Abilita le metriche GPU basate su pod in Amazon CloudWatch
Abilita metriche GPU per pod in Amazon CloudWatch
A febbraio 2022, Amazon Web Services ha aggiunto il supporto per le metriche delle GPU NVIDIA in Amazon CloudWatch, rendendo possibile inviare metriche dall’Agente Amazon CloudWatch ad Amazon CloudWatch e monitorare il tuo codice per un utilizzo ottimale delle GPU. Da allora, questa funzionalità è stata integrata in molte delle nostre immagini gestite di Amazon Machine Images (AMI), come ad esempio l’AMI Deep Learning e l’AMI AWS ParallelCluster. Per ottenere metriche di utilizzo delle GPU a livello di istanza, puoi utilizzare Packer o Amazon ImageBuilder per avviare la tua AMI personalizzata e utilizzarla in varie offerte di servizi gestiti come AWS Batch, Amazon Elastic Container Service (Amazon ECS) o Amazon Elastic Kubernetes Service (Amazon EKS). Tuttavia, per molte offerte di servizi e carichi di lavoro basati su container, è ideale acquisire metriche di utilizzo a livello di container, pod o namespace.
In questo post viene descritto come configurare le metriche delle GPU basate su container e fornisce un esempio di raccolta di queste metriche dai pod EKS.
Panoramica della soluzione
Per dimostrare le metriche delle GPU basate su container, creiamo un cluster EKS con istanze g5.2xlarge; tuttavia, questo funzionerà con qualsiasi famiglia di istanze NVIDIA accelerate supportata.
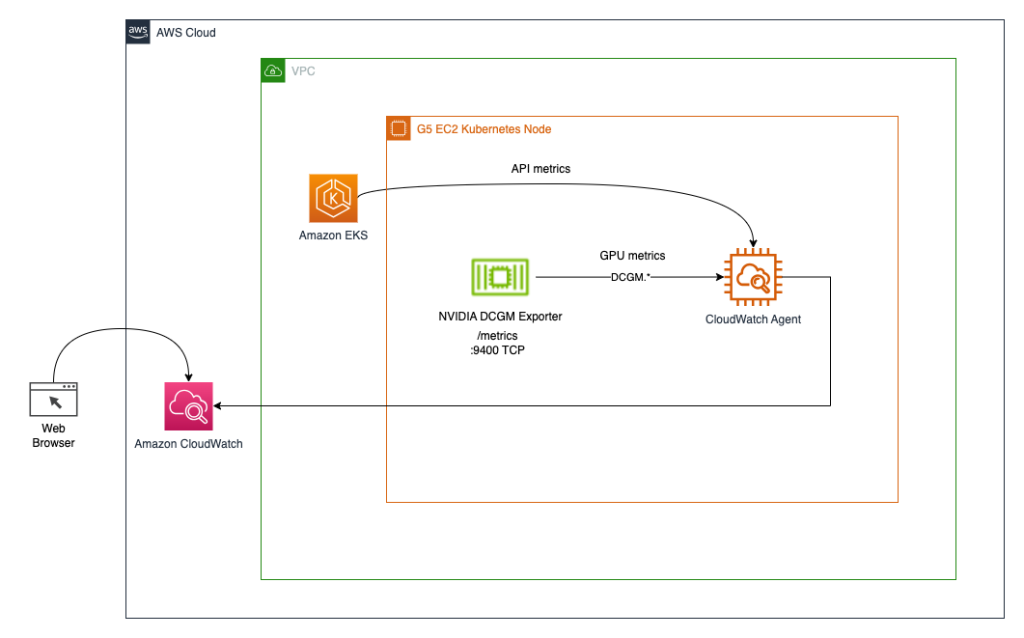
Deployiamo l’operatore GPU NVIDIA per abilitare l’uso delle risorse GPU e l’Export DCGM NVIDIA per abilitare la raccolta delle metriche delle GPU. Esploreremo quindi due architetture. La prima connette le metriche da Export DCGM NVIDIA a CloudWatch tramite un agente CloudWatch, come mostrato nel diagramma seguente.
- Ottimizza le prestazioni dell’attrezzatura con dati storici, Ray e Amazon SageMaker
- Come le industrie stanno soddisfacendo le aspettative dei consumatori con l’intelligenza artificiale vocale
- Decodifica del linguaggio parlato
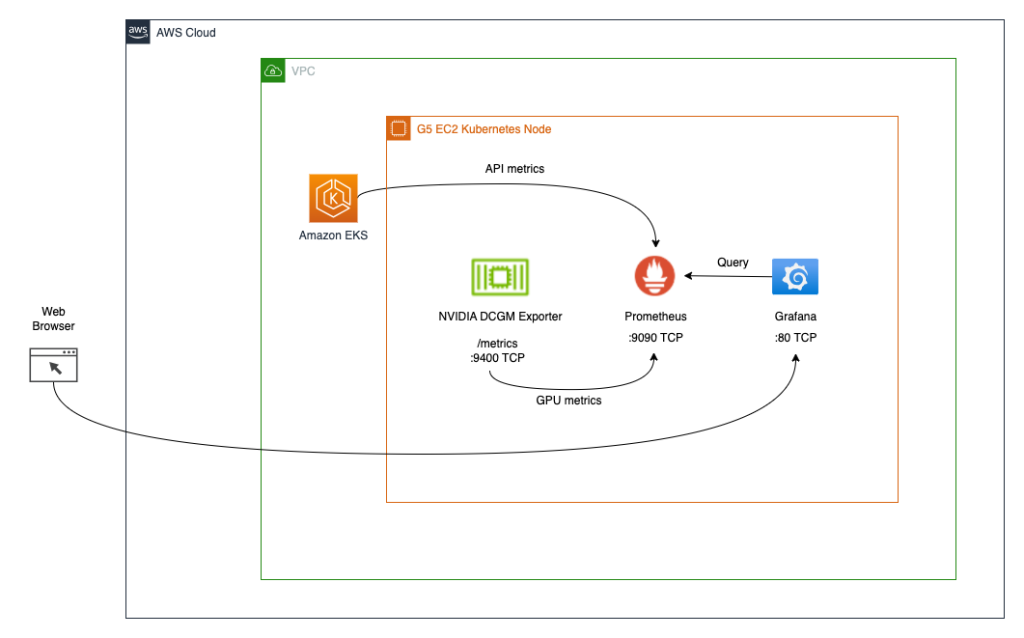
La seconda architettura (vedi il diagramma seguente) connette le metriche da Export DCGM NVIDIA a Prometheus, quindi utilizziamo un dashboard Grafana per visualizzare tali metriche.
