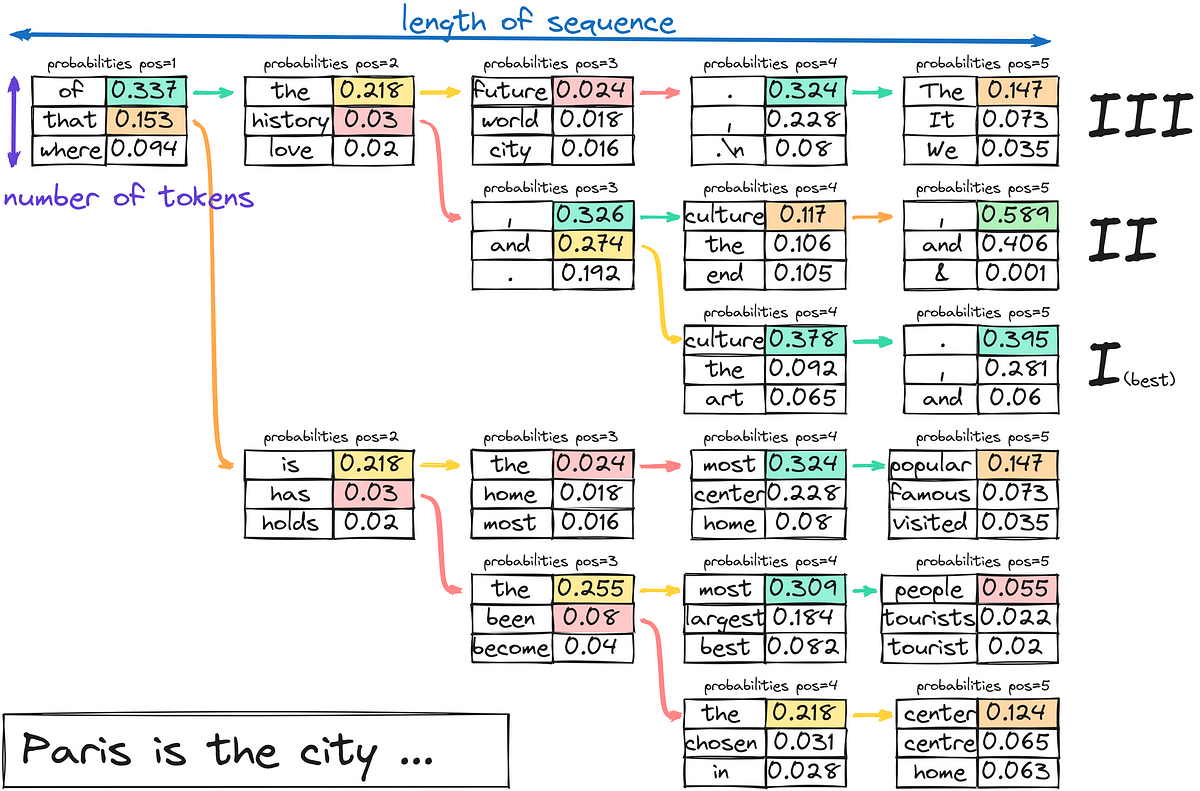
Traduzione dei termini con LLM (GPT e Vertex AI/Google Bard)
Traduzione termini con LLM (GPT e Vertex AI/Google Bard)
Possono gli LLM come ChatGPT effettuare traduzioni più accurate degli esseri umani? Quali opzioni di LLM abbiamo a disposizione? Scopri di più sull’utilizzo dell’IA generativa per effettuare traduzioni in diverse lingue.
Il Contesto
Al momento di scrivere questo post, lavoro con i dati da quasi un decennio e nel campo della localizzazione da 2 anni. Ho esperienza con vari tipi di intelligenza artificiale, inclusi, ma non limitati a, clustering, classificazione e analisi del sentiment. La traduzione automatica (MT) è comunemente utilizzata nella localizzazione. Pensate a Google Translate, dove inserite del testo e richiedete che venga tradotto in un’altra lingua. Dalla mia esperienza, la traduzione automatica è generalmente corretta all’80% delle volte, ma richiede comunque un controllo/correzione da parte di un essere umano per gli errori di traduzione.
Con l’avvento dei grandi modelli linguistici (LLM) come ChatGPT e Google Bard, potremmo riuscire ad avvicinarci alla precisione delle traduzioni umane fornendo ulteriore contesto agli LLM (come definizioni e parti del discorso).
