10 Cose Interessanti Che Puoi Fare Con gli Embeddings! [Parte 1]
10 Interessanti Utilizzi degli Embeddings! [Parte 1]
Applica questi concetti per risolvere problemi industriali reali nel deep learning
Allontanandoci dall’apprendimento automatico classico (ML), gli embeddings sono al centro della maggior parte dei casi d’uso del deep learning (DL). Avere una comprensione di questo concetto ti consente di svolgere attività flessibili nello spazio delle caratteristiche e riprogettare i problemi di ML/DL in modo diverso, soprattutto con dati ad alta dimensionalità nel campo della visione artificiale e del trattamento del linguaggio naturale.
Gli embeddings hanno avuto un impatto significativo su diverse aree di applicazioni oggi, incluso Large Language Models (LLMs). Quello che manca nella letteratura tra questi grandi concetti, anche se dispersi, riguardo agli embeddings è una guida coerente su diverse applicazioni industriali e su come iniziare in questo campo! Ecco perché questo blog ti guiderà attraverso i diversi modi in cui puoi sfruttare gli embeddings e applicarli a problemi industriali reali.
“Questo articolo è la prima parte di una serie di due parti. È pensato come guida per principianti sui diversi tipi di modelli open-source popolari, mentre ti familiarizzi con il concetto fondamentale degli embeddings.”
Una spiegazione intuitiva degli embeddings
Gli embeddings sono rappresentazioni vettoriali continue a bassa dimensionalità apprese di variabili discrete [1].
Possiamo scomporre questa definizione e comprendere i punti importanti:
- dimensionalità inferiore rispetto ai dati di input
- rappresentazione compressa dei dati
- cattura delle relazioni complesse non lineari apprese dal modello come rappresentazione lineare
- riduzione delle dimensioni memorizzando informazioni rilevanti e ignorando il rumore
- solitamente estratti dagli strati finali delle reti neurali (appena prima del classificatore)
Cerchiamo di comprendere intuitivamente la definizione e il vero potenziale degli embeddings utilizzando un esempio. Supponiamo di analizzare le prestazioni degli operatori di un call center in base ai moduli di sondaggio dei clienti. I moduli sono stati compilati da migliaia di clienti e contengono milioni di parole uniche. Per effettuare qualsiasi tipo di analisi del testo, il nostro set di parametri di input sarà enorme e probabilmente comporterà una scarsa prestazione. Qui entrano in gioco gli embeddings!
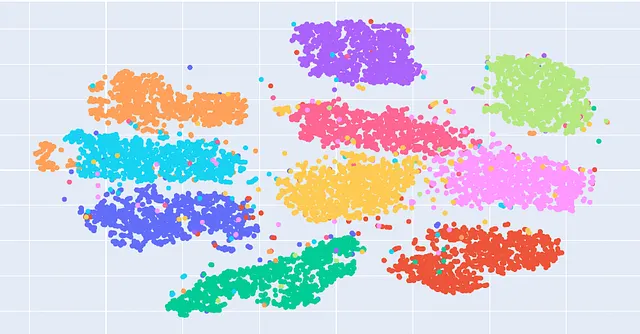
Al posto di prendere il set di parametri di input originale, prendiamo tutte le parole uniche e le esprimiamo come embeddings. In questo modo, riduciamo le dimensioni e portiamo il set di input a, diciamo, 9, che è più consumabile dal modello. Visualizzando gli embeddings degli operatori, è facile notare che gli Operatori B e C hanno ricevuto feedback simili dai clienti. Un altro esempio può essere trovato qui. [2]