Prerequisiti
Per semplificare la riproduzione dell’intero stack da questo post, utilizziamo un container che ha già installati tutti gli strumenti necessari (aws cli, eksctl, helm, ecc.). Per clonare il progetto del container da GitHub, è necessario git. Per creare e eseguire il container, è necessario Docker. Per distribuire l’architettura, è necessario disporre di credenziali AWS. Per abilitare l’accesso ai servizi Kubernetes tramite port-forwarding, sarà anche necessario kubectl.
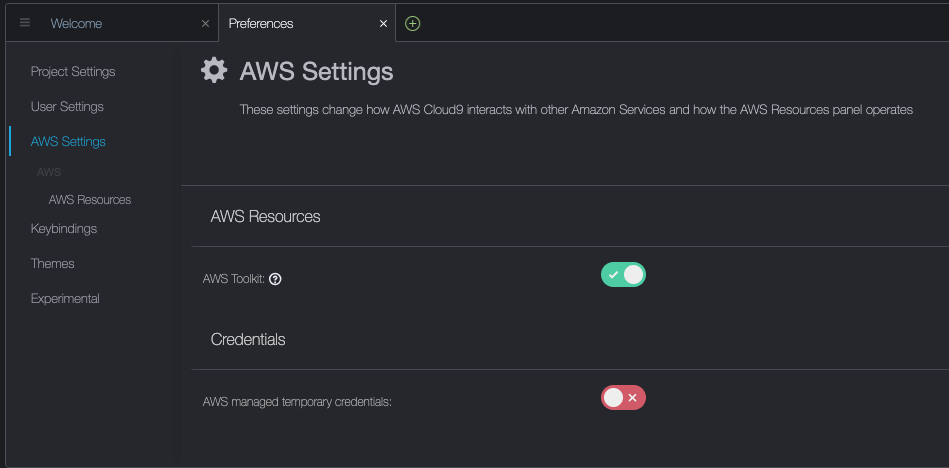
Questi prerequisiti possono essere installati sulla macchina locale, su un’istanza EC2 con NICE DCV o su AWS Cloud9. In questo post, utilizzeremo un’istanza Cloud9 c5.2xlarge con un volume di archiviazione locale di 40GB. Quando si utilizza Cloud9, disabilitare le credenziali temporanee gestite da AWS visitando Cloud9->Preferences->AWS Settings come mostrato nella schermata di seguito.
Compila ed esegui il container aws-do-eks
Apri una shell del terminale nel tuo ambiente preferito e esegui i seguenti comandi:
git clone https://github.com/aws-samples/aws-do-eks
cd aws-do-eks
./build.sh
./run.sh
./exec.shIl risultato è il seguente:
root@e5ecb162812f:/eks#Ora hai una shell in un ambiente di container che dispone di tutti gli strumenti necessari per completare i compiti seguenti. Ci riferiremo ad esso come “shell aws-do-eks”. Eseguirai i comandi nelle sezioni seguenti in questa shell, a meno che specificamente indicato diversamente.
Crea un cluster EKS con un gruppo di nodi
Questo gruppo include una famiglia di istanze GPU a tua scelta; in questo esempio, utilizziamo il tipo di istanza g5.2xlarge.
Il progetto aws-do-eks viene fornito con una raccolta di configurazioni del cluster. Puoi impostare la configurazione del cluster desiderata con una singola modifica della configurazione.
- Nella shell del container, esegui
./env-config.she quindi impostaCONF=conf/eksctl/yaml/eks-gpu-g5.yaml - Per verificare la configurazione del cluster, esegui
./eks-config.sh
Dovresti vedere il seguente manifesto del cluster:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-g5
version: "1.25"
region: us-east-1
availabilityZones:
- us-east-1a
- us-east-1b
- us-east-1c
- us-east-1d
managedNodeGroups:
- name: sys
instanceType: m5.xlarge
desiredCapacity: 1
iam:
withAddonPolicies:
autoScaler: true
cloudWatch: true
- name: g5
instanceType: g5.2xlarge
instancePrefix: g5-2xl
privateNetworking: true
efaEnabled: false
minSize: 0
desiredCapacity: 1
maxSize: 10
volumeSize: 80
iam:
withAddonPolicies:
cloudWatch: true
iam:
withOIDC: true- Per creare il cluster, esegui il seguente comando nel container
./eks-create.shL’output è il seguente:
root@e5ecb162812f:/eks# ./eks-create.sh
/eks/impl/eksctl/yaml /eks
./eks-create.sh
Lun 22 Mag 20:50:59 UTC 2023
Creazione del cluster usando /eks/conf/eksctl/yaml/eks-gpu-g5.yaml ...