- Scegli la tua arma strategie di sopravvivenza per consulenti AI depressi
- Top 5 Alternative Gratuite a GPT-4
- Raggiungere la collaborazione tra umani e IA con ChatGPT 🧠
L’Ipotesi
Gli LLM lavorano con un input basato su prompt. Ciò significa che più informazioni e contesto si possono fornire nel prompt, migliori saranno i risultati ottenuti dagli LLM. Dato un campione di termini inglesi, le loro definizioni e le loro parti del discorso, vorremmo verificare se gli LLM possono produrre risultati migliori nella traduzione dei termini in diverse lingue. I due LLM che utilizzeremo sono GPT (tramite un Jupyter Notebook tramite un’API di OpenAI) e Vertex AI (tramite la funzione ML.GENERATE_TEXT di Google BigQuery). Quest’ultima richiede molto più setup, ma può essere eseguita direttamente nella console delle query SQL.
Utilizzo degli LLM per Tradurre
GPT
Iniziamo installando la libreria python di OpenAI nel nostro jupyter notebook
import sys !{sys.executable} -m pip install openaiImporta pandas per lavorare con i dataframes. Importa la libreria openai precedentemente installata e imposta la tua chiave API. Leggi i tuoi dati in un dataframe. Se desideri seguire l’esempio, i dati con cui lavorerò possono essere trovati qui.
import pandasimport openai openai.api_key = "YOUR_API_KEY" # leggi i tuoi dati df = pd.read_csv('mydata/terms_sample.csv')In una lista, imposta le lingue in cui desideri tradurre la parola.
languages = ['Spagnolo (Spagna)', 'Spagnolo (Latino America)', 'Tedesco', 'Italiano', 'Giapponese', 'Cinese (S)', 'Francese']Crea una funzione che itera sulle righe del dataframe e sulle lingue nella tua lista per tradurre i termini rispettivamente. Il prompt verrà inserito nella sezione “messaggi”. Utilizzeremo GPT 3.5 e impostiamo la temperatura a un numero molto piccolo per garantire che otteniamo risposte precise/meno creative dagli LLM.
def translate_terms(row, target_language): """Traduci i termini""" user_message = ( f"Traduci il seguente termine inglese in {target_language}: '" + row['Term'] + "'.\n Ecco la definizione del termine per maggiore contesto: \n" + row['Definition'] + "'.\n Ecco la parte del discorso del termine per maggiore contesto: \n" + row['Part of speech'] + ".\n Si prega di tradurre solo il termine e non la definizione. Non fornire alcun testo aggiuntivo oltre al termine tradotto." ) response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "Sei un assistente di traduzione utile che traduce termini in altre lingue dato un termine inglese e una definizione."}, {"role": "user", "content": user_message}, ], max_tokens=50, n=1, temperature=0.1 ) return response['choices'][0]['message']['content']Il passo finale è iterare la funzione di traduzione sul dataframe per ogni lingua nella lista e creare una nuova colonna per i termini in quelle rispettive lingue. Trova di seguito il codice completo a titolo di riferimento.
# Applica la funzione al DataFramefor language in languages: df[language+'_terms'] = df.apply(translate_terms, axis=1, args=(language,))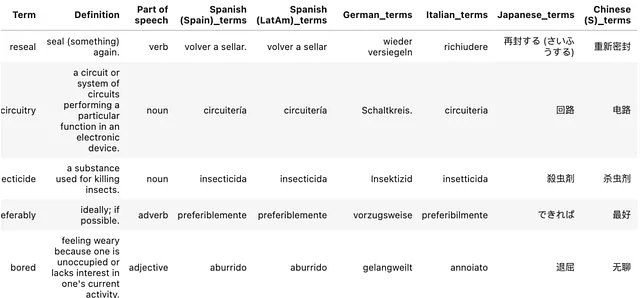
Google Bard / text-bisonm / Vertex AI
Utilizzeremo la funzione ML.GENERATE_TEXT all’interno del modello text-bison di Google per tradurre gli stessi termini di prima. Questo processo richiede un po’ più di risorse per essere configurato, ma una volta che è in funzione, saremo in grado di chiamare direttamente un LLM nella nostra query SQL.
Configurazione
Non fornirò una guida dettagliata alla configurazione in quanto l’infrastruttura del tuo Google Cloud è unica in base alle tue esigenze. Invece, fornirò una panoramica generale con link su come iniziare.
- Assicurati che sia abilitato un ruolo utente di Vertex AI per accedere al tuo account di servizio.
- Configura una connessione cloud remota seguendo le istruzioni su Google Cloud.
- Crea un modello LLM con la connessione cloud remota.
- Ora dovresti essere in grado di eseguire il tuo modello LLM utilizzando la funzione ML.GENERATE_TEXT. Consiglio di esaminare gli argomenti della funzione per capire quali parametri sono richiesti.
- Carica i tuoi dati nel tuo progetto di fatturazione per poterli interrogare.
Il Codice
Il codice utilizzato per generare le traduzioni può essere trovato di seguito. A causa di una combinazione delle mie limitazioni personali e delle restrizioni del nostro motore di query, ho deciso di eseguire singolarmente il codice per ogni lingua (sostituendo manualmente il testo in grassetto) invece di iterare sulla lista delle lingue come ho fatto con il precedente notebook jupyter.
