Ink to Insights Confronto tra query SQL e Python utilizzando l’analisi di un negozio di libri
Confronto tra SQL e Python nell'analisi di un negozio di libri
Quale approccio è migliore per la tua analisi esplorativa dei dati?
SQL è il pane quotidiano di ogni data scientist – la capacità di estrarre rapidamente i dati da una fonte per l’analisi è una competenza essenziale per chiunque lavori con grandi quantità di dati. In questo post vorrei fornire alcuni esempi di alcune query di base che utilizzo di solito in SQL, nel corso di un processo di EDA. Confronterò queste query con script simili in Python che producono lo stesso output, come confronto tra i due approcci.
Per questa analisi userò alcuni dati sintetici sui libri con il punteggio più alto dell’anno scorso di una catena ipotetica di librerie (la Total Fiction Bookstore). Un link alla cartella di GitHub per questo progetto può essere trovato qui, dove spiego i dettagli dell’esecuzione dell’analisi.
Come nota a margine – mentre mi concentro principalmente sulle query SQL in questo articolo, vale la pena notare che queste query possono essere integrate in modo abbastanza semplice con Python utilizzando la libreria pandaSQL (come ho fatto per questo progetto). Questo può essere visto nel dettaglio nel notebook Jupyter al link GitHub di questo progetto, ma la struttura di questa query generalmente procede come segue:
query = """SELECT * FROM DATA"""output = sqldf(query,locals())outputPandaSQL è una libreria molto pratica per coloro che hanno maggiore familiarità con le query SQL rispetto alla manipolazione tipica dei dataset di Pandas – ed è spesso molto più facile da leggere, come mostrerò qui.
- Programmazione con l’Intelligenza Artificiale
- Riconoscimento delle entità con LLM Una valutazione completa
- Sei uno sviluppatore efficiente? Allora l’IA sta cercando di prendere il tuo posto
Il Dataset
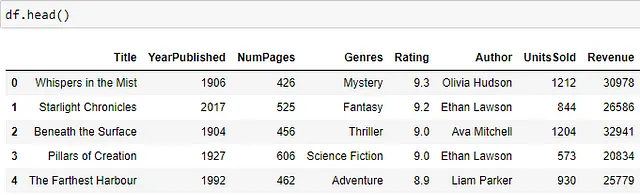
Una porzione del dataset può essere visualizzata di seguito – ci sono colonne per il titolo del libro e l’anno di pubblicazione, il numero di pagine, i generi, il punteggio medio del libro, l’autore, il numero di unità vendute e il ricavo del libro.
Analisi del Ricavo per Decade
Supponiamo che voglio sapere quale decade ha pubblicato i libri più redditizi per la libreria. Il dataset originale non ha una colonna per indicare in quale decade sono stati pubblicati i libri – tuttavia, questo è relativamente semplice da inserire nei dati. Eseguo una sottoquery per dividere l’anno utilizzando la divisione intera e moltiplicando per 10 per ottenere i dati della decade, quindi aggrego e calcolo la media dei voti per decade. Ordino quindi i risultati per ricavo totale per ottenere le decade più redditizie dei libri pubblicati nella libreria.
WITH bookshop AS(SELECT TITLE, YEARPUBLISHED,(YEARPUBLISHED/10) * 10 AS DECADE,NUMPAGES, GENRES, RATING, AUTHOR, UNITSSOLD,REVENUEfrom df)SELECT DECADE, SUM(REVENUE) AS TOTAL_REVENUE,ROUND(AVG(REVENUE),0) AS AVG_REVENUEFROM bookshopGROUP BY DECADEORDER BY TOTAL_REVENUE DESCA confronto, un output equivalente in Python avrebbe un aspetto simile al frammento di codice riportato di seguito. Applico una funzione lambda che esegue la divisione intera e restituisce la decade, e da lì aggrego i voti per decade e ordino il risultato per ricavo totale.