eksctl create cluster -f /eks/conf/eksctl/yaml/eks-gpu-g5.yaml
2023-05-22 20:50:59 [ℹ] versione eksctl 0.133.0
2023-05-22 20:50:59 [ℹ] utilizzo della regione us-east-1
2023-05-22 20:50:59 [ℹ] subnet per us-east-1a - pubblica:192.168.0.0/19 privata:192.168.128.0/19
2023-05-22 20:50:59 [ℹ] subnet per us-east-1b - pubblica:192.168.32.0/19 privata:192.168.160.0/19
2023-05-22 20:50:59 [ℹ] subnet per us-east-1c - pubblica:192.168.64.0/19 privata:192.168.192.0/19
2023-05-22 20:50:59 [ℹ] subnet per us-east-1d - pubblica:192.168.96.0/19 privata:192.168.224.0/19
2023-05-22 20:50:59 [ℹ] il gruppo di nodi "sys" utilizzerà "" [AmazonLinux2/1.25]
2023-05-22 20:50:59 [ℹ] il gruppo di nodi "g5" utilizzerà "" [AmazonLinux2/1.25]
2023-05-22 20:50:59 [ℹ] utilizzo della versione Kubernetes 1.25
2023-05-22 20:50:59 [ℹ] creazione del cluster EKS "do-eks-yaml-g5- Per verificare che il tuo cluster sia stato creato con successo, esegui il seguente comando
kubectl get nodes -L node.kubernetes.io/instance-type
L'output sarà simile al seguente:
NOME STATO RUOLI ETÀ VERSIONE TIPO_ISTANZA
ip-192-168-18-137.ec2.internal Pronto <nessuno> 47m v1.25.9-eks-0a21954 m5.xlarge
ip-192-168-214-241.ec2.internal Pronto <nessuno> 46m v1.25.9-eks-0a21954 g5.2xlarge
In questo esempio, abbiamo un'istanza m5.xlarge e un'istanza g5.2xlarge nel nostro cluster; quindi vediamo due nodi elencati nell'output precedente.
Durante il processo di creazione del cluster, verrà installato il plugin del dispositivo NVIDIA. Dovrai rimuoverlo dopo la creazione del cluster perché useremo invece l'operatore NVIDIA GPU.
- Elimina il plugin con il seguente comando
kubectl -n kube-system delete daemonset nvidia-device-plugin-daemonset
Ottieni il seguente output:
daemonset.apps "nvidia-device-plugin-daemonset" eliminato
Installa il repo Helm di NVIDIA
Installa il repo Helm di NVIDIA con il seguente comando:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
Esegui il deploy di DCGM exporter con NVIDIA GPU Operator
Per eseguire il deploy di DCGM exporter, segui i seguenti passaggi:
- Prepara la configurazione delle metriche della GPU per DCGM exporter
curl https://raw.githubusercontent.com/NVIDIA/dcgm-exporter/main/etc/dcp-metrics-included.csv > dcgm-metrics.csv
Hai la possibilità di modificare il file dcgm-metrics.csv. Puoi aggiungere o rimuovere le metriche desiderate.
- Crea il namespace gpu-operator e il ConfigMap di DCGM exporter
kubectl create namespace gpu-operator && /
kubectl create configmap metrics-config -n gpu-operator --from-file=dcgm-metrics.csv
L'output sarà il seguente:
namespace/gpu-operator creato
configmap/metrics-config creato
- Applica l'operatore GPU al cluster EKS
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator \
--set dcgmExporter.config.name=metrics-config \
--set dcgmExporter.env[0].name=DCGM_EXPORTER_COLLECTORS \
--set dcgmExporter.env[0].value=/etc/dcgm-exporter/dcgm-metrics.csv \
--set toolkit.enabled=false
L'output sarà il seguente:
NOME: gpu-operator-1684795140
ULTIMO DEPLOYMENT: Giorno Mese Data HH:mm:ss YYYY
NAMESPACE: gpu-operator
STATO: deployato
REVISIONE: 1
TEST: Nessuno
- Verifica che il pod di DCGM exporter sia in esecuzione
kubectl -n gpu-operator get pods | grep dcgm
L'output sarà il seguente:
nvidia-dcgm-exporter-lkmfr 1/1 In esecuzione 0 1m
Se controlli i log, dovresti vedere il messaggio “Starting webserver”:
kubectl -n gpu-operator logs -f $(kubectl -n gpu-operator get pods | grep dcgm | cut -d ' ' -f 1)
L'output sarà il seguente:
Defaulted container "nvidia-dcgm-exporter" out of: nvidia-dcgm-exporter, toolkit-validation (init)
time="2023-05-22T22:40:08Z" level=info msg="Starting dcgm-exporter"
time="2023-05-22T22:40:08Z" level=info msg="DCGM successfully initialized!"
time="2023-05-22T22:40:08Z" level=info msg="Collecting DCP Metrics"
time="2023-05-22T22:40:08Z" level=info msg="No configmap data specified, falling back to metric file /etc/dcgm-exporter/dcgm-metrics.csv"
time="2023-05-22T22:40:08Z" level=info msg="Initializing system entities of type: GPU"
time="2023-05-22T22:40:09Z" level=info msg="Initializing system entities of type: NvSwitch"
time="2023-05-22T22:40:09Z" level=info msg="Not collecting switch metrics: no switches to monitor"
time="2023-05-22T22:40:09Z" level=info msg="Initializing system entities of type: NvLink"
time="2023-05-22T22:40:09Z" level=info msg="Not collecting link metrics: no switches to monitor"
time="2023-05-22T22:40:09Z" level=info msg="Kubernetes metrics collection enabled!"