DECLARE USER_MESSAGE_PREFIX STRING DEFAULT ( 'Sei un assistente di traduzione utile che traduce termini in altre lingue dato un termine e una definizione in inglese.'|| '\n\n' || 'Traduci il seguente termine in inglese in francese. Non tradurre anche la definizione.'|| '\n\n' || 'Termine: ');DECLARE USER_MESSAGE_SUFFIX DEFAULT ( '\n\n' || 'Ecco la definizione del termine per maggiori informazioni: '|| '\n\n');DECLARE USER_MESSAGE_SUFFIX2 DEFAULT ( '\n\n' || 'Ecco la parte del discorso del termine per maggiori informazioni: '|| '\n\n');DECLARE USER_MESSAGE_SUFFIX3 DEFAULT ( '\n\n' || 'Traduzione in francese del termine:');DECLARE languages ARRAY<string>;SET languages = ['Spagnolo (Spagna)', 'Spagnolo (LatAm)', 'Tedesco', 'Italiano', 'Giapponese', 'Cinese (S)', 'Francese'];SELECT ml_generate_text_result['predictions'][0]['content'] AS generated_text, ml_generate_text_result['predictions'][0]['safetyAttributes'] AS safety_attributes, * EXCEPT (ml_generate_text_result)FROM ML.GENERATE_TEXT( MODEL `IL_TUO_PROGETTO_DI_FATTURAZIONE.IL_TUO_DATASET.TUO_LLM`, ( SELECT Termine, Definizione, USER_MESSAGE_PREFIX || SUBSTRING(TERMINE, 1, 8192) || USER_MESSAGE_SUFFIX || SUBSTRING(Definizione, 1, 8192) || USER_MESSAGE_SUFFIX2 || SUBSTRING(Parte_del_discorso, 1, 8192) || USER_MESSAGE_SUFFIX3 AS prompt FROM `IL_TUO_PROGETTO_DI_FATTURAZIONE.IL_TUO_DATASET.termini_estratti` ), STRUCT( 0 AS temperatura, 100 AS max_output_tokens ) );Interpretazione dei risultati
Nota: Non parlo nessuna di queste lingue oltre l’inglese, quindi prendi le mie conclusioni con cautela.
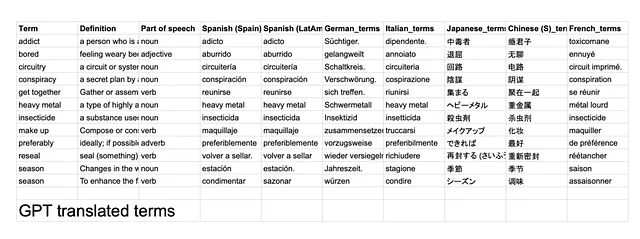
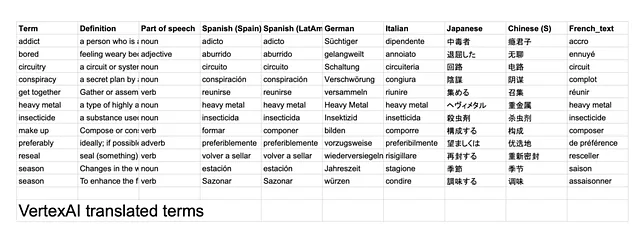
I risultati possono essere trovati qui. Alcune osservazioni che ho preso nota:
- 47 / 84 (56%) delle traduzioni fatte da entrambi i LLM erano esattamente uguali. – GPT spesso includeva un punto (.) alla fine della parola. Rimuovendo questi, la percentuale di corrispondenza aumenta al 63%.
- Sembra che giapponese e francese siano state le traduzioni più disallineate tra i due LLM.
- GPT ha interpretato il termine “make up” come make-up (cioè cosmetici), il che è preoccupante perché sembra che non abbia sfruttato la definizione e la parte del discorso di quel termine prima di effettuare una traduzione. – Questo potrebbe essere perché la struttura della mia richiesta non era ottimale. Ad esempio, avrei potuto fornire la definizione prima del termine per consentire al LLM di elaborare prima queste informazioni.
- Heavy metal (nome proprio) sembra essere tradotto letteralmente da GPT, specialmente in tedesco, dove è stato tradotto in un termine che non corrisponde al genere musicale
In definitiva, direi che entrambi i LLM hanno i loro vantaggi e svantaggi. GPT è facile da configurare ed eseguire in Python, mentre Vertex AI comprende meglio le richieste e tiene conto di tutto il contesto prima di effettuare una traduzione. Credo sia giusto dire che i LLM svolgono un lavoro molto migliore rispetto alla traduzione automatica tradizionale perché sono in grado di elaborare contesti aggiuntivi nelle loro richieste. Fammi sapere cosa ne pensi. Potevo fare meglio?
Pubblicato originariamente su https://shafquatarefeen.com.