Crea il tuo PandasAI con LlamaIndex
Crea il tuo PandasAI

Introduzione
Pandas AI è una libreria Python che sfrutta il potere dell’AI generativa per potenziare Pandas, la popolare libreria di analisi dei dati. Con un semplice comando, Pandas AI ti consente di eseguire operazioni complesse di pulizia, analisi e visualizzazione dei dati che in precedenza richiedevano molte righe di codice.
- USA Impone Restrizioni all’Esportazione di Chip NVIDIA verso Certi Paesi del Medio Oriente
- Ufficio del Copyright degli Stati Uniti aperto all’opinione pubblica su AI e Copyright
- OpenAI apre le porte all’IA aziendale
Oltre all’elaborazione dei dati, Pandas AI comprende il linguaggio naturale. Puoi fare domande sui tuoi dati in inglese semplice e fornirà riepiloghi e informazioni in un linguaggio di tutti i giorni, evitandoti di decifrare grafici e tabelle complesse.
Nell’esempio sottostante, abbiamo fornito un dataframe di Pandas e abbiamo chiesto all’IA generativa di creare un grafico a barre. Il risultato è impressionante.
pandas_ai.run(df, prompt='Traccia il grafico a barre del tipo di media per ogni anno di pubblicazione, utilizzando colori diversi.')
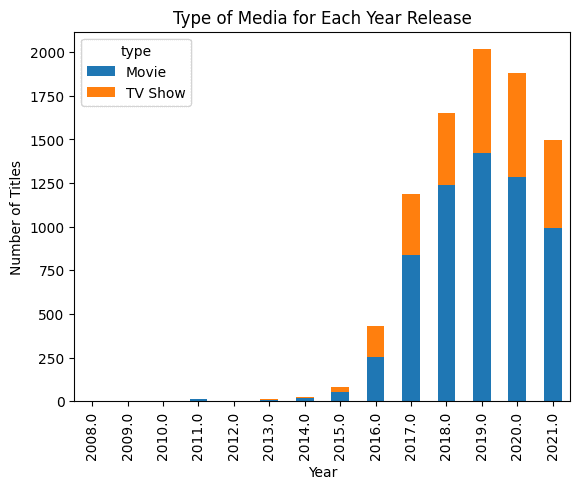
Nota: l’esempio di codice proviene dal tutorial Pandas AI: la tua guida all’analisi dei dati alimentata dall’IA generativa.
In questo post, utilizzeremo LlamaIndex per creare strumenti simili in grado di comprendere il dataframe di Pandas e produrre risultati complessi come quelli mostrati sopra.
LlamaIndex consente la query del linguaggio naturale dei dati tramite chat e agenti. Consente ai grandi modelli di linguaggio di interpretare dati privati su larga scala senza la necessità di un nuovo addestramento su nuovi dati. Integra grandi modelli di linguaggio con diverse fonti di dati e strumenti. LlamaIndex è un framework di dati che consente la creazione semplice di applicazioni per conversazioni con PDF con poche righe di codice.
Configurazione
Puoi installare la libreria Python utilizzando il comando pip.
pip install llama-index
Per impostazione predefinita, LlamaIndex utilizza il modello OpenAI gpt-3.5-turbo per la generazione di testo e text-embedding-ada-002 per il recupero e l’embedding. Per eseguire il codice senza problemi, è necessario configurare la variabile d’ambiente OPENAI_API_KEY. È possibile registrarsi e ottenere gratuitamente la chiave API su una nuova pagina di token API.
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxxxx"
Supportano anche integrazioni di Anthropic, Hugging Face, PaLM e altri modelli. Puoi saperne di più leggendo la documentazione del modulo.
Motore di query di Pandas
Arriviamo all’argomento principale: creare il tuo Pandas AI. Dopo aver installato la libreria e configurato la chiave API, creeremo un semplice dataframe delle città con il nome della città e la popolazione come colonne.
import pandas as pd
from llama_index.query_engine.pandas_query_engine import PandasQueryEngine
df = pd.DataFrame(
{"city": ["New York", "Islamabad", "Mumbai"], "population": [8804190, 1009832, 12478447]}
)
Utilizzando il PandasQueryEngine, creeremo un motore di query per caricare il dataframe e indicizzarlo.
Successivamente, scriveremo una query e visualizzeremo la risposta.
query_engine = PandasQueryEngine(df=df)
response = query_engine.query(
"Qual è la città con la popolazione più bassa?",
)
Come possiamo vedere, ha sviluppato il codice Python per visualizzare la città meno popolata nel dataframe.
> Istruzioni Pandas:
```
eval("df.loc[df['population'].idxmin()]['city']")
```
eval("df.loc[df['population'].idxmin()]['city']")
> Output Pandas: Islamabad
E se stampi la risposta, otterrai “Islamabad”. È semplice ma impressionante. Non è necessario creare la propria logica o sperimentare con il codice. Basta digitare la domanda e otterrai la risposta.
print(response)
Islamabad
Puoi anche stampare il codice dietro il risultato utilizzando i metadati della risposta.
print(response.metadata["pandas_instruction_str"])
eval("df.loc[df['population'].idxmin()]['city']")
Analisi delle statistiche globali di YouTube
Nel secondo esempio, caricheremo il dataset delle statistiche globali di YouTube 2023 da Kaggle e faremo alcune analisi fondamentali. Si tratta di un passo in avanti rispetto agli esempi semplici.
