Risolvere un problema di Leetcode utilizzando l’apprendimento per rinforzo
Usare l'apprendimento per rinforzo su Leetcode
Un’introduzione pratica al reinforcement learning
Recentemente, ho incontrato una domanda su leetcode: Percorso più breve in una griglia con eliminazione degli ostacoli. Il problema del percorso più breve in una griglia con eliminazione degli ostacoli consiste nel trovare il percorso più breve da una cella di partenza a una cella di destinazione in una griglia 2D che contiene ostacoli, dove è consentito eliminare fino a k ostacoli che si trovano lungo il percorso. La griglia è rappresentata da una matrice 2D “m x n” di 0 (celle vuote) e 1 (celle ostacolo).
Lo scopo è trovare il percorso più breve dalla cella di partenza (0, 0) alla cella di destinazione (m-1, n-1) attraversando le celle vuote mentre si eliminano al massimo k ostacoli. Eliminare un ostacolo significa convertire la cella ostacolo (1) in una cella vuota (0) in modo che il percorso possa attraversarla.
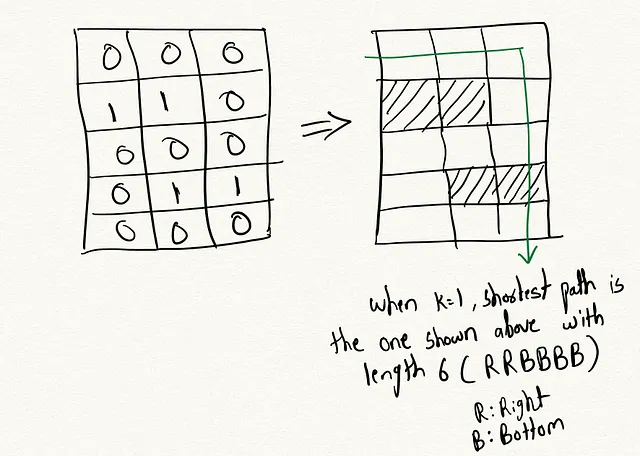
Mentre risolvevo questo problema, mi sono reso conto che potrebbe fornire un utile framework per capire i principi del reinforcement learning in azione. Prima di entrare in questo argomento, vediamo come viene tradizionalmente risolto questo problema.
Per risolverlo idealmente, è necessario effettuare una ricerca del grafo a partire dalla cella di partenza tenendo traccia del numero di ostacoli eliminati finora. Ad ogni passo, consideriamo di spostarci in una cella vuota adiacente o eliminare una cella ostacolo adiacente se abbiamo ancora eliminazioni disponibili. Il percorso più breve è quello che raggiunge la destinazione con il minor numero di passi ed eliminando al massimo k ostacoli. Possiamo utilizzare la ricerca in ampiezza (BFS), la ricerca in profondità (DFS) per trovare il percorso più breve ottimale in modo efficiente.
- Auto-Tuning per la distribuzione di Reti Neurali Profonde
- Modellazione dei dati per i comuni mortali – Parte 2 Fondamenti della modellazione dimensionale
- Flick Recensione Il miglior strumento di hashtag su Instagram per aumentare la visibilità
Ecco la funzione python che utilizza l’approccio BFS per questo problema:
class Solution: def shortestPath(self, grid: List[List[int]], k: int) -> int: rows, cols = len(grid), len(grid[0]) target = (rows - 1, cols - 1) # se abbiamo sufficienti quote per eliminare gli ostacoli nel caso peggiore, # la distanza più breve è la distanza di Manhattan if k >= rows + cols - 2: return rows + cols - 2 # (riga, colonna, quota rimanente per eliminare gli ostacoli) stato = (0, 0, k) # (passi, stato) coda = deque([(0, stato)]) visto = set([stato]) while coda: passi, (riga, colonna, k) = coda.popleft() # raggiungiamo la destinazione qui if (riga, colonna) == target: return passi # esplora le quattro direzioni al passo successivo for new_riga, new_colonna in [(riga, colonna + 1), (riga + 1, colonna), (riga, colonna - 1), (riga - 1, colonna)]: # se (new_riga, new_colonna) è entro i limiti della griglia if (0 <= new_riga < righe) and (0 <= new_colonna < colonne): nuove_eliminazioni = k - griglia[new_riga][new_colonna] nuovo_stato = (new_riga, new_colonna, nuove_eliminazioni) # aggiungi la mossa successiva nella coda se qualifica if nuove_eliminazioni >= 0 e nuovo_stato non in visto: visto.add(nuovo_stato) coda.append((passi + 1, nuovo_stato)) # non ha raggiunto la destinazione return -1Un piccolo approfondimento del reinforcement learning
Il reinforcement learning (RL) è un’area del machine learning in cui un agente impara una politica tramite un meccanismo di ricompensa per compiere un compito apprendendo l’ambiente circostante. Sono sempre stato affascinato dal reinforcement learning perché credo che questo framework rifletta da vicino il modo in cui gli esseri umani imparano attraverso l’esperienza. L’idea è costruire un agente apprendibile che, con prove ed errori, impari sull’ambiente per risolvere il problema.