time="2023-05-22T22:40:09Z" level=info msg="Pipeline starting"
time="2023-05-22T22:40:09Z" level=info msg="Starting webserver"
NVIDIA DCGM Exporter espone un endpoint di metriche Prometheus, che può essere inglobato dall'agente CloudWatch. Per visualizzare l'endpoint, utilizza il comando seguente:
kubectl -n gpu-operator get services | grep dcgm
Ottieni l'output seguente:
nvidia-dcgm-exporter ClusterIP 10.100.183.207 <none> 9400/TCP 10m
- Per generare una certa utilizzazione della GPU, distribuiamo un pod che esegue il binario gpu-burn
kubectl apply -f https://raw.githubusercontent.com/aws-samples/aws-do-eks/main/Container-Root/eks/deployment/gpu-metrics/gpu-burn-deployment.yaml
L'output è il seguente:
deployment.apps/gpu-burn creato
Questo deployment utilizza una singola GPU per produrre un pattern continuo di utilizzo del 100% per 20 secondi seguito da un utilizzo del 0% per 20 secondi.
- Per verificare che l'endpoint funzioni, puoi eseguire un container temporaneo che utilizza curl per leggere il contenuto di
http://nvidia-dcgm-exporter:9400/metrics</li
Configurare e distribuire l'agente CloudWatch
Per configurare e distribuire l'agente CloudWatch, seguire i seguenti passaggi:
- Scaricare il file YAML e modificarlo
curl -O https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/k8s/1.3.15/k8s-deployment-manifest-templates/deployment-mode/service/cwagent-prometheus/prometheus-eks.yaml
Il file contiene una configmap di cwagent e una configmap di prometheus. Per questo post, modifichiamo entrambe.
- Modificare il file
prometheus-eks.yaml
Aprire il file prometheus-eks.yaml nel proprio editor preferito e sostituire la sezione cwagentconfig.json con il seguente contenuto:
apiVersion: v1
data:
# cwagent json config
cwagentconfig.json: |
{
"logs": {
"metrics_collected": {
"prometheus": {
"prometheus_config_path": "/etc/prometheusconfig/prometheus.yaml",
"emf_processor": {
"metric_declaration": [
{
"source_labels": ["Service"],
"label_matcher": ".*dcgm.*",
"dimensions": [["Service","Namespace","ClusterName","job","pod"]],
"metric_selectors": [
"^DCGM_FI_DEV_GPU_UTIL$",
"^DCGM_FI_DEV_DEC_UTIL$",
"^DCGM_FI_DEV_ENC_UTIL$",
"^DCGM_FI_DEV_MEM_CLOCK$",
"^DCGM_FI_DEV_MEM_COPY_UTIL$",
"^DCGM_FI_DEV_POWER_USAGE$",
"^DCGM_FI_DEV_ROW_REMAP_FAILURE$",
"^DCGM_FI_DEV_SM_CLOCK$",
"^DCGM_FI_DEV_XID_ERRORS$",
"^DCGM_FI_PROF_DRAM_ACTIVE$",
"^DCGM_FI_PROF_GR_ENGINE_ACTIVE$",
"^DCGM_FI_PROF_PCIE_RX_BYTES$",
"^DCGM_FI_PROF_PCIE_TX_BYTES$",
"^DCGM_FI_PROF_PIPE_TENSOR_ACTIVE$"
]
}
]
}
}
},
"force_flush_interval": 5
}
}
- Nella sezione di configurazione
prometheus, aggiungere la seguente definizione del job per l'esportatore DCGM
- job_name: 'kubernetes-pod-dcgm-exporter'
sample_limit: 10000
metrics_path: /api/v1/metrics/prometheus
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_container_name]
action: keep
regex: '^DCGM.*$'
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: ${1}:9400
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: Namespace
- source_labels: [__meta_kubernetes_pod]
action: replace
target_label: pod
- action: replace
source_labels:
- __meta_kubernetes_pod_container_name
target_label: container_name
- action: replace
source_labels:
- __meta_kubernetes_pod_controller_name
target_label: pod_controller_name
- action: replace
source_labels:
- __meta_kubernetes_pod_controller_kind
target_label: pod_controller_kind
- action: replace
source_labels:
- __meta_kubernetes_pod_phase
target_label: pod_phase
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: NodeName
- Salvare il file e applicare la configurazione
cwagent-dcgm al proprio cluster
kubectl apply -f ./prometheus-eks.yaml
Si otterrà il seguente output:
namespace/amazon-cloudwatch created
configmap/prometheus-cwagentconfig created
configmap/prometheus-config created
serviceaccount/cwagent-prometheus created
clusterrole.rbac.authorization.k8s.io/cwagent-prometheus-role created
clusterrolebinding.rbac.authorization.k8s.io/cwagent-prometheus-role-binding created
deployment.apps/cwagent-prometheus created
- Verifica che il pod dell'agente CloudWatch sia in esecuzione
kubectl -n amazon-cloudwatch get pods
Otteniamo il seguente output:
NOME PRONTO STATO RIAVVII ETA'
cwagent-prometheus-7dfd69cc46-s4cx7 1/1 In esecuzione 0 15m
Visualizza le metriche sulla console di CloudWatch
Per visualizzare le metriche in CloudWatch, completa i seguenti passaggi:
- Nella console di CloudWatch, sotto Metriche nel riquadro di navigazione, scegli Tutte le metriche
- Nella sezione Namespace personalizzati, scegli la nuova voce per ContainerInsights/Prometheus
Per ulteriori informazioni sul namespace ContainerInsights/Prometheus, consulta la sezione Scraping di ulteriori fonti Prometheus e importazione di tali metriche.
