaggi messages.append({"role": "user", "content": command}) # Genera una risposta dall'assistente chat completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=messages ) # Estrai la risposta dal completamento chat_response = completion.choices[0].message.content # Estrai la risposta dal completamento print(f'ChatGPT: {chat_response} \n') # Stampa la risposta dell'assistente messages.append({"role": "assistant", "content": chat_response}) # Aggiungi la risposta dell'assistente alla cronologia dei messaggi # ...La funzione interact_with_tutor inizia definendo il ruolo di sistema di ChatGPT per modellare il suo comportamento durante la conversazione. Dal momento che il mio obiettivo è praticare il tedesco, imposto di conseguenza il ruolo di sistema. Ho chiamato il mio tutor virtuale “Anna” e ho impostato il mio livello di competenza linguistica per farle adattare le sue risposte. Inoltre, le ho dato istruzioni per mantenere la conversazione coinvolgente facendo domande.
Successivamente, il comando vocale trascritto dell’utente viene aggiunto alla lista dei messaggi con il ruolo di “utente”. Questo messaggio viene quindi inviato a ChatGPT. Durante la conversazione all’interno di un ciclo while, l’intera cronologia dei comandi dell’utente e delle risposte di GPT viene registrata nella lista dei messaggi.
- Dopo ogni risposta di ChatGPT, convertiamo il messaggio di testo in audio utilizzando gTTS.
def interact_with_tutor(): # ... # Convert the text response to speech speech_object = gTTS(text=messages[-1]['content'],tld="de", lang=language, slow=False) speech_object.save("GPT_response.wav") current_dir = os.getcwd() audio_file = "GPT_response.wav" # Play the audio response play_wav_once(audio_file, args.samplerate, 1.0) os.remove(audio_file) # Remove the temporary audio fileLa funzione gTTS() riceve 4 parametri: text, tld, lang e slow. Il parametro text viene assegnato al contenuto dell’ultimo messaggio nella lista messages (indicato da [-1]) che si desidera convertire in audio. Il parametro tld specifica il dominio di primo livello per il servizio Google Translate. Impostandolo su "de" significa che viene utilizzato il dominio tedesco, il che può essere importante per garantire che la pronuncia e l’intonazione siano appropriate per il tedesco. Il parametro lang specifica la lingua in cui il testo deve essere pronunciato. In questo codice, la variabile language è impostata su 'de', il che significa che il testo verrà pronunciato in tedesco. slow=False: il parametro slow controlla la velocità della pronuncia. Impostandolo su False significa che il testo verrà pronunciato a velocità normale. Se fosse impostato su True, il testo verrebbe pronunciato più lentamente.
- L’audio convertito della risposta di ChatGPT viene quindi salvato come file .wav temporaneo, riprodotto all’utente e quindi rimosso.
- La funzione
interact_with_tutorviene eseguita ripetutamente quando l’utente continua la conversazione premendo nuovamente il tasto di spazio. - Se l’utente preme “esc”, la conversazione termina e l’intera conversazione viene salvata in un file pickle,
chat_log.pkl. Puoi usarlo in seguito per analisi.
Utilizzo da linea di comando
Per eseguire lo script, esegui semplicemente il codice Python nel terminale come segue:
sudo python chat.pyÈ necessario usare sudo in quanto lo script richiede l’accesso al microfono e l’utilizzo della libreria di tastiera. Se usi Anaconda, puoi anche avviare il terminale di Anaconda come “esegui come amministratore” per ottenere l’accesso completo.
Ecco un video dimostrativo che mostra come viene eseguito il codice sul mio laptop. Puoi farti un’idea delle prestazioni:
Video dimostrativo creato dall’autore
Considerazioni finali
Ho impostato la lingua del tutor in tedesco semplicemente impostando il ruolo di sistema di ChatGPT e regolando i parametri all’interno della funzione gTTs per allinearsi con la lingua tedesca. Tuttavia, potresti facilmente passare a un’altra lingua. Ci vorrebbero solo pochi secondi per configurarlo per la tua lingua di destinazione.
Se desideri parlare di un argomento specifico, puoi anche aggiungerlo nel ruolo di sistema di ChatGPT. Ad esempio, potrebbe essere un bel caso d’uso esercitarsi per i colloqui. Puoi anche specificare il tuo livello linguistico per adattare le sue risposte.
Un’osservazione importante è che la velocità complessiva della chat dipende dalla tua connessione Internet (a causa dell’API di ChatGPT e di gTTS) e dall’hardware (a causa dell’implementazione locale di Whisper). Nel mio caso, il tempo di risposta complessivo dopo i miei input varia tra 4 e 10 secondi.