Utilizzeremo read_csv per caricare il dataset nel motore di query. Quindi scriveremo il comando per visualizzare solo le colonne con valori mancanti e il numero di valori mancanti.
df_yt = pd.read_csv("Global YouTube Statistics.csv")
query_engine = PandasQueryEngine(df=df_yt, verbose=True)
response = query_engine.query(
"Elencare le colonne con valori mancanti e il numero di valori mancanti. Mostrare solo le colonne con valori mancanti.",
)
> Istruzioni Pandas:
```
df.isnull().sum()[df.isnull().sum() > 0]
```
df.isnull().sum()[df.isnull().sum() > 0]
> Output Pandas: category 46
Country 122
Abbreviation 122
channel_type 30
video_views_rank 1
country_rank 116
channel_type_rank 33
video_views_for_the_last_30_days 56
subscribers_for_last_30_days 337
created_year 5
created_month 5
created_date 5
Gross tertiary education enrollment (%) 123
Population 123
Unemployment rate 123
Urban_population 123
Latitude 123
Longitude 123
dtype: int64
Ora, faremo delle domande dirette sui tipi di canali popolari. A mio parere, il motore di query LlamaIndex è altamente accurato e finora non ha prodotto allucinazioni.
response = query_engine.query(
"Qual è il tipo di canale con più visualizzazioni.",
)
> Istruzioni Pandas:
```
eval("df.groupby('channel_type')['video views'].sum().idxmax()")
```
eval("df.groupby('channel_type')['video views'].sum().idxmax()")
> Output Pandas: Entertainment
Entertainment
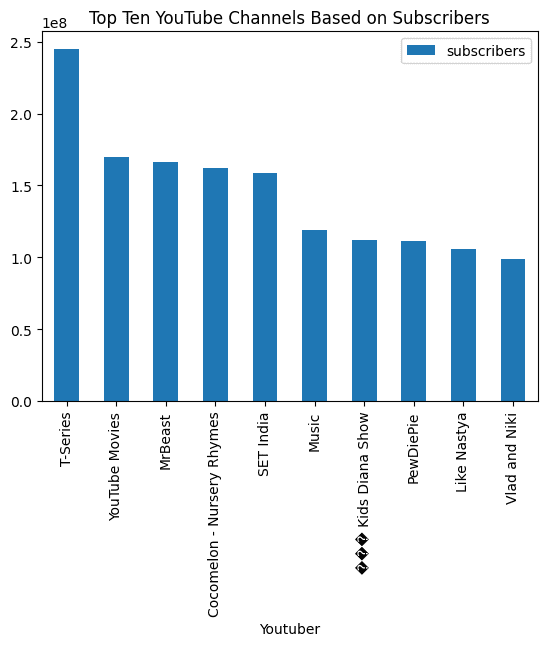
Alla fine, chiederemo di visualizzare un grafico a barre e i risultati sono sorprendenti.
response = query_engine.query(
"Visualizza un grafico a barre dei primi dieci canali YouTube in base agli iscritti e aggiungi il titolo.",
)
> Istruzioni Pandas:
```
eval("df.nlargest(10, 'subscribers')[['Youtuber', 'subscribers']].plot(kind='bar', x='Youtuber', y='subscribers', title='Top Ten YouTube Channels Based on Subscribers')")
```
eval("df.nlargest(10, 'subscribers')[['Youtuber', 'subscribers']].plot(kind='bar', x='Youtuber', y='subscribers', title='Top Ten YouTube Channels Based on Subscribers')")
> Output Pandas: AxesSubplot(0.125,0.11;0.775x0.77)
Con un semplice prompt e un motore di query, possiamo automatizzare l’analisi dei dati e svolgere compiti complessi. C’è molto di più da scoprire su LamaIndex. Ti consiglio vivamente di leggere la documentazione ufficiale e provare a creare qualcosa di sorprendente.
Conclusioni
In sintesi, LlamaIndex è uno strumento nuovo ed entusiasmante che consente agli sviluppatori di creare il proprio PandasAI, sfruttando la potenza dei grandi modelli di linguaggio per l’analisi e la conversazione intuitive dei dati. Indicizzando ed incorporando il tuo dataset con LlamaIndex, puoi abilitare funzionalità avanzate di linguaggio naturale sui tuoi dati privati senza compromettere la sicurezza o la riformazione dei modelli.
Questo è solo l’inizio, con LlamaIndex puoi costruire Q&A su documenti, Chatbot, AI automatizzata, Knowledge Graph, Motore di query SQL AI, Applicazione Web Full-Stack e creare applicazioni AI generative private. Abid Ali Awan (@1abidaliawan) è un professionista certificato nel campo della scienza dei dati che ama costruire modelli di apprendimento automatico. Attualmente si concentra sulla creazione di contenuti e sulla scrittura di blog tecnici sulle tecnologie di apprendimento automatico e scienza dei dati. Abid ha conseguito una laurea magistrale in Gestione della Tecnologia e una laurea in Ingegneria delle Telecomunicazioni. La sua visione è quella di costruire un prodotto AI utilizzando una rete neurale a grafico per gli studenti che lottano con disturbi mentali.