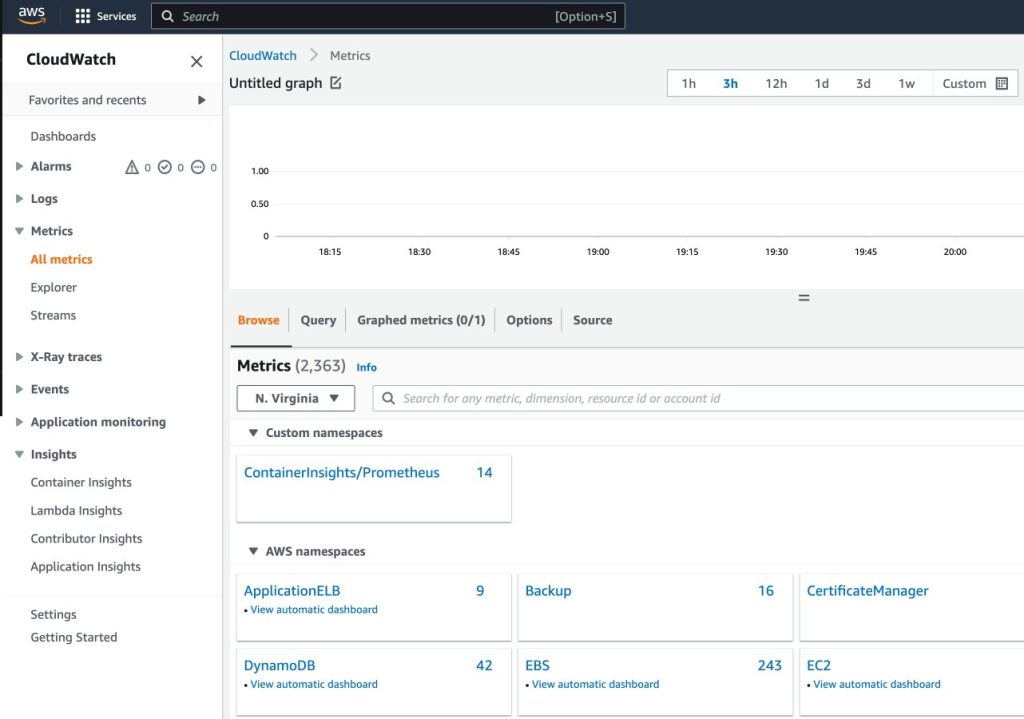
- Approfondisci i nomi delle metriche e scegli
DCGM_FI_DEV_GPU_UTIL
- Nella scheda Metriche graficate, imposta Periodo su 5 secondi

- Imposta l'intervallo di aggiornamento su 10 secondi
Vedrai le metriche raccolte dall'esportatore DCGM che visualizzano il modello gpu-burn acceso e spento ogni 20 secondi.
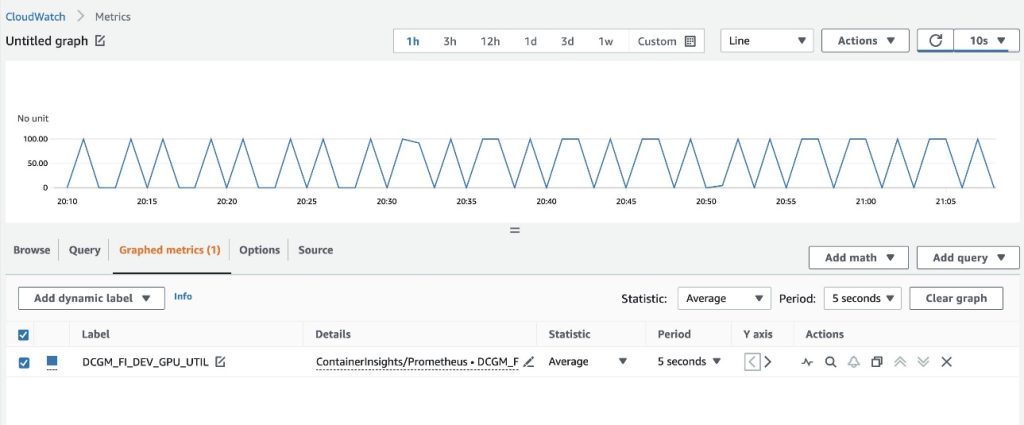
Nella scheda Sfoglia, puoi vedere i dati, inclusi il nome del pod per ogni metrica.
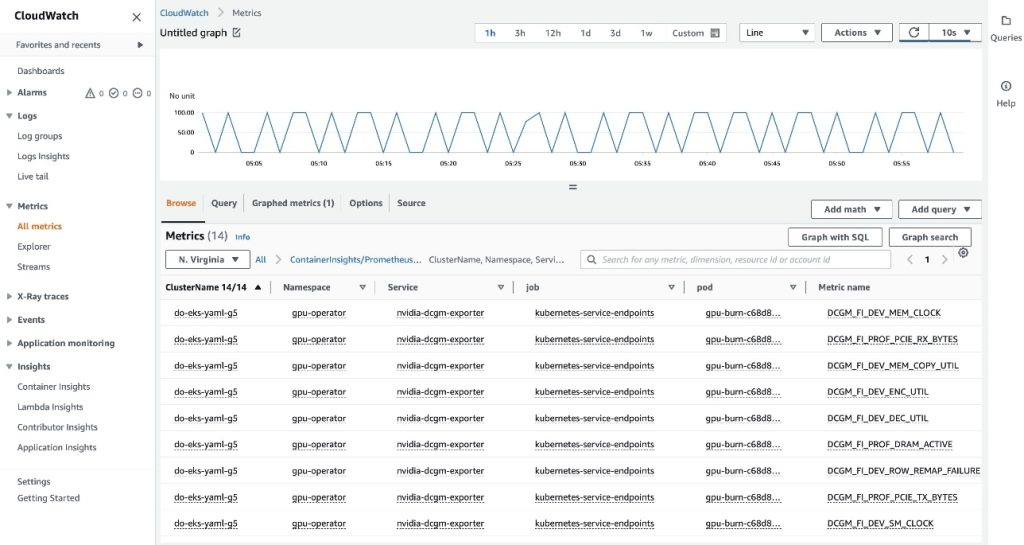
I metadati dell'API EKS sono stati combinati con i dati delle metriche DCGM, ottenendo le metriche GPU basate su pod fornite.
