Pandas Playbook 7 Funzioni di dati complete da conoscere
Pandas Playbook 7 Funzioni dati complete

Nel campo dell’analisi dei dati e dell’apprendimento automatico, la libreria Pandas si presenta come un potente strumento. Con più di 200 funzioni e metodi, ti permette di manipolare e trasformare i dati, ma allo stesso tempo ti rende incapace di manipolare e trasformare i dati a causa delle sue complessità. È una spada a doppio taglio.
Pertanto, esploreremo le funzioni e i metodi più comuni e utili di Panda. Conoscere questo ti metterà in vantaggio rispetto ad altri principianti che imparano Pandas.
Utilizzeremo un pseudo-dataset per tutto il corso di questo articolo.
Il primo passo è importare pandas come pd. Questa è una delle migliori pratiche per importare pandas, poiché pd è un’abbreviazione ben nota per pandas.
- Una guida semplice di Hugging Face per chattare con il modello Llama-2 7B in un notebook Colab
- Aumenta il tuo tasso di richiami con un profilo LinkedIn
- Crescente Preoccupazione Pubblica sul Ruolo dell’Intelligenza Artificiale nella Vita Quotidiana
import pandas as pdImportare i tuoi dati
Prima di qualsiasi manipolazione dei dati, è necessario importare i dati. La funzione read_csv() è il punto di ingresso per caricare set di dati in DataFrame di Pandas. Specificando il percorso del file, questa funzione dà vita ai dati, consentendoti di iniziare l’esplorazione e l’analisi dei dati.
Per importare, segui questa sintassi e inserisci il percorso del file del tuo dataset.
In[*] car_sales = pd.read_csv("./data/car-sales.csv") car_sales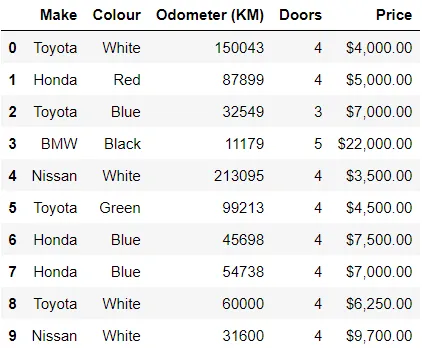
Uno sguardo ai tuoi dati
Curioso di vedere le prime o le ultime righe del tuo DataFrame? head() e tail() forniscono un’occhiata rapida, aiutandoti a valutare la struttura e il contenuto del tuo dataset. Ideale per una comprensione preliminare prima di immergersi in trasformazioni dei dati. Puoi inserire un argomento all’interno di head(9) e tail(9) per specificare quanti elementi desideri vedere. Il valore predefinito è di 5 elementi.
Per illustrare, guarda il codice di esempio di input e output di seguito.
In[*] car_sales.head()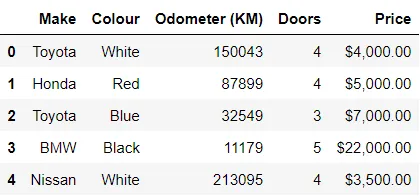
In[*] car_sales.tail()
Conosci i tuoi dati in fondo
La funzione info() è il tuo detective dei dati. Fornisce un riepilogo completo del tuo DataFrame, mostrando il numero di voci non nulle, i tipi di dati, l’utilizzo della memoria e altro ancora. Questa panoramica rapida può guidare i tuoi sforzi di pulizia e preparazione dei dati.
In[*] car_sales.info()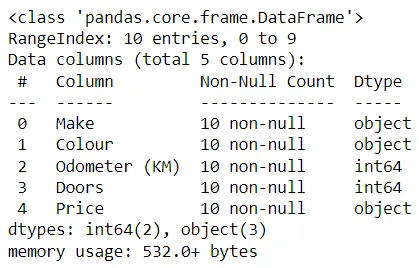
Scopri le statistiche descrittive
Le informazioni statistiche sono a portata di mano. La funzione describe() fornisce una serie di statistiche descrittive, tra cui media, mediana, minimo, massimo e quartili. Ottieni uno snapshot della distribuzione dei tuoi dati numerici e individua eventuali valori anomali. Ricorda che describe() potrebbe non mostrare informazioni significative, dipenderà sempre dai tuoi dataset.
