Apprendimento automatico su larga scala parallelismo del modello rispetto al parallelismo dei dati
Apprendimento automatico su larga scala e parallelismo dei dati
Decodifica i segreti del Machine Learning su larga scala
Introduzione
Man mano che i modelli diventano sempre più complessi e i dataset diventano giganteschi, la necessità di modi efficienti per distribuire i carichi di lavoro computazionali è più importante che mai. I setup vecchio stile con un solo computer non possono stare al passo con le esigenze di calcolo del Machine Learning di oggi.
Domanda importante: come possiamo distribuire in modo efficace questi complessi lavori di machine learning (allenamento e inferenza del modello) su risorse di calcolo multiple?
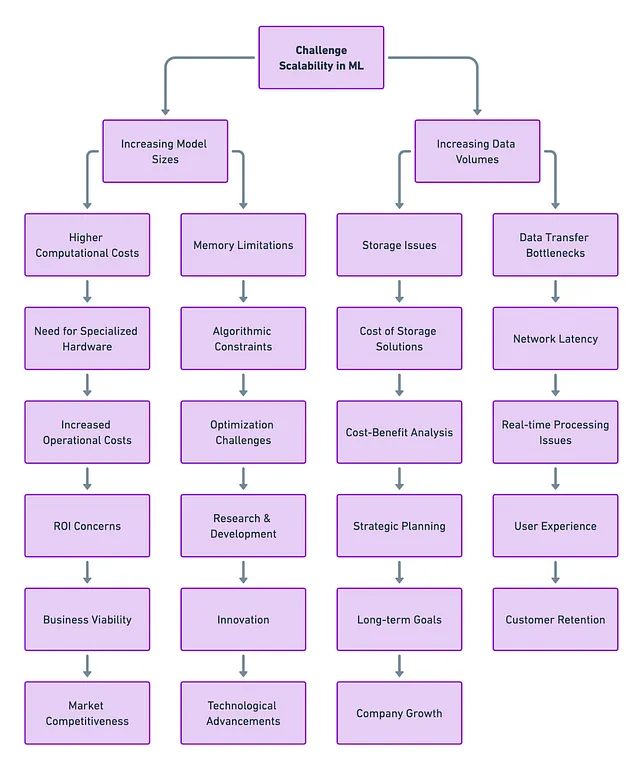
La risposta si trova in due tecniche chiave del calcolo distribuito del Machine Learning: Parallelismo del Modello e Parallelismo dei Dati. Ognuna di esse ha i suoi punti di forza, debolezze e casi d’uso ideali. In questo articolo, ci immergeremo in queste tecniche, esplorandone le sfumature e confrontandole tra loro.
Che cos’è il Parallelismo del Modello e il Parallelismo dei Dati?
Parallelismo del Modello
Questo metodo prevede la distribuzione delle diverse parti del modello di machine learning su risorse di calcolo multiple, come le GPU. È il rimedio perfetto per quei modelli sovradimensionati che non possono entrare nella memoria di un singolo computer.
- IA e il futuro del football universitario
- ElevenLabs rilascia Eleven Multilingual v2 un modello di intelligenza artificiale per la sintesi vocale che supporta 30 lingue.
- Creazione di un’immagine Docker semplice per la scienza dei dati
Parallelismo dei Dati
D’altra parte, il parallelismo dei dati mantiene il modello su ogni macchina, ma distribuisce il dataset in frammenti o batch più piccoli su risorse multiple. Questa tecnica è utile quando si hanno grandi dataset ma modelli che si adattano facilmente alla memoria.
Parallelismo del Modello: Un’Analisi Approfondita
Quando usarlo?
Hai mai provato a caricare una grande rete neurale sulla tua GPU e hai ricevuto un temuto errore di “memoria esaurita”? È come cercare di inserire un tassello quadrato in un foro rotondo. Questo semplicemente non funzionerà. Ma non preoccuparti, il parallelismo del modello è qui per aiutarti.
Come funziona?
Immagina che la tua rete neurale sia come un edificio multistorey, con ogni piano che rappresenta uno strato della rete. Ora, cosa succederebbe se potessi mettere ogni piano di quell’edificio su un pezzo di terreno diverso (o nel nostro caso, una GPU diversa)? In questo modo, non stai cercando di impilare tutto il grattacielo su un piccolo terreno. Tecnicamente parlando, ciò significa suddividere il tuo modello e mettere parti diverse su diverse GPU.