# creazione del dataframe bookshopbookshop = df.copy()bookshop['Decade'] = (bookshop['YearPublished'] // 10) * 10# raggruppamento per decade, aggregazione del ricavo per somma e mediarisultato = bookshop.groupby('DECADE') \ .agg({'Revenue': ['sum', 'mean']}) \ .reset_index()result.columns = ['Decade', 'Total_Revenue', 'Avg_Revenue']# ordinamento per decaderesult = result.sort_values('Total_Revenue')Notare il maggior numero di passaggi separati nello script python per ottenere lo stesso risultato – le funzioni sono scomode e difficili da comprendere a prima vista. In confronto, lo script SQL è molto più chiaro nella sua presentazione e molto più facile da leggere.
Ora posso prendere questa query e visualizzarla per ottenere un’idea delle tendenze dei ricavi dei libri nel corso dei decenni, impostando un grafico matplotlib utilizzando lo script seguente – i grafici a barre mostrano il ricavo totale per decennio, con un grafico a dispersione sull’asse secondario per mostrare il ricavo medio dei libri.
# Creazione dell'asse y primario (ricavo totale)
fig, ax1 = plt.subplots(figsize=(15, 9))
ax1.bar(agg_decade['DECADE'], agg_decade['TOTAL_REVENUE'], width=0.4, align='center', label='Ricavo Totale (Dollari)')
ax1.set_xlabel('Decennio')
ax1.set_ylabel('Ricavo Totale (Dollari)', color='blue')
# Regolazione delle linee della griglia sull'asse y primario
ax1.grid(color='blue', linestyle='--', linewidth=0.5, alpha=0.5)
# Creazione dell'asse y secondario (ricavo medio)
ax2 = ax1.twinx()
ax2.scatter(agg_decade['DECADE'], agg_decade['AVG_REVENUE'], marker='o', color='red', label='Ricavo Medio (Dollari)')
ax2.set_ylabel('Ricavo Medio (Dollari)', color='red')
# Regolazione delle linee della griglia sull'asse y secondario
ax2.grid(color='red', linestyle='--', linewidth=0.5, alpha=0.5)
# Impostazione dei limiti degli assi y per ax1 e ax2
ax1.set_ylim(0, 1.1 * max(agg_decade['TOTAL_REVENUE']))
ax2.set_ylim(0, 1.1 * max(agg_decade['AVG_REVENUE']))
# Combinazione delle legende per entrambi gli assi
lines, labels = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines + lines2, labels + labels2, loc='upper left')
# Impostazione del titolo
plt.title('Ricavo Totale e Medio per Decennio')
# Mostra il grafico
plt.show()La visualizzazione può essere vista di seguito – i libri pubblicati negli anni ’60 sono apparentemente i più redditizi per la libreria, generando oltre $192.000 di ricavi per Total Fiction Bookstore. In confronto, i libri della lista degli anni 1900 sono più redditizi in media, anche se non sono stati venduti altrettanto bene come i libri degli anni ’60.

Il ricavo medio dei libri segue una tendenza simile al ricavo totale in tutti i decenni dei libri pubblicati – ad eccezione dei libri degli anni 1900 e 1980, che sono più redditizi in media ma non complessivamente.
Analisi dell’autore
Supponiamo ora che voglio ottenere dati sui primi 10 autori della lista, ordinati in base al loro ricavo totale generato. Per questa query voglio conoscere il numero di libri che hanno scritto che appaiono nella lista, il ricavo totale generato da quei libri, il ricavo medio per libro e la valutazione media di quei libri nella libreria. Domanda abbastanza semplice da rispondere usando SQL – posso utilizzare una dichiarazione di conteggio per ottenere il numero totale di libri che hanno scritto e le dichiarazioni di media per ottenere il ricavo medio e la valutazione per autore. Successivamente posso raggruppare queste dichiarazioni per autore.