Cosa Possiamo Fare Con Gli Embeddings?
Nella prima parte della serie, esploreremo le seguenti applicazioni degli embeddings:
- Usare gli Embeddings di Testo per Trovare Testi Simili
- Usare gli Embeddings Visivi per Trovare Immagini Simili
- Usare Diversi Tipi di Embeddings per Trovare Elementi Simili
- Usare Diversi Pesi sugli Embeddings per Trovare Elementi Simili
- Unire Embeddings di Immagini e Testo nello Stesso Spazio (Multimodale)
Ogni punto si basa sul punto precedente, causando un effetto moltiplicativo. I frammenti di codice sono autonomi e adatti ai principianti per sperimentare. Possono essere utilizzati come mattoni per creare sistemi più complessi. Ora, immergiamoci più a fondo in ogni caso d’uso qui di seguito.
I. Usare gli Embeddings di Testo per Trovare Testi Simili
Embeddings di testo = rappresentare il testo (parole o frasi) come vettori a valori reali in uno spazio a dimensioni inferiori.
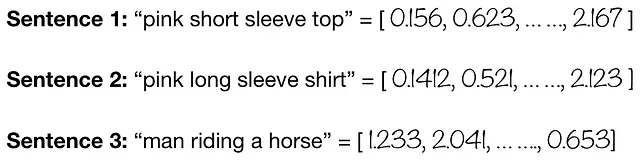
Ora, supponiamo che vogliamo sapere quanto simili o diversi siano le frasi sopra. Possiamo farlo utilizzando un codificatore di testo. Qui, utilizziamo un DistilBERT preaddestrato da Hugging Face per calcolare gli embeddings di testo e la similarità del coseno per calcolare la similarità!
Confronta le incapsulazioni del testo DistilBERT per testi diversi utilizzando la similarità coseno
Osserviamo che i testi che contengono parole simili e corrispondenti daranno un punteggio di similarità più alto. D’altra parte, i testi che sono diversi l’uno dall’altro in termini di scelta delle parole, significato e contesto (a seconda del modello!) daranno un punteggio di similarità più basso come mostrato di seguito. Pertanto, le incapsulazioni del testo mirano a utilizzare la vicinanza semantica delle parole per stabilire una relazione significativa.

Applicazioni reali: Ricerca di documenti, Recupero delle informazioni, Analisi del sentiment, Motore di ricerca [3]
II. Utilizzare incapsulazioni visive per trovare immagini simili
Incapsulazioni visive = rappresentazione delle immagini (ossia dei valori dei pixel) come vettori a valori reali in uno spazio a dimensione inferiore.
Al posto del testo, ora vogliamo sapere quanto sono visivamente simili le due immagini. Possiamo farlo utilizzando un codificatore di immagini. Qui, utilizziamo un ResNet-18 preaddestrato per calcolare le incapsulazioni visive. Puoi scaricare le immagini qui [4].
Tracciando parallelismi con il testo, le incapsulazioni apprese dalle immagini trovano la similarità basandosi su caratteristiche visive simili. Ad esempio, le incapsulazioni visive potrebbero imparare a riconoscere l’orecchio, il naso e i baffi di un gatto, dandogli un punteggio di 0,81. D’altra parte, un cane ha caratteristiche visive diverse da un gatto, risultando in un punteggio di similarità più basso, pari a 0,50. Nota che potrebbe esserci un certo pregiudizio basato sulle immagini scelte, tuttavia, questo è il principio generale sottostante. Pertanto, le incapsulazioni visive mirano a utilizzare la vicinanza dei pixel delle immagini per stabilire una relazione significativa.

Applicazioni reali: Sistemi di raccomandazione, Recupero dell’immagine, Ricerca di similarità
III. Utilizzare diversi tipi di incapsulazioni per trovare elementi simili
In precedenza, abbiamo parlato di come le incapsulazioni siano un modo per rappresentare le informazioni di input in una forma compressa. Queste informazioni possono essere di qualsiasi tipo, che vanno da vari attributi di testo a attributi visivi e altro ancora. Naturalmente, più attributi possiamo utilizzare per descrivere un elemento, più forte è il segnale di similarità.
Prendiamo un esempio semplice e cerchiamo di capire insieme questo concetto. Di seguito, abbiamo un set di dati di cinque alimenti. Ho creato gli attributi io stesso e generato i colori dei campioni utilizzando la libreria Pillow (esplora lo script qui). Puoi scaricare i dati qui (immagini dei prodotti di [5]). Per ogni elemento, abbiamo 5 attributi testuali e 2 attributi visivi.
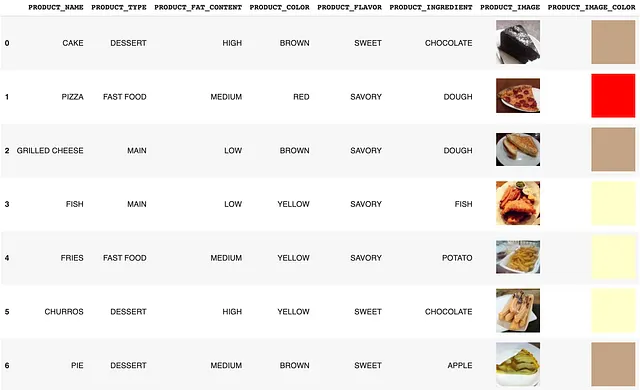
Per ciascuno di questi attributi, possiamo estrarre un vettore di incapsulazione che rappresenta quell’attributo specifico. Ora sorge una domanda naturale: come decidiamo cosa è simile? Ad esempio, abbiamo visto che due frasi possono essere simili, ma se dovessimo visualizzarle, sembrerebbero uguali? Al contrario, due animali potrebbero avere un punteggio simile perché assomigliano, ma se dovessimo caratterizzarli utilizzando le caratteristiche, sarebbero ancora simili? Qui sta l’opportunità di sfruttare diversi tipi di incapsulazioni disponibili per noi.
Iniziamo creando una singola caratteristica di testo chiamata ‘ATTRIBUTI_TESTUALI’ semplicemente unendo le parole. Nota che prendiamo un esempio semplice qui. Nei casi d’uso del mondo reale, dovremmo applicare tecniche avanzate di NLP per pulire i dati di testo prima della concatenazione.