In[*] car_sales.describe()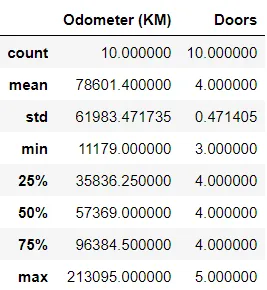
Raggruppando per ottenere intuizioni
I dati spesso raccontano una storia più ricca quando vengono raggruppati per attributi specifici. La funzione groupby() ti consente di segmentare i dati in base a una colonna specifica, rendendola uno strumento essenziale per aggregare, riassumere e visualizzare le tendenze all’interno del tuo dataset.
In[*] car_sales.groupby(["Make"]).mean()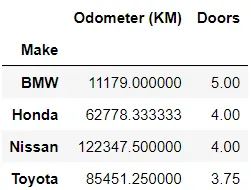
Potenziare le trasformazioni personalizzate
A volte, le funzioni standard non sono sufficienti. La funzione apply() ti consente di applicare funzioni personalizzate ai tuoi dati. Questa flessibilità apre le porte a trasformazioni personalizzate dei dati che soddisfano le tue esigenze specifiche. Questo è anche importante per la manipolazione e la pulizia dei tuoi dataset.
In questo esempio, applicheremo una funzione lambda per rimuovere $, , e .00 nei prezzi e convertirli in int per eseguire funzioni significative. Guarda il PRIMA e il DOPO dei prezzi.
In[*] car_sales["Price"] = car_sales["Price"].apply (lambda x: x.replace(".00", '')).str.replace('[\$\,]', '').astype(int) car_sales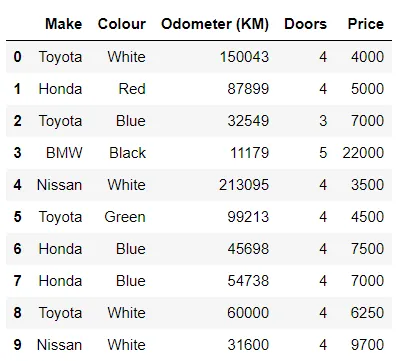
Affrontare i dati mancanti
Gestire i dati mancanti è una sfida comune. La funzione fillna() ti consente di sostituire i valori mancanti, mentre dropna() ti consente di rimuovere righe o colonne con dati mancanti. Queste funzioni garantiscono che la tua analisi si basi su informazioni complete e accurate.
A scopo illustrativo, importiamo un nuovo dataset con dati mancanti.
In[*] car_sales_missing = pd.read_csv("./data/car-sales-missing-data.csv") car_sales_missing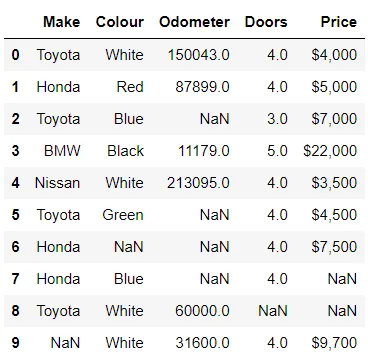
Possiamo chiaramente vedere che alcuni dati di Odometer hanno un valore di NaN, quindi useremo fillna() per riempire il valore mancante con la media di Odometer.
In[*] car_sales_missing["Odometer"] = car_sales_missing["Odometer"].fillna(car_sales_missing["Odometer"].mean())
Ora, Colours, Doors e Price sono gli unici con NaN, situati agli indici 6, 7, 8 e 9 rispettivamente. Rimuoveremo le righe e le colonne che contengono NaN utilizzando dropna().
In[*] car_sales_missing = car_sales_missing.dropna() car_sales_missing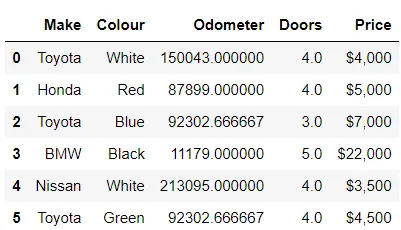
Pandas è più di una semplice libreria; è un gateway per una manipolazione e un’analisi efficaci dei dati. Armato di queste funzioni essenziali, sei pronto ad affrontare sfide di dati reali e problemi di machine learning con fiducia. Che tu sia un data scientist, un analista o un ingegnere di machine learning, Pandas ti permette di trasformare dataset disordinati in intuizioni preziose. Quindi, immergiti, sperimenta e sblocca il potenziale illimitato di Pandas per i tuoi sforzi basati sui dati.
Rimani curioso e mantieni la tua mente analitica stimolata!
Se vuoi esplorare di più su Pandas, considera di dare un’occhiata alla loro documentazione!