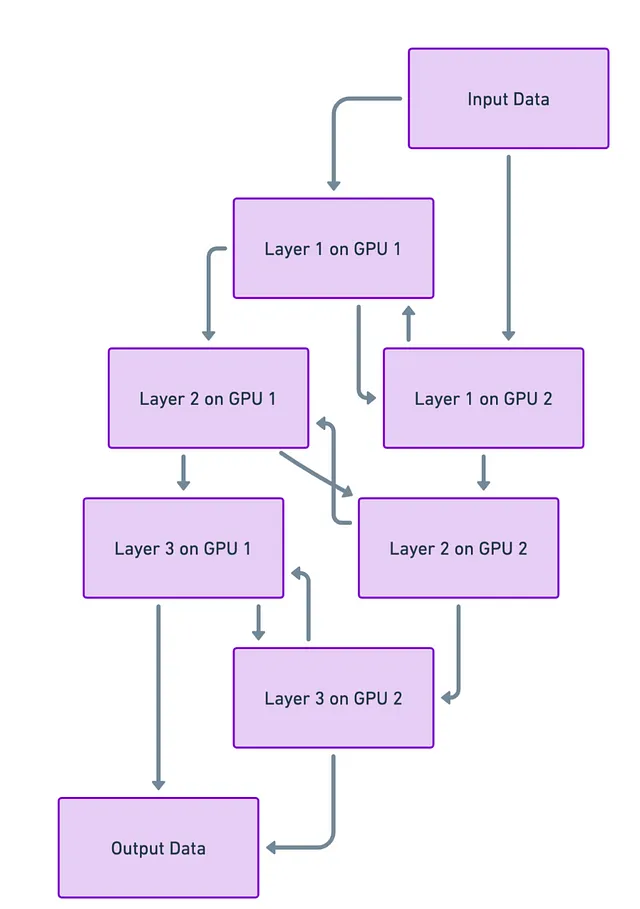
Sfide
Ma non è tutto rose e fiori. Quando suddividi l’edificio, o la rete neurale, hai comunque bisogno di scale ed ascensori (o percorsi dei dati) per spostarti tra i piani (strati). E a volte, questi possono intasarsi. In altre parole, la sfida principale è far comunicare rapidamente e senza intoppi le diverse parti tra loro. Se questa comunicazione è lenta, può rallentare l’intero processo di apprendimento o “allenamento” del modello.
Parallelismo dei Dati: Un’Analisi Approfondita
Quando usarlo?
Immagina di avere un mucchio di dati molto grande, ma il tuo modello di machine learning non è troppo complesso. In questo caso, il parallelismo dei dati è come il frullatore da cucina a cui ricorrere; può gestire facilmente tutti gli ingredienti che ci metti senza essere sopraffatto.
Come Funziona?
Pensa ad ogni computer o GPU come a una cucina separata con il proprio frullatore (il modello). Prendi il tuo grande mucchio di dati e lo dividi in porzioni più piccole. Ogni “cucina” ottiene una piccola porzione di dati e il proprio frullatore per lavorare su quei dati. In questo modo, diverse cucine stanno preparando frullati (calcolando i gradienti) contemporaneamente.
Dopo che ogni cucina ha finito di frullare, riporti tutti i frullati in un unico posto. Li mescoli insieme per ottenere un gigantesco frullato perfettamente amalgamato (aggiornando il modello basato su tutti i calcoli individuali).
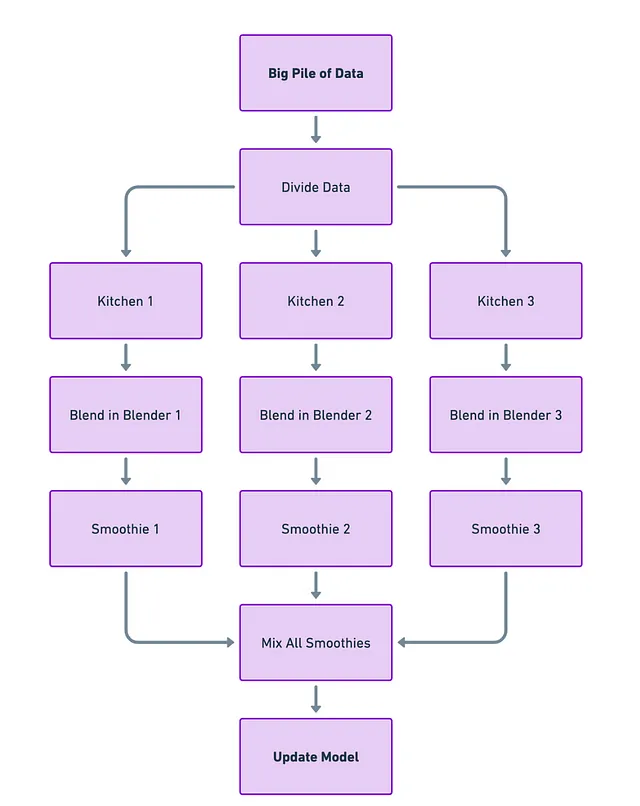
Sfide
La parte complicata è l’ultimo passaggio: mescolare tutti quei frullati in modo efficiente. Se sei lento o disordinato nel combinarli, non solo perderai tempo ma potresti anche ottenere un frullato finale non così buono (addestramento inefficiente del modello). Quindi, la sfida è riportare tutto insieme in modo efficiente e rapido possibile.