Esploriamo questi argomenti termine per termine:
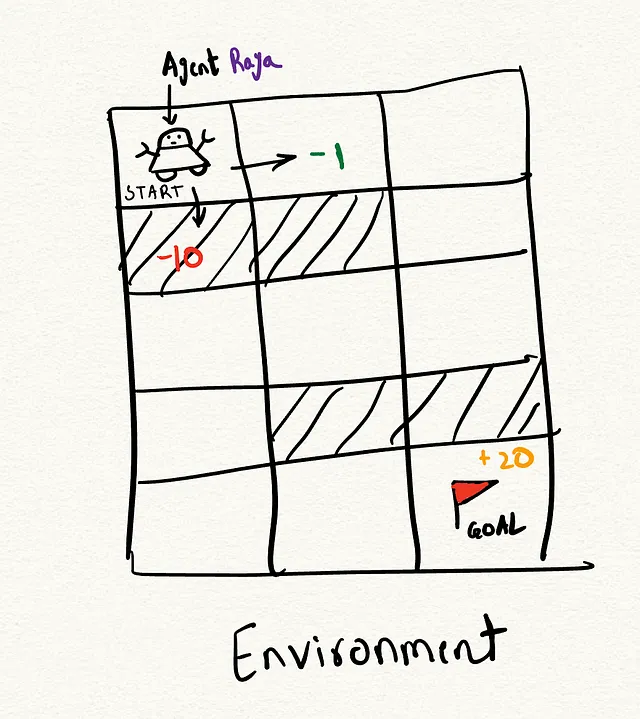
- Agente : Un agente è un’entità ipotetica che controlla il corso delle azioni. Puoi immaginare un ipotetico robot, diciamo l’Agente Raya, che parte da una posizione ed esplora il suo ambiente. Ad esempio, Raya ha due possibili opzioni: la posizione (0, 0) che va a destra o la posizione (0, 1) che va in basso, e entrambe queste posizioni hanno ricompense diverse.
- Ambiente : L’ambiente è il contesto in cui il nostro agente opera ed è bidimensionale, una griglia in questo caso.
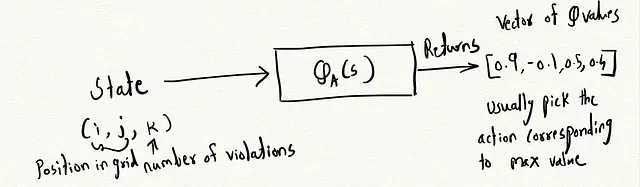
- Stato : Lo stato rappresenta la situazione attuale del giocatore. Nel nostro caso, fornisce la posizione attuale del giocatore e il numero di violazioni rimanenti.
- Sistema di Ricompense : La ricompensa è il punteggio che otteniamo come risultato di una determinata azione. In questo caso: -1 punto per una cella vuota, +20 punti per raggiungere la destinazione e -10 punti se esauriamo il numero di violazioni, k.
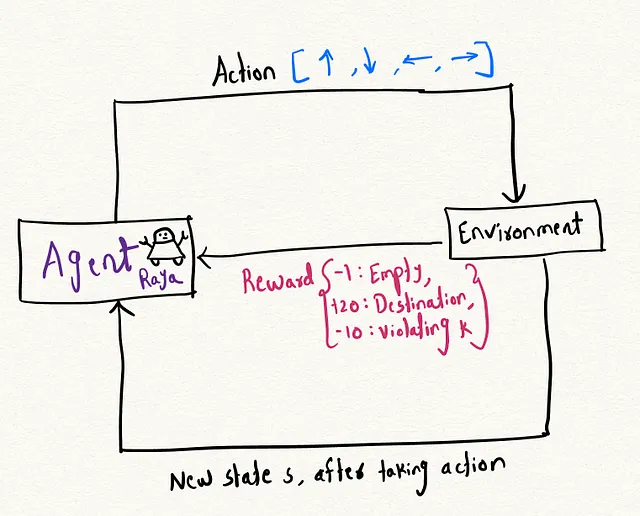
Attraverso il processo di iterazione, apprendiamo una politica ottimale che ci consente di trovare l’azione migliore possibile ad ogni passo che massimizza anche la ricompensa totale.
Per essere in grado di trovare la migliore politica, abbiamo usato qualcosa chiamato funzione Q. Puoi pensare a questa funzione come a un repository di tutta l’esplorazione che il tuo agente ha fatto finora. L’agente utilizza poi queste informazioni storiche per prendere decisioni migliori in futuro che massimizzano la ricompensa.