I GIF seguenti mostrano cosa succede quando prendiamo in considerazione solo incapsulazioni testuali o incapsulazioni visive.


Entrambi gli approcci hanno i loro limiti, come descritto sopra. Pertanto, possiamo rivolgerci all’approccio ensemble nell’apprendimento automatico combinando gli embeddings sopra indicati per fornire il maggior numero possibile di informazioni sull’elemento. Questo ci aiuta a ottenere segnali di similarità più forti. Ad esempio, possiamo trovare elementi simili utilizzando gli embeddings testuali, delle immagini dei prodotti e del colore del prodotto.
Vediamo cosa succede quando combiniamo tutti gli embeddings!

Applicazioni reali: Sistemi di raccomandazione, Ricerca di sostituzione
IV. Utilizzare Diversi Pesi sugli Embeddings per Trovare Elementi Simili
Questo concetto si basa sul punto III ed è un’estensione più flessibile. Prendiamo in considerazione 3 scenari diversi come segue:
- Stai cercando un tostapane di ricambio da Costco. Desideri la stessa funzionalità del tuo vecchio tostapane. In questo caso, non ti interessa se il tostapane assomiglia al vecchio, ma ti interessa le caratteristiche che offre (ad esempio, le caratteristiche testuali). In questo caso, vorresti utilizzare solo gli embeddings testuali.
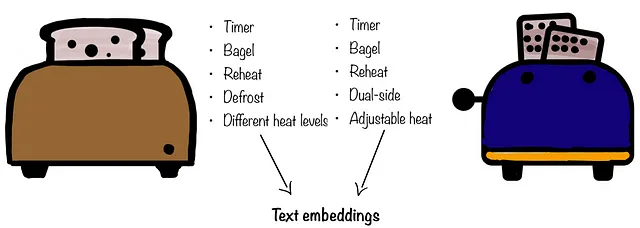
- Ho strappato i miei pantaloni preferiti e poiché li amo molto, desidero un sostituto che sia il più simile possibile. Sono disposto a sacrificare alcune delle caratteristiche che avevano i miei vecchi pantaloni, ma mi interessa l’estetica e come mi stavano addosso. In questo scenario, possiamo dare maggior peso agli embeddings visivi e un peso leggermente inferiore agli embeddings testuali.
- Se i dati forniti presentano determinati elementi di background come un modello umano, rischiamo di apprendere le caratteristiche del modello umano anziché del prodotto effettivo di nostro interesse. Nell’esempio qui sotto, vogliamo apprendere le caratteristiche della pallacanestro e non del modello che la tiene. In casi come questi, invece di utilizzare la segmentazione delle immagini, possiamo semplicemente dare un peso inferiore alle immagini del corpo intero e un peso maggiore agli attributi testuali e al colore del prodotto per catturare gli embeddings desiderati.
![Immagine di [6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*Fq9taYS1MDiiUFx-8m1fkQ.png)
In ognuno di questi casi, utilizzare pesi diversi ci dà il controllo su quali insiemi di embeddings sono importanti per noi e su come manipolarli. Questa idea può essere utilizzata per costruire sistemi flessibili per risolvere diversi tipi di problemi aziendali.
Applicazioni reali: Riduzione del bias, Sistemi di raccomandazione regolabili, Ricerca di similarità regolabile [7][8]
V. Mettere gli Embeddings di Immagini e Testo nello Stesso Spazio (Multimodale)
Fino ad ora, abbiamo considerato i dati testuali e visivi come input completamente separati. Il punto più vicino a cui siamo arrivati è stato combinare gli effetti nella fase di inferenza al punto III. Ma cosa succede se pensiamo al testo e alle immagini come oggetti? Come rappresentiamo collettivamente questi oggetti?
La risposta è la multimodalità e CLIP (Contrastive Language–Image Pre-training [9]). Se non sei sicuro di cosa significhi la multimodalità, semplicemente combina diversi tipi di dati (testo, immagine, audio, numerico) per effettuare previsioni più accurate. Utilizzando CLIP, possiamo rappresentare oggetti (in questo caso, testo o immagine) come vettori numerici (embeddings) per aiutare a proiettarli nello stesso spazio di embedding.