In termini tecnici, questo significa che devi trovare un modo veloce per raccogliere tutti i gradienti calcolati da ogni GPU e aggiornare il modello. Se non lo fai bene, il tuo modello potrebbe impiegare più tempo per addestrarsi o addirittura funzionare male quando inizi a usarlo per compiti reali.
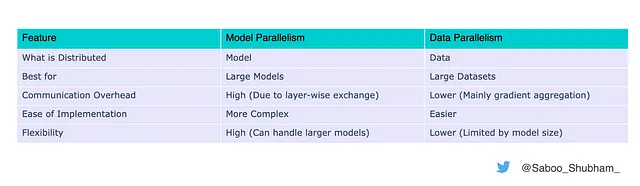
Sommario delle Differenze
Perché Non Entrambi?
Nel sempre complesso panorama del machine learning, una misura raramente è adatta a tutti. Una combinazione sinergica di parallelismo del modello e del parallelismo dei dati viene spesso utilizzata per ottenere risultati ottimali. Ad esempio, potresti suddividere un grande modello tra diverse GPU (parallelismo del modello) e quindi distribuire i dati a ciascuna di queste configurazioni parallele (parallelismo dei dati).
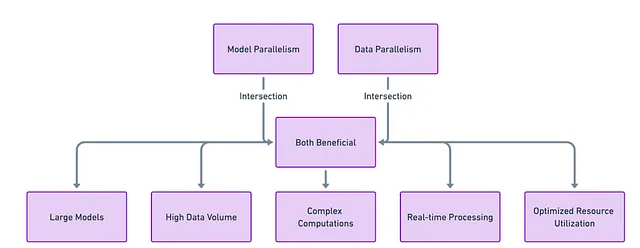
Una combinazione di parallelismo del modello e del parallelismo dei dati è spesso la chiave per perfezionare la tua “ricetta” per il machine learning.
L’analogia del Fornello a Gas per il Machine Learning
In questa analogia, il fornello a gas è come una singola GPU o un computer. Ha sia un forno che un piano cottura, che puoi utilizzare contemporaneamente per diverse operazioni di cottura.
Forno = Parallelismo del Modello
Se hai un tacchino troppo grande per entrare nel forno, potresti tagliarlo in pezzi più piccoli da cucinare separatamente, ad esempio il petto in una sezione del forno e le gambe in un’altra. Questo è simile al parallelismo del modello, dove un grande modello è diviso tra diverse GPU. In questo caso, i compartimenti del forno di un singolo fornello a gas rappresentano parti di una GPU o una risorsa di calcolo.
Piano Cottura = Parallelismo dei Dati
Adesso, supponiamo che tu stia cucinando diversi contorni sui fornelli del piano cottura. Puoi preparare le patate schiacciate su un fornello mentre le fagiolini stanno soffriggendo su un altro. Qui, ogni fornello rappresenta un approccio di parallelismo dei dati, in cui diverse porzioni dei dati vengono processate indipendentemente ma all’interno della stessa GPU o ambiente di calcolo.
Combinare Entrambi per una Festa
Infine, per completare la tua festa, useresti sia il forno che il piano cottura contemporaneamente. Le parti del tacchino sono nel forno (parallelismo del modello), mentre i contorni sono sul piano cottura (parallelismo dei dati). Una volta terminata la cottura, unisci tutte le parti del tacchino e i contorni per servire un pasto completo. Allo stesso modo, nel machine learning, combinare il parallelismo del modello e il parallelismo dei dati ti permette di elaborare in modo efficiente modelli grandi e grandi dataset, ottenendo infine un modello addestrato con successo.
Sfruttando sia il ‘forno’ che il ‘fornello’ nella tua ‘cucina’ di machine learning, puoi cucinare in modo più efficiente i tuoi dati e modelli, facendo il miglior uso di tutte le risorse che hai a disposizione.
Conclusione
Man mano che il campo del machine learning continua a evolversi, l’importanza delle tecniche come il parallelismo di modelli e dati crescerà solo e diventerà sempre più rilevante nei carichi di lavoro di machine learning quotidiani. Comprendere le sfumature di entrambi è fondamentale per chiunque voglia sviluppare e implementare modelli di machine learning su larga scala come LLMs, Stable Diffusion, ecc.
Scegliendo la tecnica giusta o una combinazione di entrambe, puoi superare le sfide del machine learning moderno e sbloccare la scalabilità e l’efficienza per i tuoi carichi di lavoro di machine learning.
Interessato a rimanere aggiornato sulle ultime novità del machine learning? Segui il mio percorso per essere sempre aggiornato con gli sviluppi freschi e all’avanguardia dell’IA 👇
Connettiti con me: LinkedIn | Twitter | Github

Se ti è piaciuto questo post o lo hai trovato utile, per favore prenditi un minuto per premere il pulsante di applauso, aumenta la visibilità del post per gli altri utenti di VoAGI.