Funzione Q
Q(s, a) rappresenta la ricompensa cumulativa attesa che un agente può ottenere prendendo l’azione a nello stato s, seguendo la politica π.

Dove
- π : la politica adottata dall’agente.
- s : lo stato attuale.
- a : l’azione intrapresa dall’agente nello stato s.
γ è il fattore di sconto che bilancia l’esplorazione e lo sfruttamento. Determina quanto peso l’agente dà alle ricompense immediate rispetto a quelle future. Un fattore più vicino a 0 fa sì che l’agente si concentri sulle ricompense a breve termine, mentre un fattore più vicino a 1 lo fa concentrare sulle ricompense a lungo termine.
L’agente deve bilanciare l’utilizzo di azioni conosciute ad alto rendimento con l’esplorazione di azioni sconosciute che potrebbero potenzialmente fornire ricompense più elevate. L’utilizzo di un fattore di sconto compreso tra 0 e 1 aiuta a evitare che l’agente si blocchi in politiche localmente ottimali.
Passiamo ora al codice di come funziona tutto.
Ecco come definiamo un agente e le variabili ad esso associate.
Funzione di Ricompensa : La funzione di ricompensa prende lo stato attuale e restituisce la ricompensa ottenuta per tale stato.
Equazione di Bellman :
Come dovremmo aggiornare la tabella Q in modo che abbia il valore migliore possibile per ogni posizione e azione ? Per un numero arbitrario di iterazioni, l’agente parte dalla posizione (0, 0, k), dove k indica il numero consentito di violazioni. Ad ogni passo, l’agente passa a uno stato nuovo esplorando casualmente o sfruttando i valori Q appresi per muoversi avidamente.
Arrivando in un nuovo stato, valutiamo la ricompensa immediata e aggiorniamo il valore Q per quella coppia stato-azione in base all’equazione di Bellman. Ciò ci permette di migliorare iterativamente la funzione Q incorporando nuove ricompense nelle ricompense storiche aggregate per ogni stato-azione.
Ecco l’equazione per l’equazione di Bellman :
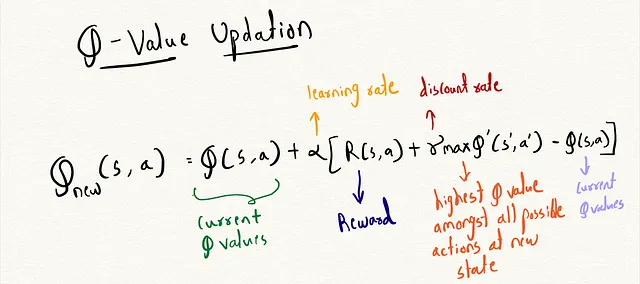
Questo è come appare il processo di addestramento nel codice:
Costruzione del percorso: Per il percorso, utilizziamo il valore massimo di Q per ciascuna posizione della griglia per determinare l’azione ottimale da intraprendere in quella posizione. I valori di Q codificano essenzialmente l’azione migliore da intraprendere in ciascuna posizione sulla base delle ricompense a lungo termine. Ad esempio, tra tutte le azioni k nella posizione (0,0), il valore massimo di Q corrisponde all’azione “1”, che rappresenta lo spostamento a destra. Scegliendo avidamente l’azione con il valore di Q più alto ad ogni passo, possiamo costruire un percorso ottimale attraverso la griglia.
Se esegui il codice fornito, troverai che genera il percorso RBRBBB, che è effettivamente uno dei percorsi più brevi che tiene conto dell’ostacolo.
Ecco il link al codice completo in un unico file: shortest_path_rl.py
Conclusioni
In scenari di apprendimento per rinforzo del mondo reale, l’ambiente con cui l’agente interagisce può essere enorme, con ricompense sparse. Se modifichi la configurazione della griglia cambiando gli 0 e gli 1, questo approccio rigido della tabella Q fallirebbe nel generalizzare. Il nostro obiettivo è addestrare un agente che apprende una rappresentazione generale delle configurazioni della griglia e può trovare percorsi ottimali in nuovi layout. Nel prossimo post, sostituirò i valori rigidi della tabella Q con una Rete Q Profonda (DQN). La DQN è una rete neurale che prende in input una combinazione stato-azione e l’intero layout della griglia e produce una stima del valore di Q. Questa DQN dovrebbe consentire all’agente di trovare percorsi ottimali anche in nuovi layout di griglia che non ha incontrato durante l’addestramento.
Contattami su LinkedIn se vuoi fare una chiacchierata veloce e connetterti: https://www.linkedin.com/in/pratikdaher/