Il vero valore della natura multimodale di CLIP risiede nella traduzione di concetti simili in testo e immagini in vettori simili. Questi vettori vengono poi posizionati vicini tra loro a seconda di quanto sono simili. Ciò significa che se un testo cattura bene i concetti di un’immagine, viene posizionato più vicino a quella immagine. Allo stesso modo, se un’immagine è ben descritta da una frase, si trova vicina a quella frase. Nell’esempio qui sotto, il testo “cane che gioca in spiaggia” produce un embedding simile a quello di un’immagine di un cane che gioca in spiaggia.
![Oggetti simili (ad esempio, testo, immagini) sono codificati vicino l'uno all'altro nello spazio vettoriale. GIF dell'autore e immagini di [10]](https://miro.medium.com/v2/resize:fit:640/1*L-xy0aBKaJojlRXoXahs1g.gif)
Come si può vedere nell’illustrazione sopra, CLIP sblocca la capacità di muoversi attraverso il dominio del testo e dell’immagine combinando la semantica del testo con le immagini di un’immagine (da immagine a testo, da testo a immagine). Possiamo anche rimanere all’interno di un dominio specifico come da testo a testo o da immagine a immagine. Ciò apre la possibilità di potenti applicazioni che vanno dai sistemi di raccomandazione alle auto a guida autonoma, dalla classificazione dei documenti e altro ancora!
Permettici di dimostrare un esempio di testo-immagine utilizzando CLIP di HuggingFace. Utilizzeremo le immagini di cibi [5], come mostrato nel punto III. L’idea è di passare direttamente dal testo all’immagine.
Guarda il video qui sotto mentre ti guido attraverso una demo dal vivo o provaci tu stesso qui!
Vediamo alcuni risultati interessanti nella demo sopra! Il dataset contiene due immagini del dolce “cake”. Alla ricerca di “cake”, otteniamo prima un’immagine di una torta al cioccolato. Tuttavia, quando aggiungo parole chiave più descrittive come “red velvet”, mi restituisce una fetta di red velvet. Anche se entrambe queste immagini rappresentavano una torta in un certo senso, solo una di esse era una red velvet cake che il modello ha riconosciuto. Allo stesso modo, otteniamo un piatto di fish and chips quando cerchiamo “fish and chips” ma solo “chips” ci dà una scatola di patatine fritte. Il modello è anche in grado di differenziare tra patatine fritte e churros anche se sembrano molto simili.
Ora, facciamo un esempio di immagine-testo in modo simile. Qui, prendiamo esempi [4] dal punto II per classificare se un’immagine è di un cane o di un gatto.
Per ogni immagine, otteniamo la probabilità che il testo corrisponda all’immagine. Nel caso delle immagini di gatti, l’etichetta “gatto” ha una probabilità alta. D’altra parte, l’immagine del cane viene classificata come “cane”.

Applicazioni del mondo reale: Testo-immagine (Ricerca), Immagine-immagine (Similarità), Immagine-testo (Classificazione)
Nella seconda parte della serie, esamineremo ulteriori applicazioni che vanno dall’arte a visualizzazioni interessanti. Resta sintonizzato!
Se hai trovato utile questo articolo, e credi che anche gli altri lo farebbero, lascia un applauso! Se desideri rimanere in contatto, mi troverai su LinkedIn qui.
Zubia è una Senior Machine Learning Scientist e lavora sulla scoperta dei prodotti, personalizzazione e design generativo nel settore della moda. È mentore, istruttrice e relatrice su argomenti legati alla computer vision, data science, donne/donne di colore in STEM e carriera nel campo tecnologico.
Riferimenti
[1]: Definizione degli embeddings
[2]: Spiegazione degli embeddings
[3]: Motore di ricerca di Google che utilizza l’encoder di testo BERT
[4]: Immagini da Dogs vs. Cats (Kaggle)
[5]: Immagini da Food Images (Food-101)
[6]: Foto di Malik Skydsgaard su Unsplash
[7]: Combinazione di diversi tipi di embeddings
[8]: Embeddings per i sistemi di raccomandazione
[9]: CLIP di OpenAI
[10]: Immagini di Oscar Sutton, Hossein Azarbad su Unsplash
[11]: Blog di CLIP