SELECT AUTORE, COUNT(TITOLO) AS NUM_LIBRI, SUM(RICAVO) AS RICAVO_TOTALE, ROUND(AVG(RICAVO),0) AS RICAVO_MEDIO, ROUND(AVG(VALUTAZIONE),2) AS VALUTAZIONE_MEDIA_PER_LIBRO
FROM LIBRERIA
GROUP BY AUTORE
ORDER BY RICAVO_TOTALE DESC
LIMIT 10Uno script Python equivalente sarebbe simile a questo – approssimativamente la stessa lunghezza, ma molto più complesso per lo stesso risultato. Raggruppo i valori per autore prima di specificare come aggregare ciascuna colonna nella funzione agg, quindi ordino i valori per ricavo totale. Ancora una volta, lo script SQL è molto più chiaro in confronto.
risultato = libreria.groupby('Autore') \
.agg({
'Titolo': 'count',
'Ricavo': ['sum', 'mean'],
'Valutazione': 'mean'
}) \
.reset_index()
risultato.columns = ['Autore', 'Num_Libri', 'Ricavo_Totale',
'Ricavo_Medio', 'Valutazione_Media_per_Libro']
# Ordinamento per ricavo totale
risultato = risultato.sort_values('Ricavo_Totale', ascending=False)
# Top 10
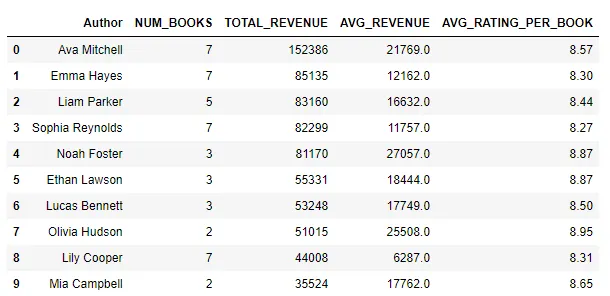
risultato_top10 = risultato.head(10)Di seguito è possibile vedere l’output di questa query: Ava Mitchell è in testa, con un fatturato totale di oltre $152.000 dalle vendite dei suoi libri. Emma Hayes si piazza al secondo posto con oltre $85.000, seguita da Liam Parker con oltre $83.000.
Visualizzando ciò in matplotlib utilizzando lo script seguente, possiamo generare grafici a barre del fatturato totale con i punti dati che mostrano il fatturato medio per autore. La valutazione media per autore viene anche tracciata su un asse secondario.
# Creazione del grafico e degli assifig1, ax1 = plt.subplots(figsize=(15, 9))# Tracciamento del grafico a barre del fatturato totaleax1.bar(agg_author['Author'], agg_author['TOTAL_REVENUE'], width=0.4, align='center', color='silver', label='Fatturato totale (dollari)')ax1.set_xlabel('Autore')ax1.set_xticklabels(agg_author['Author'], rotation=-45, ha='left')ax1.set_ylabel('Fatturato totale (dollari)', color='blue')# Regolazione delle linee guida sull'asse y primarioax1.grid(color='blue', linestyle='--', linewidth=0.5, alpha=0.5)# Tracciamento del grafico a dispersione del fatturato medioax1.scatter(agg_author['Author'], agg_author['AVG_REVENUE'], marker="D", color='blue', label='Fatturato medio per libro (dollari)')# Creazione del grafico a dispersione della valutazione media sull'asse secondarioax2 = ax1.twinx()ax2.scatter(agg_author['Author'], agg_author['AVG_RATING_PER_BOOK'], marker='^', color='red', label='Valutazione media per libro')ax2.set_ylabel('Valutazione media', color='red')# Regolazione delle linee guida sull'asse y secondarioax2.grid(color='red', linestyle='--', linewidth=0.5, alpha=0.5)# Combinazione delle legende per entrambi gli assi lines, labels = ax1.get_legend_handles_labels()lines2, labels2 = ax2.get_legend_handles_labels()ax1.legend(lines + lines2, labels + labels2, loc='upper right')# Impostazione del titoloplt.title('Top 10 autori per fatturato, valutazione')# Mostra il graficoplt.show()Eseguendo questo script, otteniamo il seguente grafico:
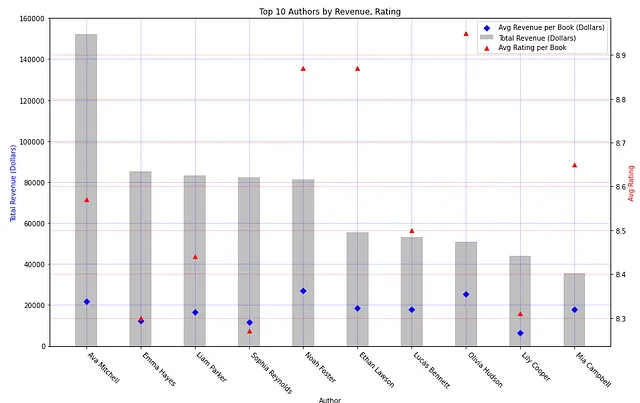
Questo grafico suggerisce una chiara affermazione: il fatturato non correla con la valutazione media di ogni autore. Ava Mitchell ha il fatturato più alto ma si trova nella mediana in termini di valutazione per gli autori elencati sopra. Olivia Hudson ha la valutazione più alta pur piazzandosi all’ottavo posto per voti totali; non c’è alcuna tendenza osservabile tra il fatturato di un autore e la sua popolarità.