Questo conclude il primo approccio per l'esportazione delle metriche DCGM su CloudWatch tramite l'agente CloudWatch.
Nella sezione successiva, configureremo la seconda architettura, che esporta le metriche DCGM su Prometheus e le visualizziamo con Grafana.
Usa Prometheus e Grafana per visualizzare le metriche GPU da DCGM
Completa i seguenti passaggi:
- Aggiungi il chart helm della community di Prometheus
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
Questo chart distribuisce sia Prometheus che Grafana. Dobbiamo apportare alcune modifiche al chart prima di eseguire il comando di installazione.
- Salva i valori di configurazione del chart in un file in
/tmp
helm inspect values prometheus-community/kube-prometheus-stack > /tmp/kube-prometheus-stack.values
- Modifica il file di configurazione del chart
Modifica il file salvato (/tmp/kube-prometheus-stack.values) e imposta l'opzione seguente cercando il nome dell'impostazione e impostando il valore:
prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
- Aggiungi il seguente ConfigMap alla sezione
additionalScrapeConfigs
additionalScrapeConfigs:
- job_name: gpu-metrics
scrape_interval: 1s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- gpu-operator
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
- Effettua il deploy dello stack Prometheus con i valori aggiornati
helm install prometheus-community/kube-prometheus-stack \
--create-namespace --namespace prometheus \
--generate-name \
--values /tmp/kube-prometheus-stack.values
Ottieni il seguente output:
NOME: kube-prometheus-stack-1684965548
ULTIMO DEPLOYMENT: Mercoledì 24 Maggio 2023 21:59:14
NAMESPACE: prometheus
STATO: deployato
REVISIONE: 1
NOTE:
kube-prometheus-stack è stato installato. Verifica il suo stato eseguendo il comando:
kubectl --namespace prometheus get pods -l "release=kube-prometheus-stack-1684965548"
Visita https://github.com/prometheus-operator/kube-prometheus
per le istruzioni su come creare e configurare Alertmanager
e le istanze di Prometheus utilizzando l'Operatore.
- Verifica che i pod di Prometheus siano in esecuzione
kubectl get pods -n prometheus
Ottieni il seguente output:
NOME PRONTO STATO RIAVVI ETA'
alertmanager-kube-prometheus-stack-1684-alertmanager-0 2/2 In esecuzione 0 6m55s
kube-prometheus-stack-1684-operator-6c87649878-j7v55 1/1 In esecuzione 0 6m58s
kube-prometheus-stack-1684965548-grafana-dcd7b4c96-bzm8p 3/3 In esecuzione 0 6m58s
kube-prometheus-stack-1684965548-kube-state-metrics-7d856dptlj5 1/1 In esecuzione 0 6m58s
kube-prometheus-stack-1684965548-prometheus-node-exporter-2fbl5 1/1 In esecuzione 0 6m58s
kube-prometheus-stack-1684965548-prometheus-node-exporter-m7zmv 1/1 In esecuzione 0 6m58s
prometheus-kube-prometheus-stack-1684-prometheus-0 2/2 In esecuzione 0 6m55s
I pod di Prometheus e Grafana sono nello stato In esecuzione.
Successivamente, verifichiamo che le metriche DCGM stiano fluendo in Prometheus.
- Esegui il port-forwarding dell'interfaccia utente di Prometheus
Ci sono diversi modi per esporre l'interfaccia utente di Prometheus in esecuzione in EKS alle richieste provenienti dall'esterno del cluster. Utilizzeremo il port-forwarding di kubectl. Finora, abbiamo eseguito comandi all'interno del contenitore aws-do-eks. Per accedere al servizio Prometheus in esecuzione nel cluster, creeremo un tunnel dall'host. Qui il contenitore aws-do-eks viene eseguito eseguendo il seguente comando al di fuori del contenitore, in un nuovo terminale shell sull'host. Faremo riferimento a questo come "shell host".
kubectl -n prometheus port-forward svc/$(kubectl -n prometheus get svc | grep prometheus | grep -v alertmanager | grep -v operator | grep -v grafana | grep -v metrics | grep -v exporter | grep -v operated | cut -d ' ' -f 1) 8080:9090 &
Mentre il processo di port-forwarding è in esecuzione, è possibile accedere all'interfaccia utente di Prometheus dall'host come descritto di seguito.
- Apri l'interfaccia utente di Prometheus
- Se stai usando Cloud9, naviga su
Preview->Preview Running Application per aprire l'interfaccia utente di Prometheus in una scheda all'interno dell'IDE di Cloud9, quindi fai clic sull'icona  nell'angolo in alto a destra della scheda per aprirla in una nuova finestra.
nell'angolo in alto a destra della scheda per aprirla in una nuova finestra.
- Se ti trovi sul tuo host locale o sei connesso a un'istanza EC2 tramite desktop remoto, apri un browser e visita l'URL
http://localhost:8080.