Confronto tra Lunghezza del Libro e Fatturato
Infine, supponiamo che voglia mostrare come il fatturato dei libri differisce in base alla lunghezza del libro. Per rispondere a questa domanda, voglio prima dividere i libri in modo equo in 4 categorie basate sui quartili della lunghezza del libro, che daranno un’idea migliore delle tendenze complessive tra il fatturato e la lunghezza del libro.
Innanzitutto, definisco i quartili in SQL, utilizzando una sottoquery per generare questi valori, prima di ordinare i libri in questi gruppi utilizzando una dichiarazione case when.
WITH PERCENTILES AS ( SELECT PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY NUMPAGES) AS PERCENTILE_25, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY NUMPAGES) AS MEDIAN, PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY NUMPAGES) AS PERCENTILE_75 FROM bookshop)SELECT TITLE, TITLE, REVENUE, NUMPAGES, CASE WHEN NUMPAGES< (SELECT PERCENTILE_25 FROM PERCENTILES) THEN 'Quartile 1' WHEN NUMPAGES BETWEEN (SELECT PERCENTILE_25 FROM PERCENTILES) AND (SELECT MEDIAN FROM PERCENTILES) THEN 'Quartile 2' WHEN NUMPAGES BETWEEN (SELECT MEDIAN FROM PERCENTILES) AND (SELECT PERCENTILE_75 FROM PERCENTILES) THEN 'Quartile 3' WHEN NUMPAGES > (SELECT PERCENTILE_75 FROM PERCENTILES) THEN 'Quartile 4' END AS PAGELENGTH_QUARTILEFROM bookshopORDER BY REVENUE DESCIn alternativa (per i dialetti SQL che non supportano le funzioni di percentili, come SQLite), i quartili possono essere calcolati separatamente prima di inserirli manualmente nella clausola case when.
--Per il dialetto SQLiteSELECT TITLE, REVENUE, NUMPAGES,CASEWHEN NUMPAGES < 318 THEN 'Quartile 1'WHEN NUMPAGES BETWEEN 318 AND 375 THEN 'Quartile 2'WHEN NUMPAGES BETWEEN 375 AND 438 THEN 'Quartile 3'WHEN NUMPAGES > 438 THEN 'Quartile 4'END AS PAGELENGTH_QUARTILEFROM bookshopORDER BY REVENUE DESCEseguendo la stessa query in Python, definisco i percentili utilizzando numpy prima di utilizzare la funzione cut per ordinare i libri nei loro bucket, quindi ordino i valori per lunghezza del libro in pagine. Come prima, questo processo è notevolmente più complesso rispetto allo script equivalente in SQL.