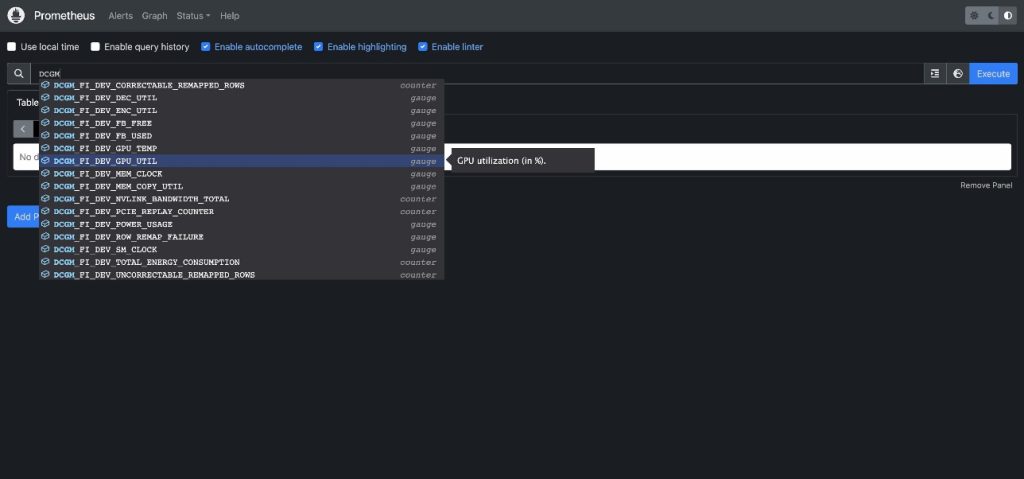
- Inserisci
DCGM per visualizzare le metriche DCGM che fluiscono in Prometheus
- Seleziona
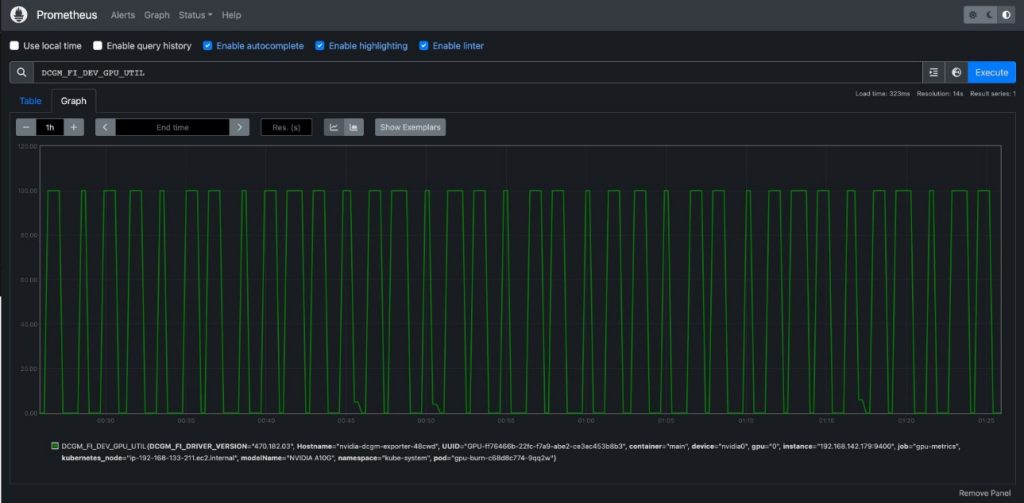
DCGM_FI_DEV_GPU_UTIL, scegli Esegui, quindi vai alla scheda Grafico per vedere il pattern atteso di utilizzo della GPU
- Interrompi il processo di port-forwarding di Prometheus
Esegui il seguente comando nella shell del tuo host:
kill -9 $(ps -aef | grep port-forward | grep -v grep | grep prometheus | awk '{print $2}')
Ora possiamo visualizzare le metriche DCGM tramite il Dashboard di Grafana.
- Ricava la password per accedere all'interfaccia utente di Grafana
kubectl -n prometheus get secret $(kubectl -n prometheus get secrets | grep grafana | cut -d ' ' -f 1) -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
- Esegui il port-forwarding del servizio Grafana
Esegui il seguente comando nella shell del tuo host:
kubectl port-forward -n prometheus svc/$(kubectl -n prometheus get svc | grep grafana | cut -d ' ' -f 1) 8080:80 &
- Accedi all'interfaccia utente di Grafana
Accedi alla schermata di accesso dell'interfaccia utente di Grafana allo stesso modo in cui hai acceduto all'interfaccia utente di Prometheus in precedenza. Se stai usando Cloud9, seleziona Anteprima->Anteprima applicazione in esecuzione, quindi apri in una nuova finestra. Se stai usando il tuo host locale o un'istanza EC2 con desktop remoto, visita l'URL http://localhost:8080. Accedi con il nome utente admin e la password che hai ricavato in precedenza.
- Nel riquadro di navigazione, scegli Dashboard
- Scegli Nuovo e Importa
 Stiamo per importare il dashboard predefinito DCGM descritto in NVIDIA DCGM Exporter Dashboard.
Stiamo per importare il dashboard predefinito DCGM descritto in NVIDIA DCGM Exporter Dashboard.
- Nel campo
importa tramite grafana.com, inserisci 12239 e scegli Carica
- Scegli Prometheus come origine dati
- Scegli Importa
Vedrai un cruscotto simile a quello nella seguente schermata.