# Definisci i percentili utilizzando numpypercentiles = np.percentile(bookshop['NumPages'], [25, 50, 75])# Definisci i limiti dei bucket utilizzando i percentili calcolatibin_edges = [-float('inf'), *percentiles, float('inf')]# Definisci le etichette per i bucketbucket_labels = ['Quartile 1', 'Quartile 2', 'Quartile 3', 'Quartile 4']# Crea la colonna 'RUNTIME_BUCKET' basata sui limiti dei bucket e sulle etichettebookshop['RUNTIME_BUCKET'] = pd.cut(bookshop['NumPages'], bins=bin_edges, labels=bucket_labels)result = bookshop[['Title', 'Revenue', 'NumPages', 'PAGELENGTH_QUARTILE']].sort_values(by='NumPages', ascending=False)L’output di questa query può essere visualizzato come boxplot utilizzando seaborn – un frammento dello script utilizzato per generare i boxplot può essere visto di seguito. Si noti che i bucket di runtime sono stati ordinati manualmente nell’ordine corretto per essere presentati correttamente.
# Imposta lo stile per i plotssns.set(style="whitegrid")# Imposta l'ordine dei bucket di profittopagelength_bucket_order = ['Quartile 1', 'Quartile 2', 'Quartile 3', 'Quartile 4']# Crea il boxplotplt.figure(figsize=(16, 10))sns.boxplot(x='PAGELENGTH_QUARTILE', y='Revenue', data=pagelength_output, order = pagelength_bucket_order, showfliers=True)# Aggiungi etichette e titoloplt.xlabel('Quartile della lunghezza delle pagine')plt.ylabel('Ricavi (Dollari)')plt.title('Boxplot dei ricavi per quartile della lunghezza delle pagine')# Mostra il plotplt.show()I boxplot possono essere visualizzati di seguito – si osservi che i ricavi medi per ciascun quartile di lunghezza del libro tendono ad aumentare all’aumentare della lunghezza dei libri. Ciò suggerisce che i libri più lunghi sono più redditizi presso la libreria.
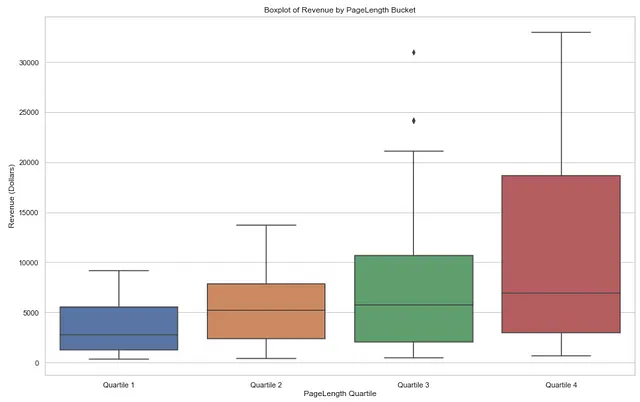
Inoltre, l’intervallo del quarto quartile è molto più ampio rispetto agli altri quartili, indicando una maggiore variazione nel prezzo per i libri più grandi.
Considerazioni finali e ulteriori applicazioni
Per concludere, l’uso di SQL per le interrogazioni di analisi dei dati è tipicamente molto più semplice rispetto all’utilizzo di operazioni equivalenti in Python; il linguaggio è più facile da scrivere rispetto alle query in Python, pur essendo in grado di produrre risultati simili. Non affermerei che uno sia migliore dell’altro – ho utilizzato una combinazione di entrambi i linguaggi in questa analisi – piuttosto, credo che l’utilizzo di una combinazione di entrambi i linguaggi insieme possa produrre un’analisi dei dati più efficiente ed efficace.
Pertanto, data la maggiore chiarezza nella scrittura delle query SQL rispetto alle query in Python, penso che sia molto più naturale utilizzare questo approccio durante l’esecuzione dell’EDA iniziale per un progetto. SQL è molto più facile da leggere e scrivere, come ho mostrato in questo articolo, il che lo rende particolarmente vantaggioso per queste prime attività esplorative. Lo uso spesso all’inizio di un progetto e consiglierei questo approccio a chiunque abbia già una buona comprensione delle query SQL.