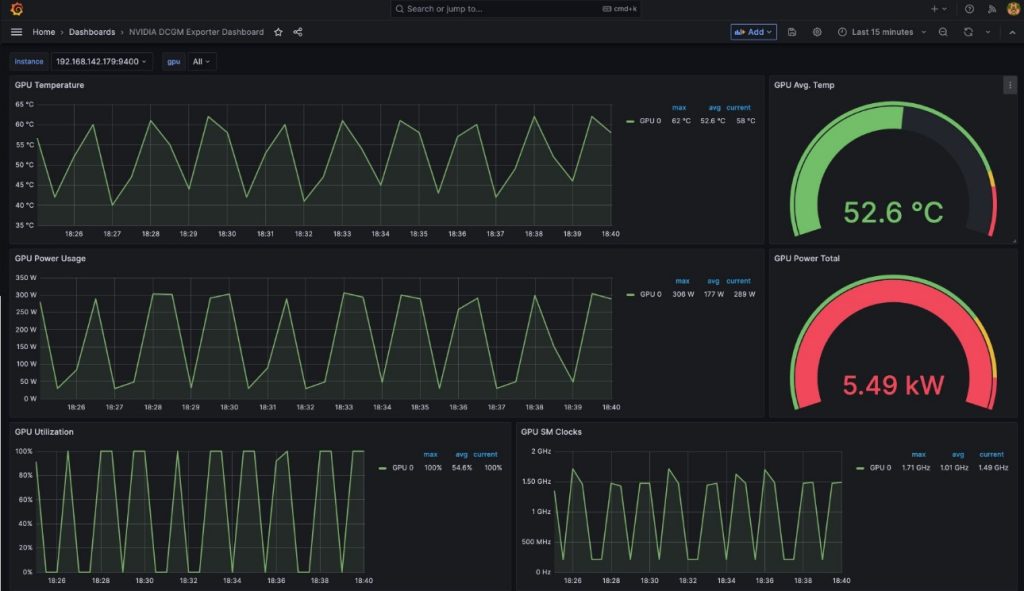
Per dimostrare che queste metriche sono basate sui pod, modificheremo il pannello Utilizzo GPU in questo cruscotto.
- Scegli il pannello e il menu delle opzioni (tre puntini)
- Espandi la sezione Opzioni e modifica il campo Legenda
- Sostituisci il valore con
Pod {{pod}}, quindi scegli Salva
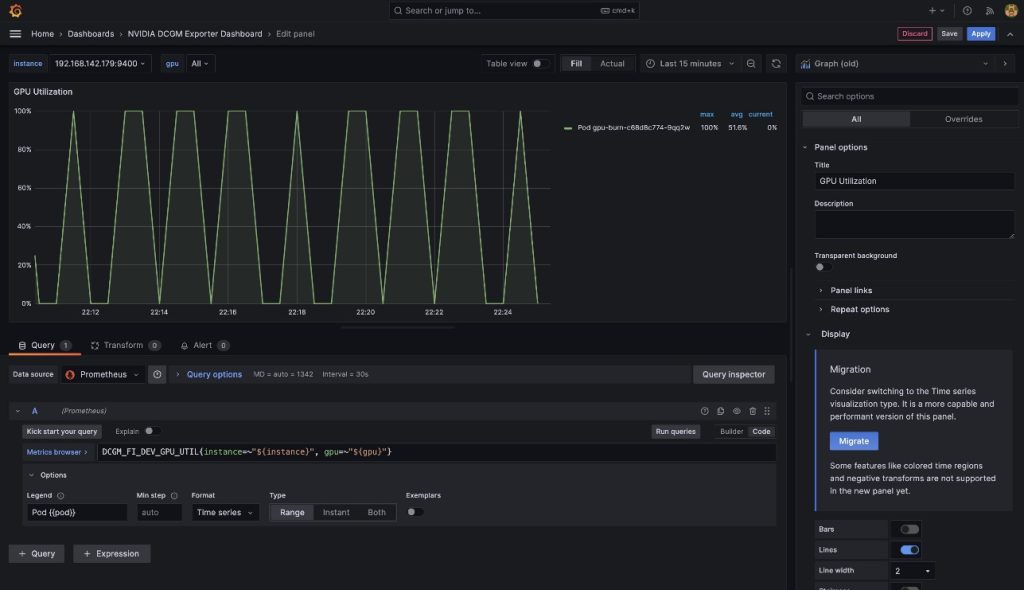 Ora la legenda mostra il nome del pod
Ora la legenda mostra il nome del pod gpu-burn associato all'utilizzo visualizzato della GPU.
- Smetti di inoltrare le porte per il servizio UI di Grafana
Esegui il seguente comando nella shell del tuo host:
kill -9 $(ps -aef | grep port-forward | grep -v grep | grep prometheus | awk '{print $2}')
In questo post, abbiamo dimostrato l'uso di Prometheus e Grafana open-source implementati nel cluster EKS. Se lo desideri, questa implementazione può essere sostituita con Amazon Managed Service for Prometheus e Amazon Managed Grafana.
Pulizia
Per eliminare le risorse create, esegui lo script seguente dalla shell del contenitore aws-do-eks:
./eks-delete.sh
Conclusioni
In questo post, abbiamo utilizzato NVIDIA DCGM Exporter per raccogliere metriche GPU e visualizzarle con CloudWatch o Prometheus e Grafana. Ti invitiamo a utilizzare le architetture qui dimostrate per abilitare il monitoraggio dell'utilizzo delle GPU con NVIDIA DCGM nel tuo ambiente AWS.
Risorse aggiuntive
- Istanze GPU Amazon EC2
- NVIDIA DCGM: Gestione e monitoraggio delle GPU in ambienti cluster
- Repo GitHub kube-prometheus-stack






